Table of Contents
From EJB 3.0, entity bean is replaced by JPA. Therefore, it is recommended to use JPA by referencing the JEUS JPA guide when creating a new bean. However, JEUS EJB engine supports entity beans for existing users.
This chapter describes everything about configuring and tuning entity beans in JEUS EJB engine.
In compliance with the EJB specifications, the following three entity bean types are fully supported in the JEUS EJB engine.
-
Bean Managed Persistence Entity Beans (BMP)
-
Container Managed Persistence Entity Beans according to the EJB 1.1 specification (CMP 1.1)
-
Container Managed Persistence Entity Beans according to the EJB 2.0 specification (CMP 2.0)
Regardless of types, entity beans in JEUS share configuration functions and components described in "Chapter 4. Common Characteristics of EJB". Therefore, in order to configure and use entity beans in JEUS EJB engine, you need to have knowledge of the relevant chapters.
There are three kinds of configuration settings related to these three bean-types:
-
Shared configurations that apply to all three types of entity beans
-
Configurations that apply to both CMP 1.1 and CMP 2.0
-
Configurations that apply to CMP 2.0
The following table shows the configurable properties by entity bean type.
[Table 8.1] Configurable Elements of Entity Bean Types
| Configurable Entity | BMP | CMP 1.1 | CMP 2.0 |
|---|---|---|---|
| 1. EJB name | √ | √ | √ |
| 2. Export name | √ | √ | √ |
| 3. Local export name | √ | √ | √ |
| 4. Export port | √ | √ | √ |
| 5. Export IIOP switch | √ | √ | √ |
| 6. use-access-control | √ | √ | √ |
| 7. Run-as identity | √ | √ | √ |
| 8. Security CSI Interop. | √ | √ | √ |
| 9. Env. refs | √ | √ | √ |
| 10. EJB refs | √ | √ | √ |
| 11. Resource Refs | √ | √ | √ |
| 12. Resource env. Refs | √ | √ | √ |
| 13. Thread ticket pool settings | √ | √ | √ |
| 14. Clustering settings | √ | √ | √ |
| 15. HTTP invoke | √ | √ | √ |
| 16. JEUS RMI | √ | √ | √ |
| 17. Object management | √ | √ | √ |
| 18. Persistence Optimize | √ | √ | √ |
| 19. CM persistence opt. | √ | √ | |
| 20. Schema info | √ | √ | |
| 21. Relationship map | √ |
As we can see from the previous table, items 1 through 16 apply to all entity types. These items were previously described in "Chapter 4. Common Characteristics of EJB".
Item 17 is for both session beans and entity beans, but in a different way. The difference will be explained in this chapter. Items 18 through 21 apply only to entity beans, and will be fully described in this chapter.
Apart from these, we shall also discuss the following topics, pertaining only to JEUS Entity EJB:
-
Default primary key class
-
JEUS-specific items added to the EJB QL language
-
JEUS Instant EJB QL API
Note
Performance tuning is a major part of EJB entity bean configuration in JEUS. Therefore, this chapter will discuss many performance-related issues such as engine modes and sub-modes. The entity bean tuning section ("8.4. Entity EJB Tuning") later in this chapter is a concise summary of what will be covered in this section.
This section describes common functions of entity beans and the main functions of each bean.
The JEUS entity bean functions are shared by all three types of entity beans in JEUS.
The following figure shows how entity bean objects are managed in the EJB engine.
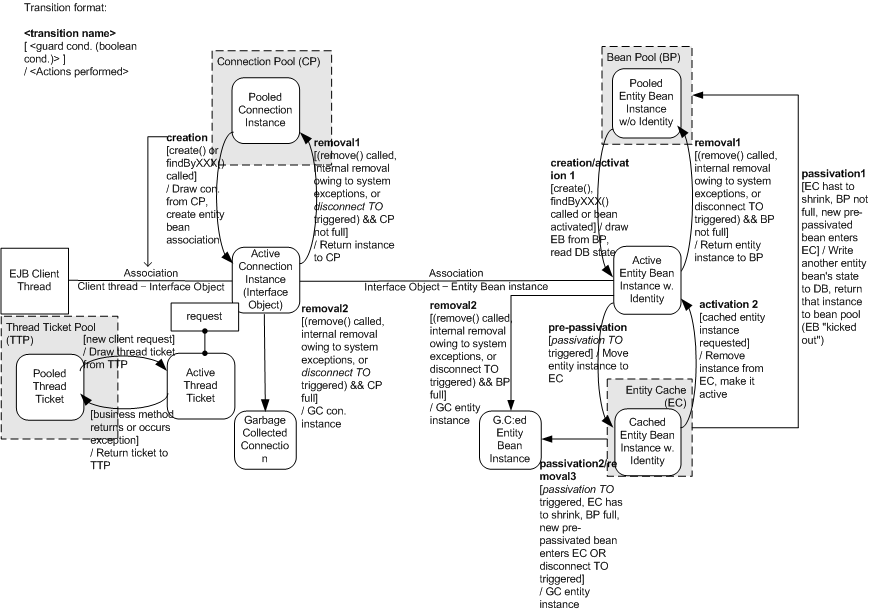
The term "object management" refers to the internal bean instance pool and connection pool of the EJB engine. These pools are configured for each bean, and helps improve the performance and resource management of the system. Basically, it acts like a stateful session bean. This section will only discuss the differences. For other details, refer to "Chapter 7. Session Bean".
An entity bean also uses the Entity-Cache along with the Connection Pool. When an entity bean is about to be passivated (when the passivation timeout expires), the bean instance is not actually passivated(Stateful Session Bean gets passivated). Instead, it is sent to the entity cache. All the entity beans that have been passivated are stored in the Cache in the activated state (they maintain an identifiable and valid status).
Entity beans are actually passivated in the following case.
An entity cache is passivated when it needs to reduce its size. If a new entity bean is about to enter the cache, but the cache is found to already be filled with "inactivated" beans, an entity bean that is already in the cache will be selected and removed from the cache. The removed entity bean will now be inactivated, and its state is written to the back-end database and its identity-less instance is now either returned to the bean pool or discarded (if the bean pool is full). The bean that was waiting to enter the cache replaces the removed bean instance in the cache.
The size of the cache may be adjusted with the <persistence-optimize> / <entity-cache-size> option. It does not reduce the cache size, but the setting is used as a hint. The removed bean instances are not selected in the order of how long they have remained in the cache.
The advantage of using such a cache is that we can improve the time-consuming inactivation management by using the cache. We do not always need to go back to the EJB database when we re-activate an inactivated entity bean; we can simply use the instance found in the cache (if present).
While the standard inactivation timeout value for object management allows the deployer to set time constraints for inactivation, the entity cache allows him or her to also set up memory-constraints for inactivation, which is the main purpose for using an entity cache.
Caution
The entity cache configuration is not actually a part of the object management configuration but rather the general entity bean persistence optimization settings (see next sub-section). This will be clearly shown in "8.3. Entity EJB Configuration".
It is up to the EJB engine (container) to decide when to invoke the ejbLoad() method on an entity bean. This method is used both in BMP and CMP beans to synchronize the runtime state of the bean instance with the state of the DB. Essentially, the ejbLoad() method is used to read in a row from the database and to populate the internal instance fields of the bean with the current row values.
The ejbLoad() method will be invoked at least once during the life-cycle of an entity bean: when it is first instantiated. In some cases, however, it will also be necessary to invoke the ejbLoad() method before every invocation of the bean instance.
There are basically two such scenarios when the state of the bean must be repeatedly read from the DB:
-
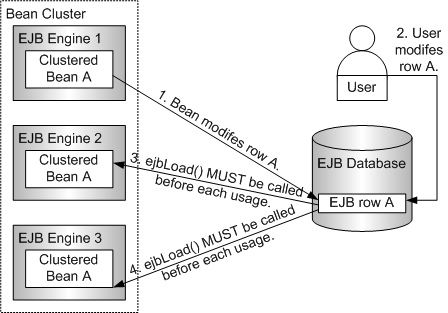
When a bean is clustered across several EJB engines, any bean in the cluster may modify a row in the DB. This means that we can never be sure whether the state stored in a particular entity bean instance is the most recent one.
-
When some external entity (user or system) modifies the EJB connected to the DB.
In this scenario, the state of a particular EJB instance on the EJB engine may not reflect the correct information.
The following figure shows 2 scenarios where the ejbLoad() method is called periodically when entity beans are clustered or when an external entity modifies the bean's DB row.
If the previous two scenarios can be avoided (i.e. you do not use clustering and you can guarantee that no external entity modifies the EJB’s back-end data), you may optimize the behavior of the ejbLoad() method for the entity bean.
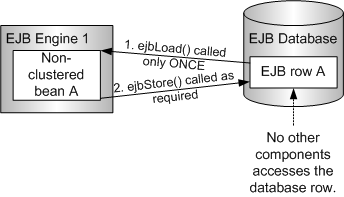
This is done by specifying what is known as the EXCLUSIVE_ACCESS engine mode for the bean. In this mode, the ejbLoad() method will only be called once, when the bean is instantiated. This will effectively remove 50% of database accesses.
The following figure depicts a scenario when the EXCLUJSIVE_ACCESS mode can be used. With EXCLUSIVE_ACCESS, only one bean accesses the database row, and most of the ejbLoad() method calls are optimized.
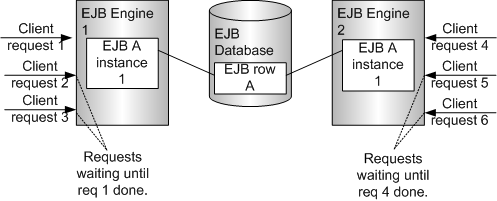
If you do need to cluster your beans or if some external entity needs to modify the EJB data, you must use either the SINGLE_OBJECT or MULTIPLE_OBJECT engine modes. When either of these modes is used, the EJB engine will invoke the ejbLoad() method each time an EJB client request is made. This will degrade the performance of individual entity bean deployments. However, this will allow you to distribute the load across many different beans and engines, since the state will now be kept and managed entirely by the DB.
The difference between the SINGLE_OBJECT and MULTIPLE_OBJECT modes is as follows:
-
SINGLE_OBJECT engine mode
With SINGLE_OBJECT, only one bean instance in each EJB engine will handle all client requests, implying that other requests that arrive during the processing of the initial request will have to wait.
-
-
MULTIPLE_OBJECT engine mode
With MULTIPLE_OBJECT, however, the previous restriction does not apply. The EJB engine will spawn a new entity bean instance for handling each new EJB client request. In other words, a new EJB instance gets allocated in this mode.
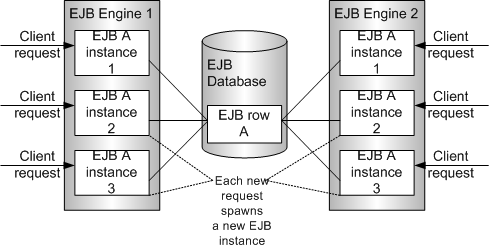
The following table lists all the advantages and disadvantages of selecting an engine mode.
[Table 8.2] The Three Engine Modes and Their Disadvantages and Advantages
| Classification | EXCLUSIVE | SINGLE | MULTIPLE |
|---|---|---|---|
| Can be used with clustering? | No | Yes | Yes |
| Can be used if external entity accesses the DB? | No | Yes | Yes |
| Efficiently uses database connections (ejbLoad() called rarely)? | Yes | No | No |
| Provides good options for time-consuming transactions? | No | No | Yes |
| Efficient mode for one engine to handle a single request? | Not applicable | Yes | No |
| Efficient for one engine to handle multiple, concurrent EJB requests? | Not applicable | No | Yes |
The following is the guidelines for choosing a mode.
-
If you expect a large number of requests for your entity bean, and if you also have a large number of EJB engines set up, use the SINGLE_OBJECT mode and cluster the beans across the engines.
-
If you expect a large number of requests for your entity bean, but if you only have a limited number of EJB engines set up, use the MULTIPLE_OBJECT mode and cluster the beans across the engines.
-
Another very important consideration when choosing a mode is the total time needed for a single transaction to complete. If this time is long, it is recommended to use the MULTIPLE_OBJECT mode.
-
If you expect a very moderate number of concurrent requests for your entity bean, use the EXCLUSIVE_ ACCESS mode and deploy the bean to only one EJB engine.
For information about EJB clustering, refer to an earlier chapter called "Chapter 6. EJB Clustering".
This subsection will show ways to optimize the ejbStore() method invocations.
The discussion in this subsection applies only to BMP and CMP 1.1 beans. CMP 2.0 uses a different approach to solve these problems.
The ejbStore() method is called by the EJB engine whenever it is decided that the bean’s state must be persisted to the back-end DB. Usually, saving to the back-end storage is performed after each transaction commitment or before the bean instance is inactivated.
If, however, during the course of a transaction, a bean’s state does not change, there is no reason to call the ejbStore() method.
Currently, the JEUS EJB engine cannot automatically detect whether a bean’s state has changed or not. Therefore, you as the developer or deployer must provide hints to aid the EJB engine decide whether to invoke ejbStore() or not. These hints are provided as a list of so-called non-modifying methods. A non-modifying method is essentially a read-only method (a getter method) that does not change the entity bean’s internal database-bound state in any way.
By looking at the list of non-modifying methods, the EJB engine can decide whether to invoke the ejb Store() method. If only non-modifying methods were executed during a transaction or when a bean is an activated state, the EJB engine skips the method call by assuming that it is not needed. This implies the improvement of the overall performance.
The following describes major features of CMP 1.1/2.0.
"8.2.1.2. ejbLoad() Persistence Optimization through Engine Mode Selection" and "8.2.2.1. ejbStore() Persistence Optimization through Non-Modifying Methods" talked about when the ejbLoad() and ejbStore() methods should be invoked. That discussion applied to both BMP and CMP type entity beans since both types use these methods.
In this sub-section, we will discuss how the engine-generated implementation of the ejbLoad() and ejbFind() methods can be optimized declaratively to enhance the overall performance.
This discussion only applies to CMP type beans (both the 1.1 and the 2.0 versions) since with this bean type, it is up to the EJB engine to actually define how to implement the ejbLoad() and ejbFind() methods. With BMP, on the other hand, the implementation and behavior of the methods are completely up to the developer.
When the EJB engine makes a call to the database to execute the ejbLoad() and ejbFind() methods of CMP, it can optimize its behavior by choosing between two possible engine sub-modes:
We shall only describe in which situation either mode should be used. The technical details of these two modes will not be covered here.
-
If your CMP bean is expected to do more reading operations than writing operations, always use the ReadLocking mode.
-
If, on the other hand, your CMP bean is expected to do more writing operations than reading operations, select the WriteLocking mode.
For CMP, the engine mode, the use of non-modifying methods described in the previous sub-sections, and the engine sub-mode described in this sub-section should be combined according to the set rules. See "8.4. Entity EJB Tuning" for a summary on configuring these parameters.
For CMP beans, you may also specify things such as java.sql.ResultSet fetch size and a setting called "init caching" that determines whether EJB bean instances should be pre-instantiated and cached when the EJB engine boots.
When the EJB engine is responsible for managing bean persistence (CMP), we must have a way of declaratively defining the mapping between entity bean instance fields and the actual tables and columns in the database. We must also specify the database source to be used. This information is encapsulated in the <schema info> element of the EJB XML configuration.
For CMP 1.1, this element also contains SQL fragments used as a base when the EJB engine generates CMP 1.1 finder methods.
In some cases, a developer may need to create an EJB instance without specifying a primary key. In these cases, the JEUS EJB engine can be configured to take responsibility for generating a unique primary key for the new EJB instance. The JEUS EJB engine provides this functionality through cooperation with the Database.
In JEUS, automatic primary key generation works for both CMP 1.1 and CMP 2.0 beans. With this feature, EJB may be easily developed regardless of the presence of a primary key.
The following describes how to use and apply the automatic primary key generation function.
-
The developer tends to call the create() method for the CMP1.1/CMP2.0 EJB without parameters. This means that the create() method in question does not receive a parameter that corresponds to the primary key of the EJB.
InitialContext ctx = new InitialContext(); BookHome bHome = (BJookHome) ctx.lookup("bookApp"); Book b = bHome.create(“JEUS EJB Guide”, ”Park Sungho”); // Start using “b”. . . .The above example looks up the BookHome EJB and calls the create() method with two arguments, whose values are "JEUS EJB Guide" and "Johan Gellner".The former argument represents the title of the new book, and the latter is the author's name. None of these arguments is appropriate for use as a primary key, as there may be several books with the same title, and several authors may have the same name.
To support this kind of client code, the EJB engine (let us call it A) must now somehow generate a unique primary key for the new Book instance, and it must do so under the assumption that several other EJB engines in an EJB cluster (B and C) may also try to achieve the same thing concurrently.
This means that somewhere, there must exist a single central storage, since each engine could try to fetch the cluster-wide unique primary key value. This storage is implemented in the form of a database table with a single row and a single column.
The single value in this row is the primary key counter (or primary key generator), which is constantly incremented after it is fetched by an EJB engine. In this way, the database always holds a new, unique primary key value that may be read and used by any EJB engine in the cluster.
-
After calling the create() method without providing a primary key, the EJB engine A accesses the central primary key storage (the primary key database). From this storage, it fetches the primary key value (which must always be an integer) and assigns it as the primary key of the new Book instance.
-
EJB engine A then increments the primary key field in the storage with a pre-determined value called the "key cache size". The pre-determined default value is 1, but it is recommended to use a value considerably larger than 1, e.g., 20.
If the key cache size is set to 20, the current EJB engine A will thus allocate (or cache) nineteen (20-1) unique values for its own use. Other EJB engines (B and C), that read the primary key value next, will read a value that is twenty more than the previously fetched primary key value.
This means that the engine does not need to fetch a new primary key value from the external primary key storage to create the following nineteen EJB instances inside the EJB engine without a primary key. This considerably helps improve the performance. It is simply sufficient for engine A to keep an internal counter to see when it has run out of allocated primary keys, forcing it to read a new value from the primary key storage. The internal counter is of course also used to directly generate a new unique primary key without involving the external storage.
Some general points to note about the automatic primary key generation feature are as follows:
-
Oracle and MS SQL Server databases support automatically generated primary key sequences.
We will discuss how to set up automatic primary key generation for these databases in the sub-sections, Automatic Primary Key Generation Support with Oracle DB and Automatic Primary Key Generation Support with MS SQL Server DB.
-
Non-Oracle and non-MS SQL Server databases need to be explicitly configured with a primary key table to hold the primary key value.
This is discussed in Automatic Primary Key Generation Support with Oracle DB.
-
The database that is to support this feature must support the TRANSACTION_SERIALIZABLE isolation level (configured for the JDBC calls). This guide assumes that it is supported.
-
A primary key field must still be defined for the EJB.
The primary key field must be of the type java.lang.Integer, it must not be a single key, and it must be declared in the EJB deployment DD.
We will now look at how to set up the DB properly.
Automatic Primary Key Generation Support for Oracle DB
Automatically generated primary keys in the Oracle DB use an Oracle-specific feature called sequence. To use primary key generation, you must setup a sequence generator for Oracle DB. Refer to the Oracle documentation for information about setting up a sequence generator.
The following is an example of the jeus-ejb-dd.xml file that generates a primary key in Oracle DBs.
[Example 8.1] Automatic Primary Key Generation Support for Oracle DB: <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<beanlist>
. . .
<jeus-bean>
. . .
<schema-info>
. . .
<data-source-name>MYORACLEDB</data-source-name>
<auto-key-generator>
<generator-type>
Oracle
</generator-type>
<generator-name>
my_generator
</generator-name>
<key-cache-size>
20
</key-cache-size>
</auto-key-generator>
</schema-info>
. . .
</jeus-bean>
. . .
</beanlist>
. . .
</jeus-ejb-dd>
In the previous example, we have specified the primary key generator type as "Oracle", <generator-name> is set to "my_generator" and <key-cache-size> is set to "20".
Note
The <key-cache-size> value must be set equal to the SEQUENCE INCREMENT value that was used to create the Oracle sequence generator.
The <data-source-name> value is used to select a particular Oracle DB. (In this case, "MYORACLEDB," a DB connection pool JNDI name defined in JEUSMain.xml)
For more information, refer to the "JEUS Server Guide".
Automatic Primary Key Generation Support for MS SQL Server DB
Setting up automatic primary key generation for MS SQL Server is rather simple. MS SQL Server automatically maintains a unique primary key value in the IDENTITY column.
The following is an example of jeus-ejb-dd.xml that generates a primary key in the MS SQL server DB.
[Example 8.2] Automatic Primary Key Generation Support for MS SQL Server DB: <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
<beanlist>
. . .
<jeus-bean>
. . .
<schema-info>
. . .
<data-source-name>MSSQLDB</data-source-name>
<auto-key-generator>
<generator-type>
MSSQL
</generator-type>
</auto-key-generator>
</schema-inboldfo>
</jeus-bean>
. . .
</beanlist>
</jeus-ejb-dd>
We thus see that it is sufficient to set the <generator-type> value to "MSSQL". The specific MS SQL database is specified in the <data-source-name> element.
Automatic Primary Key Generation Support for Other DB Types
If you want to use automatic primary key generation with databases other than Oracle and MS SQL Server, you must do the following:
-
Start by defining a new table in the Database. The table should have one row and at least one column with an arbitrary name. The value should initially be set to "0".
Primary Key generator table PrimKeyTable PrimKeyGeneratorColumn (The column to store the Primary Key value.) Row 1 0 (Initial value of the Primary Key) The previous sample table could be created with two SQL statements as follows:
CREATE table PrimKeyTable (PrimKeyGeneratorColumn int); INSERT into PrimKeyTable VALUES (0);
-
After completing step 1, modify the jeus-ejb-dd.xml file as follows:
[Example 8.3] Automatic Primary Key Generation Support for Other DB Types: <<jeus-ejb-dd.xml>>
<jeus-ejb-dd> . . . <beanlist> . . . <jeus-bean> . . . <schema-info> . . . <data-source-name>MYDB</data-source-name> <auto-key-generator> <generator-type> USER_KEY_table </generator-type> <generator-name> PrimKeyTable </generator-name> <sequence-column> PrimKeyGeneratorColumn </sequence-column> <key-cache-size> 20 </key-cache-size> </auto-key-generator> </schema-info> . . . </jeus-bean> . . . </beanlist> . . . </jeus-ejb-dd>In the previous example, we see how the type is set to 'USER_KEY_table', the key generator table name is set to 'PrimKeyTable', and the column used to store the primary key value is set to 'PrimKeyGeneratorColumn'. The key cache size is then set to 20.
The Database to use is specified in the <data-source-name> element. The value should match a DB connection pool <export-name> specified in the JEUSMain.xml file.
Note
For more information, refer to the "JEUS Server Guide".
The following describes major features of CMP 2.0.
In EJB 3.0 specification, the concept of CMP relationships is introduced to describe relationships in the underlying Database. The use of such relationships with CMP 2.0 beans requires that the deployer provides additional information in the JEUS-specific EJB DD.
CMP 2.0 type beans must have any findByXXXX() method, that is associated with an EJB-QL statement of the ejb-jar.xml deployment descriptor, declared in the home interface. JEUS supports a number of additions to the standard EJB-QL language. These additions may be used either in the ejb-jar.xml file or in an instant EJB QL request.
Refer to "8.3.3.3. Using JEUS EJB QL Extension" for a complete ejb-jar.xml example.
When you need to find a set of CMP beans within client code, you are usually forced to rely on the find ByXXXX() methods that were declared in the bean home interface. In some cases, when the search criteria is complex, the findByXXXX() method alone might not be sufficient.
For those cases, JEUS offers a non-standard interface that you may use in order to define your own EJB-QL select query directly inside the client code. This interface is called jeus.ejb.Bean.objectbase.EJBInstanceFinder, and it will be implemented by the entity bean's home interface when instant QL of the bean is enabled in the JEUS EJB DD. The interface contains one method, called findWithInstantQL (String ejbQLString), that allows you to forward the user's EJB-QL to the home interface. The method will return a java.util.Collection object of an EJB interface that matches the query.
See "8.2.3.3. Automatic Primary Key Generation" for an example of using this method. "Appendix B. Instant EJB QL API Reference" contains a formal description of this API.
The following are the configuration methods for JEUS entity EJB:
-
Configuration applied to all entity beans
-
The basic, shared settings
-
Object pool
-
Persistence optimizations including the entity cache settings
-
-
Configuration applied to CMP types only
-
CM persistence optimization
-
Schema information
-
-
Configuration applied to CMP 2.0 only
-
Relationships mapping
-
Instant EJB QL
-
All of these properties will be configured inside the <beanlist> tag using the <jeus-bean> tag in the JEUS EJB module DD file (jeus-ejb-dd.xml).
The following explains the basic settings applicable to all entity beans.
Refer to "Chapter 4. Common Characteristics of EJB" for information about basic EJB settings that apply to every kind of bean in JEUS. Those settings will also apply to all types of entity beans.
The following is an example of basic XML tags for a BMP entity bean:
[Example 8.4] Configuring the Basic Shared Settings for Entity EJB: <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<beanlist>
<jeus-bean>
<ejb-name>account</ejb-name>
<export-name>ACCOUNTEJB</export-name>
<local-export-name>
LOCALACCOUNTEJB
</local-export-name>
<export-port>7654</export-port>
<export-iiop>true</export-iiop>
. . .
</jeus-bean>
. . .
</beanlist>
. . .
</jeus-ejb-dd>
The following is an example of XML where object management is configured using the <jeus-bean> element, which is inside the <object-management> element.
[Example 8.5] Configuring Object Management : <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<beanlist>
<jeus-bean>
. . .
<object-management>
<bean-pool>
<pool-min>10</pool-min>
<pool-max>200</pool-max>
</bean-pool>
<connect-pool>
<pool-min>10</pool-min>
<pool-max>200</pool-max>
</connect-pool>
<passivation-timeout>10000</passivation-timeout>
<disconnect-timeout>1800000</disconnect-timeout>
</object-management>
</jeus-bean>
. . .
</beanlist>
. . .
</jeus-ejb-dd>
Descriptions for each element are as follows:
-
-
Determines the behavior of the bean instance pool.
-
Sub-elements are:
-
Element Description <pool-min> Initial number of bean instances created when a pool is initialized and the number of minimum bean instances that will be maintained in a pool(number of instances left in the pool during resizing). (default value: 0) <pool-max> Maximum number of bean instances for a pool that determines whether to save an instance in the pool after the instance is used. Since session beans can be generated up to max number, the number of requests that exceeds the max number may induce an EJB exception. However, an entity bean has no limit in generating bean instances, and it restricts the number of instances that will be maintained in a pool. (default value: 100) <resizing-period> Time interval for resizing a pool. Resizing means that unused bean instances are removed, and only minimum number of bean instances are left in the pool. (default value: 15 minutes, Unit: ms)
-
-
-
Determines the number of client and bean instance connections to keep (This option is not used in session beans).
-
Child elements are:
-
Element Description <pool-min> The minimum number of instances to be maintained in a pool during resizing. (default value: 0) <pool-max> Maximum number of connections for a pool that is used to determine whether to save a connection in the pool after the instance is used. (default value: 100) <resizing-period> Time interval for resizing a pool. Resizing means that unused bean instances are removed, and only minimum number of bean instances are left in the pool. (default value: 15 minutes, Unit: ms)
-
-
-
The maximum number of bean instances to be created. This applies only for entity beans. This value is used to efficiently configure connections between internal client session data and EJB.
-
The default value is 10000.
-
-
-
Timeout interval for inactivating a bean in the EJB engine, for which there are no client requests during this time.
If no client request is made for a bean during the timeout period, that bean instance is subject to passivation. The number of bean instances in memory that will be subject to passivation can be adjusted with <persistence-optimize> / <entity-cache-size> tags.
-
Since there is no entity cache for a stateful session bean, it is subject to passivation If no client request is made for a bean during this time. An entity bean, however, remains in the entity cache before becoming subject to passivation. The interval for checking for beans to passivate depends on the <resolution> value set in EJBMain.xml (default value: 5 minutes).
If passivation is executed, the bean instance is removed from memory, and its state is archived in a file or database.
-
These settings can be configured at several locations, and their priorities are as follows:
-
Applied to only certain session beans: <passivation-timeout> of jeus-ejb-dd.xml.
-
Applied to all stateful session beans: system property jeus.ejb.stateful.passivate.
-
Applied to all EJB beans (all entity beans and session beans): system property jeus.ejb.all.passivate.
If no setting exists, default value is 300,000ms (5 minutes).
-
-
-
-
Used for disconnecting a connection between the client and a bean instance if there are no client requests during the timeout period. This means that connections to clients and instances are disconnected and returned to a connection pool.
Therefore, a client can no longer make a request through this connection. Bean instances in use are removed, or returned to a bean pool if the bean pool is used.
-
These settings can be configured at several locations, and their priorities are as follows.
-
Applied to only certain session beans: <disconnect-timeout> of jeus-ejb-dd.xml.
-
Applied to all entity beans: system property jeus.ejb.stateful.disconnect.
-
Applied to all EJB beans (all entity beans and session beans): system property jeus.ejb.all.disconnect. The time period used when comparing with <passivation-timeout> and <disconnect-timeout> are both measured from the time of last access to the bean instance. This means that you should set the <disconnect-timeout> period to a value considerably larger than the <passivation-timeout> value. The <passivation-timeout> value should be larger than the resolution specified in the EJBMain.xml file.
If the timeout value is too large, a lot of instances, that are inactivated, end up remaining in the memory for a long period (more than 10 minutes or when timeout expires), wasting system resources. Too short of a timeout period (several seconds), however, may undermine the performance due to frequent inactivations/activations, and has the risk of losing the session data.
-
-
Optimizations for persistence method invocation are configured in DD of each bean of the jeusejb- dd.xml file.
The following is an XML example in which persistence of ejbLoad() and ejbStore() methods is configured in the <persistence-optimize> element inside the <jeus-bean> element.
[Example 8.6] Configuring ejbLoad() and ejbStore() Persistence Optimization: <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<beanlist>
. . .
<jeus-bean>
. . .
<persistence-optimize>
<engine-type>SINGLE_OBJECT</engine-type>
<non-modifying-method>
<method-name>myBusinessmethod</method-name>
<method-params>
<method-param>
java.lang.String
</method-param>
<method-param>int</method-param>
<method-param>double</method-param>
</method-params>
</non-modifying-method>
<non-modifying-method>
<method-name>myBusinessmethod2</method-name>
<method-params>
<method-param>
java.lang.String
</method-param>
<method-param>int</method-param>
</method-params>
</non-modifying-method>
<entity-cache-size>500</entity-cache-size>
<update-delay-till-tx>
false
</update-delay-till-tx>
<include-update>
true
<include-update>
</persistence-optimize>
</jeus-bean>
. . .
</beanlist>
. . .
</jeus-ejb-dd>
Details for each element are as follows:
| Element | Description |
|---|---|
| <engine-type> | Set to one of the following: For more information about the differences between these types, refer to "8.2. Major Functions".
|
| <non-modifying-method> | Provides hints to the EJB engine when it is trying to decide whether the ejbStore() method should be invoked. This element does not apply to CMP 2.0 bean. |
| <entity-cache-size> | Determines the size of the internal cache for entity bean instances that are subject to inactivation. The size is the maximum number of entity bean instances that can be held in the cache. The higher the value the better the performance, but more system resources (e.g., main memory) will be used. (default value: 2,000) |
| <update-delay-till-tx> | A Boolean value that determines whether EJB data updates/ inserts should be postponed until the ongoing transaction is committed. If this value is set to "false", all inserts/updates will be performed immediately, ensuring that any read operations within the same transaction will see the changes dynamically before the commit() call. This, however, also results in a lower performance. (default value: true) |
| <include-update> | Specifies the default value for the <schema-info><jeus-query><include-updates> setting. If this value is set to "true", the updates generated while the finder method is called are committed, ensuring that any read operations will see the updated information while the execution of the finder method. (default value: false) |
The following explains applicable settings for CMP 1.1/2.0.
For CMP 1.1 and 2.0 beans, we may configure optimizations for ejbLoad() implementation persistence. More detailed information was described in "8.3.1.3. Configuring ejbLoad() and ejbStore() Persistence Optimization".
The following is an XML example in which persistence of ejbLoad() and ejbFind() CM is configured through the <cm-persistence-optimize> element inside the <jeus-bean> element.
[Example 8.7] Configuring ejbLoad() and ejbFind() CM Persistence Optimization: <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<beanlist>
. . .
<jeus-bean>
. . .
<cm-persistence-optimize>
<subengine-type>WriteLocking</subengine-type>
<fetch-size>80</fetch-size>
<init-caching>true</init-caching>
</cm-persistence-optimize>
</jeus-bean>
. . .
</beanlist>
. . .
</jeus-ejb-dd>
Details for each element are as follows:
In CMP 1.1/2.0 you must configure the schema information, which contains mappings from EJB instance fields to database tables and columns.
The following is an XML example of DB schema information configured in the <schema-info> element inside the <jeus-bean> element.
[Example 8.8] Configuring DB Schema Information: <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<beanlist>
. . .
<jeus-bean>
. . .
<schema-info>
<table-name>ACCOUNT</table-name>
<cm-field>
<field>id</field>
<column-name>ID</column-name>
<type>NUMERIC</type>
<exclude-field>false</exclude-field>
</cm-field>
<cm-field>
<field>customer_addr</field>
<column-name>customer_address</column-name>
<type>VARCHAR(30)</type>
<exclude-field>false</exclude-field>
</cm-field>
<creating-table>
<use-existing-table/>
</creating-table>
<deleting-table>true</deleting-table>
<prim-key-field>
<field>id</field>
</prim-key-field>
<jeus-query>
<method>
<method-name>findByAddress</method-name>
<method-params>
<method-param>java.lang.String</method-param>
</method-params>
</method>
<sql>customer_address=?</sql>
</jeus-query>
<jeus-query>
<query-method>
<method-name>findByTitle</method-name>
<method-params>
<method-param>java.lang.String</method-param>
</method-params>
</query-method>
<jeus-ql>
SELECT OBJECT(b) FROM Book b
WHERE b.title = ?1 ORDERBY b.price
</jeus-ql>
</jeus-query>
<db-vendor>oracle</db-vendor>
<data-source-name>MYDB</data-source-name>
</schema-info>
. . .
</jeus-bean>
. . .
</beanlist>
. . .
</jeus-ejb-dd>
Details for each element are as follows:
-
-
The name of the relational database table to which the current EJB should be mapped to.
-
If not set, an arbitrary table name will be set using the <EJB module name> and <EJB name> elements.
-
Due to certain restrictions on the length of the table names in some DBMSs, only 15 characters are allowed for a table name.
-
-
-
The container managed field mappings exist for each column-to-field relationships.
-
Child elements are:
-
Element Description <field> Specifies the name of an EJB field to which the column should be mapped to. <column-name> The same as it appears in the given database table. (If not set, the name of the EJB field is used.) <type> The column data type from the database's point of view.
(e.g., "VARCHAR(25)", "NUMERIC", etc.)
If this element is not specified, a default type will be used (the type used will vary according to the DB vendor). The default mappings are covered in "Appendix A. Basic Java Type and Database Field Mappings". You may also use the values "BLOB" (Binary Large Object) and "CLOB" (Character Large Object) with Oracle DBMSs. These are types used for the efficient storage of large pieces of data, such as images.
-
CLOB(Character Large Object): correspond to java.lang.String fields
-
BLOB(Binary Large Object): corresponds to any serializable field types.
<exclude-field> If enabled, causes the specified field not to be mapped and included in the persistence management. This option works for CMP 2.0 beans only. It is included for migration purposes. (default value: false) -
-
-
-
Checks whether a table to be used by a bean exists in the Database when the bean starts. An existing table is used, a new table is created, or an error occurs according to the child elements.
-
Checks whether a bean contains a table with the name specified in <schema-info>/<table-name>, if the fields specified in <schema-info>/<cm-field> exist, and if foreign keys specified in <ejb-relation-map>/<jeus-relationship-role>/<column-map> exist for a bean that manages relationships.
-
Child elements are:
-
Element Description <use-existing-table> Only create the table if it does not already exist, otherwise use the existing table. <force-creating-table> Delete the table and generate a new table, even if the table already exists in the Database. When these child elements are not specified and if a table already exists, an error will occur. If a table does not exist, a new table will be generated.
-
If there are no child elements configured, the "-Djeus.ejb.checktable" setting in an MS JVM parameter is used to determine whether to check for the table.
Value Description true An error occurs if the table is not found during the check.
(Default value)
false Since table check is not performed when a bean is started, an error may occur when trying to use the table.
-
-
-
If enabled, causes the given table to be removed from the Database when the EJB module is undeployed.
-
Since this option should be used with caution, it has to be separately configured as a JEUS system property to prevent any configuration errors. It only works when the Command setting in the JEUSMain.xml file is set to the value, "-Djeus.ejb.enable.configDeleteOption=true".
In addition, the <deleting-table> setting is hardly used without the <creating-table> setting. Hence it is implemented so that the <deleting-table> setting does not execute without the <creating-table> setting.
-
-
-
This is optionally used for when a composite key is used as the primary key. It can only be used if a primary key class implemented by a user for a compound key is specified in ejb-jar.xml/<prim-key-class>. Basically, all public fields defined in <prim-key-class> are configured as a primary key, but, if the user wants to configure it by selecting a specific field, this list must be configured.
-
Make sure not to confuse the following elements.
-
Composite field key
Element Description ejb-jar.xml/<prim-key-class> A primary key class implemented by the user. (Required) ejb-jar.xml/<primkey-field> Cannot be declared. The type defined in <prim-key-class> cannot be mapped to a single field name, because it includes multiple fields.
(Optional)
jeus-ejb-dd.xml/<prim-key-field> Declares a list of fields to be configured as a primary key, instead of configuring all public fields of a primary key class as a primary key. (Optional)
-
Single field key
Element Description ejb-jar.xml/<prim-key-class> A type of ejb-jar.xml/<primkey-field>, such as java.lang.String, java.lang.Integer, etc. (Required) ejb-jar.xml/<primkey-field> A field name of an entity bean for a primary key. A field name defined in <primkey-field> and a type defined in <prim-key-class> must be mapped to a name and type defined by an entity bean class, respectively. (Optional) jeus-ejb-dd.xml/<prim-key-field> Only declared when selecting one or more among multiple fields. (Optional)
-
-
-
-
For CMP 1.1, you must specify SQL statements for any finder methods that should be implemented by the EJB engine.
In CMP 2.0, this element overrides the EJB QL configured in ejb-jar.xml. The <jeus-query> setting enables query methods(findXXX()) to use the standard EJB QL and JEUS EJB QL extensions. This is similar to the <query> element of ejb-jar.xml. For more information about the <query> element, refer to "8.3.3.3. Using JEUS EJB QL Extension". This element mainly exists for easier migration from BEA WebLogic application server to JEUS 7.
-
SQL statement and the name and arguments of the finder method, that will use the SQL statement, must be specified to define SQL. This SQL statement is used when generating the finder method.
The specified text must only include the part after the "where" keyword. The rest is given implicitly. In the SQL string you may specify "?" characters that will be substituted by the values of the finder method's arguments. You can use the WHERE clause syntax of ANSI SQL, which includes the "where" keyword.
-
If <include-updates> is set to "true", any commitments done up until invoking the finder method will be written to the database so that the finder method can see the changes.
-
-
-
Specifies the vendor of the Database you use for this bean.
The vendor name is used by the EJB engine to make some vendor-specific optimizations. The value you specify here, however, might or might not have an actual impact on the performance. A list of vendor names that you can use are specified in "Appendix A. Basic Java Type and Database Field Mappings". Oracle is a commonly used name.
-
This value is also used to determine the correct mapping between Java objects and DB field types defined by the vendor in question.
-
-
-
Specifies the JNDI name of the DB connection pool used to connect to the Database. This connection pool is usually configured in JEUSMain.xml and is running on the JEUS MS JVM.
-
-
-
Contains child elements for setting up automatic primary key generation for CMP 2.0 beans.
-
Refer to "8.2.3.3. Automatic Primary Key Generation" for information about configuring this element.
-
The following explains settings applicable to CMP 2.0.
Configuring relationship mapping is done for the following cases.
-
One-to-one/One-to-many Relationship Mapping
-
Many-to-many Relationship Mapping
One-to-one/One-to-many Relationship Mapping
When setting up a One-to-one/one-to-many relationship between two beans, you must configure the <ejb-relation-map> tag.
The following is an example of a many-to-one (= one-to-many) relationship between two beans in a relationship called employee-manager. It is configured in the <ejb-relation-map> tag.
[Example 8.9] Configuring One-to-one/One-to-many Relationship Mapping: <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<ejb-relation-map>
<relation-name>employee-manager</relation-name>
<jeus-relationship-role>
<relationship-role-name>employee-to-manager</relationship-role-name>
<column-map>
<foreign-key-column>manager-id</foreign-key-column>
<target-primary-key-column>man-id</target-primary-key-column>
</column-map>
</jeus-relationship-role>
</ejb-relation-map>
. . .
</jeus-ejb-dd>
Descriptions for each element are as follows:
-
Configure two JEUS relationship roles for each direction. The information required for each relationship role is:
-
<relationship-role-name>
Defined in the <ejb-relationshiprole- name> element.
-
<column-map>
Contains two child tags: <foreign-key-column> and <targetprimary- key-column>.
Element Description <foreign-key-column> The name of the column that acts as a foreign key in a relationship. <target-primary-key-column> The primary key column of a table to which the foreign key column is to be mapped. Several column-to-column mappings may be specified if the keys are composed of multiple columns.
-
In the previous XML example, a foreign key column called "manager-id" in the employee table is mapped to the primary key column of the manager table in order to establish many-to-one employee-to-manager relationship.
One-to-one mappings would work in a completely analogous manner. Just remember that for one-to-one, the primary key column and the foreign key column may exist in either table. For one-to-many, the table on the many side must contain the foreign key column.
Many-to-many Relationship Mapping
In order to establish a many-to-many relationship between two beans, you must provide the <table-name> and <jeus-relationship-role> elements in addition to the information given for one-to-one/one-to-many relationships.
The following is an example of configuring a many-to-many relationship named student-course:
[Example 8.10] Configuring Many-to-many Relationship Mapping: <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<ejb-relation-map>
<relation-name>student-course</relation-name>
<table-name>STUDENTCOURSEJOIN</table-name>
<jeus-relationship-role>
<relationship-role-name>student</relationship-role-name>
<column-map>
<foreign-key-column>
student-id <!--This column in join table-->
</foreign-key-column>
<target-primary-key-column>
stu-id <!--This column in student table-->
</target-primary-key-column>
</column-map>
</jeus-relationship-role>
<jeus-relationship-role>
<relationship-role-name>course</relationship-role-name>
<column-map>
<foreign-key-column>
course-id <!--This column in join table-->
</foreign-key-column>
<target-primary-key-column>
cou-id <!--This column in course table-->
</target-primary-key-column>
</column-map>
</jeus-relationship-role>
</ejb-relation-map>
. . .
</jeus-ejb-dd>
Descriptions for each element are as follows:
In the above example, notice how two JEUS relationship roles are used. Each role declares the mapping between one of two columns of the join table and the primary key column of a table that is used by an EJB.
In order to enable instant EJB QL queries on the client-side, it is sufficient to simply set the <enable-instant-ql> element in the JEUS EJB DD to "true." For more information, refer to "Appendix B. Instant EJB QL API Reference".
[Example 8.11] Configuring Instant EJB QL: <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<beanlist>
. . .
<jeus-bean>
. . .
<enable-instant-ql>true</enable-instant-ql>
</jeus-bean>
. . .
</beanlist>
. . .
</jeus-ejb-dd
The following describes EJB QL extension related to JEUS CMP.
The extensions include new keywords, subqueries, ResultSet returned by the ejbSelect() method, aggregate functions, various EJB QL queries, and the GROUP BY keyword.
The home interface must be associated with an EJB-QL statement of the ejb-jar.xml in the findByXXX() and ejbSelectXXX() methods of CMP 2.0 beans. JEUS includes a couple of additions to the standard EJB-QL language.
These additions may be used either in the ejb-jar.xml file or in an instant EJB QL request. Refer to "8.5. CMP 2.0 Entity Bean Example" for a complete ejb-jar.xml example with some examples.
Caution
The EJB QL extensions presented in this section are not supported by standard EJB 2.0 QL, and using them makes your EJB applications non-portable according to the J2EE standard. This means that you can not seamlessly deploy an EJB component, which uses any of these extensions, to another J2EE server. Since most of EJB QL extensions in JEUS work like the standard SQL, refer to SQL for more details.
JEUS EJB QL Extension Keyword Additions
The following non-standard keywords may be used in any EJB QL statements within JEUS:
JEUS EJB QL Extension Subquery
A JEUS EJB QL subquery is an EJB QL query that is nested within the WHERE clause of a parent EJB QL query. This is similar to the relationship between SQL queries and subqueries.
The following example illustrates this concept by constructing a nested EJB QL query that selects all employees with an above-average salary:
SELECT OBJECT(e)
FROM EmployeeBean AS e
WHERE e.salary >
(SELECT AVG(e2.salary)
FROM EmployeeBean AS e2)
-
Return Type
A return type from a JEUS EJB QL query can be:
-
A single value or a collection of values corresponding to the <cmp-field> setting (e.g., e.salary in the previous example).
-
A single return value generated through an aggregate function (e.g., MAX(e.salary)).
-
A cmp-bean with a simple primary key (not compound primary key). Example: SELECT OBJECT(emp).
-
-
The Operands of Comparison Operators.
JEUS EJB QL supports the use of subqueries as the operands of comparison operators. JEUS EJB QL supports the following comparison operators:
-
[NOT] IN, [NOT] EXISTS, [NOT] UNIQUE )
-
<, >, <=, >=, =, <>
-
Combination of the previous operators and the following three operators: ANY, ALL, and SOME.
-
The following example would select all employees who are not managers.
SELECT OBJECT(employee)
FROM EmployeeBean AS employee
WHERE employee.id NOT IN
(SELECT employee2.id
FROM ManagerBean AS employee2)
Following is an example of the NOT EXISTS operator that tests for the non-existence of a subquery result. ("NOT" may be removed to test for the existence of the result)
SELECT OBJECT(cust)
FROM CustomerBean AS cust
WHERE NOT EXISTS
(SELECT order.cust_num
FROM OrderBean AS order
WHERE cust.num = order.cust_num)The previous query retrieves all customers that have not placed an order.
The last query of the previous example is called a correlated query, since the evaluation of the nested subquery requires access to a variable defined by the parent query. Queries without such dependencies are called uncorrelated.
The following example shows the use of the UNIQUE operator. This operator is used for testing for duplicate rows in a result set. It returns TRUE if the result set has zero or one row, or if every row is unique. Adding NOT to this operator achieves the opposite.
SELECT OBJECT(cust)
FROM CustomerBean AS cust
WHERE UNIQUE
(SELECT cust2.id FROM CustomerBean AS cust2)
Following is an example of the > operator, which, like all simple arithmetic operators, may be used with a single value result obtained from the subquery to the right of the operator:
SELECT OBJECT(employee)
FROM EmployeeBean AS employee
WHERE employee.salary >
(SELECT AVG(employee2.salary)
FROM EmployeeBean AS employee2)The previous JEUS EJB QL query would return all employees that earn more than the average salary.
Note that if ANY, ALL, and SOME operators are not used, the nested subquery must produce a single value result (the average salary in this case). The operators ANY, ALL, and SOME are used with subqueries that return more than one value. These operators follow the following rules:
-
<Operand> <arithmetic operator> ANY <subquery>
Yields "true" if at least one value in the subquery return set yields "true" for the given operand and arithmetic operator.
-
<Operand> <arithmetic operator> SOME <subquery>
Synonym to "ANY" (see above).
-
<Operand> <arithmetic operator> ALL <subquery>
Yields "true" if all values in the subquery return set yield "true" for the given operand and arithmetic operator.
Note
When you use the characters ">" and "<" inside an XML DD file, you must enclose them within CDATA constructs. Otherwise, the XML parser will mistaken these characters for XML tag symbols.
[Example 8.12] Typing ">" and "<" inside an XML DD File: <<ejb-jar.xml>>
. . .
<query>
<description>method finds large orders</description>
<query-method>
<method-name>findLargeOrders</method-name>
<method-params></method-params>
</query-method>
<ejb-ql>
<![CDATA[SELECT OBJECT(o) FROM Order o WHERE o.amount > 1000]]>
</ejb-ql>
</query>
. . .
JEUS EJB QL Extension ResultSet
JEUS EJB engine supports ejbSelect() queries that return a multi-column java.sql.ResultSet object. This means that you may specify a comma-separated list of target fields within the SELECT clause of the ejbSelect() method.
SELECT employee.name, employee.id, employee.salary FROM EmployeeBean AS employee
The previous query would create a java.sql.ResultSet object that consists of the name, ID, and salary of all EmployeeBean instances.
The ResultSet would contain a set of rows with the columns "name," "ID," and "salary." Each row in the ResultSet would represent a matching entity EJB instance. ResultSets can only be used in this way to return cmp-field values, and not beans or relationship fields.
Note
When you retrieve an object of the type java.sql.ResultSet through the ejbSelect() method call and complete all necessary tasks, you must call the ResultSet.close() method. The close() method will not be called by the EJB engine.
JEUS EJB QL Extension Dynamic Query
JEUS EJB QL supports creating EJB QL queries programmatically. This is accomplished through the Instant EJB QL function. This short section explains the fundamentals of programming instant EJB QL with JEUS CMP 2.0.
The following code-snippet shows the use of instant EJB QL of the CMP 2.0 Home Interface. The code is on the client-side. For this code to work, instant EJB QL has to be correctly configured on the CMP bean in question. This was described in "8.3. Entity EJB Configuration".
import jeus.ejb.Bean.objectbase.EJBInstanceFinder; import java.util.Collection; . . . Context initial = new InitialContext(); Object objref = initial.lookup("emp"); EmpHome home = (EmpHome) PortableRemoteObject.narrow(objref, EmpHome.class); EJBInstanceFinder finder = (EJBInstanceFinder) home; java.util.Collection foundBeans = finder.findWithInstantQL (“<EJB QL query sentence>”); // Use foundBeans collection… . . .
The EJB QL query statement in the example should be substituted with a complete EJB QL statement without any arguments (i.e., “?” is not allowed). See "Appendix B. Instant EJB QL API Reference" for full information about this API.
JEUS EJB QL Extension GROUP BY Keyword
JEUS EJB QL supports the GROUP BY and GROUP BY..HAVING keywords. They work as follows:
-
<SELECT statement> GROUP BY <grouping column(s)>
The SELECT statement is executed, producing a set of rows. The GROUP BY statement then inspects this set for the column(s) included in the <grouping column(s)> list. All rows of this column(s) with the same value are merged into one row, essentially throwing away duplicate values of the column.
SELECT employee.departmentName FROM EmployeeBean AS employee GROUP BY employee.departmentNameThe previous query would yield a list with all unique departmentNames from the EmployeeBean table.
-
<SELECT statement> GROUP BY <grouping column(s)> HAVING <condition>
Statements of this form will work the same way as described in the previous example, but with one addition: only the column groups that satisfy the <condition> setting are included.
SELECT employee.departmentName FROM EmployeeBean AS employee GROUP BY employee.departmentName HAVING COUNT(employee.departmentName) >= 3
The previous query would thus return a list of all unique departmentNames with more than 2 EmployeeBean instances (i.e., all departments with 3 or more employees).
Example)
If you run the EJB QL query on the [Table 8.3] data, you would get the following [Table 8.4].
[Table 8.3] Original EJB Fields for EmployeeBean Instances
| id | departmentName |
|---|---|
| johnsmith | R&D |
| peterwright | R&D |
| lydiajobs | R&D |
| catherinepeters | Marketing |
This is the result of the HAVING condition that includes
only column groups with at least three rows. Refer to SQL reference
material for complete information about the GROUP BY and GROUP BY
HAVING keywords.
Note
In JEUS EJB QL, you may use the GROUP BY and GROUP BY HAVING statements in subqueries or top-level queries. In the latter case, a collection of java.lang.String objects are returned. Top-level GROUP BY and GROUP BY HAVING statements cannot return bean objects.
It is possible to specify at which point in time the EJB data should be written to the backend Database when EJB is created in CMP.
| Method | Description |
|---|---|
| ejbCreate | Insert new EJB data after completing the ejbCreate() call but before calling the ejbPostCreate() method. |
| ejbPostCreate | Insert new EJB data after completing the ejbCreate() and ejbPostCreate() calls. This is used as the default value. |
The following Database insert delay setting is configured in the <database-insert-delay> element, which is inside the <jeus-bean> element of jeus-ejb-dd.xml.
[Example 8.13] Configuring DB Insert Delay: <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<beanlist>
. . .
<jeus-bean>
. . .
<database-insert-delay>ejbCreate</database-insert-delay>
. . .
</jeus-bean>
. . .
</beanlist>
. . .
</jeus-ejb-dd>
This chapter summarizes and elaborates further on what has already been mentioned about performance tuning for entity EJBs in JEUS.
The tuning tips offered here are in addition to the entity bean tuning tips outlined in other chapters (e.g., "Chapter 4. Common Characteristics of EJB" and the Object Management section in "Chapter 7. Session Bean").
The following explains performance tuning for all entity beans.
-
Selecting the Main Engine Mode and Whether or not to Cluster
-
Configuring the Entity Cache Size - Configuring the DB Vendor
Choosing Main Engine Mode and Whether or not to Cluster
The following table outlines the rules that are used to determine the <engine-type> setting and deciding whether to cluster the EJB across several EJB engines.
[Table 8.5] Selecting Entity Bean Engine Type and Whether to Use Clustering
| Request Amount per Bean | Many EJB engines on multiple CPUs | A small number of EJB engines on multiple CPUs | Single EJB engine on single CPU |
|---|---|---|---|
| Frequently | Cluster EJB and use SINGLE_OBJECT mode. | Cluster EJB and use MULTIPLE_ OBJECT mode. | Try to use more EJB engines. Otherwise, do not cluster but use MULITPLE_OBJECT mode. |
| Moderately | Cluster EJB and use SINGLE_OBJECT mode. | Cluster EJB and use MULTIPLE_ OBJECT mode. | Do not cluster, use EXCLUSIVE_ ACCESS mode. |
| Rarely | Do not cluster, use EXCLUSIVE_ ACCESS mode. | Do not cluster, use EXCLUSIVE_ ACCESS mode. | Do not cluster, use EXCLUSIVE_ ACCESS mode. |
Of course, if the entity bean’s back-end data in the Database is modified by an external non-WAS component, you will be forced to use the SINGLE_OBJECT or MULTIPLE_OBJECT mode. Also, remember that for fail over to work, you need to cluster your beans.
The final consideration that needs to be made when choosing either the SINGLE_OBJECT or MULTIPLE_ OBJECT mode is whether the bean(s) in question have a long transaction processing time. This refers to the average time period between transaction start and commit for a bean. If this time is very long, it is highly recommended to use the MULTIPLE_OBJECT mode for the concurrency feature. On the other hand, consider using the SINGLE_OBJECT mode for short transactions.
If the previous rules are followed, the EJB engine will invoke the ejbLoad() method in an optimal way.
Note
The terms "frequently," "moderately," and "rarely" are not clearly defined in the previous table. Some intuition and a lot of testing might be needed to find the optimal setting for a given scenario.
Setting the Entity Cache Size
As we have seen, the entity cache acts as a storage for entity bean instances that have been inactivated. Instances will be drawn from this cache when an entity bean is reactivated.
If you set the <entity-cache-size> element to a large value (several hundred instances or so), the performance will be enhanced since new entity bean instances need not be created when inactivated beans are re-activated. However, if memory conservation is the most important issue, be sure to set this value low or disable it altogether (set the size to “0” in order to disable the entity cache).
Setting the DB Vendor
You must properly configure the <db-vendor> element. In some cases, the EJB engine can optimize database connections for products from other vendors, like Oracle. For more information on DBMS vendor names that can be used in this tag, refer to "Chapter 11.Configuring domain.xml EJB Engine" of the "JEUS XML Reference".
The following explains tuning methods applicable to BMP and CMP 1.1.
Registering Non-modifying Methods
All entity bean business methods, that do not alter the state information in the back-end database, should be registered through the <non-modifying-method> element of the JEUS EJB module DD. This allows the EJB engine to optimize the ejbStore() calls. Such tuning method only applies to BMP and CMP 1.1 beans.
The following explains tuning methods applicable to CMP 1.1/2.0.
Choosing Engine Sub-mode
The <subengine-type> element enables EJB engine to optimize the ejbLoad() and ejbFInd() methods when using CMP beans. CMP beans adhere to the following rules when setting the <subengine-type> element.
-
If your CMP bean is expected to do more reading than writing operations, always use the ReadLocking mode.
-
If your CMP bean is expected to do more writing than reading operations, select the WriteLocking or WriteLockingFind mode.
Setting the Fetch Size
The <fetch-size> element of CMP beans should be set high if you prioritize high performance at the expense of wasting system memory: a large value would imply a more efficient use of network connections since large amount of data is read in each time. However, this also requires the EJB engine to cache a large amount of data, as wasting system resources, and therefore increases the latency for each individual call.
The reverse is true if you prioritize conservation of system memory and is prepared to sacrifice some (network) performance: in this case, set the value relatively low. The default fetch size is "10". A value of "100" would, in most cases be considered rather high while a value less than "10" is quite low.
Configuring Initial Caching
If you are prepared to sacrifice system memory for higher runtime performance, set the <init-caching> value of CMP beans to "true". This will create entity bean instances from all Database rows that are read during the boot-time of the EJB. This will result in a much more time-consuming engine boot sequence but much quicker first-time accesses.
The reverse is true if either system memory conservation or engine boot-time is the main concern, in which case init caching should be set to "false". If a Database table that is mapped to an EJB contains a lot of rows (more than several hundreds or thousands of rows, etc.), the <init-caching> setting will need to be set to false. On the other hand, if the EJB is read-only (implying that ejbLoad() will only have to be called once), it is highly recommended to set it to "true".
In order to show how the EJB code, standard EJB DD, and JEUS-specific DD work together, we will show a complete example of a CMP 2.0 bean called the Book EJB, which models the concept of a book.
This section is uncommented and is only meant to illustrate how a CMP 2.0 bean might be configured in jeus-ejb-dd.xml. In order to deploy this example, package it first and then deploy it as an EJB. For more information about using EJB QL in JEUS ejb-jar.xml, refer to "Chapter 3. EJB Module".
Remote Interface
[Example 8.14] Remote Interface : <<Book.java>>
package test.book;
import java.rmi.RemoteException;
import javax.ejb.EJBObject;
public interface Book extends EJBObject {
public String getTitle() throws RemoteException;
public void setTitle(String title) throws RemoteException;
public String getAuthor() throws RemoteException;
public void setAuthor(String author) throws RemoteException;
public double getPrice() throws RemoteException;
public void setPrice(double price) throws RemoteException;
public String getPublisher() throws RemoteException;
public void setPublisher(String publisher)
throws RemoteException;
public String toBookString() throws RemoteException;
}
Home Interface
[Example 8.15] Home Interface : <<BookHome.java>>
package test.book;
import java.rmi.RemoteException;
import javax.ejb.CreateException;
import javax.ejb.FinderException;
import javax.ejb.EJBHome;
import java.util.*;
public interface BookHome extends EJBHome {
public Book create(String code, String title, String author,
double price, String publisher)
throws CreateException, RemoteException;
public Book findByPrimaryKey(String code)
throws FinderException, RemoteException;
public Collection findByTitle(String title)
throws FinderException, RemoteException;
public Collection findInRange(String from, String to)
throws FinderException, RemoteException;
public Collection findAll()
throws FinderException, RemoteException;
}
Bean Implementation
[Example 8.16] Bean Implementation : <<BookEJB.java>>
package test.book;
import javax.ejb.EntityBean;
import javax.ejb.EntityContext;
public abstract class BookEJB implements EntityBean {
public String ejbCreate(String code, String title,
String author, double price, String publisher) {
setCode(code);
setTitle(title);
setAuthor(author);
setPrice(price);
setPublisher(publisher);
return null;
}
public void ejbPostCreate(String code, String title,
String author, double price, String publisher) {}
public abstract String getCode();
public abstract void setCode(String code);
public abstract String getTitle();
public abstract void setTitle(String title);
public abstract String getAuthor();
public abstract void setAuthor(String author);
public abstract double getPrice();
public abstract void setPrice(double price);
public abstract String getPublisher();
public abstract void setPublisher(String publisher);
public String toBookString() {
return getCode() + "- [" + getTitle() + "] by " +
getAuthor() + " | " + getPrice() + " | " +
getPublisher();
}
public BookEJB() {}
public void setEntityContext(EntityContext ctx) {}
public void unsetEntityContext() {}
public void ejbLoad() {}
public void ejbStore() {}
public void ejbActivate() {}
public void ejbPassivate() {}
public void ejbRemove() {}
}
Java EE EJB DD
[Example 8.17] Java EE EJB DD : <<ejb-jar.xml>>
<?xml version="1.0"?>
<ejb-jar version="3.1" xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-Instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/ejb-jar_3_1.xsd">
<enterprise-Beans>
<entity>
<ejb-name>BookBean</ejb-name>
<home>test.book.BookHome</home>
<remote>test.book.Book</remote>
<ejb-class>test.book.BookEJB</ejb-class>
<persistence-type>Container</persistence-type>
<prim-key-class>java.lang.String</prim-key-class>
<reentrant>false</reentrant>
<cmp-version>2.x</cmp-version>
<abstract-schema-name>Book</abstract-schema-name>
<cmp-field><field-name>code</field-name></cmp-field>
<cmp-field><field-name>title</field-name></cmp-field>
<cmp-field><field-name>author</field-name></cmp-field>
<cmp-field><field-name>price</field-name></cmp-field>
<cmp-field><field-name>publisher</field-name></cmp-field>
<primkey-field>code</primkey-field>
<query>
<query-method>
<method-name>findByTitle</method-name>
<method-params>
<method-param>
java.lang.String
</method-param>
</method-params>
</query-method>
<ejb-ql>
SELECT OBJECT(b) FROM Book b
WHERE b.title = ?1 ORDERBY b.price
</ejb-ql>
</query>
<query>
<query-method>
<method-name>findInRange</method-name>
<method-params>
<method-param>
java.lang.String
</method-param>
<method-param>
java.lang.String
</method-param>
</method-params>
</query-method>
<ejb-ql>
SELECT OBJECT(b) FROM Book b
WHERE b.title BETWEEN ?1 AND ?2
</ejb-ql>
</query>
<query>
<query-method>
<method-name>findAll</method-name>
<method-params/>
</query-method>
<ejb-ql>
SELECT OBJECT(b) ORACLEHINT '/*+ALL_ROWS*/' FROM Book b
</ejb-ql>
</query>
</entity>
</enterprise-Beans>
<assembly-descriptor>
<container-transaction>
<method>
<ejb-name>BookBean</ejb-name>
<method-name>*</method-name>
<method-params/>
</method>
<trans-attribute>Required</trans-attribute>
</container-transaction>
</assembly-descriptor>
</ejb-jar>
Note
Note the three bold lines in the previous code. They show some additional, non-standard EJB QL keywords that are allowed in JEUS (ORDERBY, BETWEEN, and ORACLEHINT).
JEUS EJB DD
[Example 8.18] JEUS EJB DD : <<jeus-ejb-dd.xml>>
<?xml version="1.0"?>
<jeus-ejb-dd xmlns="http://www.tmaxsoft.com/xml/ns/jeus">
<module-info/>
<beanlist>
<jeus-bean>
<ejb-name>BookBean</ejb-name>
<export-name>book</export-name>
<export-port>0</export-port>
<export-iiop><only-iiop>false</only-iiop></export-iiop>
<persistence-optimize>
<engine-type>EXCLUSIVE_ACCESS</engine-type>
<non-modifying-method>
<method-name>getTitle</method-name>
</non-modifying-method>
<non-modifying-method>
<method-name>getAuthor</method-name>
</non-modifying-method>
<non-modifying-method>
<method-name>getPrice</method-name>
</non-modifying-method>
<non-modifying-method>
<method-name>getPublisher</method-name>
</non-modifying-method>
<non-modifying-method>
<method-name>toBookString</method-name>
</non-modifying-method>
</persistence-optimize>
<schema-info>
<table-name>Booktable</table-name>
<cm-field><field>code</field></cm-field>
<cm-field><field>title</field></cm-field>
<cm-field><field>author</field></cm-field>
<cm-field><field>price</field></cm-field>
<cm-field><field>publisher</field></cm-field>
<creating-table>
<use-existing-table/>
</creating-table>
<deleting-table>true</deleting-table>
<db-vendor>oracle</db-vendor>
<data-source-name>datasource1</data-source-name>
</schema-info>
<enable-instant-ql>true</enable-instant-ql>
</jeus-bean>
</beanlist>
</jeus-ejb-dd>