내용 목차
본 장에서는 EJB 클러스터링 개념과 주요 기능 설정 방법에 대해 설명한다.
EJB의 Failover와 Load Balancing 기능을 사용하기 위해서 각 Bean들은 여러 EJB 엔진에 deploy되어 클러스터링을 형성해야 한다. 클러스터링은 컴포넌트 레벨(개별 Bean)에서 수행되고 Stateless/Stateful Session Bean과 Entity Bean에서 이용할 수 있다. Message Driven Bean(MDB)은 클러스터링 대상에 해당 되지 않는다.
JEUS EJB 클러스터링은 크게 다음과 같은 2가지 기능을 갖는다.
다음 그림은 2가지 EJB 클러스터링의 주요 기능인 Failover와 Load Balancing을 설명한다.
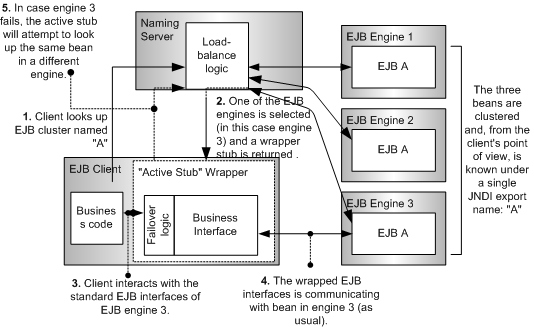
클러스터링을 원하는 모듈을 deploy하면 Naming Server에 모두 같은 이름으로 바인드된다. 클라이언트는 그 하나의 이름으로 수행해도 Load Balancing과 Failover가 가능하다. 따라서 같은 모듈이더라도 Naming Server에 바인딩할 이름을 다르게 하여 deploy하면 해당 모듈은 클러스터링되지 않음에 주의한다.
참고
Stateful Session Bean의 경우 Failover를 위해 JEUS 분산 Session Manager를 사용한다. Session Manager는 EJB 엔진당 하나만 존재하기 때문에 클러스터링할 Bean의 클러스터링 범위가 각 Bean별로 달라서는 안 된다. 예를 들어 Bean A는 EJB einge1과 EJB engine2로 묶고 Bean B는 EJB engine1과 engine3으로 묶었다면 Session Manager는 Bean A와 Bean B가 EJB engine1, EJB engine2, EJB engine3에 클러스터링되어 있다고 잘못 확인하게 된다.
다음은 EJB 클러스트링의 주요 기능에 대한 설명이다.
클라이언트가 lookup이나 injection에 의해 Bean A를 요청하면 Naming Server는 3개의 EJB 엔진에 존재하는 3개의 Bean 중 하나를 임의로 선택하여 반환한다. 클라이언트는 그 후부터는 선택된 EJB 엔진에서 비즈니스 인터페이스를 통하여 Bean과 일반적인 방법으로 연동한다.
이는 3개의 Bean들은 동일하게 같은 메소드 호출 요청을 받게 되고 잠재적으로 한 개의 엔진이 모든 요청에 대해 서비스하는 것보다 무려 3배의 시스템 성능 향상을 기대할 수 있다는 것을 의미한다(Load Balancing의 경우에 발생하는 작은 자원소모를 계산하지 않을 때).
Failover는 하나의 EJB 서비스에 장애가 발생해도 서비스를 정상적으로 제공하는 것을 의미한다(예: OS 장애, 네트워크 중단 또는 EJB 엔진 장애).
JEUS 시스템이 처리할 수 있는 장애 복구에는 다음의 2가지가 있다.
-
클라이언트의 요청이 도착했을 때 접근 불가한 Bean에게 요청을 보내지 않고, 처리되지 않은 요청을 다른 Bean에게 다시 보내는 방법
단순히 문제가 발생한 EJB 엔진을 제외하고 Load Balancing 알고리즘을 실행한다. 새로운 클라이언트의 요청을 처리하기 위해서는 사용 가능한 엔진의 Bean을 선택한다.
JEUS에서는 Failover의 Rerouting이 클라이언트 측의 EJB Stub에서 처리된다. 이 Stub을 Active Stub이라 부르고 또는 표준 EJB 인터페이스를 둘러 싼 wrapper라고도 부른다. 이러한 wrapper를 사용할 때의 다른 점은 현재 연결되어 있는 Bean 또는 EJB 엔진이 문제가 있는지 판단할 수 있는 로직을 가지고 있는지 여부이다. 이러한 문제점이 발견되면, 기동 중인 Stub이 자동으로 JNDI 서버에 접속해서 작동하고 있는 EJB 엔진을 대신하여 새로운 Stub을 요청한다([그림 6.1]의 5번).
-
실행 중인 Bean이 어떤 이유로 런타임 오류를 가지고 있다면 진행 중인 요청을 다른 Bean에게 다시 보내는 방법
이러한 상황에서의 복구 방법은 한계가 있다. Bean이 요청을 처리하고 있을 때 문제가 발견되면 얼만큼 요청을 처리하고 있었는지도 모르고 문제가 발생했을 때 어떤 런타임 에러를 발생시켰는지도 모른다. 단순하게 클러스터에 존재하는 다른 Bean의 같은 메소드를 호출하는 것은 또 다른 부작용을 조장할 수 있기 때문에 자칫하면 위험한 결과를 가져올 수도 있다.
이 문제를 명백히 하기 위해 DB 필드를 1씩 증가시키는 메소드를 가지는 Bean Instance A를 고려해보자. 1이 증가된 후에 바로 문제가 발생하는 경우 단순하게 다른 Bean "B"에 있는 같은 Business 메소드를 다시 호출하면 1이 다시 한 번 증가한다. 결과적으로 DB에 일괄적이지 못하고 잘못된 값을 전송하게 된다. 이런 경우 Idempotent 메소드를 이용하면 안전하게 복구될 수 있다. Idempotent 메소드를 통한 EJB 복구 방법에 대한 자세한 내용은 “6.2.3. Idempotent 메소드를 통한 EJB 복구”를 참고한다.
위의 두 시나리오의 차이는 오류 상황이 발견되는 시점이다. 즉, Remote Business 메소드를 호출하기 전인지 또는 Bean이 요청을 처리하고 있는 중인지의 예가 있을 수 있다.
Idempotent 메소드는 부작용이 없는 getter 메소드이다. 이는 메소드의 수행 중에 어떠한 상태(예: instance 변수, DB 필드 등)도 변경되지 않는 것을 보장한다.
따라서 “6.2.2. Failover(EJB 복구)”에서의 두 번째 복구 방법이 지닌 한계는 Idempotent 메소드로 극복할 수 있다. 그러나 Idempotent 메소드가 아니라면 역시 대책이 없다. 런타임 에러가 발생한 메소드를 다시 실행시키는 것보다는 Exception을 던지는 것이 차라리 낫다. 그러므로 Idempotent 메소드를 많이 사용할수록 EJB Failover는 더 잘 작동된다. 메소드가 Idempotent 메소드인지 아닌지 판단하는 공식은 없다. 그러므로 Business 메소드의 상태를 정확히 식별하고 설정해야 한다.
Stateful Session Bean의 경우 세션의 백업을 위해서 JEUS Session Manager를 사용한다. 일반적으로 Business 메소드 호출 단위로 세션의 상태가 변화하기 때문에 JEUS에서는 메소드 호출이 발생하고 결과가 리턴되는 시점마다 JEUS Session Manager에 세션 백업을 요청한다. 이러한 백업 작업을 다른 용어로 세션 복제(Session Replication)라고 한다.
JEUS Session Manager는 세션을 동기적(Sync) 또는 비동기적(Async)으로 복제할 수 있다. JEUS에서는 이를 복제 모드(Replication Mode)라고 한다.
2가지 방법은 서로 장단점이 있으므로 JEUS에서는 Bean과 각 Business 메소드 특성에 따라 사용자가 설정할 수 있다. 또한 세션 복제를 하지 않아도 되는 메소드가 있을 수 있으므로 이 역시 설정할 수 있다. 자세한 설정 방법은 “6.3. EJB 클러스터링 설정”을 참고한다.
참고
JEUS에서는 클러스터링에 참여한 Stateful Session Bean이라면 기본적으로 동기적(Sync) 복제 모드로 세션 복제가 이루어진다. 사용자는 설정에 의해 이를 조정할 수 있다.
EJB 클러스터링은 Bean 클래스에 Annotation으로 설정하거나 jeus-ejb-dd.xml에 설정할 수 있다. 설정할 사항은 클러스터링으로 구성될 Bean, 그 Bean의 Idempotent 메소드 그리고 Bean 또는 각 메소드의 세션 복제 모드이다.
본 절에서는 예를 통해 Annotation과 DD(xml) 파일에 클러스터링을 설정하는 방법에 대해 설명한다.
클러스터링에 참여하는 Bean 클래스 또는 메소드에 다음과 같은 Annotation을 이용하여 설정한다.
[예 6.1] Annotation을 통한 클러스터링 설정 : <<CounterEJB.java>>
package ejb.basic.statelessSession;
import javax.ejb.Stateful;
import jeus.ejb.Clustered;
import jeus.ejb.Replication;
import jeus.ejb.ReplicationMode;
@Stateful(name="counter", mappedName="COUNTER")
@Clustered
@Replication(ReplicationMode.SYNC)
@CreateIdempotent
public class CounterEJB implements Counter, CounterLocal {
private int count = 0;
public int increaseAndGet() {
return ++count;
}
@Replication(ReplicationMode.NONE)
public void doNothing(int a, String b) {
}
@Idempotent
public int getResult() {
return count;
}
@Idempotent
@jeus.ejb.Replication(ReplicationMode.ASYNC)
public int getResultAnother() {
return count;
}
...
}
다음은 각 클래스별 설정에 대한 설명이다.
JEUS EJB 모듈 DD 파일(jeus-ejb-dd.xml)에는 클러스터링에 참여하는 각각의 Bean들을 위해서 <clustering> 태그 아래에 다음과 같은 설정을 적용할 수 있다.
[예 6.2] xml을 통한 클러스터링 설정 : <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<beanlist>
. . .
<jeus-bean>
<ejb-name>counter</ejb-name>
<export-name>COUNTER</export-name>
. . .
<clustering>
<enable-clustering>true</enable-clustering>
<ejb-remote-idempotent-method>
<method-name>getResult</method-name>
</ejb-remote-idempotent-method>
<ejb-remote-idempotent-method>
<method-name>getResultAnother</method-name>
</ejb-remote-idempotent-method>
<create-idempotent>true</create-idempotent>
<replication>
<bean-mode>sync</bean-mode>
<methods>
<method>
<method-name>doNothing</method-name>
<method-params>
<method-param>int</method-param>
<method-param>java.lang.String</method-param>
</method-params>
<mode>none</mode>
</method>
<method>
<method-name>getResultAnother</method-name>
<method-params>
<method-param>void</method-param>
</method-params>
<mode>async</mode>
</method>
</methods>
</replication>
</clustering>
. . .
</jeus-bean>
. . .
</beanlist>
. . .
</jeus-ejb-dd>
다음은 <clustering>의 하위 설정 태그에 대한 설명이다.
| 태그 | 설명 |
|---|---|
| <enable-clustering> | Bean의 클러스터링을 전체적으로 활성화 또는 비활성화시킨다. |
| <ejb-remote-idempotent-method> | Bean 메소드 중에 Idempotent 메소드들을 선언한다(“6.3.1. Annotation을 통한 클러스터링 설정”의 @jeus.ejb.Idempotent 설명 참조). |
| <ejb-remote-idempotent-exclude-method> | Bean 메소드 중에 Idempotent 메소드들로 선언한 것 중 제외하고 싶은 메소드를 선언한다. <ejb-remote-idempotent-method>보다 우선순위는 높고, 사용법은 동일하다. |
| <ejb-home-idempotent-method> | 2.x 스타일의 홈 인터페이스에 정의된 메소드 중에 Idempotent 메소드들을 선언한다(“6.3.1. Annotation을 통한 클러스터링 설정”의 @jeus.ejb.CreateIdempotent 설명 참조). 사용법은 <ejb-remote-idempotent-method>와 동일하다. |
| <ejb-home-idempotent-exclude-method> | 2.x 스타일의 홈 인터페이스에 정의된 메소드 중에 Idempotent 메소드들로 선언한 것 중 제외하고 싶은 메소드를 선언한다. <ejb-home-idempotent-method>보다 우선된다. 사용법은 <ejb-remote-idempotent-method>와 동일하다. |
| <create-idempotent> | Session Bean을 생성할 때 Idempotent하게 할지 선언한다. |
| <replication> | Bean 레벨의 세션 복제 모드 또는 메소드별 복제 모드를 설정한다. 자세한 내용은 “6.2.4. Session Replication”과 [예 6.2]를 참고한다. |
위에서 지정한 Bean 클러스터링이 작동하기 위해서는 다음의 내용을 주의해야 한다.
-
클러스터링에 참여하는 모든 Bean들은 <clustering> 하위의 모든 정보가 동일해야 한다.
-
클러스터링으로 구성하기 위해서는 원하는 Bean의 <export-name>을 모두 동일하게 설정한다.
클러스터링 환경에서 Stateful Session Bean을 실행하려면 Session Manager 설정을 추가로 해야 한다.
다음은 WebAamin을 사용해서 Session Manager를 설정하는 방법이다.
-
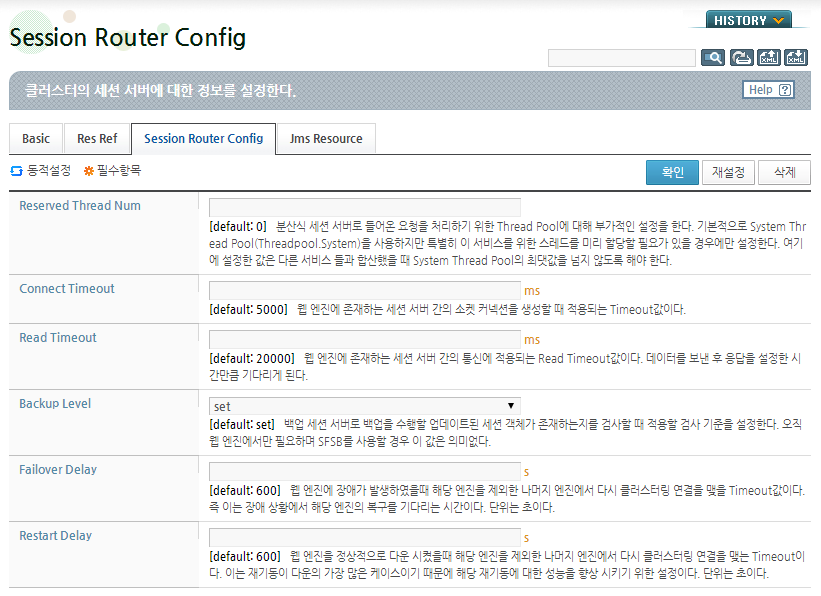
WebAdmin의 [Clusters] 메뉴를 선택한 후 [Session Router Config] 탭으로 이동한다.
-
동적 설정 변경을 위해 화면 왼쪽의 [LOCK & EDIT] 버튼을 클릭해서 설정변경 모드로 전환한다.
-
다음과 같이 Session Router Config 화면에서 설정 항목을 설정한 후 [확인] 버튼을 클릭한다.
-
서버에 설정 내용을 반영하기 위해 화면 왼쪽의 [Activate Changes] 버튼을 클릭한다.
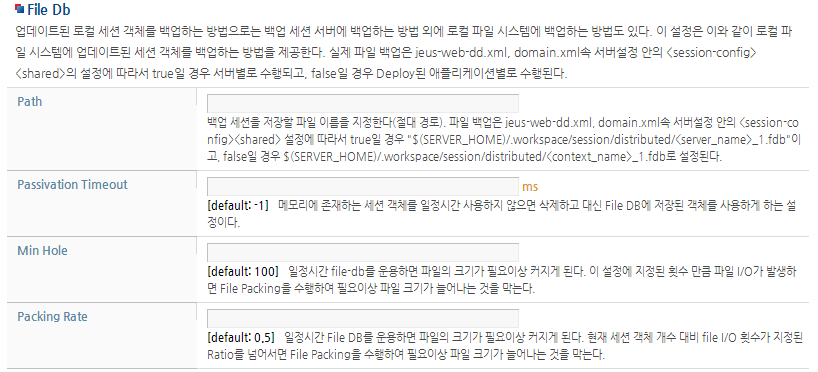
참고
Session Manager 설정에 대한 자세한 내용은 “JEUS 세션 관리 안내서”의 “2.7. 세션 서버 설정”을 참고한다.
매번 클라이언트에서 EJB Reference(Stub)를 lookup하지 않고, lookup한 EJB Reference를 Cache하여 계속 사용하는 경우(Injection을 사용하는 경우도 포함), 살아 있는 다른 EJB End-point가 있음에도 불구하고 Failover가 되지 않는 경우가 있을 수 있다. 이는 lookup하는 시점에 존재했던 EJB End-point 리스트에 해당하는 MS들이 모두 살아 있지 않고 그 이후에 구동된 새로운 MS만 존재하는 경우에 발생할 수 있다.
Failover를 해야하는 시점에서 내부적으로 lookup하여 새로운 EJB Reference를 클라이언트에게 전달한다. 그러나 이때 사용 중이던 EJB Reference가 lookup될 때 deploy되어 있던 MS들이 모두 다운되면 현재 사용 중이던 EJB Reference가 lookup될 당시 deploy되지는 않았지만 그 후에 deploy되어 Failover하는 시점에서 서비스 가능한 새로운 EJB End-point가 존재해도 Failover가 되지 않는다.
여기서 기존 MS들이 모두 다운되었다는 것은 비정상 종료되거나, 다운되거나, EJB End-point가 undeploy되어서 기존의 모든 EJB End-point의 서비스가 불가능한 것을 의미한다. 또한 새로운 EJB End-point가 deploy되는 경우는 뒤늦게(EJB Reference를 lookup하여 이미 사용 중일 때) 새로운 MS가 클러스터에 포함되거나, 뒤늦게 다운했던 MS를 재시작했거나 undeploy했던 EJB End-point를 뒤늦게 redeploy를 하는 경우가 포함된다.
2개의 MS로 Active/Backup 클러스터링을 구성하는 경우에 이런 현상이 발생할 수 있다. 또는 다음과 같은 시나리오에서 이런 경우가 발생할 수 있다.
예를 들어 A, B, C라는 MS가 있는데 클라이언트가 처음 lookup을 하여 계속 Cache를 하는 경우이다.
-
A, B, C에 모두 deploy되어 있고 처음 lookup한 결과, A의 EJB를 받는다.
-
A의 EJB를 사용하다 A가 비정상 종료되어 내부적으로 B의 EJB를 lookup하여 계속 서비스받는다.
-
B의 EJB가 undeploy되어서 C의 EJB를 lookup해서 사용한다.
-
이때 다시 B의 EJB가 deploy되고, 곧이어 C가 비정상 종료되었다.
이 경우 C의 EJB Reference가 lookup될 때 B의 EJB End-point는 undeploy되어 있었고 C의 EJB Reference를 lookup한 다음에 deploy되었으므로 C가 다운되었을 때 B는 운용 중이었지만 Failover는 되지 않는다. 그러나 이때 B가 deploy나 undeploy된 것이 아니라 비정상 기동나 비정상 종료가 되었다면 정상적으로 Failover된다. 비정상 종료의 경우에는 Failover 시점에서 재기동 여부를 검사하기 때문에 가능하다.
이렇게 Failover가 제대로 수행되지 않는 상황에는 다시 lookup해서 새로운 EJB Reference를 가져온다. 그러면 새로운 End-point 목록을 가져오기 때문에 이런 문제를 피할 수 있다.