Table of Contents
This chapter describes the concept of EJB clustering and how to configure main functions of EJB.
In order to use the failover and load balancing functions in EJB, individual beans may be deployed across several EJB engines to form a cluster. Clustering is accomplished on the component level (individual beans) and may be used by Stateless/Stateful session beans and entity beans. A Message Driven Bean (MDB) is not a clustering target.
JEUS EJB clustering has the following two functions:
The following figure explains two major functions of EJB clustering, load balancing and failover.
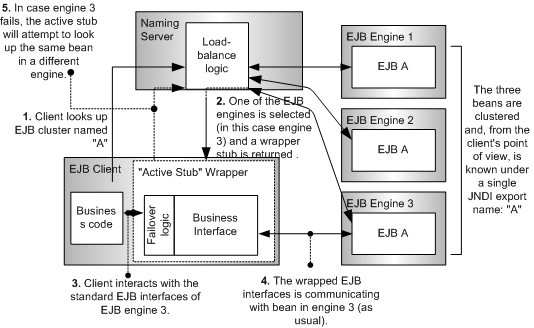
If you deploy modules that need clustering, they are all bound to the same name in the Naming Service. Using this name, client can perform load-balancing and failover. Therefore, even if you deploy the same module by binding it to the Naming Server using a different name, the module will not be included in the cluster.
Note
Stateful session beans use the JEUS session manager for failover. There is only one session manager for each EJB engine, and therefore the clustering scope of a bean should not be dependent on the individual bean. For example, if bean A is bound to EJB engine1 and EJB engine2, and bean B is bound to EJB engine1 and engine3, the session manager wrongly assumes that the bean A and B are clustered on EJB enigne1, engine2, and engine3.
The following explains major functions of EJB clustering.
When a client requests for bean A through lookup or injection, a Naming Server randomly selects and returns one of the three beans. This implies that each of the three beans will receive an equal share of requests. Thus, the client can expect to increase the maximum system performance by three times than when having only one engine that services all the requests, not counting the small overhead associated for load balancing.
Based on the bean type, the client operates as follows:
-
For stateless beans
-
EJB 3.x
The client performs load balancing for each invoked method. Note that the first call goes to the EJB engine selected in a lookup.
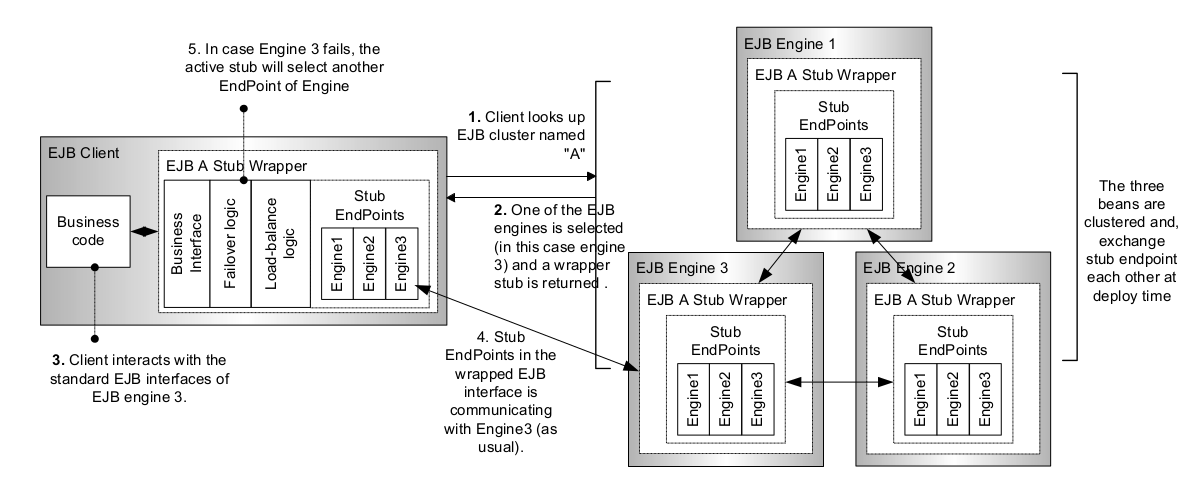
In JEUS 7 or earlier, clients could sent requests only to the EJB engine to which they sent the initial lookup request since only lookup load balancing was supported. However, in JEUS 8, they can send requests to engines other than the one to which the lookup request has been sent. Such load balancing of method calls is enabled because the engine contains endpoints such that client requests can be sent to other engines. Refer to [Figure 6.2].
The following are the load balancing methods available in JEUS 8:
Category Description RoundRobin Forwards requests to server instances on a round-robin basis. Random Forwards requests to servers randomly. LocalLinkPreference Forwards requests to the server instance on which a lookup has been performed. A load balancing policy can be configured in the system property jeus.ejb.cluster.selection-policy. For more information, refer to JEUS Reference Book. "1.8. EJB System Properties".
-
EJB 2.x
Clients select an EJB engine for a lookup using jeus.jndi.clusterlink.selection-policy, and all requests are sent to the engine.
-
-
For stateful engines
The client selects an engine to which a lookup will be performed using the jeus.jndi.clusterlink.selection-policy property, and all requests are sent to the engine.
The following table summarizes the load balancing mechanism for each EJB version and engine method.
| Category | New InitialContext() | Lookup | Method call |
|---|---|---|---|
| EJB 2.x, EJB 3.x - Stateful | O (Random) | O | X |
| EJB 3.x - Stateless | O (Random) | X | O |
To perform load balancing for stateless EJB 3.x engines in the same way as EJB 2.x engines even at the expense of compromising performance, refer to "6.3. Configuring EJB Clustering" and use the clustering method for JEUS 7 and earlier versions.
Failover is the ability to recover from a failure in a single EJB service (e.g., OS crash, network disruption, or severe EJB engine failure).
There are two types of recoveries that the JEUS system can perform:
-
Re-issuing of a pending (incoming) request to a different bean than the one originally intended if that bean is found to be inaccessible when the client's request is received.
Simply perform load balancing algorithm by excluding the failed/unreachable EJB engine. Select a working, accessible bean or engine and process the new client request.
In JEUS, this fail over re-routing of a request is actually handled by the EJB stub from the client side. This stub is called an "active stub" and is simply a wrapper class for the standard EJB interfaces. The difference when using a wrapper class is that they contain logic that determines if the currently connected bean or EJB engine has failed. If a failure is detected, the active stub, on its own initiative, will request JNDI server for a new stub on behalf of the currently running EJB engine. (Refer to step 5 in either [Figure 6.1] or [Figure 6.2].)
-
Re-issuing a request in progress to another bean in the cluster if the current bean experiences some kind of runtime failure
Recovery method is very limited in this situation. If the failure is detected during a request, we have no way of telling how much the bean has processed the request and which runtime error occurred at the time of the failure. Simply re-invoking the same method again in a different bean in the cluster could potentially be dangerous, since that may lead to other side effects.
To make this clear, consider a bean instance A. One of its business methods increments the value of a database field by one (e.g., i++). Let's assume that a failure occurs right after the increment is executed. In response to the failure, if you simply try to re-invoke the same business method through another bean B, the method will re-execute the increment. Thus, we would end with an inconsistent, erroneous value in the database. You can avoid such a critical error by declaring an idempotent method. For details about using an idempotent method for recovery, refer to "6.2.3. EJB Recovery through Idempotent Methods".
The two scenarios differ by when an error condition is detected. The first method is used for a situation when a remote business method has not been invoked yet, and the second is used for a situation when the bean is already processing the request.
An Idempotent method is a getter method that has no side effects. This means that we can invoke an idempotent method with the assurance that no states (e.g., instance variables, database fields, etc.) are changed during its execution.
An idempotent method can be used to deal with the second recovery issue of "6.2.2. Failover (EJB Restoration)": if a method is idempotent, we can safely re-invoke it on a different bean even if the first attempt to invoke the method failed during execution. However, if a method is not idempotent, there is nothing we can do in such a scenario. It is better to throw an exception than re-executing the method when a runtime error occurs. Hence, EJB failover performs better when more Idempotent methods are used. The status of the business method must be identified before configuring it.
A stateful session bean uses JEUS session manager to back up sessions. Generally, session state changes according to each business method invocation. Thus the session manager requests for a back up of sessions to JEUS session manager whenever a method is called and the result is returned in JEUS. This backup process is also called Session replication.
JEUS session manger can copy sessions either synchronously or asynchronously, which is called a replication mode in JEUS.
Both methods have pros and cons, thus JEUS lets the user select the mode according to the bean and business method characteristics. The user also can specify not to use session replication. For more information, refer to "6.3. Configuring EJB Clustering".
Note
In JEUS, by default, session replication uses the Sync mode for stateful session beans that are clustered. But this configuration can be change by the user.
EJB clustering can be configured either by using annotation in the bean class or the jeus-ejb-dd.xml file. Configuration items for clustering include the Bean to be configured, idempotent methods of the bean, and session replication mode of each bean or method.
This section shows how to configure annotation and descriptor (xml) for clustering through examples.
Configure classes or methods of a clustered bean by using annotation as follows.
[Example 6.1] Configuring Clustering through Annotation: <<CounterEJB.java>>
package ejb.basic.statelessSession;
import javax.ejb.Stateful;
import jeus.ejb.Clustered;
import jeus.ejb.Replication;
import jeus.ejb.ReplicationMode;
@Stateful(name="counter", mappedName="COUNTER")
@Clustered(useDlr = true)
@Replication(ReplicationMode.SYNC)
@CreateIdempotent
public class CounterEJB implements Counter, CounterLocal {
private int count = 0;
public int increaseAndGet() {
return ++count;
}
@Replication(ReplicationMode.NONE)
public void doNothing(int a, String b) {
}
@Idempotent
public int getResult() {
return count;
}
@Idempotent
@jeus.ejb.Replication(ReplicationMode.ASYNC)
public int getResultAnother() {
return count;
}
...
}
Descriptions for each class are as follows:
The following configuration for each clustered bean can be configured inside the <clustering> tag in the JEUS EJB module DD file (jeus-ejb-dd.xml).
[Example 6.2] Configuring Clustering by using XML: <<jeus-ejb-dd.xml>>
<jeus-ejb-dd>
. . .
<beanlist>
. . .
<jeus-bean>
<ejb-name>counter</ejb-name>
<export-name>COUNTER</export-name>
. . .
<clustering>
<enable-clustering>true</enable-clustering>
<use-dlr>true</use-dlr>
<ejb-remote-idempotent-method>
<method-name>getResult</method-name>
</ejb-remote-idempotent-method>
<ejb-remote-idempotent-method>
<method-name>getResultAnother</method-name>
</ejb-remote-idempotent-method>
<create-idempotent>true</create-idempotent>
<replication>
<bean-mode>sync</bean-mode>
<methods>
<method>
<method-name>doNothing</method-name>
<method-params>
<method-param>int</method-param>
<method-param>java.lang.String</method-param>
</method-params>
<mode>none</mode>
</method>
<method>
<method-name>getResultAnother</method-name>
<method-params>
<method-param>void</method-param>
</method-params>
<mode>async</mode>
</method>
</methods>
</replication>
</clustering>
. . .
</jeus-bean>
. . .
</beanlist>
. . .
</jeus-ejb-dd>
Descriptions for each tag are as follows:
| Tag | Description |
|---|---|
| <enable-clustering> | Indicates whether to enable clustering of all beans. |
| <use-dlr> | Indicates whether to enable DynamicLinkRef when EJB clustering is enabled. The value true indicates that the new JEUS 8 clustering method is not enabled. This configuration is supported to provide compatibility that might be compromised by the new clustering method that entails a different failover method than before. For JEUS 8 Fix#0, this option is only available for EJB 3.x stateless session beans. The default value is false. |
| <ejb-remote-idempotent-method> | Defines idempotent methods among bean methods. (Refer to @jeus.ejb.Idempotent in"6.3.1. Configuring Clustering through Annotation"). |
| <ejb-remote-idempotent-exclude-method> | Defines methods that need to be excluded from methods that are defined as idempotent. This has precedence over the <ejb-remote-idempotent-method> setting, but is used in the same way. |
| <ejb-home-idempotent-method> | Defines idempotent methods among methods defined in 2.x style home interface (Refer to @jeus.ejb.CreateIdempotent of "6.3.1. Configuring Clustering through Annotation"). This is used in the same way as <ejb-remote-idempotent-method>. |
| <ejb-home-idempotent-exclude-method> | Defines methods that need to be exclude from idempotent methods defined in 2.x style home interface. This has higher priority over <ejb-home-idempotent-method>, but is used the same way as <ejb-remote-idempotent-method>. |
| <create-idempotent> | Defines whether to declare a bean as idempotent when creating a session bean. |
| <replication> | Specifies the session replication mode at the bean or method level. For more information, refer to "6.2.4. Session Replication" and [Example 6.2]. |
In order for the previously defined bean clustering to work, you must consider these issues.
-
All beans participating in clustering should have the same settings inside the <clustering> element.
-
In order to create a cluster, beans should have the same <export-name> value.
In order to execute stateful session beans in a clustered environment, node clustering and session manager configurations are additionally required.
The following describes the passivation timeout, which is one of the session manager setting items. For more information about other items, refer to JEUS Session Management Guide. "2.10.3. Distributed Session Server Configuration Details"
A client may use the EJB reference (Stub) by caching it or using injection, instead of doing a look up each time. In this case, failover may not be performed even though there is another alive end-point. This may occur when MSs, that were alive in the EJB end-point list at the time of the lookup, are not alive, and only new MSs that started after the lookup are alive.
EJB references are looked up internally at the time of the failover, and a new EJB reference is sent to the client. However, if all deployed MSs are terminated when you are doing a lookup of an EJB reference that is in use, failover cannot be performed even though there is a new EJB end-point that is deployed after the lookup and is able to provide the service.
In the previous case, the termination of existing MSs means that the nodes are abnormally terminated or shut down, or an EJB end-point is undeployed and cannot provide the service. The deployment of a new EJB end-point can mean that the time when the new MS was included to a cluster was too late (when EJB reference is already looked up and used), downed MS was restarted too late, or the undeployed EJB end-point was redeployed too late.
This may occur when two MSs are used for active/backup clustering. The following is an example scenario.
A single EJB engine exists in each MSs: A, B, and C. A client looks up EJB references for the first time and caches them.
-
EJBs are deployed to A, B, and C, and EJB on A is obtained as a result of a lookup.
-
EJB on A is abnormally terminated during use. EJB on B is obtained through lookup internally and it continues to provide the service.
-
EJB on B is undeployed, and EJB on C is obtained through lookup.
-
At this time, EJB on B is redeployed, and C is abnormally terminated.
In this case, when EJB reference of C is looked up, EJB end-point of B was undeployed and was redeployed after EJB on C was looked up. When C was terminated, B was still alive, but failover was not performed. However, if B was not deployed or undeployed, but was abnormally started or terminated, failover is performed. This is because the status of the engine for rebooting is checked for abnormal terminations.
It is possible to avoid the previous situation, if a new EJB Reference is looked up again and a new end-point list is obtained.