내용 목차
Entity Bean은 EJB 3.0부터는 JPA로 대체되었다. 따라서 Bean을 새롭게 개발하는 경우는 JPA 사용을 권장한다. 그러나 기존 사용자를 위해 JEUS EJB 엔진은 Entity Bean를 지원한다.
본 장에서는 JEUS EJB 엔진에서 Entity Bean을 설정하고 튜닝하는 데 필요한 모든 정보에 대해 설명한다.
EJB 스펙에 따라 JEUS EJB 엔진은 다음과 같은 3가지 Entity Bean을 지원한다.
-
Bean Managed Persistence Entity Bean (BMP)
-
EJB 1.1 스펙에 따른 Container Managed Persistence Entity Bean(CMP 1.1)
-
EJB 2.0 스펙에 따른 Container Managed Persistence Entity Bean(CMP 2.0)
종류에 상관없이 JEUS의 Entity Bean들은 모두 “제4장 EJB의 공통 특성”에서 설명한 기능과 설정 컴포넌트들을 공유하므로 JEUS EJB 엔진에서 Entity Bean을 설정하고 사용하기 전에 관련 장의 내용에 대한 이해를 필요로 한다.
3개의 Bean 종류에 따라 3개의 설정이 존재한다.
-
3가지 종류에 모두 적용되는 공통된 설정
-
CMP 1.1과 CMP 2.0에만 적용되고 BMP에는 적용되지 않는 설정
-
CMP 2.0에만 적용되는 설정
다음은 각 Entity Bean 종류별 설정 특성을 나타낸 표이다.
[표 8.1] Entity Bean 종류의 설정
| 설정 가능한 Entity 옵션 | BMP | CMP 1.1 | CMP 2.0 |
|---|---|---|---|
| 1. EJB name | √ | √ | √ |
| 2. Export name | √ | √ | √ |
| 3. Local export name | √ | √ | √ |
| 4. Export port | √ | √ | √ |
| 5. Export IIOP switch | √ | √ | √ |
| 6. use-access-control | √ | √ | √ |
| 7. Run-as identity | √ | √ | √ |
| 8. Security CSI Interop. | √ | √ | √ |
| 9. Env. refs | √ | √ | √ |
| 10. EJB refs | √ | √ | √ |
| 11. Resource Refs | √ | √ | √ |
| 12. Resource env. Refs | √ | √ | √ |
| 13. Thread ticket pool settings | √ | √ | √ |
| 14. Clustering settings | √ | √ | √ |
| 15. HTTP invoke | √ | √ | √ |
| 16. JEUS RMI | √ | √ | √ |
| 17. Object management | √ | √ | √ |
| 18. Persistence Optimize | √ | √ | √ |
| 19. CM persistence opt. | √ | √ | |
| 20. Schema info | √ | √ | |
| 21. Relationship map | √ |
위의 표에서와 같이 항목 1부터 16까지는 모든 EJB에 공통으로 적용된다. 이 항목들은 “제4장 EJB의 공통 특성”에서 모두 설명하였다.
17번 항목은 Session Bean과 Entity Bean에 모두 해당되지만 사용법은 차이가 있어서 그 차이점을 중점적으로 설명한다. 항목 18부터 21까지는 Entity Bean에만 해당하는 항목들로 본 장에서 자세히 설명한다.
이 외에도 다음과 같은 JEUS Entity EJB에 연관된 주제에 대해서도 설명한다.
-
Default Primary Key 클래스
-
EJB QL 언어에 추가된 JEUS 특정 항목
-
JEUS Instant EJB QL API
참고
JEUS에서는 성능 튜닝이 EJB Entity Bean 설정의 가장 중요한 부분이다. 그러므로 본 장에서는 엔진 모드와 서브 모드와 같이 성능 관련 부분에 대해서 자세히 설명한다. 본 장 후반부의 “8.4. Entity EJB 튜닝”은 본 절에서 설명한 내용을 좀 더 간략하게 다시 정리한 것이다.
본 절에서는 Entity Bean의 공통 기능과 각 Bean의 주요 기능에 대해서 설명한다.
3가지 Entity Bean들은 종류에 상관없이 JEUS Entity Bean의 공통 기능을 갖는다.
다음은 EJB 엔진에서 Entity Bean Object가 어떻게 관리되는지 보여준다.
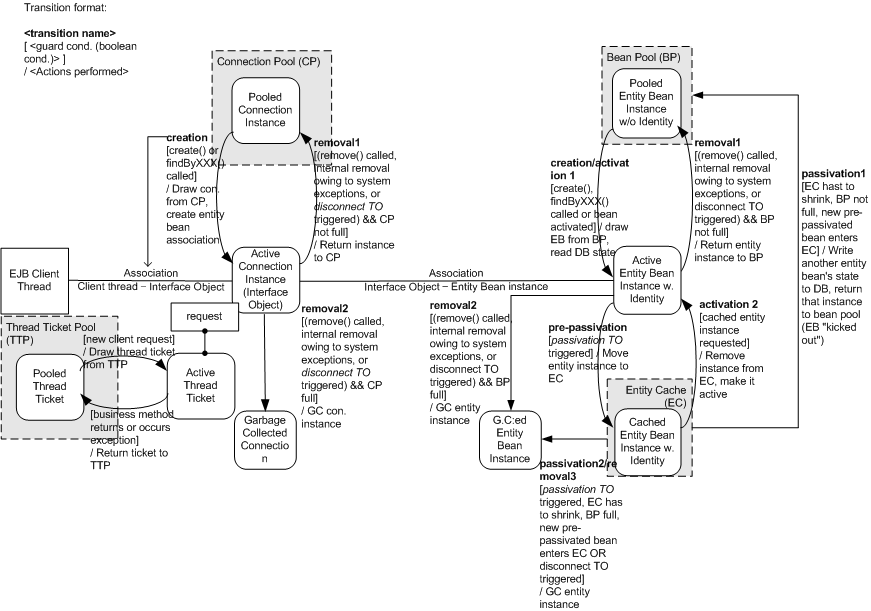
"object management"는 EJB 엔진의 내부적인 Bean Instance Pool과 Connection Pool을 의미한다. 이 Pool들은 각 Bean마다 설정되고 성능 향상과 시스템 자원의 효율적인 관리를 위해 사용된다. 기본적으로 Stateful Session Bean과 비슷하게 동작하므로 본 절에서는 차이점만 언급하고 자세한 내용은 “제7장 Session Bean”을 참고한다.
Entity Bean은 Connection Pool 외에 Entity Cache를 사용한다. Entity EJB가 passivate되려 할 때(passivation timeout이 지났을 때) 그 Bean Instance는 실제로는 바로 passivate되지 않는다(Stateful Session Bean의 경우에는 passivate된다). 대신에 이는 Entity Cache로 전달된다. 이 Cache에서는 모든 passivate된 Entity Bean들이 활성화 상태로 저장되어 있다(즉, 식별이 가능하고, 유효한 상태를 유지한다). 다른 Pool들과 마찬가지로 이 Entity Cache도 런타임 메모리에 유지되고, 따라서 활성화 상태와 passivate 사이의 존재하지 않는 상태에서 Runtime Cache로 작동된다.
Entity Bean이 실제적으로 passivate되는 때는 다음과 같다.
Entity Cache가 사이즈를 줄여야 할 때 passivate가 된다. 새로운 Entity Bean이 Cache로 들어오려 할 때 그 Cache에 이미 passivate된 Bean들이 많이 있을 경우 Cache 내의 Bean들이 강제로 밀려 나간다. 이렇게 강제로 밀려 나간 Entity Bean은 passivate되고 그 상태는 DB에 쓰여지며 그 Instance는 Bean Pool로 반환되거나 Bean Pool이 가득 차 있는 상태라면 버려진다. Cache에 막 들어오려는 Entity Bean은 Cache에 진입하여 결과적으로 강제로 밀려난 Bean Instance의 자리를 차지하게 된다.
Cache 크기는 <persistence-optimize>/<entity-cache-size>로 조절 가능하다. 반드시 설정한 크기만큼 찼을 때 Cache 크기를 줄이는 것은 아나라 힌트로 사용된다. 또한 강제로 밀려나가는 Bean Instance를 선택하는 방법 또한 Cache에 오래 머문 순이 아니다.
이러한 Cache를 사용하면 시간이 많이 소모되는 passivation을 효과적으로 관리할 수 있다는 장점이 있다. Cache를 사용함으로써 passivate된 Entity Bean을 다시 활성화시킬 때 DB에 접근할 필요가 없어지고 Cache에 있는 Instance(만약에 존재하면)를 사용함으로써 해결할 수 있다.
Object Pool의 표준 passivation timeout 값이 시간적인 제약을 관장하는 passivation 값이라면 Entity Cache는 메모리의 제약을 관장하는 passivation 설정값이라고 할 수 있다. 이것이 Entity Cache를 사용하는 주요 동기이다.
주의
Entity Cache 설정은 실제로 "object management"의 설정이 아니라 일반적인 Entity Bean persistence 최적화 설정이다. 이에 대한 자세한 내용은 “8.3. Entity EJB 설정”에서 설명한다.
Entity Bean에 대해 어느 시기에 ejbLoad() 메소드를 호출할 것인지 결정하는 것은 EJB 엔진(컨테이너)이다. 이 메소드는 DB의 상태 정보와 Bean Instance의 런타임 상태 정보를 동기화하기 위해 BMP와 CMP에서 사용한다. 본질적으로 ejbLoad() 메소드는 DB에서 하나의 레코드를 읽고 그 결과를 Bean의 내부 특성 값들에 설정하기 위해 사용된다.
ejbLoad() 메소드는 Entity Bean의 생명주기 동안 적어도 한 번은 호출된다. 어떤 경우에는 Bean Instance의 호출할 때마다 바로 전에 ejbLoad() 메소드를 호출할 필요가 생기기도 한다.
DB에서 Bean의 상태 정보를 읽어야 하는 시나리오는 기본적으로 크게 2가지가 있다.
-
Entity Bean이 여러 개의 EJB 엔진에 걸쳐 클러스터되어 있을 때 그 중 하나의 Bean이 DB의 한 레코드를 변경시킬 수 있다. 즉, 클러스터링된 Entity Bean들이 서로 통신할 수 없기 때문에 특정 Entity Bean Instance의 상태 정보가 가장 최신의 것이라는 것을 보장할 수 없다.
-
어떤 외부 요소(작업자 또는 시스템)가 EJB와 연동되어 있는 DB를 변경할 경우가 있다.
이 시나리오에서 EJB 엔진의 특정 EJB Instance는 DB의 내용을 제대로 반영하지 못한 상태가 된다.
다음 그림은 Entity Bean이 클러스터링되어 있을 때나 외부에서 Bean의 DB 행을 수정했을 때 ejbLoad()가 주기적으로 호출되는 2개의 시나리오이다.
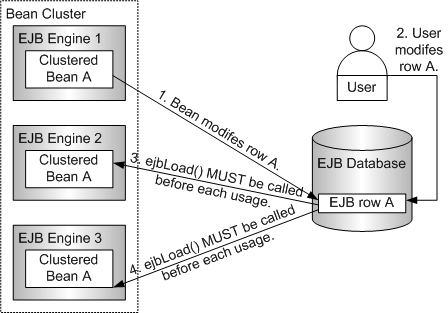
위의 두 시나리오의 상황을 피할 수만 있다면(클러스터링을 사용하지 않고, 어떤 외부 요소도 EJB의 DB 데이터를 변경하지 않는다고 보장한다면) Entity Bean의 ejbLoad() 동작을 최적화할 수 있다.
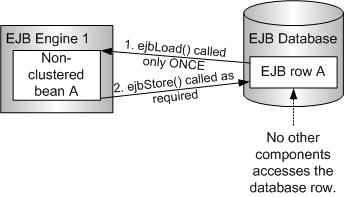
EXCLUSIVE_ACCESS 엔진 모드를 Bean에 적용하면 최적화가 가능하다. 이 모드를 사용하면, ejbLoad()는 Bean이 Instance화될 때 단 한 번만 호출된다. 이렇게 함으로써 DB의 접근량을 약 50%정도 줄일 수 있다.
다음 그림은 EXCLUSIVE_ACCESS 모드가 사용될 때의 시나리오를 보여주고 있다. EXCLUSIVE_ACCESS는 단지 하나의 Bean이 DB 행을 사용하고 대부분의 ejbLoad()는 최적화된다.
Bean을 클러스터링해야 하거나 외부 요소가 EJB 데이터를 변경시켜야 한다면 SINGLE_OBJECT 또는 MULTIPLE_OBJECT 엔진 모드를 사용해야 한다. 두 모드 중 하나가 사용되면, EJB 엔진은 EJB 클라이언트의 요청이 도착할 때마다 ejbLoad() 메소드를 호출한다. 이렇게 하면 각 Entity Bean의 성능이 저하되지만 모든 상태 정보가 DB에 의해 관리되기 때문에 다른 엔진과 Bean들에게 부하를 분산시킬 수 있다.
다음은 SINGLE_OBJECT와 MULTIPLE_OBJECT 모드의 차이점에 대한 설명이다.
-
SINGLE_OBJECT 엔진 모드
SINGLE_OBJECT 에서는 각 EJB 엔진의 단 한 개의 Bean Instance만이 모든 클라이언트의 요청을 처리한다. 즉, 첫 요청이 처리되고 있는 동안 도착한 요청들은 대기하고 있어야 한다.
-
MULTIPLE_OBJECT 엔진 모드
MULTIPLE_OBJECT 모드에서는 이러한 제약이 적용되지 않고 EJB 엔진이 새로운 Entity Bean Instance를 생성하여 새로운 EJB 클라이언트 요청을 처리한다. 즉, MULTIPLE_OBJECT 엔진 모드에서는 새로운 EJB Instance가 할당된다.
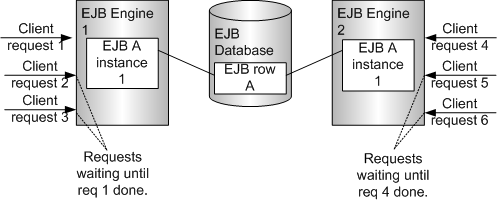
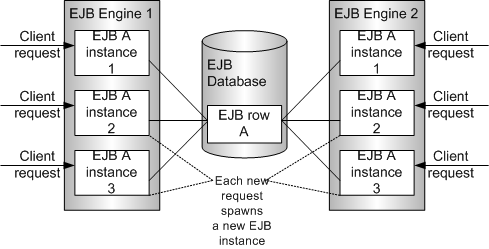
다음은 각 엔진 모드를 선택할 때의 장점과 단점을 비교한 표이다.
[표 8.2] 3가지 엔진 모드의 단점과 장점
| 구분 | EXCLUSIVE | SINGLE | MULITPLE |
|---|---|---|---|
| 클러스터링을 허용하는가? | No | Yes | Yes |
| 외부 Entity가 DB에 접근 가능한가? | No | Yes | Yes |
| DB connection이 효율적으로 사용되는가?(ejbLoad() 호출빈도) | Yes | No | No |
| 장시간의 트랜잭션의 경우 적당한 옵션을 지원하는가? | No | No | Yes |
| 하나의 엔진에 적합한 단일 처리의 효과적인 모드는? | Not applicable | Yes | No |
| 하나의 엔진에서 EJB를 동시에 처리하기 위해 요구되는 효과적인 다중처리 모드는? | Not applicable | No | Yes |
3가지 엔진 모드 중 적합한 모드를 선택하기 위한 기준은 다음과 같다.
-
많은 양의 요청이 Entity Bean에 요청되고, 많은 수의 EJB 엔진들이 설정되어 있다면 SINGLE_OBJECT 모드를 선택하고 엔진들에 Bean을 클러스터링으로 구성한다.
-
많은 양의 요청이 Entity Bean에 요청되지만, 한정된 EJB 엔진이 설정되어 있으면 MULTIPLE_OBJECT 모드를 선택하고 엔진들에 Bean을 클러스터링으로 구성한다.
-
MULTIPLE_OBJECT와 SINGLE_OBJECT를 선택할 때 고려해야 할 중요한 사항 중의 하나는 한 트랜잭션을 수행하기 위해 필요한 총 시간이다. 수행 시간이 많이 소요되는 트랜잭션이라면 당연히 MULTIPLE_OBJECT를 선택할 것을 권장한다.
-
많지 않은 동시 요청이 Entity Bean에 들어온다면 EXCLUSIVE_ACCESS 모드를 선택하고 하나의 EJB 엔진에 Bean을 deploy한다.
EJB 클러스터링에 대한 자세한 정보는 “제6장 EJB 클러스터링”의 설명을 참고한다.
본 절에서는 ejbStore() 호출을 최적화하는 방법에 대해 설명한다.
참고
본 절에서 설명하는 ejbStore() 호출의 최적화 방법은 BMP와 CMP 1.1 Bean들에만 적용되고, CMP 2.0은 다른 방법으로 접근해야 한다.
ejbStore()는 EJB 엔진에 의해 DB의 Bean 상태 정보가 유지되어야 한다고 판단될 때마다 호출된다. 일반적으로 해당 DB로의 접근은 각 트랜잭션의 commit 또는 Bean Instance가 passivate되기 전에 시도된다.
그러나 만약에 트랜잭션의 중간에 Bean의 상태가 바뀌지 않으면 ejbStore()가 호출될 이유가 없다.
JEUS EJB 엔진은 Bean의 상태 변경을 자동적으로 예측할 수 없다. 그러므로 개발자나 deployer는 ejbStore()를 호출하는 시점을 EJB 엔진이 판단할 수 있도록 힌트를 제공해야 한다. 이 힌트는 Non-modifying 메소드들의 목록으로 제공된다. Non-modifying 메소드는 근본적으로 읽기만 허용하는 메소드(getter)로서 Entity Bean의 DB 내부 상태를 변경하지 않는다.
Non-modifying 메소드의 목록을 보고 EJB 엔진은 ejbStore() 메소드를 호출할지 여부를 결정한다. 트랜잭션 중 또는 Bean이 활성화된 상태일 때 Non-modifying 메소드만 실행되면 EJB 엔진은 ejbStore() 호출이 불필요하다고 판단하고 그 과정을 생략한다. 이는 전체적인 성능이 향상됨을 의미한다.
본 절에서는 CMP 1.1/2.0의 주요 기능에 대해서 설명한다.
“8.2.1.2. 엔진 모드 Selection을 통한 ejbLoad() Persistence 최적화”와 “8.2.2.1. Non-modifying 메소드에 의한 ejbStore() Persistence 최적화”에서 ejbLoad()와 ejbStore() 메소드의 호출 시점에 대해서 설명하였다. BMP와 CMP는 ejbLoad()와 ejbStore() 메소드를 사용하기 때문에 BMP와 CMP Entity Bean에만 적용되었다.
본 절에서는 성능향상을 위해 ejbLoad()와 ejbFind() 메소드를 최적화하는 방법에 대해서 설명한다. ejbLoad(), ejbFind()의 구현 방법은 EJB 엔진에 영향을 받기 때문에 CMP Bean(1.1과 2.0 버전)에 국한해서 설명한다. BMP에서 해당 메소드의 구현과 작동 방식은 개발자에 의해 결정된다.
EJB 엔진이 CMP ejbLoad(), ejbFind()를 호출하면 다음과 같은 엔진의 하위 모드를 선택하여 작동 방식을 최적화할 수 있다. 3가지 모드에 대한 자세한 기술적 설명은 하지 않는다.
위의 3가지 모드가 사용되어야 하는 상황은 다음과 같다.
-
CMP Bean이 쓰기 작업보다는 읽기 작업을 더 빈번히 수행하면 항상 ReadLocking 모드를 선택한다.
-
CMP Bean이 읽기 보다는 쓰기 작업을 더 많이 수행하면 WriteLocking 모드나 WriteLockingFind 모드를 선택한다.
CMP에서는 엔진 모드와 앞 절에서 설명한 Non-modifying 메소드, 그리고 본 절에서 설명한 엔진 내 하위 모드가 규칙에 맞게 조합되어 설정되어야 한다. 이 모든 파라미터들의 설정 요약은 “8.4. Entity EJB 튜닝”의 설명을 참고한다.
또한 CMP Bean에서는 java.sql.ResultSet의 Fetch Size, EJB 엔진이 기동(Booting)할 때 Caching되어야 하는지의 여부와 EJB Bean Instance가 미리 Instance되어야 할지 등을 결정하는 <init caching> 설정을 할 수 있다.
EJB 엔진이 Bean의 persistence를 관리하는 책임을 가지고 있다면(CMP), Entity Bean Instance 필드와 실제 DB의 테이블과 컬럼들과의 매핑을 선언적으로 정의해주는 방법이 있어야 한다. 또한 DB 소스도 지정해주어야 한다. 이 정보는 EJB XML 환경에 <schema info>로 기술한다.
CMP 1.1의 이 태그에는 EJB 엔진이 CMP 1.1 finder 메소드를 생성할 때 기본적으로 사용될 SQL 문도 포함된다.
경우에 따라 개발자들은 Primary Key 생성 없이 EJB Instance를 생성해야 할 때가 있다. 이 경우 JEUS EJB 엔진이 새로운 EJB Instance에게 할당할 고유의 Primary Key를 생성하도록 설정할 수 있다.
JEUS EJB 엔진은 이 기능을 DB와 연동하여 제공한다. 이러한 자동 Primary Key 생성 기능에 대해 JEUS EJB 엔진은 DB와 연동하여 제공하고, CMP 1.1과 CMP 2.0에 적용된다. 이 기능을 사용하면 Primary Key에 신경쓰지 않고 손쉽게 EJB를 개발할 수 있다.
다음은 자동 Primary Key 생성 기능의 사용 방법과 적용 과정에 대한 설명이다.
-
개발자들은 습관적으로 CMP1.1/CMP2.0을 파라미터 없이 create()를 호출한다. 이것은 create() 메소드가 EJB의 Primary Key가 되는 파라미터를 갖지 않는다는 의미이다.
InitialContext ctx = new InitialContext(); BookHome bHome = (BJookHome) ctx.lookup("bookApp"); Book b = bHome.create(“JEUS EJB Guide”, ”Park Sungho”); // Start using “b”. . . .위의 예제에서 EJB Home인 BookHome을 찾고 EJB Home에서 파라미터가 2개인 create()를 호출한다("JEUS EJB Guide"와 "Park Sungho"). 이 파라미터는 새로운 책의 제목과 저자 이름을 뜻한다. 저자는 다르나 동일한 제목의 책이 있을 수 있기 때문에 이 파라미터들을 Primary Key로 이용하는 것은 적합하지 않다.
이 기능을 지원하기 위해 EJB 엔진은("A") 반드시 고유의 Primary Key를 생성해서 새 책에 할당해야 한다. 그리고 여러 엔진들("B", "C")이 클러스터링된 상태에서도 같은 일이 동시에 발생할 수 있다는 것을 고려해야 한다.
광범위한 클러스터링 중에도 각 엔진들은 고유한 Primary Key를 얻을 수 있어야 하기 때문에 하나의 중앙 저장장치를 필요로 한다. 이 저장장치는 하나의 컬럼과 하나의 데이터로 이루어진 DB로 구현된다.
이 하나의 값은 EJB 엔진과 연동하면서 계속 증가하는 Primary Key Counter(또는 Primary Key Generator)이다. 이 방법으로 DB는 항상 클러스터링된 EJB 엔진이 읽을 수 있는 새롭고 고유한 Primary Key를 유지할 수 있다.
-
Primary Key가 없는 create()가 호출되면, EJB 엔진 "A"는 중앙 저장장치(Primary Key DB)로 접근한다. 이 저장장치로부터 정수로 된 Primary Key를 받아오고 Book Instance에 할당한다.
-
EJB 엔진 "A"는 저장장치에 있는 미리 결정된 값으로 Primary Key를 증가시킨다. 미리 결정된 값(Key Cache Size)은 기본적으로 "1"이다. 그러나 1 이상을 사용할 것을 권장한다("20").
만약 Key Cache Size가 "20"이라면, EJB 엔진 "A"는 "19" (20-1)를 할당한다. 다음에 Primary Key를 읽는 다른 EJB 엔진("B"와 "C")은 가장 최근에 Primary Key를 읽어간 것보다 20이 큰 값을 읽게 된다.
이것은 EJB 엔진 "A"는 19개까지는 외부의 Primary Key 저장장치에 접근 없이 EJB Instance를 생성할 수 있다는 것을 의미한다. 따라서 성능 향상에 큰 기여를 한다. 엔진 "A"는 할당받은 Primary Key의 Counter를 유지함으로써 이 값을 모두 소비했을 때에만 외부에서 새로운 Primary Key를 읽어 온다. 내부적인 Counter는 물론 Primary Key를 생성하는 데 사용된다.
다음은 자동 Primary Key 생성의 특징에 대한 설명이다.
-
Oracle과 MS SQL 서버는 자동으로 Primary Key Sequence를 제공한다. 자동 Primary Key 생성 설정에 대한 자세한 내용은 "Oracle DB에서 Primary Key 생성 설정"과 "MS SQL Server에서 자동 Primary Key 생성 설정"을 참고한다.
-
Non-Oracle과 Non-MS SQL 서버는 직접 Primary Key 테이블을 작성해야 한다. 자세한 내용은 "Other DB의 자동 Primary Key 생성"을 참고한다.
-
자동 Primary Key 생성 기능을 사용하기 위해서는 DB가 반드시 Transaction Isolation Level - TRANSACTION_SERIALIZABLE을 지원해야 한다. 본 안내서에서는 지원한다고 가정한다.
-
Primary Key는 EJB에서 반드시 정의되어야 한다. Primary Key는 반드시 java.lang.Integer 타입이고, 단일 Key여야 하며, EJB DD에 선언되어야 한다.
참고
자동 Primary Key 생성 기능은 반드시 TRANSACTION_SERIALIZABLE(Isolation Level)을 지원해야만 한다. 즉, Oracle, MS SQL 서버 외에는 모두 이 Isolation Level이 지원되는지 확인해야 한다.
다음은 각 DB에 설정하는 방법에 대해 설명한다.
Oracle DB에서 Primary Key 생성 설정
Oracle DB에서 자동 Primary Key 생성은 Oracle에서 사용하는 Sequence 객체를 이용한다. 자동 Primary Key 생성 기능을 설정하기 전에 Sequence 객체가 생성되어 있어야 한다. Sequence 설정에 관련한 내용은 Oracle 문서를 참고한다.
다음은 Oracle DB에서 Primary Key를 생성하는 jeus-ejb-dd.xml의 예이다.
[예 8.1] Oracle DB에서 Primary Key 생성 설정 : <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<beanlist>
. . .
<jeus-bean>
. . .
<schema-info>
. . .
<data-source-name>MYORACLEDB</data-source-name>
<auto-key-generator>
<generator-type>
Oracle
</generator-type>
<generator-name>
my_generator
</generator-name>
<key-cache-size>
20
</key-cache-size>
</auto-key-generator>
</schema-info>
. . .
</jeus-bean>
. . .
</beanlist>
. . .
</jeus-ejb-dd>
위 예제에서 Primary Key 생성 타입을 "Oracle"로 설정했으며, <generator-name>을 “my_generator”로 하고 <key-cache-size>를 "20"으로 설정했다.
참고
<key-cache-size>는 Oracle의 Sequence 객체의 SEQUENCE INCREMENT 값과 일치해야 한다.
Oracle DB는 <data-source-name>에서 선택된다(여기서는 "MYORACLEDB"가 사용되었는데, JEUSMain.xml의 DB Connection Pool JNDI 이름이다). 설정에 대한 자세한 내용은 "JEUS Server 안내서"를 참고한다.
MS SQL 서버에서 자동 Primary Key 생성 설정
MS SQL 서버에서 자동 Primary Key 생성은 간단하다. MS SQL 서버는 자동으로 고유의 IDENTITY 컬럼에 Primary Key를 유지한다.
다음은 MS SQL 서버에서 자동 Primary Key 생성을 설정한 jeus-ejb-dd.xml의 예이다.
[예 8.2] MS SQL 서버에서 자동 Primary Key 생성 설정 : <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
<beanlist>
. . .
<jeus-bean>
. . .
<schema-info>
. . .
<data-source-name>MSSQLDB</data-source-name>
<auto-key-generator>
<generator-type>
MSSQL
</generator-type>
</auto-key-generator>
</schema-inboldfo>
</jeus-bean>
. . .
</beanlist>
</jeus-ejb-dd>
<generator-type>에 "MSSQL"을 입력한다. MS SQL 서버는 <data-source-name>에서 선택된다.
Other DB의 자동 Primary Key 생성 설정
만약 Oracle과 MS SQL 서버 외에 다른 DB를 이용해서 자동 Primary Key를 생성한다면, 다음의 절차를 반드시 지켜야 한다.
-
다음과 같이 DB에 테이블을 하나 생성한다. 테이블은 하나의 컬럼과 하나의 열을 갖고 있어야 하고, 값은 '0'으로 설정되어야 한다.
다음은 Primary Key 값을 관리할 테이블이다.
Primary Key generator table PrimKeyTable PrimKeyGeneratorColumn (Primary Key 값이 저장되는 컬럼) Row 1 0 (Primary Key 값의 초기값) 위의 테이블은 다음의 SQL로 생성된다.
CREATE table PrimKeyTable (PrimKeyGeneratorColumn int); INSERT into PrimKeyTable VALUES (0);
-
테이블을 생성하고 jeus-ejb-dd.xml을 다음과 같이 수정한다.
[예 8.3] Other DB의 자동 Primary Key 생성 설정 : <<jeus-ejb-dd.xml>>
<jeus-ejb-dd> . . . <beanlist> . . . <jeus-bean> . . . <schema-info> . . . <data-source-name>MYDB</data-source-name> <auto-key-generator> <generator-type> USER_KEY_table </generator-type> <generator-name> PrimKeyTable </generator-name> <sequence-column> PrimKeyGeneratorColumn </sequence-column> <key-cache-size> 20 </key-cache-size> </auto-key-generator> </schema-info> . . . </jeus-bean> . . . </beanlist> . . . </jeus-ejb-dd>위 예제에서 타입은 'USER_KEY_table'이고, 테이블 이름이 'PrimKeyTable'이다. 컬럼 이름은 'PrimKeyGeneratorColumn'이고 Key Cache 크기는 '20'으로 설정했다.
DB를 사용하기 위해서 설정하는 <data-source-name> 태그의 값은 JEUSMain.xml의 DB Connection Pool의 <export-name>과 일치해야 한다.
참고
설정에 대한 자세한 내용은 "JEUS Server 안내서"를 참고한다.
본 절에서는 CMP 2.0의 주요 기능에 대해서 설명한다.
EJB 2.0 스펙에는 DB에 있는 관계(Relationship)를 지원하기 위해 CMP Relationship의 개념이 소개되어 있다. CMP 2.0 Bean들과 이 Relationship들을 사용할 때에는 deployer가 JEUS EJB DD에 추가 정보를 제공해야 한다.
CMP 2.0 Bean은 ejb-jar.xml의 EJB QL 문장과 연계되어 있는 home interface의 findByXXXX() 메소드를 가지고 있어야 한다. JEUS는 표준 EJB QL 언어에 몇 가지 추가 사항을 더 지원한다. 이 추가 지원 사항은 ejb-jar.xml에 사용되거나 Instant EJB QL 요청에 사용될 수 있다.
“8.3.3.3. JEUS EJB QL Extension”에는 위의 예가 포함된 완전한 ejb-jar.xml의 예가 포함되어 있다.
클라이언트 코드 내에서 CMP Bean의 집합을 찾으려면 Bean의 home interface에 선언되어 있는 findByXXXX() 메소드들에 의존할 수 밖에 없다. 이 찾기 방법이 복잡한 경우에는 findByXXXX() 만으로는 부족할 수가 있다.
이러한 경우를 대비하여 JEUS에서는 클라이언트 코드에서 EJB QL select 질의문들을 정의할 수 있는 비표준 인터페이스를 제공한다. 이 인터페이스는 jeus.ejb.Bean.objectbase.EJBInstanceFinder라고 불리며, JEUS EJB DD에 Bean의 Instant QL을 활성화시킨 경우 Entity Bean의 home interface에서 구현한다. 이 인터페이스는 사용자의 EJB QL을 home interface로 넘겨주는 메소드인 findWithInstantQL(String ejbQLString)을 가지고 있다. 이 메소드는 질의에 해당하는 EJB 인터페이스의 java.util.Collection 객체를 반환한다.
이 메소드의 예제는 “8.2.3.3. 자동 Primary Key 생성”을 참고하고, 해당 API에 대한 설명은 “Appendix B. Instant EJB QL API Reference”를 참고한다.
본 절에서는 다음과 같은 JEUS Entity EJB의 설정 방법을 설명한다.
-
모든 Entity Bean에 적용 가능한 설정
-
기본적이고 공통적인 설정들
-
Object Pool
-
Entity Cache 설정을 포함한 Persistence 최적화
-
-
CMP에만 적용 가능한 설정
-
CM persistence optimization 최적화
-
스키마 정보 설정
-
-
CMP 2.0에만 적용 가능한 설정
-
Relationships 매핑 설정
-
Instant EJB QL 설정
-
모든 이 특성들은 JEUS EJB모듈 DD(jeus-ejb-dd.xml)의 <beanlist> 태그 아래의 <jeus-bean>에 설정된다.
다음은 모든 Entity Bean에 적용 가능한 기본 설정에 대한 설명이다.
“제4장 EJB의 공통 특성”에서 설명한 JEUS에서 지원하는 모든 Bean 종류에 적용 가능한 설정은 모든 종류의 Entity Bean들에게도 적용할 수 있다.
다음은 BMP Entity Bean의 기본 XML 태그의 예이다.
[예 8.4] Entity EJB의 기본 공통 항목 설정 : <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<beanlist>
<jeus-bean>
<ejb-name>account</ejb-name>
<export-name>ACCOUNTEJB</export-name>
<local-export-name>
LOCALACCOUNTEJB
</local-export-name>
<export-port>7654</export-port>
<export-iiop>true</export-iiop>
. . .
</jeus-bean>
. . .
</beanlist>
. . .
</jeus-ejb-dd>
다음은 Object Management 관련 설정이 된 XML 예제로 <jeus-bean>의 <object-management> 태그 내에서 구성된다.
[예 8.5] Object Management 관련 설정 : <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<beanlist>
<jeus-bean>
. . .
<object-management>
<bean-pool>
<pool-min>10</pool-min>
<pool-max>200</pool-max>
</bean-pool>
<connect-pool>
<pool-min>10</pool-min>
<pool-max>200</pool-max>
</connect-pool>
<capacity>5000</capacity>
<passivation-timeout>10000</passivation-timeout>
<disconnect-timeout>1800000</disconnect-timeout>
</object-management>
</jeus-bean>
. . .
</beanlist>
. . .
</jeus-ejb-dd>
다음은 설정 태그에 대한 설명이다.
-
-
EJB Bean Instance Pool의 작동 방식을 결정한다.
-
하위 태그들은 다음과 같다.
태그 설명 <pool-min> Pool을 초기화할 때 생성해두는 초기 Bean Instance 개수와 Pool에 유지하려는 최소 Bean Instance의 개수(resizing 작업할 때 Pool에 남기는 Instance의 개수)이다. (기본값: 0) <pool-max> Instance의 사용이 끝난 후 Pool에 저장 여부를 결정하는 Pool이 가질 수 있는 최대 Bean Instance 개수이다. Session Bean은 <pool-max> 설정값까지만 생성할 수 있으므로 그 이상의 요청이 한 번에 오면 EJB Exception이 발생한다.
반면, Entity Bean은 Bean Instance 생성에는 제한이 없고 사용 후에 Pool에 보관할 개수를 제한한다. (기본값: 100)
<resizing-period> Pool의 크기를 재조정하는 시간으로 "resizing"은 사용되지 않는 Bean Instance들이 Pool의 최솟값까지 제거됨을 의미한다. (기본값: 5분, 단위: ms)
-
-
-
클라이언트와 Bean Instance를 연결하는 connection을 몇 개까지 유지할 것인지를 설정한다. 해당 옵션은 Session Bean에서는 사용하지 않는다.
-
하위 태그들은 다음과 같다.
태그 설명 <pool-min> Pool에 유지하려는 최소 connection의 개수로 resizing 작업할 때 Pool에 남기는 Instance의 개수이다. (기본값: 0) <pool-max> connection 사용이 끝난 후 Pool에 저장 여부를 결정하는 Pool이 가질 수 있는 최대 connection 개수이다. (기본값: 100) <resizing-period> Pool의 크기를 재조정하는 시간으로 "resizing"은 사용되지 않는 connection들이 Pool의 최솟값까지 제거됨을 의미한다. (기본값: 5분, 단위: ms)
-
-
-
생성될 것으로 예상되는 Bean Instance의 최대 개수를 의미하며, Entity Bean에만 사용된다. 이 값은 EJB와 연계될 내부 클라이언트 세션 데이터의 효율적인 구성을 위해 사용된다. (기본값: 10000)
-
-
-
지정된 시간 동안 클라이언트의 요청을 받지 않은 Bean을 passivate할 때 사용된다.
여기에 설정된 시간을 초과하는 동안 클라이언트의 요청이 없는 Bean Instance가 passivate 대상이 된다. passivate 대상인 Bean Instance가 메모리에 남아 있는 개수를 <persistence-optimize>/<entity-cache-size>로 조절할 수 있다.
-
Stateful Session Bean의 경우는 Entity Cache라는 것이 없어 설정한 시간 동안 요청이 없으면 passivate되지만 Entity Bean의 경우는 Entity Cache에 머물러 있다가 passivate된다. 어떤 Bean이 passivate되는지 검사하는 주기는 EJB 엔진에 설정한 resolution을 따른다. (기본값: 5분)
passivate가 실행되면 메모리에서 해당하는 Bean Instance가 제거된다.
-
이 설정은 다음과 같이 여러 곳에서 설정 가능하고 우선순위는 다음과 같다.
-
특정 Session Bean에만 적용 : jeus-ejb-dd.xml의 <passivation-timeout>
-
모든 Entity Bean에 적용 : 시스템 프로퍼티 jeus.ejb.entity.passivate
-
모든 EJB Bean에(Entity Bean과 Session Bean 모두) 적용 : 시스템 프로퍼티 jeus.ejb.all.passivate
위의 모든 설정이 없으면 기본값으로 설정된다. (기본값: 300000(5분), 단위: ms)
-
-
-
-
지정된 시간 동안 클라이언트의 요청을 받지 못하면 클라이언트와 Bean Instance 사이를 연결하던 connection을 끊을 때 사용된다. 그렇게 되면 connection은 각각의 클라이언트와 인스턴스가 맺고 있던 연결을 끊고 Connection Pool로 반환된다.
따라서 클라이언트는 이 connection으로 더 이상 요청을 할 수 없고, 사용 중이던 Bean Instance는 삭제되거나 Bean Pool을 사용 중이면 Bean Pool로 반환된다.
-
이 설정은 다음과 같이 여러 곳에서 설정 가능하고 우선순위는 다음과 같다.
-
특정 Session Bean에만 적용 : jeus-ejb-dd.xml의 <disconnect-timeout>
-
모든 Entity Bean에 적용 : 시스템 프로퍼티 jeus.ejb.stateful.disconnect
-
모든 EJB Bean에(Entity Bean과 Session Bean 모두) 적용 : 시스템 프로퍼티 jeus.ejb.all.disconnect
위의 모든 설정이 없으면 시스템 프로퍼티 jeus.ejb.all.disconnect의 기본값인 3600000(1시간)으로 설정된다. (단위: ms)
-
-
참고
<passivation-timeout>과 <disconnect-timeout>에 사용되는 시간은 Bean Instance에 액세스했던 마지막 시점부터 측정된다. 그러므로 <disconnect-timeout>을 <passivation- timeout>보다 길게 설정해야 한다. 또한 <passivation-timeout>은 EJB 엔진에 설정되는 resolution보다는 커야 한다.
타임아웃 값을 길게 설정하면 오랜 시간(대략 십여 분 이상 또는 타임아웃이 중지된 경우) 동안 메모리 안에 많은 Instance가 활성화된 상태로 머물러 있다. 그러므로 시스템 자원이 낭비된다. 타임아웃 값이 수 초정도로 너무 짧으면 passivation, activation 등의 작업이 자주 발생되므로 성능을 저하시킬 수 있고 disconnect 작업으로 인해 세션의 유실 가능성이 있다.
Persistence 메소드 호출의 최적화는 jeus-ejb-dd.xml의 각 Bean DD에 설정되어 있다.
다음은 ejbLoad(), ejbStore() 메소드의 Persistence 최적화 설정된 XML 예제로 <jeus-bean>의 <persistence-optimize> 태그 내에서 구성된다.
[예 8.6] ejbLoad()와 ejbStore() Persistence 최적화 설정 : <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<beanlist>
. . .
<jeus-bean>
. . .
<persistence-optimize>
<engine-type>SINGLE_OBJECT</engine-type>
<non-modifying-method>
<method-name>myBusinessmethod</method-name>
<method-params>
<method-param>
java.lang.String
</method-param>
<method-param>int</method-param>
<method-param>double</method-param>
</method-params>
</non-modifying-method>
<non-modifying-method>
<method-name>myBusinessmethod2</method-name>
<method-params>
<method-param>
java.lang.String
</method-param>
<method-param>int</method-param>
</method-params>
</non-modifying-method>
<entity-cache-size>500</entity-cache-size>
<update-delay-till-tx>
false
</update-delay-till-tx>
<include-update>
true
<include-update>
</persistence-optimize>
</jeus-bean>
. . .
</beanlist>
. . .
</jeus-ejb-dd>
다음은 설정 태그에 대한 설명이다.
| 태그 | 설명 |
|---|---|
| <engine-type> | 다음 중에 하나로 설정되어야 한다. 각 설정에 대한 차이는 “8.2. 주요 기능”의 설명을 참고한다.
|
| <non-modifying-method> | ejbStore()가 호출되어야 하는지에 대한 힌트를 EJB 엔진에 제공한다. 이 태그는 CMP 2.0 Bean에서는 적용되지 않는다. |
| <entity-cache-size> | passivate되어야 할 Entity Bean Instance들을 위한 내부 Cache의 크기를 결정한다. Cache에 담을 수 있는 Entity Bean Instance의 최대 크기 만큼이 주어진다. 크기가 클수록 좋은 성능을 가질 수 있지만 시스템 리소스(주 메모리)는 그 만큼 더 많이 사용된다. (기본값: 2000) |
| <update-delay-till-tx> | Boolean 값을 가지며 EJB 데이터의 update, insert가 트랜잭션이 commit될 때까지 지연될지를 나타낸다. 이 값이 false이면 모든 update, insert 작업은 즉각 실행되므로, 동일한 트랜잭션 내에서는 commit()이 호출되기 전에도 변경 사항을 확인할 수가 있지만 성능에 악영향을 미친다. (기본값: true) |
| <include-update> | <schema-info><jeus-query><include-updates>의 기본값을 지정한다. 이 값이 true일 경우 finder 메소드가 호출되는 동안에 생성된 update가 commit되므로, finder 메소드가 실행될 동안 업데이트된 정보를 조회할 수 있다. (기본값: false) |
다음은 CMP 1.1/2.0의 설정에 대한 설명이다.
CMP 1.1과 2.0 Bean에는 ejbLoad() persistence 최적화를 설정할 수 있다. 자세한 내용은 “8.3.1.3. ejbLoad()와 ejbStore() Persistence 최적화 설정”을 참고한다.
다음은 ejbLoad, ejbFind CM Persistence 최적화 설정한 XML의 예로 <jeus-bean>의 <cm-persistence-optimize> 태그 내에 설정된다.
[예 8.7] ejbLoad()와 ejbFind() CM Persistence 최적화 설정 : <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<beanlist>
. . .
<jeus-bean>
. . .
<cm-persistence-optimize>
<subengine-type>WriteLocking</subengine-type>
<fetch-size>80</fetch-size>
<init-caching>true</init-caching>
</cm-persistence-optimize>
</jeus-bean>
. . .
</beanlist>
. . .
</jeus-ejb-dd>
다음은 설정 태그에 대한 설명이다.
CMP 1.1/2.0에서는 DB 테이블과 컬럼에 대응하는 EJB Instance 필드와의 매핑을 포함하고 있는 DB 스키마 정보를 설정해야 한다.
다음은 DB 스키마 정보를 설정한 XML 예제로 <jeus-bean>의 <schema-info> 태그 내에 구성된다.
[예 8.8] DB 스키마 정보 설정 : <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<beanlist>
. . .
<jeus-bean>
. . .
<schema-info>
<table-name>ACCOUNT</table-name>
<cm-field>
<field>id</field>
<column-name>ID</column-name>
<type>NUMERIC</type>
<exclude-field>false</exclude-field>
</cm-field>
<cm-field>
<field>customer_addr</field>
<column-name>customer_address</column-name>
<type>VARCHAR(30)</type>
<exclude-field>false</exclude-field>
</cm-field>
<creating-table>
<use-existing-table/>
</creating-table>
<deleting-table>true</deleting-table>
<prim-key-field>
<field>id</field>
</prim-key-field>
<jeus-query>
<method>
<method-name>findByAddress</method-name>
<method-params>
<method-param>java.lang.String</method-param>
</method-params>
</method>
<sql>customer_address=?</sql>
</jeus-query>
<jeus-query>
<query-method>
<method-name>findByTitle</method-name>
<method-params>
<method-param>java.lang.String</method-param>
</method-params>
</query-method>
<jeus-ql>
SELECT OBJECT(b) FROM Book b
WHERE b.title = ?1 ORDERBY b.price
</jeus-ql>
</jeus-query>
<db-vendor>oracle</db-vendor>
<data-source-name>MYDB</data-source-name>
</schema-info>
. . .
</jeus-bean>
. . .
</beanlist>
. . .
</jeus-ejb-dd>
다음은 설정 태그에 대한 설명이다.
-
-
현재 EJB에 매핑되어야 할 관계형 DB 테이블의 이름이다.
-
만약에 설정되어 있지 않으면 EJB module name, EJB name을 이용해 테이블 이름이 임의로 설정된다.
-
일부 DBMS들이 가지는 테이블 이름의 길이제한 때문에 15자 이내의 테이블 이름만 허용된다.
-
-
-
Container Managed Field 매핑은 각각의 컬럼과 필드의 관계를 위해 존재한다.
-
하위에 다음의 태그를 설정한다.
태그 설명 <field> DB 컬럼에 매핑되어야 하는 EJB 필드의 이름을 지정한다. <column-name> 주어진 DB 테이블에 존재하는 것과 같은 것이다. 지정되어 있지 않으면 EJB 필드의 이름을 사용한다. <type> DB 컬럼에 정의된 데이터 타입(예: VARCHAR(25), NUMERIC 등)을 기준으로 한다. 태그가 지정되어 있지 않으면 디폴트 타입이 사용된다(사용될 타입은 DB에 따라 다를 수 있다). 이 매핑은 “Appendix A. 기본 Java 타입과 DB 필드 매핑”에서 설명한다.
Oracle DBMS의 경우 다음의 값을 다룰 수 있다. 이 타입들은 이미지같이 큰 자료 타입에 적합하다.
-
CLOB(Character Large Object) : java.lang.String에 적합하다.
-
BLOB(Binary Large Object) : serializable된 필드에 적합하다.
<exclude-field> true로 설정하면 <field> 태그로 지정된 필드에 대해 accessor 메소드가 생성되지 않아 클라이언트에서 해당 필드를 접근할 수 없다. 이 옵션은 CMP 2.0 Bean에서만 작동한다. 이 옵션은 이전(migration)을 위한 목적으로 사용된다.
(기본값: false)
-
-
-
-
Bean이 start되는 시점에 이 Bean이 사용할 테이블이 DB에 존재하는지를 검사하여 하위 태그에 따라 기존의 테이블을 사용하거나 새로 생성하거나 에러를 발생한다.
-
검사하는 방법은 <schema-info>/<table-name>과 같은 이름을 가지고, <schema-info>/<cm-field>에 명시한 필드들이 존재하며, relation을 관리하는 Bean이라면 <ejb-relation-map>/<jeus-relationship-role>/<column-map>에 명시한 Foreign Key들도 존재하는지 검사한다.
-
다음의 하위 태그를 설정한다.
태그 설명 <use-existing-table> DB에 이미 테이블이 있으면 그대로 사용하고 없는 경우에만 테이블을 생성한다. <force-creating-table> DB에 테이블이 존재해도 그 테이블을 삭제하고 새로운 테이블을 생성한다. 하위 태그를 지정하지 않을 경우 테이블이 이미 존재하면 에러를 발생하고 발생하고 없는 경우는 테이블을 생성한다.
-
태그가 없는 경우는 MS JVM 파라미터에 "-Djeus.ejb.checktable" 설정에 따라 테이블의 검사 여부를 결정한다.
설정값 설명 true 테이블 검사를 하는데 해당 테이블이 존재하지 않으면 에러가 발생한다.
(기본값)
false Bean이 start하는 시점에 테이블 검사를 하지 않기 때문에 실제 테이블을 사용할 때 에러가 발생한다.
-
-
-
스위치가 활성화되면 EJB 모듈이 undeploy될 때 지정된 테이블이 DB에서 제거된다.
-
이 옵션은 실제 상황에서 아주 조심스럽게 사용되어야 하므로 실수를 방지하기 위해 JEUS의 시스템 프로퍼티로 별도의 설정을 해야 동작한다. 즉, JEUSMain.xml의 Command 옵션에 "-Djeus.ejb.enable.configDeleteOption=true"로 설정할 때만 동작한다.
또한 <creating-table> 설정이 없는데 <deleting-table> 설정을 사용하는 경우는 거의 없으므로, <creating-table> 설정이 없을 때에는 <deleting-table> 설정이 실행되지 않는다.
-
-
-
복합 Key를 Primary Key로 사용하는 경우에 선택적으로 사용된다. 즉, ejb-jar.xml의 <prim-key-class>에 복합 Key를 위해 사용자가 구현한 Primary Key 클래스를 지정한 경우에 선택적으로 사용할 수 있다. 기본적으로는 <prim-key-class>에 선언된 모든 public 필드가 Primary Key를 구성하지만, 사용자가 필드를 선택하여 Primary Key를 구성하고 싶은 경우에 이 목록을 설정한다.
-
다음의 element를 혼동하지 않도록 한다.
-
복합 Key
Element 설명 ejb-jar.xml/<prim-key-class> 사용자가 구현한 Primary Key 클래스이다. (필수 항목) ejb-jar.xml/<primkey-field> 선언할 수 없다. <prim-key-class>에 선언한 타입은 여러 필드를 포함하는 타입이므로 하나의 필드 이름과 매핑시킬 수가 없다.
(선택 항목)
jeus-ejb-dd.xml/<prim-key-field> Primary Key 클래스의 public 필드 모두를 Primary Key로 구성하지 않고 필드를 선택하고 싶은 경우 그 목록을 선언한다. (선택 항목)
-
단일 Key
Element 설명 ejb-jar.xml/<prim-key-class> java.lang.String, java.lang.Integer 등 ejb-jar.xml/<primkey-field>의 타입이다. (필수 항목) ejb-jar.xml/<primkey-field> Primary Key에 해당하는 Entity Bean의 필드 이름이다.
<primkey-field>에 선언한 필드 이름과 <prim-key-class>에 선언한 타입이 Entity Bean 클래스에 선언된 필드 이름, 타입과 매핑되어야 한다. (선택 항목)
jeus-ejb-dd.xml/<prim-key-field> 여러 필드가 있을 경우 선택할 때 필요한 것이기 때문 선언할 필요가 없다. (선택 항목)
-
-
-
-
CMP 1.1 Entity Bean의 경우 finder 메소드에 대해서 필요한 SQL 문장을 반드시 명시해야 한다.
-
CMP 2.0의 경우에는 ejb-jar.xml에 지정된 EJB QL을 overriding할 수 있다.
<jeus-query>를 설정하면 Query 메소드(findXXX)에서 EJB QL과 JEUS EJB QL 확장을 사용할 수 있다. 이것은 ejb-jar.xml의 <query> 태그와 비슷하다. “8.3.3.3. JEUS EJB QL Extension”에서 자세하게 설명한다. 이 태그는 BEA WebLogic 애플리케이션 서버를 JEUS v4.2로 마이그레이션할 때 용이하게 하는 것이 주요 목적이다.
-
SQL들을 정의하기 위해 SQL 문장이 사용될 finder 메소드의 이름과 파라미터 그리고 SQL 문장이 설정되어야 한다. 이 문장은 finder 메소드를 생성할 때 사용된다.
지정된 문장에는 WHERE 절 다음에 나오는 부분만을 포함하고 있어야 한다. 다른 요소는 자동으로 주어진다. 여기에는 "?" 문자를 지정할 수 있고 이는 finder 메소드의 파라미터 값들을 대신하게 된다. ANSI SQL의 WHERE 절 문법을 사용할 수 있다(이 SQL은 WHERE에 포함된다).
-
<include-updates>가 true로 설정되면 finder 메소드 호출 동안 변경된 사항이 DB에 Commit되므로 finder 메소드에서 변경된 사항을 확인할 수 있다.
-
-
-
Bean을 위해 사용되는 DB의 벤더를 지정한다.
벤더 이름은 벤더 특정 최적화를 위해 EJB 엔진이 사용하게 된다. 여기서 지정된 값이 실제로 성능에 얼마나 많은 영향을 미칠 수 있는지는 확인된 바 없다. 사용 가능한 벤더의 종류는 “Appendix A. 기본 Java 타입과 DB 필드 매핑”을 참고한다. 일반적인 예는 "oracle"을 들 수 있다.
-
이 값은 또한 Java 객체와 벤더가 정한 DB 필드 타입과의 정확한 매핑을 가려내기 위하여 사용된다.
-
-
-
DB와 연결할 때 사용하는 DB Connection Pool의 JNDI 이름을 지정한다. Connection Pool은 일반적으로 도메인에 설정되고, MS JVM에 의해 실행된다.
-
-
-
CMP 2.0에서 자동으로 Primary Key를 생성하기 위해 사용하며 하위 태그들이 있다. 하위 태그에 대한 자세한 설명은 “8.2.3.3. 자동 Primary Key 생성”을 참고한다.
-
본 절에서는 CMP 2.0 설정에 대해서 설명한다.
2개의 Bean 사이에 Relationship Mapping을 설정하는 방법은 다음과 같이 경우에 따라 달라진다.
-
One-to-one/One-to-many Relationship Mapping
-
Many-to-many Relationship Mapping
One-to-one/One-to-many Relationship Mapping
2개의 Bean 간에 One-to-one/One-to-many Relationship을 설정할 때 <ejb-relation-map> 태그 내에 설정해야 한다.
다음은 'employee-manager'라는 관계를 가지는 2개의 Bean 간에 Many-to-one(= One-to-many) 관계를 설정한 예로 <ejb-relation-map> 태그에 설정한다.
[예 8.9] One-to-one/One-to-many Relationship 설정 : <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<ejb-relation-map>
<relation-name>employee-manager</relation-name>
<jeus-relationship-role>
<relationship-role-name>employee-to-manager</relationship-role-name>
<column-map>
<foreign-key-column>manager-id</foreign-key-column>
<target-primary-key-column>man-id</target-primary-key-column>
</column-map>
</jeus-relationship-role>
</ejb-relation-map>
. . .
</jeus-ejb-dd>
다음은 설정 태그에 대한 설명이다.
-
2개의 JEUS Relationship의 역할을 Relationship의 각 방향별로 하나씩 설정한다. 각 Relationship의 역할에 필요한 정보는 다음과 같다.
-
<relationship-role-name>
ejb-jar.xml의 <ejb-relationship-role-name> 태그에 정의되어 있다.
-
<column-map>
2개의 하위 태그인 <foreign-key-column>과 <target-primary-key-column>을 가진다.
태그 설명 <foreign-key-column> Relationship에서 Foreign Key의 역할을 하는 컬럼의 이름이다. <target-primary-key-column> Foreign Key 컬럼이 매핑되어야 할 테이블의 Primary Key 필드이다.
Key가 여러 개의 컬럼으로 구성되어 있으면 여러 개의 컬럼 대 컬럼 매핑을 지정할 수 있다.
-
위의 XML 예제에서는 employee 테이블의 manager-id라는 Foreign Key 컬럼이 employee-to-manager의 Many-to-one 관계를 맺기 위해 manager 테이블의 Primary Key 필드와 매핑되어 있다.
One-to-one Mapping도 이와 비슷한 방법으로 설정된다. 단, One-to-one 관계에서는 Primary Key 컬럼과 Foreign Key 컬럼이 테이블 어디에 존재해도 상관없으며, One-to-many에서는 반드시 “many” 측의 테이블이 Foreign Key 컬럼을 가지고 있다는 것을 유념한다.
Many-to-many Relationship Mapping
2개의 Bean 간에 Many-to-many 관계를 맺기 위해서는 One-to-one의 관계에서 설정된 정보 외에 추가로 <table-name>과 <jeus-relationship-role>의 정보가 반드시 설정되어야 한다.
다음은 Many-to-many 관계 설정을 나타내는 'student-course'의 예이다.
[예 8.10] Many-to-many Relationship Mapping 설정 : <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<ejb-relation-map>
<relation-name>student-course</relation-name>
<table-name>STUDENTCOURSEJOIN</table-name>
<jeus-relationship-role>
<relationship-role-name>student</relationship-role-name>
<column-map>
<foreign-key-column>
student-id <!--This column in join table-->
</foreign-key-column>
<target-primary-key-column>
stu-id <!--This column in student table-->
</target-primary-key-column>
</column-map>
</jeus-relationship-role>
<jeus-relationship-role>
<relationship-role-name>course</relationship-role-name>
<column-map>
<foreign-key-column>
course-id <!--This column in join table-->
</foreign-key-column>
<target-primary-key-column>
cou-id <!--This column in course table-->
</target-primary-key-column>
</column-map>
</jeus-relationship-role>
</ejb-relation-map>
. . .
</jeus-ejb-dd>
다음은 설정 태그에 대한 설명이다.
| 태그 | 설명 |
|---|---|
| <table-name> | Many-to-many 관계의 join 테이블 이름을 지정한다. |
| <jeus-relationship-role> | 2개의 <jeus-relationship-role>에서 각 Join 테이블 2개의 Foreign Key 컬럼을 Bean이 사용하는 테이블의 Primary Key 컬럼에 매핑한다. |
위의 예에서 두 JEUS Relationship Role이 어떻게 사용되고 있는지 확인할 수 있다. 각 role은 Join 테이블의 두 컬럼 중 한 개와 실제 Bean이 사용하는 테이블의 Primary Key 컬럼이 매핑하도록 선언하고 있다.
클라이언트에 Instant EJB QL 질의를 가능하게 하려면, JEUS EJB DD의 <enable-instant-ql> 태그를 true로 설정한다. 자세한 내용은 “Appendix B. Instant EJB QL API Reference”를 참고한다.
[예 8.11] Instant EJB QL 설정 : <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<beanlist>
. . .
<jeus-bean>
. . .
<enable-instant-ql>true</enable-instant-ql>
</jeus-bean>
. . .
</beanlist>
. . .
</jeus-ejb-dd
본 절에서는 JEUS CMP에 관련된 EJB QL Extension에 대해 설명한다.
이 확장자들은 새로운 키워드들과 subquery들, ejbSelect() 메소드에 의해 리턴되는 ResultSet, 집합 함수, 다양한 EJB QL 질의 그리고 GROUP BY 키워드이다.
CMP 2.0 Bean의 findByXXX() 메소드와 ejbSelectXXX() 메소드에서는 그 home interface와 ejb-jar.xml의 EJB QL 문장이 연계되어 있어야 한다. JEUS는 표준 EJB QL 언어에 몇 가지 사항들을 추가한다. 이 추가 사항들은 ejb-jar.xml 파일이나 EJB QL에서 사용된다. 이 기능이 사용된 ejb-jar.xml의 예는 “8.5. 완전한 CMP 2.0 Entity Bean 예제”를 참고한다.
주의
본 안내서에서 제공된 EJB QL Extension들은 표준 EJB 2.1 QL에서 지원하지 않는 항목들로서 이것을 이용하여 작성된 EJB 애플리케이션은 Java EE 표준에 준하지 않으므로 이식성이 떨어진다. 이 의미는 여기서 제공된 확장 기능을 사용하여 생성한 EJB 컴포넌트는 다른 Java EE 서버에 deploy될 수 없다는 것이다. JEUS의 EJB QL Extension은 대부분 표준 SQL처럼 작동한다. 그러므로 더 상세한 정보는 SQL을 참고한다.
JEUS EJB QL Extension 키워드 추가사항
JEUS에서는 다음과 같은 비표준 키워드들이 EJB QL 문장에 사용될 수 있다.
JEUS EJB QL Extension Subquery
JEUS의 EJB QL Subquery는 EJB QL 질의의 하나로 WHERE 절에 포함된 또 다른 질의절을 의미한다. 이것은 SQL 질의와 Subquery의 관계와 비슷하다.
다음의 예에서는 중첩된 EJB QL 질의의 한 예로서 평균 이상의 월급을 받는 고용인들을 질의한다.
SELECT OBJECT(e)
FROM EmployeeBean AS e
WHERE e.salary >
(SELECT AVG(e2.salary)
FROM EmployeeBean AS e2)
-
리턴 타입
JEUS EJB QL 질의에 대해 다음과 같은 리턴 타입들이 올 수 있다.
-
Single value 또는 <cmp-field>에 대응하는 Collection(위의 예에서 e.salary와 같은 값들)
-
집합 함수를 통해서 생성된 한 개의 리턴값(예: MAX(e.salary))
-
간단한 Primary Key(Compound Primary Key가 아닌)를 포함한 cmp-Bean(예: SELECT OBJECT(emp))
-
-
비교 연산자
JEUS EJB QL은 Subquery를 비교 연산자의 피연산자로 사용할 수 있다.
JEUS EJB QL은 비교 연산자는 다음과 같다.
-
[NOT] IN, [NOT] EXISTS, [NOT] UNIQUE
-
<, >, <=, >=, =, <>
-
위 연산자와 ANY, ALL, SOME의 조합
-
다음은 매니저가 아닌 직원을 추출하는 예이다.
SELECT OBJECT(employee)
FROM EmployeeBean AS employee
WHERE employee.id NOT IN
(SELECT employee2.id
FROM ManagerBean AS employee2)
다음은 Subquery 결과값이 없는지 테스트하는 NOT EXISTS 연산자의 예이다("NOT"은 값이 있는지를 테스트하기 위해 제거될 수 있다).
SELECT OBJECT(cust)
FROM CustomerBean AS cust
WHERE NOT EXISTS
(SELECT order.cust_num
FROM OrderBean AS order
WHERE cust.num = order.cust_num)위 질의의 결과는 주문을 하지 않은 모든 고객의 명단이 된다.
마지막 예는 상호 연관된(correlated) 질의라고 할 수 있는데, 그 이유는 Subquery의 결과가 상위 질의의 파라미터로 반영되어야 하기 때문이다. 의존 관계가 없는 질의를 비상호 연관(uncorrelated) 질의라고 한다.
다음의 예는 UNIQUE 연산자의 사용을 보여주고 있다. 이 연산자는 result set의 row 중 중복된 것이 있는지를 확인한다. 0개 또는 1개의 row이거나, Subquery의 결과 내에 있는 모든 레코드가 유일하다면 true를 리턴한다. 이 연산자에 NOT을 붙이면 반대의 결과를 얻게 된다.
SELECT OBJECT(cust)
FROM CustomerBean AS cust
WHERE UNIQUE
(SELECT cust2.id FROM CustomerBean AS cust2)
다음은 ">" 연산자의 예로서, 다른 연산자와 마찬가지로 Subquery의 결과값과 사용될 수 있다.
SELECT OBJECT(employee)
FROM EmployeeBean AS employee
WHERE employee.salary >
(SELECT AVG(employee2.salary)
FROM EmployeeBean AS employee2)위의 JEUS EJB QL 질의는 평균 월급보다 많이 받는 모든 고용인의 결과를 리턴한다.
참고로 ANY, ALL, SOME이 사용되지 않는 경우에는 반드시 한 개의 값만이 Subquery의 결과로 리턴되어야 한다(이 경우에서는 평균 월급). ANY, ALL, SOME 연산자는 하나의 값보다 더 많은 값을 리턴하는 Subquery에 사용한다. 이 연산 작업은 다음과 같이 해석할 수 있다.
-
<Operand> <arithmetic operator> ANY <subquery>
subquery의 결과 중 적어도 한 개의 값이 true를 리턴하면 true를 리턴한다.
-
<Operand> <arithmetic operator> SOME <subquery>
"ANY"와 같은 의미를 가진다.
-
<Operand> <arithmetic operator> ALL <subquery>
Subquery의 결과 모두가 true를 리턴해야 true를 리턴한다.
참고
XML DD 파일에 ">"와 "<" 문자를 넣으려 할 때는 CDATA 부분에 포함시켜야 한다. 그렇지 않으면 XML Parser가 혼동을 일으키고 XML 태그 지정문자로 인식한다.
[예 8.12] XML DD 파일에 ">"와 "<" 문자 삽입 : <<ejb-jar.xml>>
. . .
<query>
<description>method finds large orders</description>
<query-method>
<method-name>findLargeOrders</method-name>
<method-params></method-params>
</query-method>
<ejb-ql>
<![CDATA[SELECT OBJECT(o) FROM Order o WHERE o.amount > 1000]]>
</ejb-ql>
</query>
. . .
JEUS EJB QL Extension ResultSet
JEUS EJB 엔진은 복수 컬럼인 java.sql.ResultSet 객체를 반환하는 ejbSelect() 질의를 지원한다. 그러므로 ejbSelect 메소드의 SELECT 문 안에 콤마(,)로 구분된 Target 필드의 목록을 지정할 수 있다.
SELECT employee.name, employee.id, employee.salary FROM EmployeeBean AS employee
위의 질의는 모든 EmployeeBean Instance의 name, id, salary로 구성된 java.sql.ResultSet을 생성한다. 이 ResultSet은 "name", "id", "salary"의 컬럼으로 구성된 레코드를 포함하게 된다. 이 ResultSet의 각 레코드는 해당하는 Entity Bean Instance를 표현한다. ResultSet들은 <cmp-field> 값(Bean이나 relationship filed가 아닌)만을 반환한다.
참고
ejbSelect() 메소드를 사용해서 java.sql.ResultSet 종류의 객체를 얻어와 모든 작업을 마쳤을 때에는 ResultSet.close()를 호출해야 한다. 이 close() 메소드는 EJB 엔진에 의해 자동적으로 호출되지 않는다.
JEUS EJB QL Extension Dynamic Query
JEUS EJB QL은 EJB QL 질의를 프로그램적으로 구현할 수 있도록 지원한다. 이것은 Instant EJB QL 기능으로 가능한 것이다. 본 절에서는 JEUS CMP 2.0에서 Instant EJB QL을 프로그래밍할 때 필요한 기본적인 사항들을 설명한다.
다음 코드에서는 CMP 2.0 Home Interface의 Instant EJB QL 사용법을 보여주고 있다. 이 코드는 순수하게 클라이언트 측의 것이다. 이 코드가 작동되도록 하려면 Instant EJB QL을 사용하도록 CMP Bean에 설정되어 있어야 한다. 이 부분에 대해서는 “8.3. Entity EJB 설정”을 참고한다.
import jeus.ejb.Bean.objectbase.EJBInstanceFinder; import java.util.Collection; . . . Context initial = new InitialContext(); Object objref = initial.lookup("emp"); EmpHome home = (EmpHome) PortableRemoteObject.narrow(objref, EmpHome.class); EJBInstanceFinder finder = (EJBInstanceFinder) home; java.util.Collection foundBeans = finder.findWithInstantQL (“<EJB QL query sentence>”); // Use foundBeans collection… . . .
위 예에서의 <EJB QL query sentence>는 파라미터 없는 완전한 EJB QL 문장으로 대체되어야 한다("?"가 허용되지 않는다). 이 API에 대해서는 “Appendix B. Instant EJB QL API Reference”를 참고한다.
JEUS EJB QL Extension GROUP BY 키워드
JEUS EJB QL은 GROUP BY와 GROUP BY HAVING 절을 지원한다. 이들은 다음과 같이 작동한다.
-
<SELECT statement> GROUP BY <grouping column(s)>
SELECT 문장이 실행되면 레코드들이 생성되고, GROUP BY 문장은 <grouping column(s)>에 지정된 컬럼(들)의 셋을 검색한다. 같은 값을 갖는 이 컬럼(들) 내의 모든 레코드들은 하나의 레코드로 합쳐지고 중복되는 것들은 버려진다.
SELECT employee.departmentName FROM EmployeeBean AS employee GROUP BY employee.departmentName위 질의는 employee Bean의 유일한 모든 departmentName의 목록을 결과값으로 가진다.
-
<SELECT statement> GROUP BY <grouping column(s)> HAVING <condition>
이런 형식의 문장은 이전에 설명한 예제와 같은 방식으로 동작하지만, <condition>에 설정된 것을 만족시키는 컬럼 그룹만이 포함된다.
SELECT employee.departmentName FROM EmployeeBean AS employee GROUP BY employee.departmentName HAVING COUNT(employee.departmentName) >= 3
위의 질의는 2개 이상의 EmployeeBean Instance가 발견된 모든 유일한 departmentName들의 목록을 반환한다(즉, 3 이상의 employee들을 가진 department의 목록).
예를 들어 [표 8.3]의 데이터에 EJB QL 질의를 실행시키면 [표 8.4]와 같은 결과가 출력된다.
[표 8.3] EmployeeBean Instance을 위한 EJB 필드들
| id | departmentName |
|---|---|
| johnsmith | R&D |
| peterwright | R&D |
| lydiajobs | R&D |
| catherinepeters | Marketing |
이 결과는 HAVING 조건이 적어도 3개의 레코드를 가진 컬럼 그룹을 포함시켜야 한다고 명시되었기
때문이다. 더 자세한 GROUP BY, GROUP BY HAVING 절에 대한 정보는 SQL 문서들을 참고한다.
참고
JEUS EJB QL에서는 GROUP BY와 GROUP BY HAVING 문장을 Subquery 또는 최상위의 질의에서 사용할 수 있다. 후자의 경우에는 java.lang.String 객체의 집합이 리턴된다. 최상위의 GROUP BY와 GROUP BY HAVING 문장은 Bean 객체를 리턴할 수 없다.
CMP에서 EJB가 생성될 때 EJB 데이터가 Backend DB에 기록되는 시점을 설정할 수 있다.
| 메소드 | 설명 |
|---|---|
| ejbCreate | ejbCreate()를 실행 후 ejbPostCreate()를 실행하기 전에 새로운 EJB 데이터를 삽입한다. |
| ejbPostCreate | ejbCreate()와 ejbPostCreate()를 완성한 후에 새로운 EJB 데이터를 삽입한다. 기본값으로 사용된다. |
DB Insert Delay 설정은 jeus-ejb-dd.xml에서 <jeus-bean>의 <database-insert-delay> 태그 내에서 구성된다.
[예 8.13] DB Insert Delay 설정 : <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<beanlist>
. . .
<jeus-bean>
. . .
<database-insert-delay>ejbCreate</database-insert-delay>
. . .
</jeus-bean>
. . .
</beanlist>
. . .
</jeus-ejb-dd>
본 절에서는 JEUS의 Entity EJB 성능 튜닝 방법에 대해서 자세히 설명한다.
본 절에서 제공하는 튜닝 방법들은 “제4장 EJB의 공통 특성”과 “제7장 Session Bean”의 "object management"에서 제공한 방법들과 함께 Entity Bean에 적용할 수 있다.
모든 Entity Bean의 성능 튜닝에 공통적으로 필요한 설정은 다음과 같다.
-
엔진 메인 모드 선택과 클러스터링 적용 여부
-
Entity Cache 크기 설정 - DB 벤더 설정
다음은 모든 Entity Bean의 성능 튜닝을 위한 설명이다.
엔진 메인 모드 선택과 클러스터링 적용 여부
다음은 <engine-type>을 선택할 때와 몇 개의 EJB 엔진에 EJB를 클러스터링할지를 선택할 때 주요 판단 기준이 될 수 있는 규칙을 정리한 표이다.
[표 8.5] Entity Bean 엔진 타입 선택과 클러스터링 사용 여부
| Bean당 요청 수 | 많은 EJB 엔진 다수의 CPU | 적은 EJB 엔진 1개 이상의 CPU | EJB 엔진 1개 CPU 1개 |
|---|---|---|---|
| 자주 사용 | EJB를 클러스터링하고, SINGLE_OBJECT를 사용한다. | EJB를 클러스터링하고, MULTIPLE_OBJECT를 사용한다. | 더 많은 EJB 엔진을 사용하도록 한다. 그렇지 않으면, 클러스터링하지 않고, MULITPLE_OBJECT를 사용한다. |
| 보통으로 사용 | EJB를 클러스터링하고, SINGLE_OBJECT를 사용한다. | EJB를 클러스터링하고, MULTIPLE_OBJECT를 사용한다. | EJB를 클러스터링하지 않고, EXCLUSIVE_ACCESS를 사용한다. |
| 조금 사용 | EJB를 클러스터링하지 않고, EXCLUSIVE_ACCESS를 사용한다. | EJB를 클러스터링하지 않고, EXCLUSIVE_ACCESS를 사용한다. | EJB를 클러스터링하지 않고, EXCLUSIVE_ACCESS를 사용한다. |
물론 Entity Bean의 DB 데이터가 외부의 WAS가 아닌 컴포넌트에 의해 변경되는 환경에서는 SINGLE_OBJECT나 MULTIPLE_OBJECT를 사용해야 한다. 그리고 Failover를 위해서는 Bean을 클러스터링해야 한다.
SINGLE_OBJECT와 MULTIPLE_OBJECT 모드 중 하나를 선택할 때 마지막으로 고려해야 할 사항은 대상 Bean의 트랜잭션 처리시간이다(즉, Bean 내부에서 트랜잭션이 시작하고 commit되어 끝날 때까지의 평균시간). 그 시간이 아주 길면 MULTIPLE_OBJECT 모드를 선택하기를 권장하고, 이 모드에서 사용 가능한 동시성을 사용해야 한다. 그 시간이 반대로 짧으면 SINGLE_OBJECT 모드 사용을 권장한다.
만약에 위의 "규칙"이 준수되면 EJB 엔진은 최적의 성능으로 ejbLoad()를 호출할 수 있다.
참고
위의 테이블에서 사용된 "자주 사용되는", "보통으로 사용되는", "조금 사용되는"의 의미를 명확하게 정의할 수 없다. 약간의 직관력과 많은 테스트가 주어진 환경에 최적의 설정을 찾는 방법일 것이다.
Entity Cache 크기 설정
Entity Cache는 passivate된 Entity Bean Instance들의 저장소 역할을 한다. Instance들은 Entity Bean이 다시 Activate가 되면 Cache에서 나오게 된다.
<entity-cache-size> 크기를 크게(수백 개의 Instance가 수용되도록) 설정하면 passivate된 Bean들이 다시 Activate될 때 새로운 Entity Bean Instance들이 생성되지 않아도 되므로 성능이 좋아질 것이다. 그러나 메모리 관리가 가장 중요한 사항이라면 이 값을 적게 주거나 아예 사용하지 않도록 한다(값이 '0'이면 Entity Cache를 사용하지 않는다).
DB 벤더 설정
<db-vendor> 태그를 올바르게 설정한다. 모든 경우는 아니지만 어떤 상황에서는 Oracle과 같은 벤더의 제품을 위해서 EJB 엔진이 DB와의 연결을 최적화시킨다. 이 태그에 사용할 수 있는 DBMS 벤더의 이름 값들은 "JEUS XML Reference"의 "제11장.domain.xml EJB 엔진 설정"을 참고한다.
다음은 BMP와 CMP 1.1 튜닝에 대한 설명이다.
Non-modifying 메소드 등록
DB에 표현된 상태 정보를 변경하지 않는 Entity Bean의 모든 업무 메소드들은 JEUS EJB 모듈 DD의 <non-modifying-method> 태그에 등록되어야 한다. 이렇게 하면 EJB 엔진이 ejbStore()를 호출하지 않아 효율적으로 운영될 수 있다. 이 튜닝은 BMP와 CMP 1.1 Bean에게만 적용할 수 있다.
다음은 CMP 1.1/2.0 튜닝에 대한 설명이다.
엔진 Sub-mode 선택
CMP Bean을 사용할 때 <subengine-type>을 선택하면 EJB 엔진이 ejbLoad(), ejbFInd() 메소드를 최적화해서 사용할 수 있다.
<subengine-type>을 선택하는 주요 기준은 다음과 같다.
-
CMP Bean이 읽기 작업을 쓰기 작업보다 더 많이 할 것이라 예상되면 ReadLocking 모드를 사용한다.
-
CMP Bean이 쓰기 작업을 읽기 작업보다 더 많이 할 것이라 예상되면 WriteLocking 또는 WriteLockingFind 모드를 사용한다.
Fetch Size 설정
시스템 메모리의 과용을 감수하더라도 높은 성능을 원한다면 CMP Bean의 <fetch-size> 태그를 시스템 메모리의 과용을 감수하더라도 높게 설정해야 한다. 큰 값을 설정하면 매 호출마다 많은 양의 데이터를 읽어오기 때문에 네트워크를 효과적으로 사용할 수 있다. 그러나 EJB 엔진은 많은 양의 데이터를 Caching해야 하기 때문에 시스템 자원을 많이 소모하게 되어 각 호출에 대한 대기시간이 증가한다.
반대의 경우 만약 시스템 메모리의 절약이 높은 우선순위를 가지고 느린 네트워크 속도를 감수할 수 있다면 이 값을 상대적으로 낮게 설정한다. 기본값은 "10"이다. 대부분의 경우 "100"은 높은 값이고 "10"보다 낮은 값은 낮은 값으로 생각할 수 있다.
Initial Caching 설정
높은 운영 성능을 위해 많은 시스템 메모리 사용을 감수할 수 있다면, CMP Bean의 <init-caching> 값을 true로 설정한다. 이렇게 설정하면 EJB 엔진이 기동(Booting)할 때 모든 DB의 레코드들이 읽혀져 Entity Bean Instance로 전달된다. 결과적으로 엔진 기동(Booting) 시간이 오래 걸리겠지만, 처음의 접근시간을 훨씬 줄일 수 있다.
반대의 경우 만약 시스템 메모리의 절약 또는 빠른 엔진 기동(Booting)시간이 우선이라면 이 값은 false로 설정해야 한다. 만약 DB 테이블이 EJB에 아주 많이 매핑되어 있는 경우(수백, 수천 레코드)에는 <init-caching>가 false로 설정되어야 할 것이다. 그러나 EJB가 read-only(ejbLoad()가 한 번만 호출되는 것을 암시)라면 이 옵션을 강력히 추천한다.
EJB 코드, 표준 EJB DD, JEUS DD가 함께 설정되고 작동될 수 있는지 보여주기 위해 본 절에서는 완전한 CMP 2.0 Bean의 예를 제시한다. 이 예제는 책을 개념으로 모델화한 Book EJB이다.
기본적으로 모든 예에 주석을 달지 않았고 CMP 2.0 Bean이 jeus-ejb-dd.xml에 설정하는 방법만 보여준다. 예제를 deploy하려면 패키징 후에 EJB로 deploy한다. 자세한 내용은 “제3장 EJB 모듈”을 참고한다.
JEUS의 ejb-jar.xml에서 EJB QL 사용 예는 본 절의 절 8.5. “Java EE EJB DD”를 참고한다.
Remote Interface
[예 8.14] Remote Interface : <<Book.java>>
package test.book;
import java.rmi.RemoteException;
import javax.ejb.EJBObject;
public interface Book extends EJBObject {
public String getTitle() throws RemoteException;
public void setTitle(String title) throws RemoteException;
public String getAuthor() throws RemoteException;
public void setAuthor(String author) throws RemoteException;
public double getPrice() throws RemoteException;
public void setPrice(double price) throws RemoteException;
public String getPublisher() throws RemoteException;
public void setPublisher(String publisher)
throws RemoteException;
public String toBookString() throws RemoteException;
}
Home Interface
[예 8.15] Home Interface : <<BookHome.java>>
package test.book;
import java.rmi.RemoteException;
import javax.ejb.CreateException;
import javax.ejb.FinderException;
import javax.ejb.EJBHome;
import java.util.*;
public interface BookHome extends EJBHome {
public Book create(String code, String title, String author,
double price, String publisher)
throws CreateException, RemoteException;
public Book findByPrimaryKey(String code)
throws FinderException, RemoteException;
public Collection findByTitle(String title)
throws FinderException, RemoteException;
public Collection findInRange(String from, String to)
throws FinderException, RemoteException;
public Collection findAll()
throws FinderException, RemoteException;
}
Bean Implementation
[예 8.16] Bean Implementation : <<BookEJB.java>>
package test.book;
import javax.ejb.EntityBean;
import javax.ejb.EntityContext;
public abstract class BookEJB implements EntityBean {
public String ejbCreate(String code, String title,
String author, double price, String publisher) {
setCode(code);
setTitle(title);
setAuthor(author);
setPrice(price);
setPublisher(publisher);
return null;
}
public void ejbPostCreate(String code, String title,
String author, double price, String publisher) {}
public abstract String getCode();
public abstract void setCode(String code);
public abstract String getTitle();
public abstract void setTitle(String title);
public abstract String getAuthor();
public abstract void setAuthor(String author);
public abstract double getPrice();
public abstract void setPrice(double price);
public abstract String getPublisher();
public abstract void setPublisher(String publisher);
public String toBookString() {
return getCode() + "- [" + getTitle() + "] by " +
getAuthor() + " | " + getPrice() + " | " +
getPublisher();
}
public BookEJB() {}
public void setEntityContext(EntityContext ctx) {}
public void unsetEntityContext() {}
public void ejbLoad() {}
public void ejbStore() {}
public void ejbActivate() {}
public void ejbPassivate() {}
public void ejbRemove() {}
}
Java EE EJB DD
[예 8.17] Java EE EJB DD : <<ejb-jar.xml>>
<?xml version="1.0"?>
<ejb-jar version="3.1" xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-Instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/ejb-jar_3_1.xsd">
<enterprise-Beans>
<entity>
<ejb-name>BookBean</ejb-name>
<home>test.book.BookHome</home>
<remote>test.book.Book</remote>
<ejb-class>test.book.BookEJB</ejb-class>
<persistence-type>Container</persistence-type>
<prim-key-class>java.lang.String</prim-key-class>
<reentrant>false</reentrant>
<cmp-version>2.x</cmp-version>
<abstract-schema-name>Book</abstract-schema-name>
<cmp-field><field-name>code</field-name></cmp-field>
<cmp-field><field-name>title</field-name></cmp-field>
<cmp-field><field-name>author</field-name></cmp-field>
<cmp-field><field-name>price</field-name></cmp-field>
<cmp-field><field-name>publisher</field-name></cmp-field>
<primkey-field>code</primkey-field>
<query>
<query-method>
<method-name>findByTitle</method-name>
<method-params>
<method-param>
java.lang.String
</method-param>
</method-params>
</query-method>
<ejb-ql>
SELECT OBJECT(b) FROM Book b
WHERE b.title = ?1 ORDERBY b.price
</ejb-ql>
</query>
<query>
<query-method>
<method-name>findInRange</method-name>
<method-params>
<method-param>
java.lang.String
</method-param>
<method-param>
java.lang.String
</method-param>
</method-params>
</query-method>
<ejb-ql>
SELECT OBJECT(b) FROM Book b
WHERE b.title BETWEEN ?1 AND ?2
</ejb-ql>
</query>
<query>
<query-method>
<method-name>findAll</method-name>
<method-params/>
</query-method>
<ejb-ql>
SELECT OBJECT(b) ORACLEHINT '/*+ALL_ROWS*/' FROM Book b
</ejb-ql>
</query>
</entity>
</enterprise-Beans>
<assembly-descriptor>
<container-transaction>
<method>
<ejb-name>BookBean</ejb-name>
<method-name>*</method-name>
<method-params/>
</method>
<trans-attribute>Required</trans-attribute>
</container-transaction>
</assembly-descriptor>
</ejb-jar>
참고
굵은 글자의 3줄이 비표준의 JEUS 전용 EJB QL이다("ORDERBY", "BETWEEN", "ORACLEHINT").
JEUS EJB DD
[예 8.18] JEUS EJB DD : <<jeus-ejb-dd.xml>>
<?xml version="1.0"?>
<jeus-ejb-dd xmlns="http://www.tmaxsoft.com/xml/ns/jeus">
<module-info/>
<beanlist>
<jeus-bean>
<ejb-name>BookBean</ejb-name>
<export-name>book</export-name>
<export-port>0</export-port>
<export-iiop><only-iiop>false</only-iiop></export-iiop>
<persistence-optimize>
<engine-type>EXCLUSIVE_ACCESS</engine-type>
<non-modifying-method>
<method-name>getTitle</method-name>
</non-modifying-method>
<non-modifying-method>
<method-name>getAuthor</method-name>
</non-modifying-method>
<non-modifying-method>
<method-name>getPrice</method-name>
</non-modifying-method>
<non-modifying-method>
<method-name>getPublisher</method-name>
</non-modifying-method>
<non-modifying-method>
<method-name>toBookString</method-name>
</non-modifying-method>
</persistence-optimize>
<schema-info>
<table-name>Booktable</table-name>
<cm-field><field>code</field></cm-field>
<cm-field><field>title</field></cm-field>
<cm-field><field>author</field></cm-field>
<cm-field><field>price</field></cm-field>
<cm-field><field>publisher</field></cm-field>
<creating-table>
<use-existing-table/>
</creating-table>
<deleting-table>true</deleting-table>
<db-vendor>oracle</db-vendor>
<data-source-name>datasource1</data-source-name>
</schema-info>
<enable-instant-ql>true</enable-instant-ql>
</jeus-bean>
</beanlist>
</jeus-ejb-dd>