본 장은 JEUS JNDI의 기본적인 개념과 용어 그리고 환경설정 방법 및 애플리케이션을 개발 방법에 대해서 설명한다.
Java Naming and Directory Interface™ (JNDI)는 Java 애플리케이션이 네트워크에서 객체를 찾고 가져올 수 있도록 하는 표준 API이다. 애플리케이션은 객체의 논리적인 이름을 통해 해당하는 객체를 찾아서 사용할 수 있다. 사용자의 관점에서는 이전의 엔터프라이즈 환경보다 쉽게 객체를 찾아서 사용할 수 있는 환경을 제공해준다.
JEUS JNDI는 JNDI 1.2 API와 호환되며, Sun Microsystems에서 제안한 표준 JNDI API를 지원한다. 그리고 엔터프라이즈 환경에 적합하도록 JNDI Service Provider Interface(이하 SPI)도 제공한다. 즉, JNDI SPI를 구현한 제품은 JEUS JNDI 트리의 객체를 사용할 수 있다.
JEUS JNDI 서비스는 JEUS 시스템 전반적으로 사용되므로 EJB, Servlet/JSP, JMS, JDBC 등을 사용할 때마다 보게 될 것이다.
JEUS JNDI는 객체를 bind하고 Lookup하는 고유의 아키텍처를 가지고 있다. 우선 JEUS JNDI의 구조와 기본 개념에 대해서 설명한다.
MS를 시작하면 JEUS는 자동적으로 JNDI 서비스를 준비한다. JNDI 서비스는 JNDI Naming Server가 제공하는데, 이것이 실행될 때 내부적으로 JEUS Naming Service Server(이하 JNSServer)가 실행된다. 이 JNSServer와 통신하기 위한 클라이언트 역할을 하는 것이 JEUS Naming Service Client(이하 JNSClient)이다.
JNSClient는 JNSServer와 접속되어 있어서 객체의 bind와 Lookup은 JNSClient에서 먼저하고, 다음으로 JNSServer에서 진행된다. 하나의 JNSServer는 하나 이상의 JNSClient와 접속되어 있으며, 또한 JNSServer들도 다른 JNSServer와 접속하고 있어(특히 클러스터링 환경일 때) 트리와 같은 구조를 이루고 있다. 이러한 Naming Repository구조를 JNDI 트리라고 한다.
JNDI 트리는 객체를 bind하거나 Lookup할 때 사용되는데, 모든 객체는 서버들을 통해서 JNDI 트리로 bind되고 Lookup된다. 애플리케이션에서 JNSClient로 객체의 bind를 요청하면 JNDI 트리로 전달되어 bind되며, 이렇게 bind된 객체는 각 JNSClient를 통해 애플리케이션에서 Lookup할 수 있다.
JNDI 트리의 객체를 액세스할 때는 InitialContext를 통해서만 가능하다. 그러므로 애플리케이션에서 JNDI를 사용하려면 반드시 InitialContext 객체를 생성해야만 한다. 이 객체는 JNDI 트리에 접근해서 객체를 핸들링할 수 있도록 해준다. 그리고 객체를 bind하거나 Lookup할 뿐만 아니라, 객체의 목록을 가져올 수 있으며 제거할 수 있는 기능을 한다.
바인딩되어 있는 객체는 WebAdmin과 콘솔 툴을 통해 확인할 수 있다.
바인딩되어 있는 객체는 WebAdmin과 콘솔 툴을 통해 확인할 수 있다.
참고
본 절에서는 WebAdmin을 통해 조회하는 방법에 대해서만 설명한다. 콘솔 툴을 통해 조회하는 방법은 “JEUS Reference Book”의 “4.2.3.14. jndi-info”를 참고한다.
WebAdmin 사용
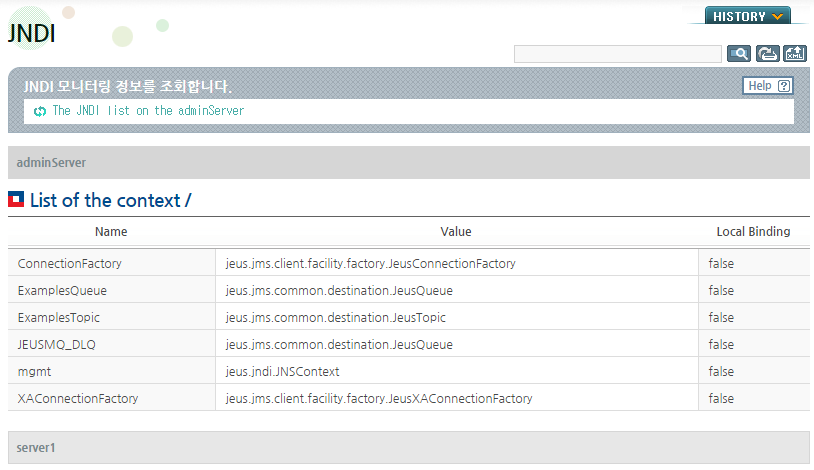
다음 그림은 WebAdmin에서 JNDI 목록을 조회한 화면이다.
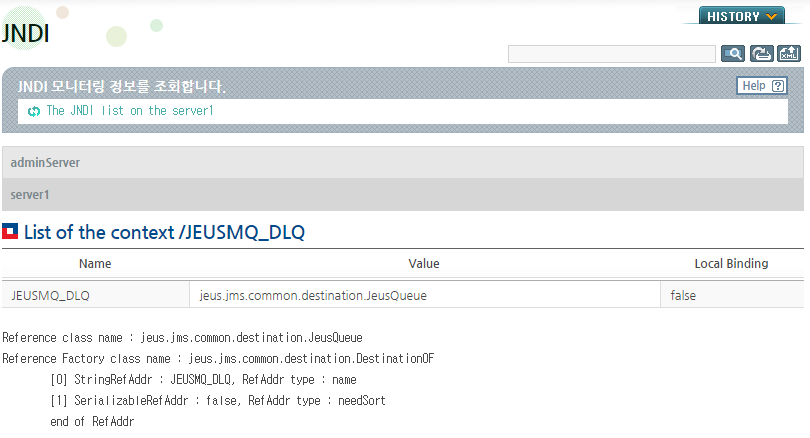
본 절에서는 JNDI 트리 구조가 실제로 어떻게 작동되는지 자세히 설명한다.
JNDI 트리는 JNSServer와 JNSClient로 구성되어 있다. JNSServer는 MS의 JVM에 존재하며, JNSClient는 MS 또는 클라이언트의 JVM에 존재한다. JNSServer는 JEUS JNDI 아키텍처의 메인으로 JNDI 트리를 생성하고 관리한다. JNSServer는 그 하위에 JNSClient를 둬서 관리한다.
다음 그림은 JNSServer와 JNSClient의 관계를 나타낸다.
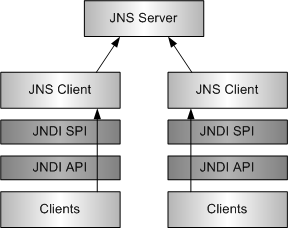
전체 JNDI 트리를 액세스하기 위해서는 JNSClient에서 JNSServer로 요청을 보내야 한다.
JNSServer는 다른 MS의 JNSServer와 연결되어서 클러스터링을 구성한다. JNSClient는 JNSServer와 MS 내에서 상호 작용을 하며, 클라이언트의 액세스 요청을 처리한다. 클라이언트는 JNSServer로 바로 접근하는 것이 아니라 JNSClient를 통해서 객체를 bind하고 Lookup한다.
JNSServer
JNSServer는 JNDI 트리를 관리하며, JNSClient가 JNDI 트리를 액세스할 수 있도록 하는 독립적인 Naming Server이다. JNDI 트리를 확장하기 위해서 여러 개의 JNSServer를 연결할 수 있다. JNSServer는 다른 MS의 JNSServer와 직접적으로 연결할 수 있기 때문이다. JEUS에서는 MS가 시작되면 JNSServer는 자동적으로 JNSClient의 접속을 기다린다.
JNSClient
JNSClient의 기본적인 기능은 JNSServer로 접속하여 애플리케이션의 요청을 전송하고 JNSServer의 결과를 다시 돌려주는 것이다. 각 JVM에서는 하나의 서버에 대해 하나의 JNSClient Singleton 인스턴스만 존재한다. 그래서 Lookup을 처리할 때 하나의 JNSClient만 사용하므로 엔터프라이즈 환경에서 EJB와 Servlet을 사용할 때 효과적이다.
다음은 JNSClient의 중요 기능이다.
-
JNDI 트리 접속
JNSClient는 JNSServer에 접속해서 MS가 관리하는 JNDI 트리로 접속하는 방법을 제공한다. bind되고 Lookup되는 객체는 전체 JNDI 트리에서 공유되거나, 클라이언트의 설정에 따라서 특정 클라이언트만 액세스할 수도 있다.
-
Lookup된 객체의 캐싱
JNSClient는 자주 사용되는 객체를 캐싱해서 클라이언트가 더 빠르게 사용할 수 있도록 한다. JNSClient는 JNSServer와 통신을 하면서 객체를 캐싱한다.
-
JNSServer와의 연결 관리
JNSClient는 클라이언트의 요청을 받아서 JNSServer로 전달하고 그 결과를 받아서 리턴한다. 클라이언트가 있는 JVM에 JNSClient가 존재하므로 별다른 I/O 없이 효율적으로 통신할 수 있다.
JNSClient에는 JNSServer의 위치(같은 MS인지 아니면 원격지에 있는지)에 따라서 2가지 종류로 나뉜다.
JNDI 트리는 JNSServer와 JNSClient 간의 연결로 구성되어 있다. 이 구조는 하나의 컴포넌트(JNSClient)에서 객체에 대한 정보의 변화가 있을 때 다른 컴포넌트(JNSClient)로 전달될 수 있도록 하며, 또한 여러 개의 MS를 지원(클러스터링)할 수 있도록 한다. 즉, JNDI Naming 클러스터링은 각각의 독립적인 JNDI를 하나의 확장된 JNDI 트리로 구성하는 것이라 할 수 있으며 이때도 마찬가지로 각 JNDI 트리에서 발생하는 객체에 대한 정보의 변화가 있을 때에는 나머지 다른 JNDI로 그 내용이 전달된다. 따라서 JNDI Naming 클러스터링 환경에서는 하나의 Naming Server에서 바인딩한 객체를 다른 여러 Naming Server에서 이 객체를 Lookup할 수 있게 된다.
예를 들어 다음 그림처럼 A, B, C, D라는 4개의 MS가 클러스터링을 구성하고 있는 환경에서 MS A에 obj1이라는 객체를 'objName1'이라는 이름으로 바인딩하면, 이는 나머지 3개의 MS B, C, D에도 이 객체가 전달된다. 따라서 처음에 클라이언트가 직접 바인딩을 시도한 MS A가 아닌 다른 3개의 MS에서도 'objName1'으로 Lookup하면 obj1이라는 객체를 얻어올 수 있게 된다.
그러나 바인딩한 모든 객체가 클러스터링에 속한 MS로 복제되는 것은 아니고, 클러스터링 대상으로 바인딩한 객체만 복제된다. 예를 들어 데이터소스같이 각 MS에 특화된 객체는 각 MS의 JNS Server에만 바인딩된다.
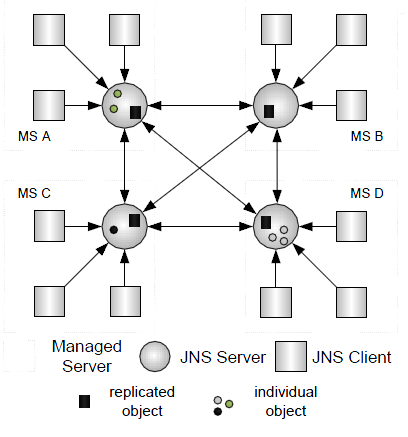
각 MS는 각각의 JNSServer를 관리할 책임을 가지고 있다. 각 JNSServer는 JEUS 시스템이 기동될 때 시작되어서 다른 MS의 JNSServer와 연결된다. 각 JEUS 엔진은 InitialContext를 가져옴과 동시에 JNSClient가 JNSServer로 연결된다. 클라이언트가 JNDI 트리의 객체를 Lookup할 때 JNSClient로 요청하고 이어서 해당 MS의 JNSServer로 요청이 보내진다. 그리고 이에 대한 객체를 클라이언트가 받게 된다.
클러스터링 환경에서 원격으로 Lookup
별도의 설정을 하지 않은 경우 JNDI Lookup은 자신이 포함된 JEUS JNDI 클러스터링 영역에 대해서 수행된다. 그러나 애플리케이션이 클러스터링에 있지 않은 다른 MS의 JNDI 서버에 있는 내용을 Lookup할 때에는 PROVIDER URL(“JEUS Reference Book”의 “1.4. JNDI 시스템 프로퍼티” 참고)을 지정해서 Context를 생성하거나 Lookup할 때 JEUS에서 생성한 jh(JEUS Host) 프로토콜을 사용한 이름으로 Lookup해야 한다. 이에 대한 내용은 “4.5. JNDI 프로그래밍”을 참고한다.
JNSServer Replication
JEUS의 각 JNSServer는 다른 서버와 연결되어서 상호 작용하기를 기다리고 있다. 기존의 클러스터로 새로운 MS가 들어오면, 새로 들어온 MS의 JNSServer는 시작할 때 이미 존재하는 다른 JNSServer로 통보를 보내게 된다. 이때 각 JNSServer는 자신의 데이터를 새로 들어온 JNSServer로 전송하게 되며, 이렇게 해서 새로 들어온 JNSServer에서도 기존에 bind되어 있는 객체를 Lookup할 수 있게 된다.
이런 확장성으로 인해 이상 작동하여 재기동된 JNSServer는 다른 JNSServer로부터 JNDI 트리 정보를 받아 정상 상태로 동작할 수 있다.
JNDI Naming Server는 JNSServer와 JNSClient로 구성되어 있다. 이 둘은 서로 다른 설정을 가진다.
JNSServer에서는 JNSClient의 커넥션을 받아들이는 설정과 다른 JNSServer와 접속하기 위한 설정이 필요하고, JNSClient는 JNSServer와 접속하기 위한 것과 JNDI 트리의 반영을 위한 설정이 필요하다.
본 절에서는 JNSServer와 JNSClient를 설정하는 방법에 대해서 설명한다.
WebAdmin의 왼쪽 메뉴에서 [Servers]를 선택하면 서버 목록 조회 화면으로 이동한다. 서버 목록에서 서버를 선택하면 서버 설정 화면으로 이동한다. 설정 화면에서 [Naming Server] 메뉴를 선택하면 JNSServer의 설정할 수 있는 화면으로 이동한다.
다음은 Naming Server 설정 화면이다.
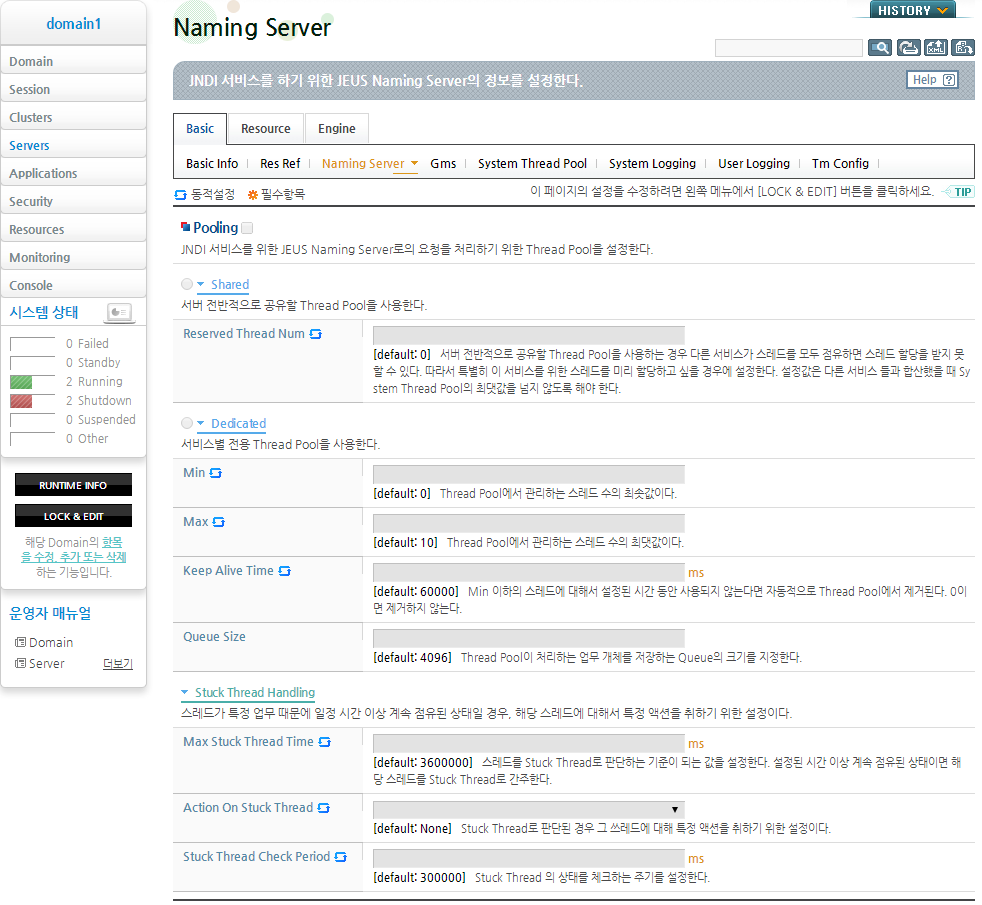
공용 Thread Pool 설정
WebAdmin이나 콘솔 툴을 사용해서 서버 전반적으로 공유할 Thread Pool을 설정할 수 있다. Thread Pool에 대한 기본적인 설명은 “2.3.4. Thread Pool 설정”을 참고한다.
-
WebAdmin 사용
다음은 WebAdmin의 공용 Thread Pool 설정 화면이다. 'Pooling' 체크박스를 체크하고 'Shared' 항목을 선택한다. 공용 Thread Pool에 대한 항목을 설정하고 [확인] 버튼을 클릭한다.
-
콘솔 툴 사용
콘솔 툴을 통해서도 공용 Thread Pool을 설정할 수 있다.
[DAS]domain1.adminServer>modify-system-thread-pool adminServer -service namingserver -r 10 Successfully performed the MODIFY operation for The namingserver thread pool of the server (adminServer)., but all changes were non-dynamic. They will be applie d after restarting. Check the results using "show-system-thread-pool adminServer -service namingserv er or modify-system-thread-pool adminServer -service namingserver" [DAS]domain1.adminServer>modify-system-thread-pool adminServer -service namingserver show the current configuration. The namingserver thread pool of the server (adminServer) ================================================================================ +----------------------------------------------------------------------+-------+ | Reserved Threads for the Service namingserver | 10 | +----------------------------------------------------------------------+-------+ ================================================================================
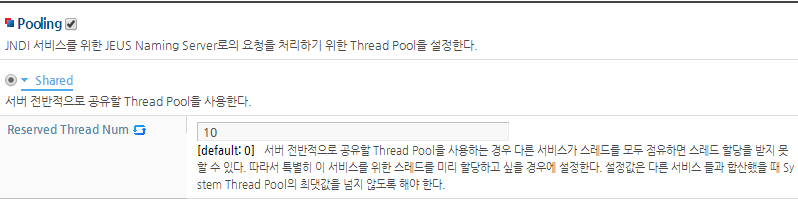
서비스 전용 Thread Pool 설정
WebAdmin이나 콘솔 툴을 사용해서 서비스별 전용 Thread Pool을 설정할 수 있다.
-
WebAdmin 사용
다음은 WebAdmin의 서비스 전용 Thread Pool 설정 화면이다. 'Dedicated' 항목을 선택하고, 서비스 전용 Thread Pool에 대한 항목을 설정한 후 [확인] 버튼을 클릭한다.
Thread가 특정 일 때문에 일정시간 이상 계속 점유된 상태일 경우 그 Thread에 대해서 특정 액션을 취하기 위한 설정이다. 공유할 Thread Pool을 사용한다.
다음은 Stuck Thread Handling 관련 설정 항목에 대한 설명이다.
항목 설명 Max Stuck Thread Time Thread를 Stuck Thread로 판단하는 기준이 되는 값이다.
여기에 설정된 시간 이상 계속 점유된 상태이면 그 Thread를 Stuck Thread로 간주한다. (기본값: 3600000(1시간), 단위: ms)
Action On Stuck Thread Stuck Thread로 판단된 경우 그 Thread에 대해 특정 액션을 취하기 위한 설정이다.
다음 중 하나의 값을 설정한다.
-
None : 아무 액션도 취하지 않는다.
-
Interrupt : Interrupt Signal을 보낸다.
-
IgnoreAndReplace : Stuck Thread를 무시하고 새로운 Thread로 교체한다.
Stuck Thread Check Period Stuck Thread의 상태를 체크하는 주기를 설정한다.
여기에 설정된 주기마다 Thread의 상태를 체크하여 Stuck Thread로 판단할지 여부를 결정한다. (기본값: 300000(5분), 단위: ms)
-
-
콘솔 툴 사용
콘솔 툴을 통해서도 서비스 전용 Thread Pool을 설정할 수 있다.
[DAS]domain1.adminServer>modify-service-thread-pool server1 -service namingserver -min 0 -max 20 Successfully performed the MODIFY operation for The namingserver thread pool of the server (server1)., but all changes were non-dynamic. They will be applied af ter restarting. Check the results using "show-service-thread-pool server1 -service namingserver or modify-service-thread-pool server1 -service namingserver" [DAS]domain1.adminServer>modify-service-thread-pool server1 -service namingserver Shows the current configuration. The namingserver thread pool of the server (server1). =================================================================== +-------------------------------------------------------+---------+ | Min | 0 | | Max | 20 | | Keep-Alive Time | 60000 | | Queue Size | 4096 | | Max Stuck Thread Time | 3600000 | | Action On Stuck Thread | NONE | | Stuck Thread Check Period | 300000 | +-------------------------------------------------------+---------+ ===================================================================
참고
서비스의 Thread Pool 설정을 수정하는 것은 동적 반영 가능하기 때문에 서버를 재기동하지 않아도 된다. 하지만 공용 Thread Pool을 사용하다가 전용 Thread Pool을 사용하도록 변경하려면 서버를 재기동해야 한다.
JNSClient는 놓이는 위치에 따라서 설정하는 방법이 달라진다.
-
Server-side JNSClient 설정
Server-side JNSClient는 JNSClient가 MS와 같이 실행되는 것을 의미하며 JNSSever의 설정을 따른다.
-
Client-side JNSClient 설정
Client-side JNSClient는 JVM이 서로 다른 JNSServer를 액세스한다. 그래서 JNSServer와 연결되어서 JNDI 트리의 내용을 반영하는 Thread가 존재한다. JEUS JNDI는 Thread Pool로 Thread를 관리한다. 이 Thread Pool은 JEUS 프로퍼티를 사용해서 설정하며, 기본값을 사용해도 무방하다. Client-side JNSClient의 프로퍼티를 설정하려면 JVM의 시스템 프로퍼티를 사용하거나 InitialContext의 Hash Table을 사용해야 한다.
다음은 Client-side JNSClient의 프로퍼티의 종류이다.
참고
EJB와 Servlet/JSP 같은 서버 측 객체에서 JNDI를 사용한다면 MS에 의해서 Server-side JNSClient를 사용해서 bind나 Lookup되기 때문에 이런 프로퍼티를 설정할 필요가 없다. 프로퍼티에 대한 자세한 내용은 “JEUS Reference Book”의 “1.4. JNDI 시스템 프로퍼티”를 참고한다.
MS 간에 클러스터링 환경이 구성되어 있다면 JNDI를 클러스터링하기 위해서 별도의 작업은 필요없다. 만약 MS가 클러스터링된다면 각 JNSServer도 자동적으로 클러스터링 환경을 구성한다. MS들을 클러스터링하는 것에 대해서는 “JEUS Domain 안내서”의 “제5장 JEUS 클러스터링”을 참고한다.
기본적으로 JNSClient는 로컬 JNSServer로 접속한다. JNSClient는 MS의 JNSServer 주소를 Context.PROVIDER_URL로 제공받는데, 클러스터링 환경인 경우에도 클러스터링에 참여하고 있는 모든 MS의 주소를 다음과 같이 적어 주어야 한다.
JNSClient는 제공된 Context.PROVIDER_URL를 바탕으로 Load Balancing과 Failover를 수행하기 때문이다.
Hashtable ht = new Hashtable(); ht.put(Context.PROVIDER_URL, "host1:9736,host2:9736"); //cluster에 host1, host2가 참여
만약 Context.PROVIDER_URL에서 적혔는 MS 중에 특정 MS가 FAILED 상태가 되면 JNSClient는 FAILED 상태가 된 MS로 JNSServer의 JNDI 오퍼레이션할 때 이를 감지하여 다른 JNSServer로 Failover를 한다. FAILED 상태로 판단된 MS는 JNSClient에서 주기적으로 체크하여 RUNNING 상태가 되었는지 확인한다. -Djeus.jndi.cluster.recheckto 옵션으로 설정 가능하다. (기본값: 5, 단위: 분)
만약 JNSClient가 DAS의 관리를 받는 MS에서 동작하고 있다면, 다음과 같이 DAS에서 설정한 클러스터 이름을 적어서 사용할 수 있다.
Hashtable ht = new Hashtable(); ht.put(Context.PROVIDER_URL, "jeus://cluster1"); //cluster1은 DAS에 설정한 클러스터 이름
클러스터 이름을 적어서 사용한 경우에는 JNSClient의 "jeus.jndi.cluster.recheckto" 옵션과 상관없이 DAS로부터 늘 MS 서버의 최신 상태 정보를 받아서 클러스터링을 할 수 있다. 즉, 클러스터에 속한 MS가 FAILED 상태가 되거나 새로운 MS가 추가된 경우에 JNSClient에서 JNDI 오퍼레이션을 수행하기 전에 최신의 서버 상태로 업데이트되어 동작된다. 따라서 JNSClient가 DAS의 관리를 받는 MS에서 동작된다면 클러스터 이름을 사용할 것을 권장한다.
Lookup
클러스터에 있는 클라이언트는 JNDI 트리에 bind되어 있는 어떤 객체든 Lookup할 수 있다. 만약 클라이언트가 JNSClient에 객체를 bind한다면 즉시 JNSServer를 통해서 클러스터링된 모든 MS에서 그것을 공유하게 된다. 또한 데이터 삭제나 변경이 발생하면 즉시 각 MS의 JNSClient에도 반영된다.
JEUS JNDI에서는 객체의 성격에 따라서 어떤 객체는 클러스터 전체에 공유되고 (Lookup을 위한 export name 같은 객체), 어떤 객체는 자신의 MS(데이터소스같은 MS에 의존적인 객체)에서만 보인다.
본 절에서는 JEUS JNDI를 사용하는 프로그래밍 방법에 대해서 설명한다.
Java 클라이언트는 InitialContext를 사용해서 JNDI 트리를 접근한다. InitialContext에 사용되는 프로퍼티는 JNDI 표준 프로퍼티와 JEUS용 프로퍼티가 있다. 먼저 JNDI 환경을 설정하고 그 다음으로 InitialContext를 사용해서 객체를 Lookup한 다음, 객체의 레퍼런스를 가져온다. 마지막으로 InitialContext를 사용한 다음에는 반드시 close시켜준다.
다음의 과정으로 Java 클라이언트는 JEUS JNDI 서비스를 사용한다.
-
JEUS 환경설정
-
InitialContext를 위한 프로퍼티 설정
-
Context를 사용한 Named Object의 Lookup
-
Named Object를 사용해서 객체의 레퍼런스 취득
-
Context 닫기
각 단계에 대한 자세한 설명은 해당 절을 참고한다.
JNDI 서비스에서 필요한 클래스를 사용할 수 있도록 JEUS 클라이언트 모듈의 경로(JEUS_CLIENT)를 클래스 패스에 설정한다.
-classpath ${JEUS_CLIENT};
Java 클라이언트가 JEUS JNDI 서비스를 사용하기 전에 우선 InitialContext의 환경 프로퍼티를 설정한다.
설정하는 방법은 다음의 2가지가 있다.
-
JVM의 -D 옵션을 사용한다.
-
Hash Table을 생성하여 InitialContext의 생성자에게 넘긴다.
위의 2가지 방법 중 Hash Table을 생성하여 InitialContext의 생성자에게 넘기는 방법보다 JVM의 -D 옵션을 사용하는 방법이 우선한다.
JEUS JNDI의 InitialContext를 생성하기 위해서 설정해야 하는 프로퍼티는 다음과 같다.
-
Context.INITIAL_CONTEXT_FACTORY (required)
-
Context.URL_PKG_PREFIXES
-
Context.PROVIDER_URL
-
Context.SECURITY_PRINCIPAL
-
Context.SECURITY_CREDENTIALS
참고
프로퍼티에 대한 자세한 사항은 “JEUS Reference Book”의 “1.4. JNDI 시스템 프로퍼티”를 참고한다.
이 프로퍼티들은 Hash Table에 넣어서 InitialContext를 생성할 때 사용한다. 만약 서버 측 객체 내(EJB나 Servlet/JSP)에서만 InitialContext를 사용한다면 별도의 설정 없이 기본으로 설정된 InitialContext를 사용한다.
클라이언트 프로그램에서는 다음과 같이 설정한다.
Context ctx = null; Hashtable ht = new Hashtable(); ht.put(Context.INITIAL_CONTEXT_FACTORY, "jeus.jndi.JNSContextFactory”); ht.put(Context.URL_PKG_PREFIXES, “jeus.jndi.jns.url”); ht.put(Context.PROVIDER_URL, “<hostname>”); ht.put(Context.SECURITY_PRINCIPAL, “<username>”); ht.put(Context.SECURITY_CREDENTIALS, “<password>”); try { ctx = new InitialContext(ht); // use the context } catch (NamingException ne) { // fail to get an InitialContext } finally { try{ ctx.close(); catch (Exception e) { // an error occurred } }
클러스터링 환경에서 JNDI를 사용할 때는 JNDI 트리를 구성하고 JNSClient의 내부적인 작동을 효과적으로 관리하기 위해서 jeus.jndi.JNSContext의 추가적인 환경 프로퍼티를 사용할 수 있다.
-
Hash Table을 사용해서 Context 생성하기
InitialContext의 환경 프로퍼티를 설정할 때 Hash Table(java.util.Hashtable)의 키로 프로퍼티 이름을 넣고, 값으로 프로퍼티의 데이터를 넣은 후에 InitialContext 생성자의 파라미터로 넣어준다.
-
Security Context 생성하기
JEUS Security 도메인의 사용자를 실행 Thread에 적용시키기 위해서 몇 가지 보안 관련 환경 프로퍼티를 사용할 수 있다. InitialContext가 생성될 때 Security Context는 다음의 프로퍼티로 구성한다.
-
사용자명 프로퍼티 : java.naming.security.principal
-
패스워드 프로퍼티 : java.naming.security.credentials
-
인증이 성공하면 인증된 사용자의 정보가 실행 Thread에 설정되며, JEUS Security Manager가 관리하는 리소스를 액세스할 수 있다. 만약 인증에 실패하면 Thread는 guest 사용자로 인식된다.
Security Context가 설정되어도 InitialContext가 생성되기 전에 JEUS Security API를 사용해서 로그인한 경우 Security Context는 무시된다. 즉, 이미 로그인된 subject를 사용해서 JNDI 통신을 수행한다.
참고
1. 사용자 정보 설정에 관한 더 자세한 내용과 JEUS Security Service에 대한 내용은 "JEUS Security 안내서"를 참고한다.
2. InitialContext 설정 관련 프로퍼티와 환경 프로퍼티에 대한 자세한 내용은 “JEUS Reference Book”의 “1.4. JNDI 시스템 프로퍼티”를 참고한다.
JNDI 트리에 bind된 객체는 JNDI Context의 Lookup() 메소드를 사용해서 찾는다. 다음은 Lookup하려는 객체의 모듈 이름이 countermod이고, EJB 이름이 Count인 경우이다.
try {
Context ctx = new InitialContext();
Count count = (Count)ctx.lookup(“java:global/countermod/Count”);
// Count count = (Count)ctx.lookup(“java:global/countermod/Count!my.ejb3.tx.Count”);
// Count count = (Count)ctx.lookup(“Count”);
// successfully got the object
} catch (NameNotFoundException ex) {
// no such binding exists
} catch (NamingException e) {
// an error occurred
}
비즈니스 인터페이스가 여러 개인 경우 "!인터페이스이름"을 뒤에 더 붙여서 Lookup하면 된다.
Count count = (Count)ctx.lookup(“java:global/countermod/Count!my.ejb3.tx.Count”);
export name을 준 경우는 export name으로 Lookup할 수 있다.
Count count = (Count)ctx.lookup(“Count”);
다음은 EJB 2.x 객체인 경우를 Lookup하는 예제이다.
try {
Context ctx = new InitialContext();
CountHome countHome = (CountHome)ctx.lookup(“Count”);
// successfully got the object
} catch (NameNotFoundException ex) {
// no such binding exists
} catch (NamingException e) {
// an error occurred
}
EJB 3.x인 경우에는 Lookup한 객체를 다음과 같이 바로 사용한다.
count.service();
EJB 2.x인 경우 Lookup한 EJB 홈 객체의 create() 메소드를 사용해서 EJB 리모트 객체의 Reference를 가져온다. 다음과 같이 메소드를 실행해서 사용하려는 객체의 Home Reference를 가져오고, 그 Reference의 메소드를 실행한다.
Count count = countHome.create(); count.service();
다음과 같이 Context를 사용한 다음에는 close() 메소드를 실행해서 Context를 닫아준다.
try {
cx.close();
} catch(Exception e) {
// an error occurred
}
JEUS 클러스터링 환경에서 사용할 수 있는 Context를 생성하기 위해서는 다음과 같이 Context.PROVIDER_URL에 여러 개의 호스트를 설정한다.
Hashtable ht = new Hashtable(); ht.put(Context.PROVIDER_URL, "host1:9736,host2:9736");
도메인에 설정한 클러스터 이름을 알고 있다면 다음과 같이 설정하여 사용할 수도 있다.
Context.PROVIDER_URL에 'jeus://' + <클러스터 이름>
단, 클러스터에 속한 MS에서만 사용이 가능하고, 독립된 클라이언트(Standalone Client)에서는 클러스터 정보를 알 수 없어 사용할 수 없다.
Hashtable ht = new Hashtable(); ht.put(Context.PROVIDER_URL, "jeus://cluster1");
클러스터링된 Context에서 Lookup하는 경우 어떤 MS에서 객체를 가져올 것인지에 대한 정책을 정할 수 있다.
jeus.jndi.clusterlink.selection-policy 프로퍼티를 제공하며 다음과 같은 3가지 값을 설정할 수 있다. 또한 이 값들은 System property를 주어 설정할 수도 있으며, 이 경우에는 Hashtable을 통한 설정이 우선된다.
| 구분 | 설명 |
|---|---|
| locallinkPreference | 로컬 MS에 있는 객체를 사용한다. |
| roundrobin | 처음 요청에서는 random하게 선택한 MS의 객체를 사용하고, 그 후 요청부터는 하나씩 증가하면서 서버를 선택한다. |
| random | 클러스터링된 MS들 중에서 random하게 하나를 선택해서 사용한다. |
다음은 설정 예제이다.
Hashtable ht = new Hashtable();
ht.put(Context.PROVIDER_URL, "host1:9736,host2:9736");
ht.put("jeus.jndi.clusterlink.selection-policy", "random");
애플리케이션이 클러스터링에 있지 않은 다른 MS의 JNDI 서버에 있는 내용을 Lookup할 때에는 PROVIDER URL을 지정해서 Context를 생성하거나 Lookup할 때 JEUS에서 생성한 jh(JEUS Host) 프로토콜을 사용한 이름으로 Lookup해야 한다.
다음은 JEUS의 클러스터링 환경에서 원격으로 Lookup을 실행할 수 있도록 하는 특별한 Lookup 구문이다. 이 구문은 자신이 속한 JEUS JNDI 클러스터링의 영역을 벗어나 원격지의 JEUS JNDI 클러스터링에 있는 객체를 Lookup할 때 사용한다.
jh:<remote JEUS host name>:<remote JEUS base port>/<export name>
("jh" = JEUS host)
다음은 Lookup 구분의 사용법으로 JNDI Context 문자열 내에 다음과 같은 구문을 입력한다.
try {
Context ctx = new InitialContext();
CountHome countHome = (CountHome)ctx.lookup("jh:dev:9736/Count");
// successfully got the object
} catch (NameNotFoundException ex) {
// no such binding exists
} catch (NamingException e) {
// an error occurred
}