Table of Contents
This chapter describes the process of migrating legacy system data sets.
This chapter briefly describes the processes for converting and migrating data sets from a legacy mainframe system to the OpenFrame system.
Data sets are collections of logically linked data records. A record is the basic unit of data used by applications and system processes. There are many different types of data sets, but they can be grouped into two broad categories: VSAM data sets and non-VSAM data sets.
Note
For more information about data sets, refer to OpenFrame Data Set Guide.
-
Non-VSAM Data Sets
Non-VSAM data sets (PDS, GDS, SAM, and ISAM data sets) can be migrated as follows:
-
VSAM Data Sets
VSAM data sets (KSDS, ESDS, RRDS, and LDS) can be migrated as follows:
The method of converting data sets for migration from mainframe to OpenFrame varies with the data set type, as shown in the following figure.
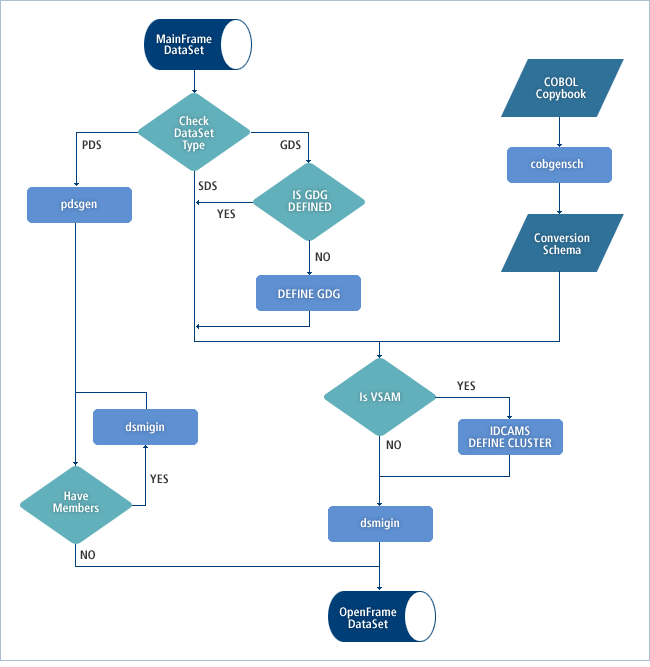
The following are the general steps for migrating non-VSAM data sets to OpenFrame.
-
Migration target identification and source extraction
-
Data set layout analysis
-
Data set migration schema creation
-
Target data set migration
-
PDS migration
-
GDG BASE definition
-
Variable-length data set migration
-
Data set migration verification
Before implementing a migration project, it is important to make a list of the data sets to migrate. While it is possible to analyze the JCL or PROCEDURE to create the list, this is not recommended because some of the data set names may be modified by an SMS or security policy, or during migration to OpenFrame. Because data set names must not be duplicated, an accurate list should be requested from the customer.
Once the list of data sets to migrate has been finalized, the source data sets should be extracted from the mainframe. Ideally, the data sets should be extracted in the original EBCDIC character set (used in mainframes) to avoid conversion errors, such during the conversion of special characters such as SOSI or 2-byte characters.
To ensure successful data set migration, the data sets must be thoroughly analyzed. For most modern data sets, the COBOL copybook or database schema can be analyzed to extract the data set layout information. However, it can be difficult to analyze the exact layout of older data sets without opening them. Therefore, the customer should provide the data set layout information.
Although it is common for all records within a data set to use the same layout, some data sets may contain records with different layouts. This may occur as a result of using the COBOL REDEFINES statement or having variable-length records.
Depending on the preference of the customer, data set layout information may be provided in variety of formats. However, not all formats are supported by OpenFrame; the layout information must first be converted into either standard COBOL copybook format or PL/I include format.
<XTBC106.cpy>
01 I1.
05 KYAKUMEI-KN PIC X(0018).
05 BTN-CD PIC X(0004).
05 KYAKU-NO PIC X(0007).
05 ATUKAI-CD PIC X(0003).
05 MDY-CD PIC X(0003).
05 YAKU-YMD PIC S9(0009) COMP-3.
05 UKEW-YMD PIC S9(0009) COMP-3.
05 KOYU-MEI-CD PIC S9(0005) COMP-3.
05 KAISU PIC S9(0005) COMP-3.
05 GO .
10 GO-1 PIC X(0001).
10 GO-2 PIC X(0001).
10 GO-3 PIC X(0001).
The cobgensch tool can be used to create the data set migration schema file from a COBOL copybook file <XTBC106.cpy>.
In the following example, the total record length is specified as 54 with the –r option. If a record length is specified, ensure that the total length of the fields in the COBOL copybook file matches the value specified.
$ cobgensch XTBC106.cpy –r 54
The following example shows the schema file generated by cobgensch from the <XTBC106.cpy> file.
<XTBC106.conv>
* Schema Version 7.1 L1, 01, I1, NULL, NULL, 0, 1:1, L2, 05, KYAKUMEI-KN, EBC_ASC, NULL, 18, 1:1, L3, 05, BTN-CD, EBC_ASC, NULL, 4, 1:1, L4, 05, KYAKU-NO, EBC_ASC, NULL, 7, 1:1, L5, 05, ATUKAI-CD, EBC_ASC, NULL, 3, 1:1, L6, 05, MDY-CD, EBC_ASC, NULL, 3, 1:1, L7, 05, YAKU-YMD, PACKED, NULL, 5, 1:1, L8, 05, UKEW-YMD, PACKED, NULL, 5, 1:1, L9, 05, KOYU-MEI-CD, PACKED, NULL, 3, 1:1, L10, 05, KAISU, PACKED, NULL, 3, 1:1, L11, 05, GO, NULL, NULL, 0, 1:1, L12, 10, GO-1, EBC_ASC, NULL, 1, 1:1, L13, 10, GO-2, EBC_ASC, NULL, 1, 1:1, L14, 10, GO-3, EBC_ASC, NULL, 1, 1:1, * Condition L0, "\0", ( L1 L2 L3 L4 L5 L6 L7 L8 L9 L10 L11 L12 L13 L14 )
Each line in the copybook file containing a PIC statement is converted into data set conversion schema format. The PIC X statement specifies that the value of that field will be converted from EBCDIC to ASCII format; the COMP-3 statement after PIC S9 indicates a field in PACKED format. In addition to these formats, the ZONED type (zoned decimal field) and the GRAPHIC type (2-byte character field) can be used in schema files.
Instead of COBOL copybook files, PL/I include-type files such as the following can be used.
<XTBC107.inc>
3 ID CHAR(02),
3 NAME CHAR(05),
3 CODE,
5 CODE_NUM PIC'(03)9',
5 CODE_DAT PIC'(03)X',
3 ETC FIXED DEC (3, 0) ;
If a PL/I include file, <XTBC107.inc>, is used, the data set conversion schema file must be created with pligensch.
The following command uses the -s option. This option must be specified when converting only a part of the PL/I include file.
$ pligensch -s XTBC107.inc
The following is the data set conversion schema file generated from <XTBC107.inc>. The CHAR, PIC 9, and FIXED DEC statements are converted by pligensch to EBC_ASC, ZONED, and PACKED data types respectively.
<XTBC107.conv>
* Schema Version 7.1 L1, 01, ID_STRUCTURE, NULL, NULL, 0, 1:1, L2, 03, ID, EBC_ASC, NULL, 2, 1:1, L3, 03, NAME, EBC_ASC, NULL, 5, 1:1, L4, 03, CODE, NULL, NULL, 0, 1:1, L5, 05, CODE_NUM, ZONED, NULL, 3, 1:1, L6, 05, CODE_DAT, EBC_ASC, NULL, 3, 1:1, L7, 03, ETC, PACKED, NULL, 2, 1:1, * Condition L0, "\0", ( L1 L2 L3 L4 L5 L6 L7 )
Note
For more information about the schema file structure, refer to "Appendix C. Schema File Structure" in this guide.
The dsmigin tool accepts a source data set to migrate and a migration schema file to perform migration.
In the following example, <XTB.T66.raw> is the source data set, <XTB.T66.conv> is the migration schema file (in COBOL copybook format), and <XTB.T66> is the output data set.
$ dsmigin XTB.T66.raw XTB.T66 –s XTB.T66.conv –e JP –l 800
dsmigin converts the character set of each record and registers the data set in the catalog.
Note
For more information about dsmigin, refer to OpenFrame Tool Reference Guide.
PDS data sets are composed of directories that contain member files. The PDS data set name and member names (in parentheses) are set to the DSN parameter of JCL or PROC.
//SYSIN DD DSN=PLNI.EDVR.SYSIN(LNIYY01), // DISP=(SHR,PASS,KEEP)
PDS data sets are used as libraries for managing executable modules or files such as JCL, PROC and SYSIN.
In OpenFrame, PDS data sets are managed as UNIX directories and can be created with the pdsgen or dscreate .
The following example creates a PDS named TEST.PDS, by using the dscreate tool.
$ dscreate -o PO TEST.PDS
When creating a SYSIN-type PDS data set, the record format (recfm) must be specified as "L". This is an OpenFrame record format with a line feed and is not supported in mainframes.
In PDS, managing execution modules store compiled execution modules as members of the PDS directory. For member files of PDS file management such as JCL, PROC and SYSIN, execute character set conversion for the source file from the mainframe with the dsmigin tool, and then store the converted file as a member of the PDS.
GDG BASE entries are pure catalog entries that can be created with the gdgcreate. You need a correct GDG LIMIT value, which is provided by the customer, to create a GDG BASE entry.
The following example defines a GDG BASE by using the gdgcreate tool.
$ gdgcreate -l 255 TEST.GDG01
When a GDG BASE entry is registered in a user catalog, all associated PDS data sets are also registered in the same catalog. If an attempt is made to add a PDS data set to a catalog before creating a GDG BASE entry, the "AMS_ERR_GDG_NOT_REGISTERED (-4025)" error occurs.
The migration process for variable-length data sets is the same as that for regular data sets. However, analyzing the data set layout and generating the migration schema can be more complicated.
For variable-length data sets, the source data set from mainframe is identical in format to the following sequential file. Each record is composed of a 4-byte Record Descriptor Word (RDW) followed by data. The first two bytes of RDW describe the length of the record (including the 4 bytes from the RDW) and the remaining 2 bytes are filled with zeros. By using the record information of RDW, you can easily determine the start and end of a record.

As with fixed-length data sets, you can organize the migration schema for variable-length data sets into a COBOL copybook format and create the migration schema by using the cobgensch tool. However, depending on the project, you can create a migration schema directly as shown in the following example, without having to reorganize it into the COBOL copybook format.
* Schema Version 7.1 L1, 01, V-REC, NULL, NULL, 0, 1:1, L2, 05, REC-KEY, EBC_ASC, NULL, 8, 1:1, L3, 05, ODO-LEN, COPY, NULL, 2, 1:1, L4, 05, ODO-FLD, NULL, NULL, 0, 0:4000, ODO-LEN L5, 07, ODO-DAT, EBC_ASC, NULL, 1, 1:1, * Condition L0, "\0", ( L1 L2 L3 L4 L5 )
The schema file ODO-FLD is an example of a variable-length data set whose length varies according to the value of the ODO-LEN field. The number of repetitions of ODO-FLD and the data set length are determined by reading the ODO-LEN field value of the record. After the source data set and the migration schema files are prepared, the actual migration can be performed by using the dsmigin tool in the same way as a fixed-length dataset.
The following example creates the data set <TEST.VAR> with the dsmigin tool. <TEST.VAR.raw> is the source file and <TEST.VAR.conv> is the migration schema file:
$ dsmigin TEST.VAR.raw TEST.VAR –s TEST.VAR.conv –e JP -f VB
After migrating the data sets, you can use the listcat tool to verify that they have been successfully registered in the catalog. After verifying registration, you can view the data in the data sets using the dsview tool to check the result.
The following shows the contents of the data set in dsview.
The following are the general steps for migrating VSAM data sets to OpenFrame.
-
Create an empty VSAM data set by using the DEFINE CLUSTER command of the idcams tool.
-
Import data to the VSAM data set using the RECATALOG option of the dsmigin tool.
For data sets that cannot be migrated using this procedure, such as an RRDS with missing record numbers, you must write a separate data set import program for migration.
VSAM data sets can be defined using the DEFINE CLUSTER command of idcams.
The following example shows a JCL that defines a VSAM data set by using idcams.
$ idcams DEFINE CLUSTER -n TEST.KSDS -o KS -k 6,0 -l 250,250
Note
-
OpenFrame provides a function to define VSAM data sets (TSAM RDB) so that data can be converted and managed for each copybook field. For more information, refer to "Appendix D. TSAM RDB".
-
For more information about defining VSAM data sets by using IDCAMS, refer to OpenFrame Tool Reference Guide.
Unlike non-VSAM data sets, VSAM data sets can be imported with the dsmigin tool after they are defined with the DEFINE CLUSTER command of the idcams tool. You must specify the recatalog option (-R) for dsmigin.
The following example uses dsmigin to import all records from <XTB.XY1315>, a non-VSAM data set, into <TEST.VSAM.KSDS>, a VSAM data set.
$ dsmigin XTB.XY1315 TEST.KSDS –s XTB.XY1315.conv –e JP -R
Previous versions of OpenFrame did not support importing VSAM datasets using the migration tool. Instead, they used the REPRO command of the idcams utility to copy SAM-formatted non-VSAM datasets to VSAM datasets. In the current release, it is recommended to use the dsmigin tool rather than the idcams utility to import VSAM datasets.
When data set records cannot be imported by using the dsmigin tool, you need to write an additional data set import program.
Migrating data sets by using an additional import program is as follows:
-
Convert the character set in the source data set extracted from the mainframe by using the dsmigin tool.
-
Define an empty VSAM data set with the DEFINE CLUSTER command of idcams.
-
Use the data set import program to import the data set records into the new data set.
It is recommended to use a data set import program written in C, as it is the most commonly used language on the Unix platform.
Note
For information about calling the WRITE function to write an import program to store individual records into each of their correct key position, refer to "Appendix C. Data Set I/O API" in OpenFrame Data Set Guide.
Data sets can be migrated using two methods: static migration and dynamic migration. You can determine which method was used by looking at the data set schema.
-
The user selects a single migration path out of those specified in the $$COND conditions and uses it to migrate all records.
-
All group items are checked against user-specified $$COND conditions. The results are applied to a dynamic migration table. After all the items are checked, migration is executed based on the table.
Dynamic migration has lower performance than static migration because it must check all group items. Note that static migration is unavailable for the case described in the "3.4.2. When Dynamic Migration is Required" section. Static migration is available for the case described in the "3.4.3. When Dynamic Migration is Recommended" section, but dynamic migration allows for the easier creation of schema information. In other cases, dynamic migration can be used as needed.
Dynamic migration must be used in the following case:
-
If a field that determines the $$COND condition, which is used to create the schema file, exists in the OCCURS statement of the copybook.
If static migration is used when the field exists in an OCCURS statement, the migration path is determined by the first $$COND value that follows the OCCURS statement. If different condition values are specified for the same field as shown in the following example, the first $$COND value is used. This, in turn, may produce an undesired migration result.
01 A OCCURS 10 TIMES.
05 KBN PIC X.
05 B1 PIC N(3)
05 B2 PIC X(6) REDEFINES B1.
$$COND : KBN : "1" : B1
$$COND : KBN : !"1" : B2
While static migration can be used in the following case, it is easier to create schema by using dynamic migration.
-
If there is a list of data sets specified as migration targets using $$COND statements.
If there is a list of data sets to migrate, 2^n (all) items must be defined for static migration and 2*n for dynamic migration.
03 A OCCURS 10 TIMES.
05 KBN1 PIC X.
05 B1 PIC N(3).
05 B2 PIC X(6) REDEFINES B1.
05 C1 PIC X(5).
05 C2 PIC 9(5) REDEFINES C1.
05 D1 PIC X(5).
05 D2 PIC 9(5) REDEFINES D1
<$$COND statements for static migration>
$COND : KBN1 : X"01" : B1, C1, D1 $COND : KBN1 : X"02" : B1, C1, D2 $COND : KBN1 : X"03" : B1, C2, D1 $COND : KBN1 : X"04" : B1, C2, D2 $COND : KBN1 : X"05" : B2, C1, D1 $COND : KBN1 : X"06" : B2, C1, D2 $COND : KBN1 : X"07" : B2, C2, D1 $COND : KBN1 : X"08" : B2, C2, D2
<$$COND statements for dynamic migration>
$COND : KBN1 : X"01", X”02”, X”03”, X”04” : B1 $COND : KBN1 : X"04", X”05”, X”06”, X”07” : B2 $COND : KBN1 : X"01", X”02”, X”05”, X”06” : C1 $COND : KBN1 : X"03", X”04”, X”07”, X”08” : C2 $COND : KBN1 : X"01", X”03”, X”05”, X”07” : D1 $COND : KBN1 : X"02”, X”04”, X”06”, X”08” : D2
To dynamically migrate data sets, create a dynamic migration schema first by using the cobgensch tool with the -D option.
$ cobgensch -D XXX.scm
After creating the dynamic migration schema, you can migrate data sets dynamically using the dsmigin tool without specifying any options.
$ dsmigin EBCDIC ASCII -s XXX.scm
Note
For more information about cobgensch and dsmigin tools, refer to OpenFrame Tool Reference Guide.
This section describes the migration sequence for three types of data sets: fixed-length data sets, variable-length data sets, and data sets that use the REDEFINES statement.
The following shows the contents of the <FL.SAMPLE.raw> file, an EBCDIC data set that contains three records. Each record is 16 characters long.

The following COBOL copybook file, <FL.SAMPLE.cpy>, is used to identify the layout of the data set.
<FL.SAMPLE.cpy>
01 FIXEDLENGTH.
05 KEY PIC X(4).
05 TYPE PIC X(6).
05 DATA.
10 EBCDATA PIC X(3).
10 ZONEDDATA PIC S9(3).
After defining the layout of the data set, you can use the cobgensch tool to generate a migration schema file.
$ cobgensch FL.SAMPLE.cpy
After defining the layout of the data set, you can use the cobgensch tool to generate a migration schema file.
<FL.SAMPLE.conv>
* Schema Version 7.1 L1, 01, FIXEDLENGTH, NULL, NULL, 0, 1:1, L2, 05, KEY, EBC_ASC, NULL, 4, 1:1, L3, 05, TYPE, EBC_ASC, NULL, 6, 1:1, L4, 05, DATA, NULL, NULL, 0, 1:1, L5, 10, EBCDATA, EBC_ASC, NULL, 3, 1:1, L6, 10, ZONEDDATA, ZONED, TRAILING, 3, 1:1, * Condition L0, "\0", ( L1 L2 L3 L4 L5 L6 )
After preparing the source data set and the migration schema file, you can use the dsmigin tool to migrate the data set.
$ dsmigin FL.SAMPLE.raw FL.SAMPLE.TEST –s FL.SAMPLE.conv –l 16
Once the migration is complete, you can view the migrated data set using the dsview tool.

The following example uses a variable-length data set with the following records.
00000001..AAAAAAAAAAAA 00000002..BBBB 00000003..CCCCCCCCCCCCCCCCCCCCC
The following shows the contents of the <VB.SAMPLE.raw> file, an EBCDIC data set with four-byte RDW (Record Description Word) in the first 4 bytes of each record.

The following copybook file, <VB.SAMPLE.cpy>, shows the layout of the data set.
<VB.SAMPLE.cpy>
01 V-REC.
05 REC-KEY PIC X(8).
05 ODO-LEN PIC S9(4) COMP.
05 ODO-FLD OCCURS 4000 TIMES
DEPENDING ON ODO-LEN.
07 ODO-DAT PIC X(1).
The following migration schema file is generate by the cobgensch tool with the previous copybook as input.
* Schema Version 7.1 L1, 01, V-REC, NULL, NULL, 0, 1:1, L2, 05, REC-KEY, EBC_ASC, NULL, 8, 1:1, L3, 05, ODO-LEN, COPY, NULL, 2, 1:1, L4, 05, ODO-FLD, NULL, NULL, 0, 1:4000, ODO-LEN L5, 07, ODO-DAT, EBC_ASC, NULL, 1, 1:1, * Condition L0, "\0", ( L1 L2 L3 L4 L5 )
After preparing the source data set and the migration schema, you can use the dsmigin tool to migrate the data set.
$ dsmigin VB.SAMPLE.raw VB.SAMPLE.TEST –s VB.SAMPLE.conv –e JP -f VB
The three file names specified in the previous command - <VB.SAMPLE.raw>, <VB.SAMPLE.TEST>, and <VB.SAMPLE.conv> - are the source data set file, the target data set file, and the migration schema file respectively.
For data sets with copybook files that contain REDEFINES statements, information must be provided about the conditions that will trigger the redefinition.
01 A.
05 B PIC X(01).
05 C PIC X(05).
05 D REDEFINES C.
10 E PIC X(02).
10 F PIC X(03).
In the above example, assume that D field should only be redefined as C if the value of the B field is "A". All other cases should reference the C field. To achieve this, a $$COND statement must be added to the copybook file.
The following is the syntax of a $$COND statement.
$$COND : NAME_01 : VALUE_01 [: NAME_02 : VALUE_02 … ] : REDEFINE_NAME [...]
-
$$COND
-
Label that specifies the start of the condition statement.
-
-
NAME_01 : VALUE_01
-
A field name and condition value pair separated with a colon (:). When using the dsmigin tool, the value specified in VALUE_# will be converted automatically to the NAME_# field type. This means that you can enter an ASCII value enclosed with double quotes without knowing the actual field type, such as EBCDIC, ZONED, or PACKED.
-
Multiple entries of 'NAME_# : VALUE_#' pair are also separated with a colon (:).
-
-
REDEFINE_NAME
-
The redefined field to use when the $$COND statement is met. Multiple field names can be specified.
-
The type of a value in the condition statement can be converted to another type by explicitly specifying the desired type.
-
The following field types can be specified.
Type Description ! (exclamation mark)
Checks NOT EQUALITY.
'(empty)'
Returns the default type of the field.
'A'
Uses the ASCII character of the value.
'E'
Converts to EBCDIC character.
'P' or 'UP'
Converts to Packed Decimal or Unsigned Packed Decimal type.
'Z' or 'UZ'
Converts to Zoned Decimal or Unsigned Zoned Decimal type.
'G'
Converts to GRAPHIC (2Byte) character.
'H'
Coverts the value to a Hexadecimal value. (Example: H"123" → 0x7B)
'X'
Converts the 2 byte value to a 1 byte Hex value. (Example: X"12AB" → 0x12 0xAB)
'T'
Checks the field type. Only Zoned, Packed and National are supported. (Example: T"ZONED"/T"PACKED"/T"NATIONAL" → Check whether the field is Zoned/Packed Decimal/National Character.)
-
To specify a packed or zoned decimal type, you must decide whether it is a signed or unsigned decimal. For example, if the hexadecimal value of the last digit of a packed decimal field is '0x0C' (positive value) or '0x0D' (negative value), then you must use the signed packed decimal type; if the last digit is '0x0F', then you must use the unsigned packed decimal type instead.
If the hexadecimal value of the last digit of a zoned decimal field is '0xC0' (positive value) or '0xD0' (negative value), then you must use the signed zoned decimal type; if the last digit is '0xF0', you must use the unsigned zoned decimal type.
-
The following example uses a $$COND conditional statement in a copybook with a REDEFINES statement.
01 A.
05 B PIC X(01).
05 C PIC X(05).
05 D REDEFINES C.
10 E PIC X(02).
10 F PIC X(03).
$$COND : B : "A" : D
The cobgensch tool references the $$COND statement to generate a migration schema that will be used by dsmigin.
The following is an example of a migration schema generated by cobgensch.
* Schema Version 7.1
L1, 01, A, NULL, NULL, 0, 1:1,
L2, 05, B, EBC_ASC, NULL, 1, 1:1,
L3, 05, C, EBC_ASC, NULL, 5, 1:1,
L4, 05, D, NULL, NULL, 0, 1:1, # REDEFINES C
L5, 10, E, EBC_ASC, NULL, 2, 1:1,
L6, 10, F, EBC_ASC, NULL, 3, 1:1,
* Condition
L2, "A", ( L1 L2 L4 L5 L6 )
L0, "\0", ( L1 L2 L3 )
The conditions specified in the migration schema is used during migration.
The statement beginning with the label 'L0' is the default condition statement.
Data sets using multiple layouts are specified with conditional statements using constructs similar to the previous section.
01 AAA-A.
03 BBB-A.
05 DATA-1 PIC X(01).
05 DATA-2 PIC X(04).
05 DATA-A REDEFINES DATA-2.
07 DATA-A1 PIC 9(02).
07 DATA-A2 PIC X(02).
01 AAA-B.
03 BBB-B.
05 DATA-3 PIC 9(01).
05 DATA-4 PIC 9(04).
05 DATA-D REDEFINES DATA-4.
07 DATA-D1 PIC 9(01).
07 DATA-D2 PIC X(03).
When there are multiple level 01 items as in the previous example, you must specify a $$COND statement, as for REDEFINES statement, to use a layout other than the first item.
A $$COND statement to use a specific layout can be written as follows:
$$COND : DATA-3 : "B" : AAA-B
The following is an example of a $$COND statement that specifies the REDEFINES statement of the second layout.
$$COND : DATA-3 : "D" : AAA-B DATA-D
The following is an example of a schema file created by using the cobgensch tool:
* Schema Version 7.1 L1, 01, AAA-A, NULL, NULL, 0, 1:1, L2, 03, BBB-A, NULL, NULL, 0, 1:1, L3, 05, DATA-1, EBC_ASC, NULL, 1, 1:1, L4, 05, DATA-2, EBC_ASC, NULL, 4, 1:1, L5, 05, DATA-A, NULL, NULL, 0, 1:1, # REDEFINES DATA-2 L6, 07, DATA-A1, U_ZONED, NULL, 2, 1:1, L7, 07, DATA-A2, EBC_ASC, NULL, 2, 1:1, L8, 01, AAA-B, NULL, NULL, 0, 1:1, L9, 03, BBB-B, NULL, NULL, 0, 1:1, L10, 05, DATA-3, U_ZONED, NULL, 1, 1:1, L11, 05, DATA-4, U_ZONED, NULL, 4, 1:1, L12, 05, DATA-D, NULL, NULL, 0, 1:1, # REDEFINES DATA-4 L13, 07, DATA-D1, U_ZONED, NULL, 1, 1:1, L14, 07, DATA-D2, EBC_ASC, NULL, 3, 1:1, * Condition L10, "B", ( L8 L9 L10 L11 ) L10, "D", ( L8 L9 L10 L12 L13 L14 ) L0, "\0", ( L1 L2 L3 L4 )
The schema file includes two layouts with level 01. All conditions, except for the default condition, specified using $$COND start from the AAA-B field, which is level 01 of the second layout.
The schema file allows you to apply a conversion rule based on the value of the specified field, DATA-3 in the previous example, to migrate data sets that use multiple layouts.