내용 목차
본 장에서는 Tibero Standby Cluster의 구성요소와 동작 및 운영 방법을 설명한다.
Tibero Standby Cluster는 데이터베이스의 고가용성, 데이터의 보호, 재난 복구 등을 목적으로 제공하는 Tibero의 핵심 기능이다.
Tibero Standby 서버는 물리적으로 독립된 장소에 원본 데이터베이스의 복사본을 트랜잭션 단위로 보관한다. 복사할 대상이 되는 원본 데이터베이스를 Primary DB(이하 Primary)라 하고, 복사된 데이터가 저장되는 데이터베이스를 Standby DB(이하 Standby)라고 한다.
Tibero Standby Cluster의 원리는 Primary에서 생성된 Redo 로그를 배경 프로세스가 Standby로 전송하고, Standby는 Redo 로그를 이용해 Primary의 모든 변화를 똑같이 반영하는 것이다.
다음은 Tibero Standby Cluster가 어떻게 동작하는지를 나타내는 그림이다.
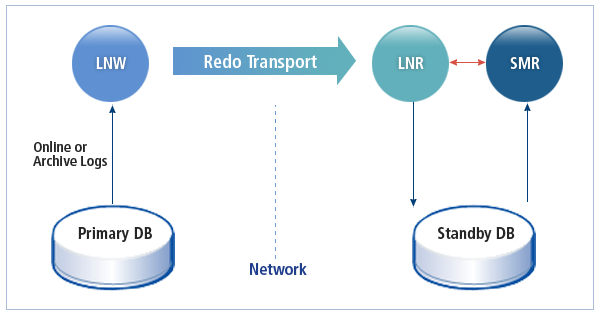
데이터의 복사를 통해 Primary는 서비스가 요청한 데이터 처리에 실패했을 경우 Standby의 데이터를 활용해 해당 서비스를 신속히 재개할 수 있다. 또한 Primary의 서버만으로는 손상된 데이터를 복구를 할 수 없는 경우에도 쉽게 대처할 수 있다.
예를 들면 Primary의 서버의 디스크가 손상된 경우 Standby를 통해 손상된 데이터를 보호할 수 있다.
Tibero Standby Cluster의 프로세스는 다음과 같다.
-
Primary의 Redo 로그를 Standby로 전송하는 프로세스이다. 로그 전송 방식과 무관하게 로그를 보내는 것은 항상 LNW에서 이루어진다.
Standby는 9개까지 설정이 가능하며, 각 Standby마다 LNW가 하나씩 실행된다.
-
Standby에서 Primary로부터 받은 Redo 로그를 온라인 Redo 로그 파일에 기록하는 프로세스이다.
Standby는 MOUNT나 NORMAL이 아닌 RECOVERY 부트 모드로 동작하며, 이때 log writer는 사용되지 않고, LNR이 LGWR의 역할을 대신한다.
-
온라인 Redo 로그를 읽어 Standby에 적용하는 복구 과정을 수행하는 프로세스이다.
LNR, SMR은 첫 번째 워킹 프로세스의 워킹 스레드 중 하나로 동작한다. 따라서 Standby를 구성하기 위해서는 $TB_SID.tip 파일의
_WTHR_PER_PROC초기화 파라미터의 값을 2보다 크게 설정해야 한다.
다음은 Standby로 연결할 데이터베이스의 정보와 각 Standby의 종류 그리고 동작 모드를 설정하는 방법이다.
<$TB_SID.tip>
LOG_REPLICATION_MODE = {PROTECTION|AVAILABILITY|PERFORMANCE}
LOG_REPLICATION_DEST_1 = "hostname_1:port_1 {LGWR SYNC|LGWR ASYNC|ARCH ASYNC}"
LOG_REPLICATION_DEST_2 = "hostname_2:port_2 {LGWR SYNC|LGWR ASYNC|ARCH ASYNC}"
...
LOG_REPLICATION_DEST_N = "hostname_N:port_N {LGWR SYNC|LGWR ASYNC|ARCH ASYNC}"
다음은 위 파일에서 설정한 각 초기화 파라미터에 대한 설명이다.
-
LOG_REPLICATION_MODE-
데이터를 보호하는 수준에 중점을 둘지 또는 성능을 최대화할지에 대한 전체적인 동작 모드를 설정한다. 한 번만 설정하면 된다.
-
LOG_REPLICATION_MODE 초기화 파라미터에 설정할 수 있는 항목은 다음과 같다.
항목 설명 PROTECTION LGWR SYNC로 설정된 Standby가 하나도 없는 경우를 허용할 수 없는 항목이다. 이 항목을 설정하면 서버를 기동할 때 초기화 에러가 발생한다. 이 에러를 해결하기 위해서는 모드에 따라 Standby에 맞게 설정한 후 다시 서버를 기동해야 한다. AVAILABILITY PROTECTION 항목과 마찬가지로 LGWR SYNC로 설정된 Standby가 하나도 없는 경우를 허용할 수 없는 항목이다. 이 항목을 설정하면 서버를 기동할 때 초기화 에러가 발생한다. 이 에러를 해결하기 위해서는 모드에 따라 Standby에 맞게 설정한 후 다시 서버를 기동해야 한다. PERFORMANCE Standby로 로그가 전송되는 방식에 제한이 없고 동기화를 보장하지 않으므로 시스템 성능을 높이는 데 가장 유리한 항목이다.
-
-
LOG_REPLICATION_DEST_N-
각 Standby의 데이터베이스의 연결 정보(hostname:port)와 로그 전송 방식을 설정한다. 설정할 수 있는 최대 Standby의 개수(N)은 9이고, 필요한 만큼만 LOG_REPLICATION_DEST_1부터 설정한다.
-
LOG_REPLICATION_DEST_N 초기화 파라미터에 설정할 수 있는 항목은 다음과 같다.
항목 설명 LGWR SYNC LGWR SYNC로 설정된 Standby는 Primary의 Redo 버퍼의 내용을 전송받아 동작하므로 가장 빈번하게 Redo 로그를 전송한다. 따라서 데이터가 보호될 확률도 높다. 반면에 Primary의 성능 저하가 심하므로 Standby를 Primary와 비슷한 수준으로 구축할 것을 권장한다.
PERFORMANCE 모드와 같이 사용할 수 있는데 이러한 경우 데이터를 보호하지 못하더라도 Primary는 계속 진행할 수 있다. 따라서 Standby가 느리면 온라인 Redo 로그 파일이나 아카이브 로그 파일에서 Redo 로그를 읽어 전송할 수 있으므로 Primary를 ARCHIVELOG 모드로 운영할 것을 권장한다.
LGWR ASYNC LGWR ASYNC로 설정된 Standby는 LGWR SYNC와 ARCH ASYNC의 중간 수준의 빈도로 Redo 로그를 전송한다.
기본적으로 온라인 Redo 로그 파일을 읽어서 전송하지만 Standby가 따라오지 못하는 경우 아카이브 로그 파일에서 읽을 수도 있으므로 Primary를 ARCHIVELOG 모드로 운영할 것을 권장한다.
ARCH ASYNC ARCH ASYNC로 설정된 Standby가 하나 이상 존재하면 Primary는 반드시 ARCHIVELOG 모드로 동작해야 한다. 그렇지 않으면 서버의 기동은 정상적으로 되지만 해당 Standby는 아무런 동작도 하지 못하게 된다. 이 점을 주의해야 한다.
비록 ARCH ASYNC인 Standby를 사용하지 않더라도 Standby 기능을 사용할 때에는 Primary를 ARCHIVELOG 모드로 운영할 것을 권장한다.
-
Primary를 NORMAL 모드로 기동하면 $TB_SID.tip 파일에 설정된 각 Standby와 연결이 이루어지고, 배경 프로세스에 의해 자동으로 데이터 이중화(Replication)가 이루어진다. 예를 들어 PROTECTION이나 AVAILABILITY 동작 모드로 기동하고 LGWR SYNC인 Standby가 모두 연결이 불가능한 상태라면 Primary도 운영이 불가능하므로 반드시 Standby를 먼저 기동해야 한다. 그 외의 경우에는 Standby를 나중에 기동하더라도 자동으로 연결되므로 운영이 가능하다.
참고
Primary에서 데이터베이스를 생성하는 동안에는 $TB_SID.tip 파일에 있는 Standby 설정이 무시된다. 따라서 Primary에서 생성된 DB 파일을 DBA가 수동으로 Standby로 복사해야 한다.
Standby를 운영하기 위해 필요한 설정 과정은 다음과 같다.
-
Primary에서 백업한 DB 파일을 복사해서 Standby를 구성한다.
컨트롤 파일, 온라인 로그 파일, 패스워드 파일을 포함한 모든 데이터 파일을 복사한다. 패스워드 파일을 함께 복사하는 이유는 Primary가 Standby에 SYS 권한을 가지고 접속하므로 SYS의 패스워드가 서로 일치해야 하기 때문이다.
-
Standby의 $TB_SID.tip 파일을 열어 DB_NAME이 Primary와 같도록 수정한다.
-
$TB_SID.tip 파일에서 컨트롤 파일이 위치하는 디렉터리 경로가 1번에서 Primary 파일을 복사한 경로와 일치하는지 확인한다. 또한
DB_BLOCK_SIZE도 Primary에 설정된 것과 같아야 한다. 설정이 같으면 복사한 데이터 파일을 열 수 있다.Primary의 백업을 가져다 놓은 Standby의 디렉터리의 경로가 원래와 달라진 경우에는 Standby의 $TB_SID.tip 파일에 다음과 같이 경로 변환을 위한 정보를 추가해야 한다.
Primary와 Standby의 절대 경로는 각각 Primary와 Standby의 instance 디렉터리의 절대 경로이다.
-
Standby를 MOUNT 모드로 기동한 후 다음의 DDL 문장을 수행하면 변환된 경로가 컨트롤 파일에 적용된다.
위의 과정은 같은 경로로 DB 파일을 가져다 놓았다면 필요하지 않으며 경로가 다른데도 위의 과정을 수행하지 않고 Standby를 기동하는 경우 컨트롤 파일에 적힌 경로에 데이터 파일을 열 수 없다는 에러가 발생한다.
-
Standby를 운영하기 위한 설정을 완료하면 다음의 명령을 통해 DB가 Standby로 동작하도록 기동시킨다.
NORMAL 모드로 Standby를 한 번이라도 기동하게 되면 더 이상 Standby로서의 기능은 할 수 없고, 앞서 설명한 과정을 다시 반복하여 Standby를 설정해야 한다는 점에 주의한다.
Standby가 기동하기 전에 DB 파일이 이전의 버전이라 하더라도 일관성만 유지한다면 동작에는 문제가 없다. 내부적으로 Primary가 접속하여 Primary와 Standby 사이의 로그 갭(log gap)을 자동으로 맞춰 동작한다. 하지만 이 과정이 모두 Redo 로그에 의존하므로 두 DB 사이의 차이가 크고, Primary가 ARCHIVELOG 모드가 아니라면 필요한 Redo 로그가 존재하지 않아 동작이 불가능할 수 있다. 따라서 Primary는 ARCHIVELOG 모드로 동작시키거나 최근에 백업한 Primary를 Standby로 복사하여 두 DB의 DB 파일을 맞춘 후에 Primary를 동작시키는 것이 바람직하다.
Standby는 내부적으로 Primary로부터 받은 Redo 로그를 디스크에 기록하고, 이를 복구하여 데이터 파일에도 반영하는 일을 수행하는 RECOVERY 모드로 동작하기 때문에 DB에 사용자의 접근이 제한된다.
Standby를 read only 클러스터용으로 사용하는 경우와 같이 Standby에서 Redo 로그를 반영하는 과정을 중단하지 않고 읽기 작업을 원하는 경우가 있다. 그때에는 다음의 DDL 문장을 실행하면 Standby는 복구 과정을 멈추지 않고 read only 세션을 허용한다.
Standby가 LGWR SYNC 모드로 설정되어 Primary와 동기화되어 있는 경우라면 Primary에 접속한 경우와 같이 최근에 커밋된 내용을 Standby에서도 볼 수 있다. 이 상태에서는 비록 DB 서버가 read only 모드임에도 불구하고 데이터의 내용이 변경될 수 있다는 사실에 주의해야 한다.
Standby를 다시 RECOVERY 모드로 전환시킬 때는 다음의 DDL 문장을 수행한다.
본 절에서는 Standby를 Primary로 전환하는 과정을 두 가지 시나리오로 나누어 설명한다.
Primiary를 정상적으로 셧다운하고 Standby 중 하나를 Primary로 전환하고 싶은 경우 다음의 절차를 수행한다.
-
Primary에서 다음의 명령어를 입력한다.
위의 명령어를 수행하면 모든 Standby를 Primary와 동기화시킨다. 그 이후에 Primary가 종료된다.
-
Standby 중 하나를 종료한 후 FAILOVER 모드로 기동하면 그 DB가 새로운 Primary가 된다.
이전의 Primary를 새로운 Standby로 사용하고 싶다면 새로 Primary가 될 DB의 $TB_SID.tip 파일에
Standby(LOG_REPLICATION_MODE,
LOG_REPLICATION_DEST_n 초기화 파라미터)를 설정하고, 이전 Primary를
RECOVERY 모드로 기동한 후에 새로 Primary가 될 DB를 FAILOVER 모드로 기동하면 서로 역할을 전환하여 수행할
수 있다.
이때 두 DB는 이미 동기화된 상태이므로 Standby를 구성할 때 필요한 새로운 Primary의 DB 파일을 복사하고, ALTER DATABASE Standby controlfile을 수행하는 과정은 더 이상 필요하지 않는다. 또한 새로운 Standby의 $TB_SID.tip 파일에 기존의 Standby와 관련된 설정이 남아 있더라도 DB가 NORMAL 모드로 운용될 때만 적용된다.
Primary와 Standby에 모두 접속하기 위해서는 tbdsn.tbr 파일에 각 DB의 접속 정보를 추가해야 한다.
예를 들면 다음과 같다.
<tbdsn.tbr>
PrimaryDB_SID=(
(INSTANCE=(HOST=primaryDB_hostname)
(PORT=primaryDB_port)
(DB_NAME=cluster_DB_NAME)
)
)
StandbyDB_SID=(
(INSTANCE=(HOST=StandbyDB_hostname)
(PORT=StandbyDB_port)
(DB_NAME=cluster_DB_NAME)
)
)
Primary와 Standby의 $TB_SID.tip 파일을 설정할 때 공통의 DB_NAME을 각각 SID별로 설정해야 한다.
참고
Primary에서 장애가 발생하면 Standby에 자동으로 접속하는 방법이 있다. 이 방법에 대한 자세한 내용은 “Appendix A. tbdsn.tbr”를 참고한다.
Tibero Standby Cluster는 Primary에서 생성된 Redo 로그를 그대로 Standby에 전송하므로 서로 간의 컴퓨팅 환경(CPU bus size, endianness, OS 등)이 동일해야 하고, $TB_SID.tip 파일의 데이터베이스 블록의 크기도 동일해야 한다.
Redo 로그를 적용하는 Standby Cluster의 특성으로 로그를 남기지 않는 DPL/DPI는 지원하지 않는다. 테이블 스페이스나 데이터베이스 파일의 상태를 변경하는 DDL 중 일부도 허용하지 않는다. 이와 같은 연산은 Standby 없이 수행해야 한다. 즉, 데이터베이스를 백업하여 Standby에 적용해야 하는 제약이 있다.
다음은 Standby Cluster에서 지원하지 않는 작업들이다.
참고
Standby가 read only 모드일 경우 DB Link 기능은 사용할 수 없다.
Tibero에서는 Tibero Standby Cluster의 상태 정보를 제공하기 위해 다음 표에 나열된 동적 뷰를 제공하고 있다.
| 동적 뷰 | 설명 |
|---|---|
| V$STANDBY_DEST | Primary에 설정된 각 Standby의 연결 정보 및 Redo 로그의 전송 상태를 조회하는 뷰이다. Primary에서만 이 뷰를 사용할 수 있다. |
| V$STANDBY | Standby에서 Primary의 연결 정보와 전달 받은 Redo 로그 그리고 이미 반영된 Redo 로그의 상태를 조회하는 뷰이다. Standby에서만 이 뷰를 사용할 수 있다. |
참고
동적 뷰에 대한 자세한 내용은 "Tibero 참조 안내서"를 참고한다.