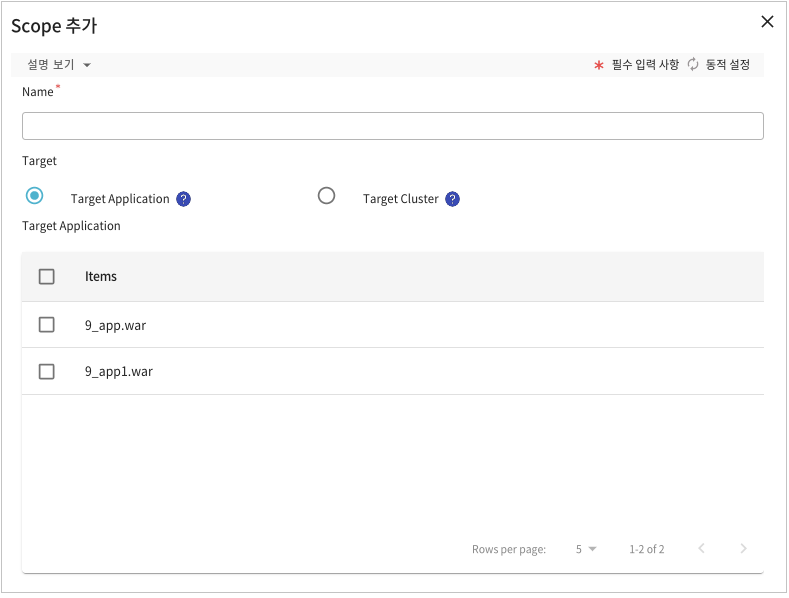
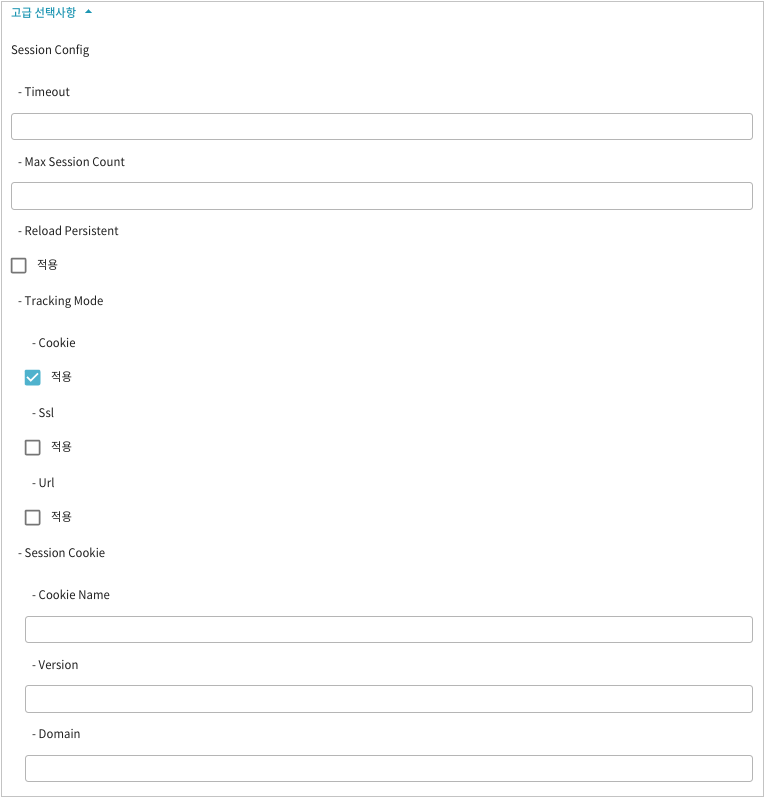
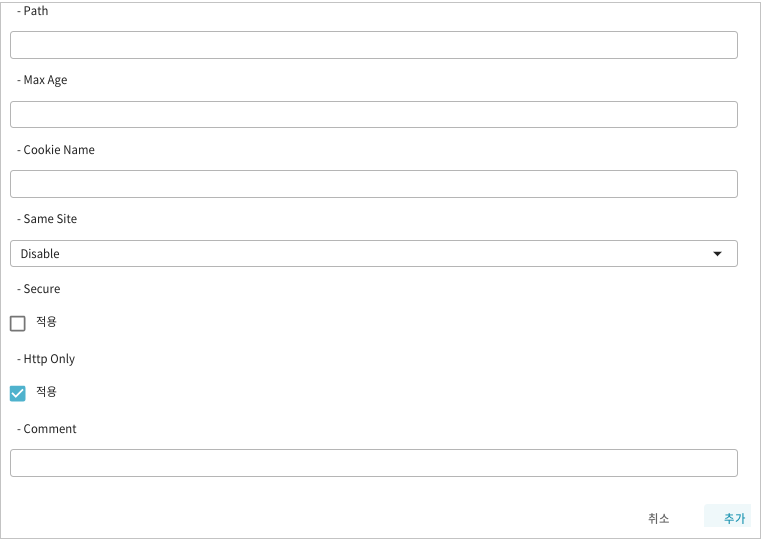
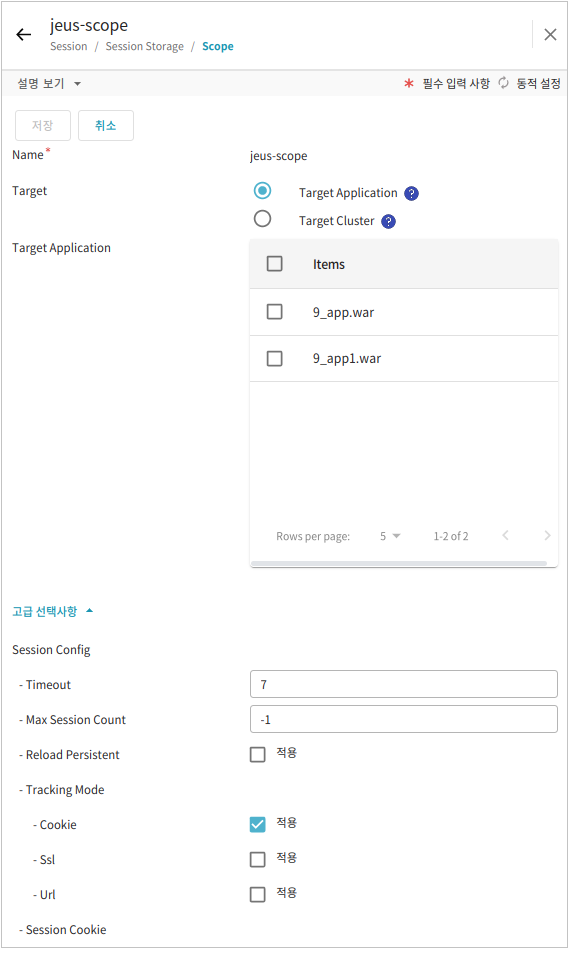
본 절에서는 중앙 세션 서버와 분산 세션의 구조를 비교해서 설명한다.
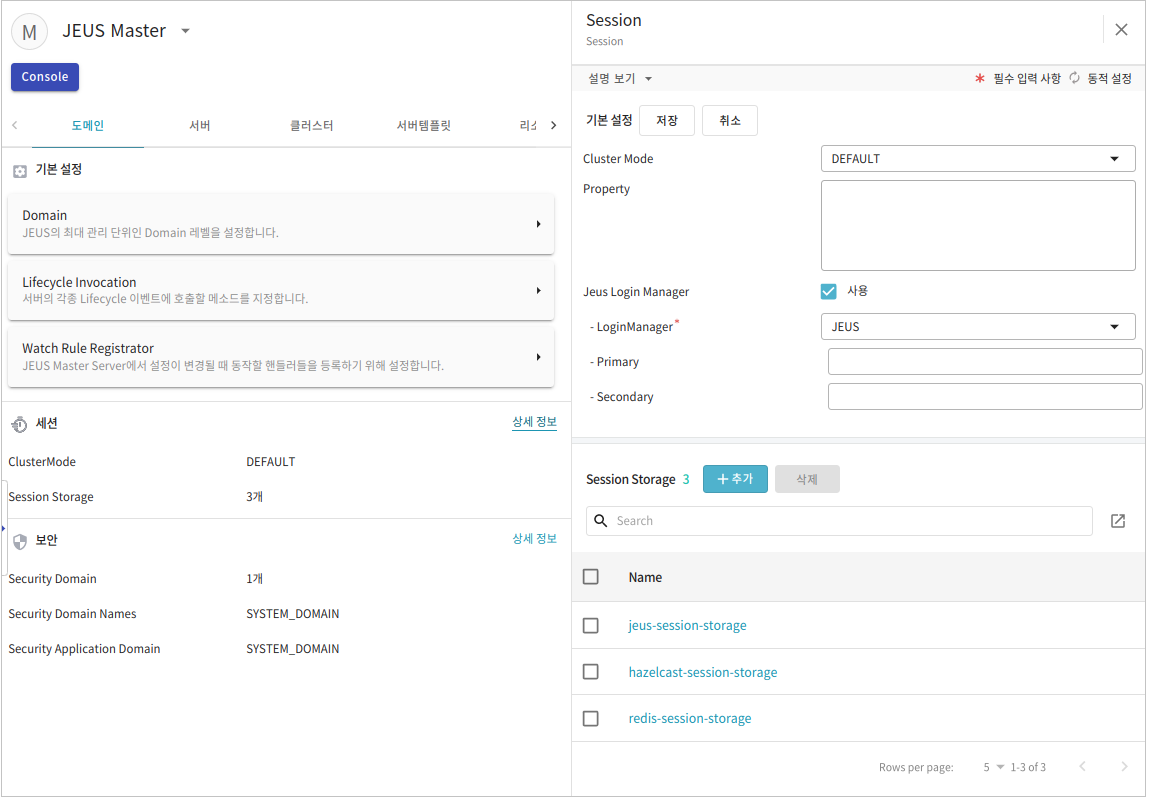
중앙 세션 서버는 JEUS 웹 컨테이너와 연결하여 운영되며, 웹 컨테이너에 있는 클라이언트의 세션을 라우팅하거나 백업하는 기능을 제공한다. 중앙 세션 서버는 Session Manager, Session Cache Memory, Session Storage 등으로 되어 있다. Session Storage로는 Redis와 Hazelcast를 지원하고 있다.
중앙 세션 서버의 서브 컴포넌트는 다음과 같다.
-
-
엔진의 세션 관리를 총괄하는 모듈이다. 로컬 메모리, 세션 서버로부터 세션을 얻어오거나 관리한다.
-
로컬 웹 엔진은 getSession을 통해 세션 매니저로부터 사용할 세션 객체를 얻어온다. Cached Session, Session Storage들 순서로 세션을 얻어온다.
-
세션에 대한 처리가 끝나면 Session Storage로 update한다.
-
-
Cached session(Session Cache Memory)
활성화되어 있거나 한 번 사용된 세션 객체는 빠른 사용을 위해서 이곳에 저장된다.
-
세션을 저장하는 Session Server역할을 한다. Storage로는 Redis와 Hazelcast를 지원한다.
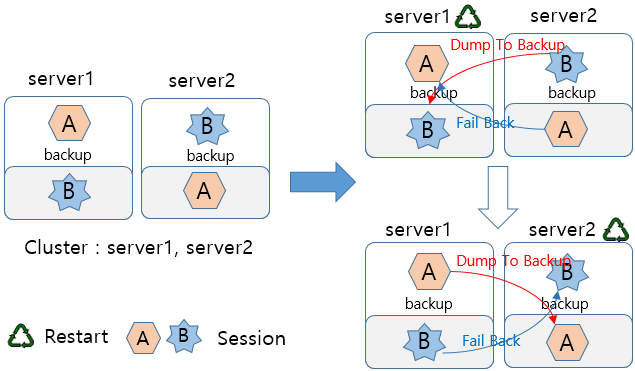
분산 세션 서버는 세션 객체를 서비스하는 서버가 각각의 서블릿 엔진(웹 엔진) 또는 각각의 EJB 엔진에 분산되어 있는 분산식 구조이다.
분산 세션 서버 방식은 클러스터링에 참여하는 모든 엔진 내에 독립적인 분산 세션 서버가 존재하고, 이들 분산 세션 서버들이 Peer-to-Peer로 다른 엔진의 분산 세션 서버와 통신하여 지속적인 세션 서비스를 제공한다.
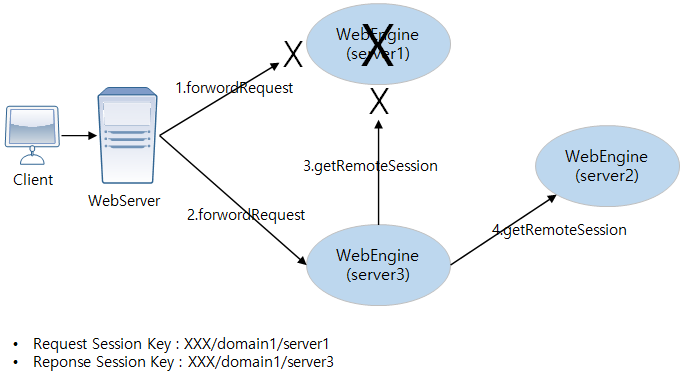
다음은 분산 세션 서버 방식을 사용하여 4개의 웹 엔진을 세션 클러스터링하는 구조이다.
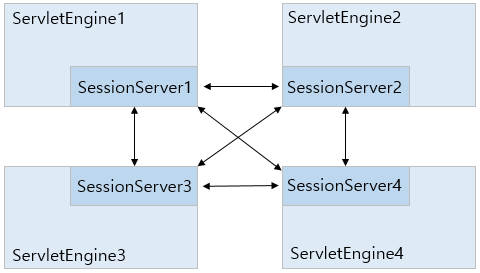
위의 구조도에서 화살표는 분산 세션 서버 간의 소켓 연결을 나타낸 것이다. 항상 모든 연결을 맺는 것이 아니고, 연결에 대한 가능성을 의미한다. 일반적으로 연결이 필요없으며 세션 유지를 위해 다른 엔진과의 통신이 필요한 경우에만 연결을 맺고 유지한다. 장애 발생의 경우를 제외하고 연결은 보통 하나씩만 갖는다.
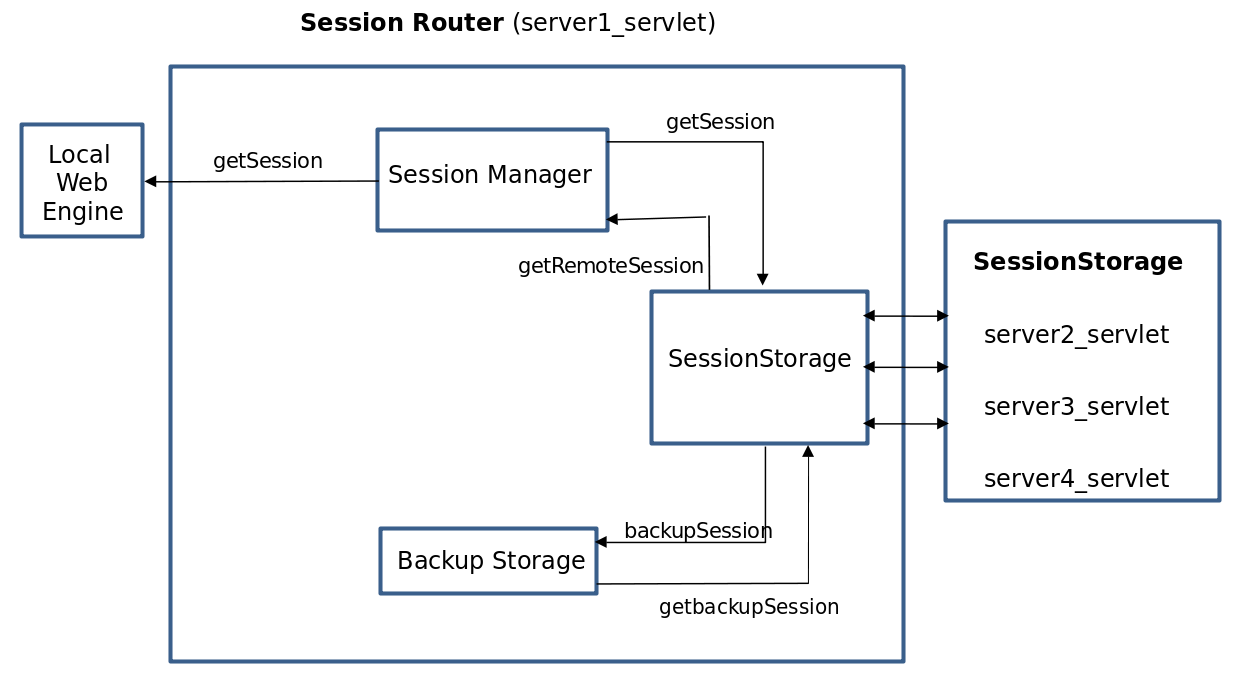
다음은 웹 엔진의 서브 컴포넌트로 동작하는 분산 세션 서버의 내부 구조이다.
-
-
엔진의 세션 관리를 총괄하는 모듈이다. 로컬 메모리, 파일 및 다른 리모트 분산 세션 서버로부터 세션을 얻어오거나 관리한다.
-
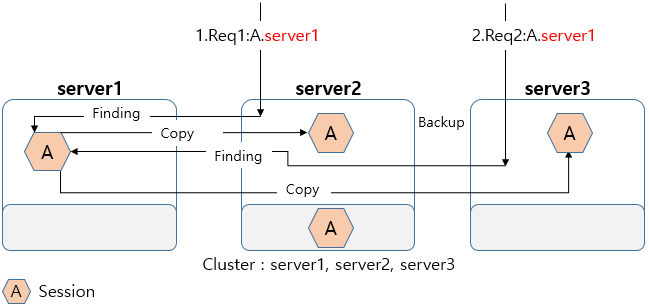
로컬 웹 엔진은 getSession을 통해 세션 매니저로부터 사용할 세션 객체를 얻어온다. session의 sticky server, 이전 backup server들 순서로 세션을 얻어온다.
-
수정된 세션은 리모트 백업이 있을 경우 Cluster Manager를 통해, 백업 서버로 정해진 다른 웹 엔진의 분산 세션 서버로 in-memory 백업된다(backupSession).
수정된 세션은 'Backup Level' 설정에 따라 다르게 적용된다. 'Backup Level'이 'all'일 경우 항상 'get'일 경우 getter와 setter의 호출할 때, 'set'일 경우 setter호출할 때에만 (setAttribute, removeAttribute, setMaxInactivateInterval)의 세션 operation이 발생했을 때 수정된 세션으로 판단한다.
'Backup Level' 항목의 설정값에 대한 자세한 설명은 “2.7. 분산 세션 서버 설정”을 참조한다.
-
-
-
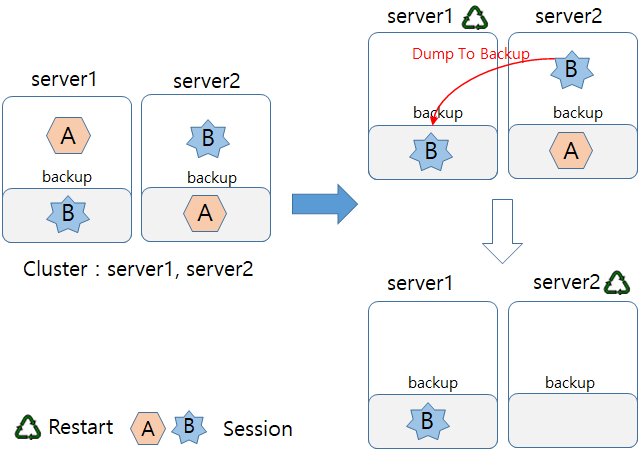
자신의 분산 세션 서버를 백업으로 선택한 다른 엔진의 분산 세션 서버가 주기적으로 전송하는 백업 세션 객체를 관리한다. 이 백업 세션 객체는 원본을 가지고 있는 엔진에 장애가 발생한 경우 대신하여 세션을 제공한다.
-
자신을 백업으로 지정한 리모트 웹 엔진이 전송하는 백업 세션을 받아서 저장 및 관리한다(backupSession, getBackupSession).
-
로컬에서 수정된 세션 객체는 조건이 만족되면 지정된 리모트 분산 세션 서버로 백업된다. 이러한 백업은 요청이 끝나면 바로 수행되어서 장애 상황에서의 Failover가 가능하도록 한다.
-
-
-
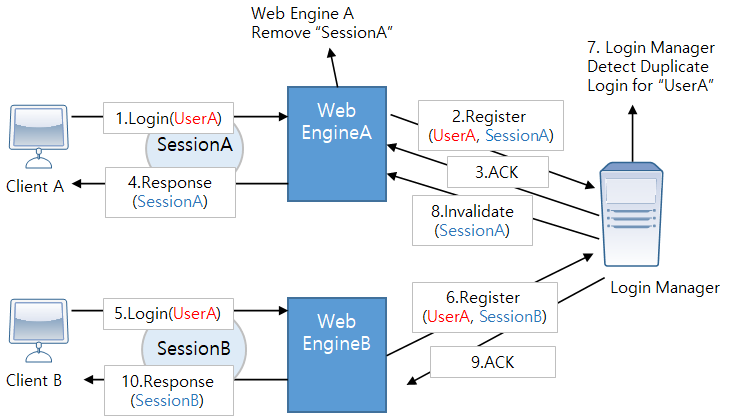
리모트 웹 엔진에 있는 세션들에 대해서 특정 operation을 할 경우 중재 역할을 하는 모듈이다.
해당 엔진은 dynamic한 환경을 고려하여 운용된다. 즉, 기동환경 중에 운용하는 서버가 추가되거나 제거된 경우 해당 상황에 적절한 백업을 선택하여 운용되고, 이것은 환경설정 중심에서 벗어난 큰 특징 중 하나이다. 리모트 엔진(RemoteEngine)에 대한 연결은 지속적인 ping을 통한 확인이 아닌 SCF를 통한 방식으로 지속적인 장애 상황에서의 불필요한 오류 상황을 제거해준다.
리모트 웹 엔진로부터의 getSession(), removeSession() 등을 예로 들 수 있다.
참고
기존 환경 중심의 구조에서는 설정으로 인해서 고정된 백업 엔진만을 바라보게 되었지만 dynamic하게 변화하는 리모트 엔진에 대해서 유동적인 변경이 가능하도록 설계되었다.
-