DML 명령어는 알파벳 순으로 나열하고, 각 명령어에 대한 설명과 문법, 특권, 예제를 기술한다. 문법을 설명할 때는 “제3장 SQL 연산”의 형식을 그대로 따르고, 키워드 와 문법의 구성요소는 별도의 표로 설명한다.
INSERT 구문은 테이블 또는 뷰에 0개 이상의 ROW를 삽입한다.
INSERT의 세부 내용은 다음과 같다.
-
문법
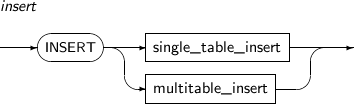
-
특권
INSERT ANY TABLE 시스템 특권을 가진 사용자는 모든 테이블과 모든 뷰에서 ROW를 삽입할 수 있다.
테이블에 ROW를 삽입하기 위해서는 테이블을 사용자가 소유하고 있거나, 그 테이블에 대해 INSERT 스키마 오브젝트 특권을 가지고 있어야 한다.
뷰의 기반 테이블에 ROW를 삽입하기 위해서는 다음의 두 가지 조건을 동시에 만족해야 한다.
-
사용자가 뷰를 가지고 있거나 뷰에 대한 INSERT 스키마 오브젝트 특권이 있어야 한다.
-
뷰가 속한 스키마의 사용자가 뷰의 기반 테이블을 가지고 있거나 기반 테이블에 대해 INSERT 스키마 오브젝트 특권을 가지고 있어야 한다.
-
-
구성요소
-
insert
구성요소 설명 single_table_insert 하나의 테이블 또는 뷰에 값을 명시하여 하나의 ROW를 삽입하거나, 부질의를 통해서 ROW를 삽입할 수 있다. multi_table_insert 하나 이상의 테이블에 부질의로부터 계산된 ROW를 삽입할 수 있다. 부질의에 별칭을 지정할 수는 없고 부질의의 SELECT 리스트의 컬럼을 참조하여 values_clause 또는 WHEN 조건절을 구성할 수는 있다.
multi_table_insert는 로컬 테이블에만 수행할 수 있다. 뷰 또는 원격(Remote) 테이블에는 수행될 수 없다.
-
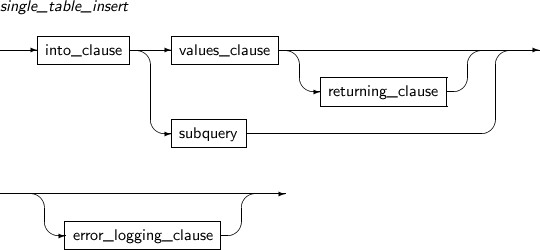
single_table_insert
구성요소 설명 into_clause 특정 컬럼에만 ROW를 삽입하고자 할 때 사용한다. values_clause 삽입되는 ROW의 컬럼 값을 지정한다.
삽입할 컬럼 값의 나열 순서는 값을 삽입하고자 하는 컬럼과 같은 순서가 되어야 한다. 값을 삽입할 컬럼을 나열한 경우 같은 순서로 컬럼 값을 나열해야 하고, 값을 삽입할 컬럼을 나열하지 않은 경우 테이블 내에 정의된 컬럼 순서에 따라 컬럼 값을 나열해야 한다.
returning_clause returning_clause를 사용해 삽입이 일어난 결과 ROW의 값을 반환 받을 수 있다. 삽입이 일어난 ROW로부터 연산식의 값을 계산해 그 결과를 호스트 변수 또는 tbPSM 변수에 저장한다.
returning_clause에는 다음과 같은 제약조건이 있다.
-
expr은 단순 연산식 또는 단독으로 사용된 단일 그룹 집단 함수(GROUP BY 절이 없음)만 가능하다.
-
하나의 returning_clause에 단순 연산식과 단일 그룹 집단 함수가 같이 나올 수는 없다.
-
단일 그룹 집단 함수 내에 예약어 DISTINCT를 사용할 수 없다.
-
LONG 타입의 값을 returning_clause를 통해 받을 수 없다.
subquery 부질의 결과 반환되는 모든 ROW를 삽입한다. 구체적인 문법은 “5.1. SELECT”를 참고한다.
부질의를 통하여 컬럼 값을 삽입하는 경우 부질의 결과 반환되는 ROW의 컬럼의 개수 및 순서는 값을 삽입하고자 하는 컬럼의 개수 및 순서와 일치해야 한다. 부질의는 임의의 테이블, 뷰를 참조할 수 있으며, 삽입 대상이 되는 테이블 또는 뷰를 참조할 수도 있다. 삽입 대상 테이블 또는 뷰를 참조할 때는 별칭을 통하여 참조한다.
error_logging_clause 에러가 발생할 경우 수행을 중단하지 않고 에러 내용과 삽입하려던 데이터를 에러 로깅 테이블(Error logging table)에 저장한 후 다음 ROW에 대해서 진행한다. -
-
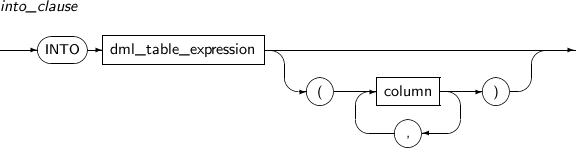
into_clause
구성요소 설명 dml_table_expression ROW를 삽입할 객체를 명시한다. column 특정 컬럼에만 값을 삽입하고자 하는 경우에는 해당 컬럼의 이름을 나열한다.
나열되지 않은 컬럼에는 기본값이 선언되어 있으면 기본값이 삽입되고 그렇지 않으면 NULL이 삽입된다. 만약 나열되지 않은 컬럼에 대하여 NOT NULL 제약조건이 정의되어 있다면, 새로운 ROW를 삽입하지 않고 에러를 반환한다.
값을 삽입할 컬럼을 나열하지 않으면 모든 컬럼에 대하여 삽입할 값을 지정해야 한다. 만약 하나의 INSERT 문장에 의하여 ROW의 삽입이 진행되다가 에러가 발생한 경우에 이전에 삽입된 모든 ROW도 함께 제거된다.
-
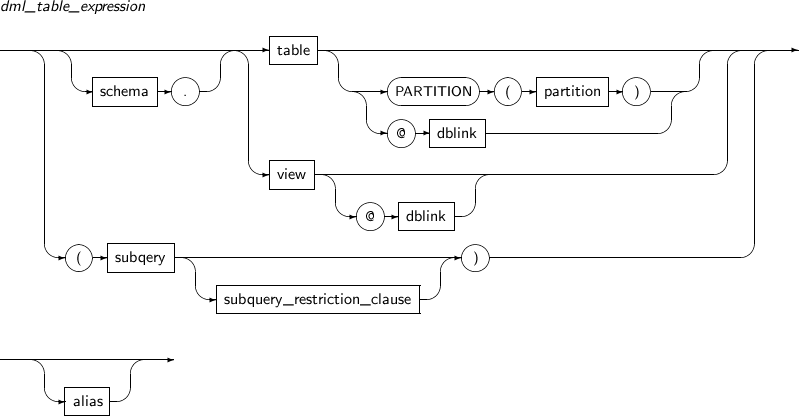
dml_table_expression
구성요소 설명 schema 삽입할 객체가 속해 있는 스키마명을 명시한다. 생략하면 현재 사용자의 스키마에서 객체를 찾는다. table
view
subquery
테이블이나 뷰의 이름 또는 삽입할 컬럼을 가지고 있는 부질의를 명시한다. 테이블에 INSERT를 수행하면 테이블에 연결된 INSERT 트리거가 동작한다.
뷰 또는 부질의를 명시할 경우 하나의 키 보존 테이블에 대한 삽입이 수행된다. 뷰에 삽입하려면 뷰가 갱신 가능한 뷰여야 한다. 예를 들어 뷰의 정의에 다음이 포함되어 있으면 그 뷰는 갱신 가능한 뷰가 아니다.
-
집합 연산자
-
DISTINCT 연산자
-
집단 함수또는 분석 함수
-
GROUP BY 또는 CONNECT BY 절
-
WITH READ ONLY
뷰가 WITH CHECK OPTION 과 함께 정의되어 있으면 갱신한 결과를 뷰가 SELECT할 수 있어야만 갱신이 가능하다.
PARTITION (partition) 테이블이 분할 테이블인 경우 파티션명을 명시할 수 있다. 이를 사용하면 데이터베이스 성능 향상에 도움이 된다. dblink 데이터베이스 링크의 이름 전체 또는 부분을 명시한다. 데이터베이스 링크를 명시할 때는 반드시 앞에 '@'를 붙여야 한다. WITH CHECK OPTION 삽입 결과를 뷰 또는 부질의가 SELECT할 수 없으면 삽입이 허용되지 않도록 한다. alias 테이블, 뷰, 부질의가 INSERT 문의 다른 곳에서 참조될 수 있도록 별칭을 지정한다. -
-
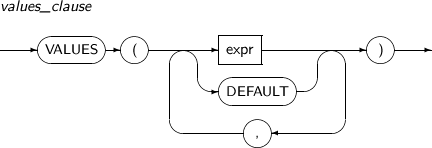
values_clause
구성요소 설명 expr 컬럼 값을 반환하는 임의의 연산식이다. 컬럼은 명시할 수 없다. 구체적인 문법은 “3.3. 연산식”을 참고한다. DEFAULT 컬럼에 삽입할 값으로 DEFAULT라고 지정한 경우 해당 컬럼의 기본값이 선언되어 있으면 기본값을 삽입하고 그렇지 않으면 NULL을 삽입한다. 뷰에 대해서는 DEFAULT라고 지정할 수 없다. -
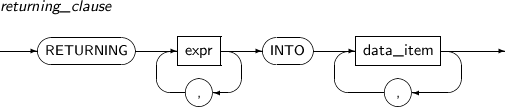
returning_clause
구성요소 설명 expr 결과 ROW로부터 returning_clause를 통해 반환할 값을 계산하는 연산식이다. 자세한 내용은 “3.3. 연산식”을 참고한다. data_item ROW로부터 계산한 expr 값을 저장할 호스트 변수 또는 tbPSM 변수를 지정한다. -
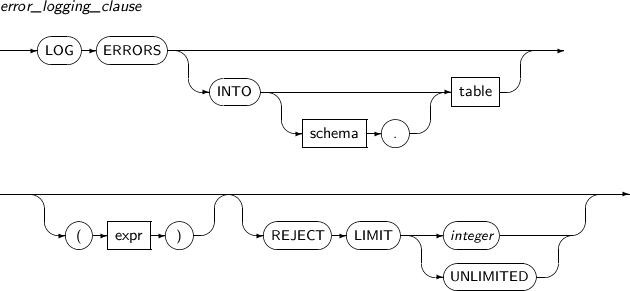
error_logging_clause
구성요소 설명 table 에러 로깅 테이블의 이름을 명시한다.
명시하지 않으면 'ERR$_'를 삽입하려는 테이블명 앞에 붙여서 사용한다. DBMS_ERRLOG 패키지를 이용하여 자동으로 생성할 수 있다. 사용자가 직접 생성할 수도 있지만 권장하지는 않는다.
expr 문자열을 반환하는 임의의 표현식이다. 수행문의 태그용으로 사용한다. REJECT LIMIT 허용하는 최대 에러 개수를 명시한다. 최대 에러 개수보다 많은 에러가 발생하면 DML 문은 수행이 실패하고 롤백된다. 이 절을 명시하지 않는다면 기본 값은 0 이다. 다음과 같은 에러를 처리할 수 있다.
-
NOT NULL 제약조건
-
CHECK 제약조건
-
UNIQUE 제약조건
-
PRIMARY KEY, FOREIGN KEY 제약조건
-
데이터 타입 에러
다음의 경우에는 사용할 수 없다.
-
DEFERED 제약조건
-
Direct-Path INSERT, Multi Table INSERT, MERGE 문
-
UPDATE 문의 UNIQUE 제약조건, PRIMARY KEY, FOREIGN KEY 제약조건
-
LONG, LOB 타입의 컬럼을 가지는 테이블
-
-
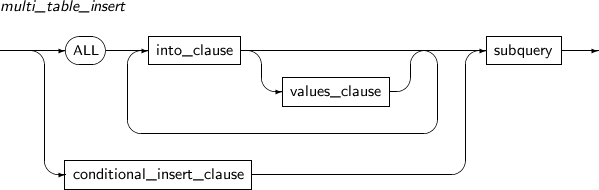
multi_table_insert
구성요소 설명 ALL into_clause 예약어 ALL 다음에 여러 개의 into_clause를 사용하면 부질의의 결과 ROW에 대해서 각 into_clause를 한 번씩 수행한다. values_clause 삽입되는 ROW의 컬럼 값을 지정한다. subquery의 컬럼을 사용할 수 있다.
삽입할 컬럼 값의 나열 순서는 값을 삽입하고자 하는 컬럼과 같은 순서가 되어야 한다. 값을 삽입할 컬럼을 나열한 경우 같은 순서로 컬럼 값을 나열해야 하고, 값을 삽입할 컬럼을 나열하지 않은 경우 테이블 내에 정의된 컬럼 순서에 따라 컬럼 값을 나열해야 한다.
subquery 부질의 결과 반환되는 모든 ROW를 삽입한다. 구체적인 문법은 “5.1. SELECT”를 참고한다.
부질의를 통하여 컬럼 값을 삽입하는 경우 부질의 결과 반환되는 ROW의 컬럼의 개수 및 순서는 값을 삽입하고자 하는 컬럼의 개수 및 순서와 일치해야 한다. 부질의는 임의의 테이블, 뷰를 참조할 수 있으며, 삽입 대상이 되는 테이블 또는 뷰를 참조할 수도 있다. 삽입 대상 테이블 또는 뷰를 참조할 때는 별칭을 통하여 참조한다.
conditional_insert_clause WHEN 조건절을 통하여 into_clause를 수행할지 안 할지를 판단한다. WHEN 조건절은 부질의의 select 리스트를 참조해야 하며, 하나의 multi_table_insert 는 최대 127개의 WHEN 절을 가질 수 있다. -
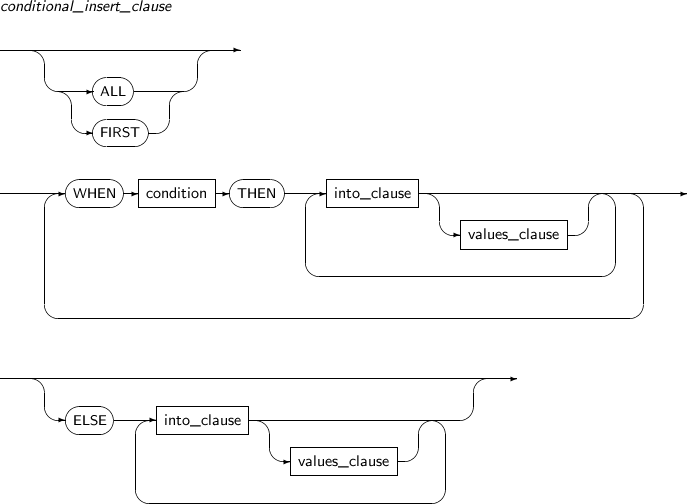
conditional_insert_clause
구성요소 설명 ALL ALL을 명시했을 경우 WHEN 조건절을 만족하는 모든 into_clause를 수행한다. ALL 또는 FIRST를 명시 하지 않았을 경우 기본값은 ALL이다. FIRST FIRST를 명시했을 경우 WHEN 조건절을 만족하는 첫 번째 into_clause 하나만 수행하고 나머지 into_clause는 건너뛴다. WHEN condition THEN condition 부분에 조건을 명시한다. 조건을 만족할 경우 into_clause를 수행한다. into_clause 특정 컬럼에만 데이터를 삽입하고자 할 때 사용한다. values_clause 삽입되는 ROW의 컬럼 값을 지정한다.
삽입할 컬럼 값의 나열 순서는 값을 삽입하고자 하는 컬럼과 같은 순서가 되어야 한다. 값을 삽입할 컬럼을 나열한 경우 같은 순서로 컬럼 값을 나열해야 하고, 값을 삽입할 컬럼을 나열하지 않은 경우 테이블 내에 정의된 컬럼 순서에 따라 컬럼 값을 나열해야 한다.
ELSE 어느 WHEN 조건절도 만족하지 못했다면 ELSE 절 뒤에 나온 into_clause를 수행한다. ELSE 절이 없을 경우에는 아무 일도 하지 않는다.
-
-
예제
다음은 INSERT를 사용하는 예이다.
INSERT INTO EMP VALUES (35, 'John', 'Houston', 30000, 5); INSERT INTO EMP (EMPNO, ENAME, DEPTNO) VALUES (35, John, 5); INSERT INTO EMP VALUES (35, 'John', DEFAULT, 30000, NULL);
다음은 error logging 절을 사용하는 예이다.
SQL> create table p (a number primary key); Table 'P' created. SQL> insert into p values (1); 1 row inserted. SQL> insert into p values (2); 1 row inserted. SQL> insert into p values (3); 1 row inserted. SQL> insert into p values (4); 1 row inserted. SQL> create table f (a number references p(a)); Table 'F' created. SQL> insert into f values (1); 1 row inserted. SQL> insert into f values (3); 1 row inserted. SQL> exec dbms_errlog.create_error_log('f'); PSM completed. SQL> commit; Commit completed. SQL> insert into f (select 1 from dual union all select 5 from dual) log errors reject limit 1; 1 row inserted. SQL> select * from f; A ---------- 1 3 1 3 rows selected. SQL> select * from err$_f; TIB_ERR_NUMBER$ --------------- TIB_ERR_MESG$ -------------------------------------------------------------------------------- TIB_ERR_ROWID$ TIB_ERR_OPTYP$ ------------------ -------------------- TIB_ERR_TAG$ -------------------------------------------------------------------------------- A -------------------------------------------------------------------------------- -10008 INTEGRITY constraint ('SYS'.'SYS_CON25700497') violated: primary key not found. I 5 1 row selected.
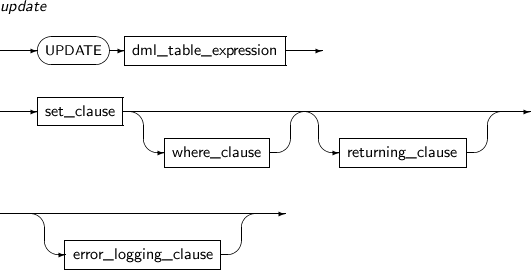
UPDATE 구문은 테이블 또는 뷰 내의 ROW에 지정된 컬럼의 값을 갱신한다.
UPDATE의 세부 내용은 다음과 같다.
-
문법
-
특권
UPDATE ANY TABLE 시스템 특권을 가지고 있으면 사용자는 모든 테이블과 모든 뷰를 갱신할 수 있다. 테이블을 갱신하기 위해서는 테이블을 사용자가 소유하고 있거나, 그 테이블에 대해 UPDATE 스키마 오브젝트 특권을 가지고 있어야 한다.
뷰의 기반 테이블을 갱신하기 위해서는 다음의 두 가지 조건을 동시에 만족해야 한다.
-
사용자가 뷰를 가지고 있거나 뷰에 대한 UPDATE 스키마 오브젝트 특권이 있어야 한다.
-
뷰가 속한 스키마의 사용자가 뷰의 기반 테이블을 가지고 있거나 기반 테이블에 대해 UPDATE 스키마 오브젝트 특권을 가지고 있어야 한다.
-
-
구성요소
-
update
구성요소 설명 dml_table_expression 갱신할 테이블 객체를 명시한다. set_clause set_clause를 사용해서 갱신할 컬럼의 값을 명시한다. where_clause 조건이 TRUE인 ROW에 대해서만 갱신을 수행하도록 지정한다. 이 절을 생략하면 테이블 또는 뷰의 모든 ROW에 대해 갱신을 수행한다. returning_clause returning_clause를 사용해 갱신이 일어난 결과 ROW의 값을 반환 받을 수 있다. 갱신이 일어난 ROW로부터 연산식의 값을 계산해 그 결과를 호스트 변수 또는 tbPSM 변수에 저장한다.
returning_clause에는 다음과 같은 제약조건이 있다.
-
expr은 단순 연산식 또는 단독으로 사용된 단일 그룹 집단 함수(GROUP BY 절이 없음)만 가능하다.
-
하나의 returning_clause에 단순 연산식과 단일 그룹 집단 함수가 같이 나올 수는 없다.
-
단일 그룹 집단 함수 내에 예약어 DISTINCT를 사용할 수도 없다.
-
LONG 타입의 값을 returning_clause를 통해 받을 수 없다.
error_logging_clause 에러가 발생할 경우 수행을 중단하지 않고 에러 내용과 삽입하려던 데이터를 에러 로깅 테이블(Error logging table)에 저장한 후 다음 ROW에 대해서 진행한다. -
-
dml_table_expression
구성요소 설명 schema 갱신할 객체가 속해 있는 스키마를 명시한다. 생략하면 현재 사용자의 스키마에서 객체를 찾는다. table
view
subquery
테이블이나 뷰의 이름 또는 갱신할 컬럼을 가지고 있는 부질의를 명시한다. 테이블에 UPDATE를 수행하면 테이블에 연결된 UPDATE 트리거가 동작한다.
뷰를 명시할 경우 뷰의 기반 테이블이 갱신된다. 뷰를 갱신하려면 뷰가 갱신 가능한 뷰여야 한다. 예를 들어 뷰의 정의에 다음이 포함되어 있으면 그 뷰는 갱신 가능한 뷰가 아니다.
-
집합 연산자
-
DISTINCT 연산자
-
집단 함수또는 분석 함수
-
GROUP BY 또는 CONNECT BY 절
-
WITH READ ONLY
dblink 데이터베이스 링크의 이름 전체 또는 부분을 명시한다. 데이터베이스 링크를 명시할 때는 반드시 앞에 '@'를 붙여야만 한다.
데이터베이스 링크에는 다음과 같은 제약조건이 있다.
-
원격 테이블에서는 Tibero 에서 지원하지 않는 사용자정의 타입 또는 REF 객체에 대한 질의를 할 수 없다.
-
원격 테이블에서는 Tibero 에서 지원하지 않는 ANYTYPE, ANYDATA 또는 ANYDATASET 타입의 컬럼에 대한 질의를 할 수 없다.
PARTITION (partition) 테이블이 분할 테이블인 경우 파티션명을 명시할 수 있다. 이를 사용하면 데이터베이스 성능 향상에 도움이 된다. WITH CHECK OPTION 갱신의 결과를 부질의가 SELECT할 수 없으면 갱신이 허용되지 않도록 한다. alias 테이블, 뷰, 부질의가 UPDATE 문의 다른 곳에서 참조될 수 있도록 별칭을 지정한다. -
-
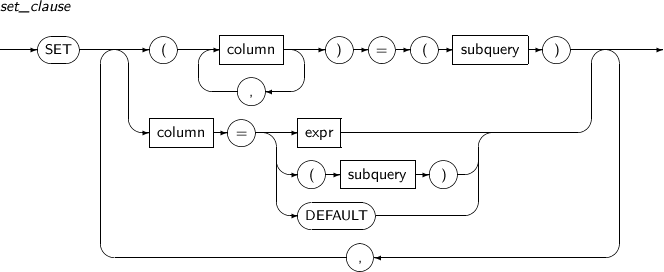
set_clause
구성요소 설명 column 갱신할 컬럼의 이름을 명시한다. 명시하지 않은 컬럼의 값은 바뀌지 않는다.
대용량 객체형 컬럼을 명시할 경우 컬럼이 분할 테이블의 분할 키 정의에 참여하고 있을 때는 UPDATE의 결과로 인해 현재 ROW가 참여하고 있는 파티션에 이 ROW가 계속 참여할 수 없을 때는 UPDATE가 실패한다.
subquery 최대 1개의 ROW를 반환하는 스칼라 서브쿼리 (scalar subquery)를 명시한다. 여러 ROW가 반환되면 UPDATE가 실패한다.
update_set_clause에서 하나의 컬럼을 명시했을 경우는, 부질의도 SELECT 리스트를 통해 하나의 값만 반환해 주어야 한다.
update_set_clause에서 여러 개의 컬럼을 명시했을 경우는, 부질의가 SELECT 리스트를 통해 반환하는 값의 개수와 컬럼의 개수가 일치하여야 한다.
부질의가 ROW를 반환하지 못했을 경우 컬럼에 갱신되는 값은 NULL이다.
expr 컬럼에 갱신할 새 값을 명시하는 연산식이다. 자세한 내용은 “3.3. 연산식”을 참고한다. DEFAULT 컬럼에 기본값이 지정된 경우 그 값을 갱신할 값으로 지정한다. 기본값이 없는데 명시했을 경우는 NULL로 갱신된다. 뷰를 갱신할 때는 DEFAULT를 명시할 수 없다. -
returning_clause
구성요소 설명 expr 결과 ROW로부터 returning_clause 절을 통해 반환할 값을 계산하는 연산식이다. 자세한 내용은 “3.3. 연산식”을 참고한다. data_item ROW로부터 계산한 expr 값을 저장할 호스트 변수 또는 tbPSM 변수에 저장한다.
-
-
예제
다음은 UPDATE를 사용하는 예이다.
UPDATE EMP SET SALARY = 35000; UPDATE EMP SET SALARY = 35000 WHERE DEPTNO = 5; UPDATE EMP SET DEPTNO = DEFAULT WHERE DEPTNO IS NULL; UPDATE EMP SET SALARY = SALARY * 1.05, ADDR = (SELECT LOC FROM DEPT WHERE DEPTNO = 5) WHERE DEPTNO = 5;
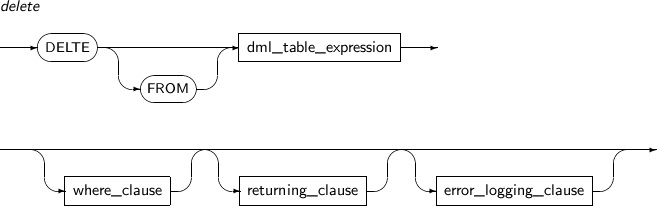
DELETE 구문은 테이블이나 뷰에서 ROW를 삭제한다. 뷰의 경우 (가능할 때만) ROW가 삭제될 기반 테이블이 하나로 정해진다. 테이블은 파티션으로 분할되어 있을 수 있다.
DELETE의 세부 내용은 다음과 같다.
-
문법
-
특권
DELETE ANY TABLE 시스템 특권을 가진 사용자는 모든 테이블과 모든 뷰에서 ROW를 삭제할 수 있다. 테이블에서 ROW를 삭제하기 위해서는 테이블을 사용자가 소유하고 있거나, 그 테이블에 대해 DELETE 스키마 오브젝트 특권을 가지고 있어야 한다.
뷰의 기반 테이블에서 ROW를 삭제하기 위해서는 다음의 두 가지 조건을 동시에 만족해야 한다.
-
사용자가 뷰를 가지고 있거나 뷰에 대한 DELETE 스키마 오브젝트 특권이 있어야 한다.
-
뷰가 속한 스키마의 사용자가 뷰의 기반 테이블을 가지고 있거나 기반 테이블에 대해 DELETE 스키마 오브젝트 특권을 가지고 있어야 한다.
-
-
구성요소
-
delete
구성요소 설명 dml_table_expression 삭제할 테이블 객체를 명시한다. where_clause 조건이 TRUE인 ROW만 삭제하도록 지정한다. 삭제의 대상이 되는 ROW를 기반으로 조건의 값을 계산하며, 부질의를 포함할 수 있다. 이 절을 생략하면 테이블 또는 뷰의 기반 테이블의 모든 ROW를 삭제한다. 자세한 내용은 “3.4. 조건식”을 참고한다. returning_clause returning_clause를 사용하면 삭제해서 없어져 버린 ROW의 값을 반환 받을 수 있다. 삭제된 ROW로부터 연산식의 값을 계산해 그 결과를 호스트 변수 또는 tbPSM 변수에 저장한다.
returning_clause에는 다음과 같은 제약조건이 있다.
-
expr은 단순 연산식 또는 단독으로 사용된 단일 그룹 집단 함수(GROUP BY 절이 없음)만 가능하다.
-
하나의 returning_clause에 단순 연산식과 단일 그룹 집단 함수가 같이 나올 수는 없다.
-
단일 그룹 집단 함수 내에 예약어 DISTINCT를 사용할 수도 없다.
-
LONG 타입의 값을 returning_clause를 통해 받을 수 없다.
error_logging_clause 에러가 발생할 경우 수행을 중단하지 않고 에러 내용과 삽입하려던 데이터를 에러 로깅 테이블(Error logging table)에 저장한 후 다음 ROW에 대해서 진행한다. -
-
dml_table_expression
구성요소 설명 schema 테이블이나 뷰가 속해 있는 스키마를 명시한다. 생략하면 현재 사용자의 스키마에서 객체를 찾는다. table
view
subquery
테이블이나 뷰의 이름 또는 삭제할 ROW를 포함하는 ROW 집합을 SELECT하는 부질의를 명시한다. 테이블에 DELETE를 수행하면 테이블에 연결된 DELETE 트리거가 동작한다.
뷰를 명시할 경우 뷰의 기반 테이블에서 ROW가 삭제된다. 뷰에서 ROW를 삭제하려면 뷰가 갱신 가능한 뷰여야 한다. 예를 들어 뷰의 정의에 다음이 포함되어 있으면 그 뷰는 갱신 가능한 뷰가 아니다.
-
집합 연산자
-
DISTINCT 연산자
-
집단 함수또는 분석 함수
-
GROUP BY 또는 CONNECT BY 절
-
WITH READ ONLY
ROW를 삭제한 후에도 테이블이나 인덱스에서 그 ROW가 차지하고 있었던 공간은 그대로 유지된다.
PARTITION (partition) 테이블이 분할 테이블인 경우 파티션명을 명시할 수 있다. 이를 사용하면 데이터베이스 성능 향상에 도움이 된다. dblink 데이터베이스 링크의 이름 전체 또는 부분을 명시한다. 데이터베이스 링크를 명시할 때는 반드시 앞에 '@'를 붙여야만 한다.
데이터베이스 링크에는 다음과 같은 제약조건이 있다.
-
원격 테이블에서는 Tibero 에서 지원하지 않는 사용자정의 타입 또는 REF 객체에 대한 질의를 할 수 없다.
-
원격 테이블에서는 Tibero 에서 지원하지 않는 ANYTYPE, ANYDATA 또는 ANYDATASET 타입의 컬럼에 대한 질의를 할 수 없다.
subquery_restriction_clause WITH READ ONLY 가 명시되어 있으면 삭제할 수 없다. WITH CHECK OPTION은 무시된다. alias 테이블, 뷰, 부질의가 DELETE 문의 다른 곳에서 참조될 수 있도록 별칭을 지정한다. -
-
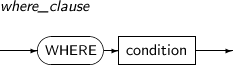
where_clause
구성요소 설명 condition WHERE 예약어 뒤에 조건식을 명시한다. 조건식이 TRUE인 ROW만 제거하도록 지정한다.
제거의 대상이 되는 ROW를 기반으로 condition 값을 계산하며, 부질의를 포함할 수 있다. where_clause를 생략하면 테이블 또는 뷰의 모든 ROW를 제거한다.
-
returning_clause
구성요소 설명 expr 결과 ROW로부터 returning_clause 절을 사용해 반환할 값을 계산할 때 사용하는 연산식이다. 자세한 내용은 “3.3. 연산식”을 참고한다. data_item ROW로부터 계산된 expr 값을 호스트 변수 또는 tbPSM 변수에 저장한다.
-
-
예제
다음은 DELETE를 사용하는 예이다.
DELETE FROM EMP; DELETE FROM John.EMP WHERE SALARY < 20000
CALL 구문은 단독으로 정의되거나 패키지 내에 정의된 프러시저나 함수를 실행한다.
CALL의 세부 내용은 다음과 같다.
-
문법

-
특권
단독으로 정의된 프러시저나 함수를 실행하려면 그 프러시저나 함수에 대한 EXECUTE 스키마 오브젝트 특권을 가지고 있어야 한다. 프러시저나 함수가 패키지 내에 정의된 경우에는 패키지에 대한 EXECUTE 특권을 가지고 있어야 한다.
또한, EXECUTE ANY PROCEDURE 시스템 특권이 있으면 어떤 프러시저나 함수라도 실행할 수 있다.
-
구성요소
-
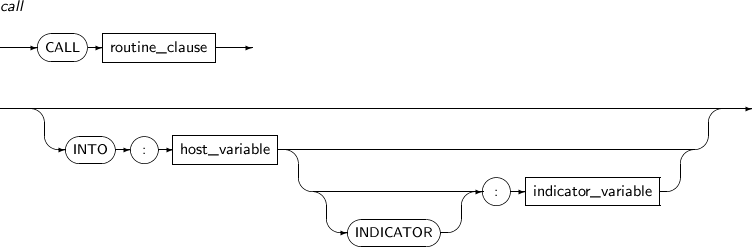
call
구성요소 설명 routine_clause 단독으로 정의된 프러시저나 함수가 속해있는 스키마, 프러시저나 함수의 이름 등 세부내용을 명시한다. INTO 함수를 실행하는 경우에만 INTO 절을 명시해야 한다. :host_variable 반환 값을 저장할 호스트 변수를 명시한다. :indicator_variable 호스트 변수의 값 또는 상태를 표시하기 위한 지시자 변수를 명시한다. -
routine_clause
구성요소 설명 schema 단독으로 정의된 프러시저나 함수가 속해 있는 스키마를 명시한다.
또는 프러시저나 함수를 포함하는 패키지가 속해 있는 스키마를 명시한다.
package 프러시저나 함수를 포함하는 패키지를 명시한다. function 실행하고자 하는 함수의 이름을 명시한다. procedure 실행하고자 하는 프러시저의 이름을 명시한다. argument 프러시저나 함수가 파라미터를 받는 경우에는 파라미터를 명시한다.
argument에는 다음과 같은 제약조건이 있다.
-
파라미터에는 의사 컬럼을 사용할 수 없다.
-
IN OUT 또는 OUT으로 명시된 파라미터는 대응하는 호스트 변수가 있어야 한다.
-
파라미터의 수는 반환 값을 포함하여 1000개까지 사용할 수 있다.
-
4KB 이상의 크기를 가지는 문자열 또는 RAW, LONG RAW 데이터를 파라미터로 사용할 수 없다.
-
-
-
예제
다음은 CALL을 사용하는 예이다.
CALL get_board_name (30);
MERGE 구문은 하나, 또는 그 이상의 원본(Source) 데이터로부터 ROW를 선택하여 테이블에 삽입 또는 갱신 작업을 수행한다. 삽입, 갱신 작업 중 어느 작업을 수행할 것인지를 결정하는 조건을 명시할 수 있다.
MERGE는 여러 작업을 통합할 수 있는 편리한 방법이다. MERGE를 수행함으로써 여러 삽입, 갱신, 삭제 작업을 수행하여야 하는 수고를 덜 수 있다. 하나의 MERGE 문에서 같은 ROW를 여러 번 갱신할 수 없다.
MERGE의 세부 내용은 다음과 같다.
-
문법
-
특권
MERGE를 수행하기 위해서는 대상(Target) 데이터에 대한 INSERT 스키마 오브젝트 특권과 UPDATE 스키마 오브젝트 특권을 가지고 있어야 하며, 원본 데이터에 대한 SELECT 스키마 오브젝트 특권을 가지고 있어야 한다.
merge_update_clause에 DELETE clause를 명시하게 위해서는 대상 데이터에 대한 DELETE 스키마 오브젝트 특권 또한 가지고 있어야 한다.
-
구성요소
-
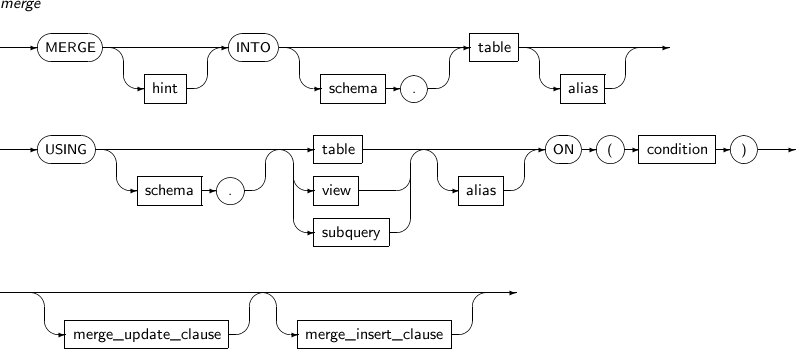
merge
구성요소 설명 hint 힌트를 명시한다. INTO 데이터를 삽입 또는 갱신할 테이블을 지정한다. schema 스키마의 이름을 명시한다. alias 별칭을 명시한다. USING 삽입 또는 갱신할 원본 데이터를 명시하기 위해 USING 절을 사용한다. 원본 데이터로는 테이블, 뷰, 또는 부질의의 결과가 사용될 수 있다. table
view
subquery
원본 데이터로 사용될 테이블, 뷰, 부질의를 명시한다. ON (condition) MERGE작업이 수행될 조건을 명시하기 위해 ON 절을 사용한다. condition 부분에 조건식을 명시한다.
대상 데이터의 테이블의 각 ROW에 대하여 조건이 TRUE일 경우 원본 데이터의 테이블의 대응하는 데이터로 ROW를 갱신한다.
모든 ROW에 대하여 조건이 FALSE일 경우 대응하는 원본 데이터 테이블의 ROW를 대상 데이터 테이블에 삽입한다.
merge_update_clause merge_update_clause는 대상 데이터 테이블의 새 컬럼 값을 명시한다. ON 절이 참일 경우 이 갱신을 수행한다.
갱신이 실행되면 대상 데이터 테이블에 설정된 모든 갱신 트리거가 작동된다.
merge_update_clause는 단독으로 명시될 수도 있고 merge_insert_clause 와 같이 명시될 수도 있다. 만약 두 가지 모두 명시될 경우 순서는 상관 없다. merge_update_clause를 먼저 명시해도 되고, merge_insert_clause를 먼저 명시해도 된다.
merge_update_clause는 ON 절에서 참조된 컬럼은 갱신할 수 없다는 제약이 있다.
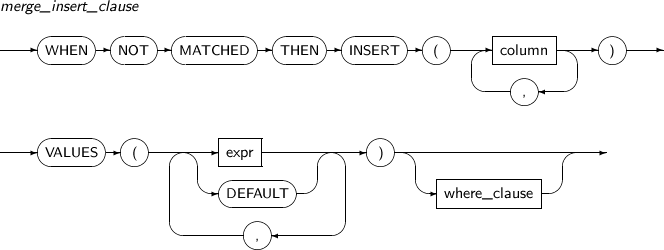
merge_insert_clause merge_insert_clause는 ON 절의 조건이 거짓일 경우 대상 데이터 테이블에 삽입될 값을 명시한다.
삽입이 실행되면 대상 데이터 테이블에 정의된 모든 삽입 트리거가 작동된다.
모든 원본 데이터의 ROW를 테이블에 삽입하기 위해서 ON 절 조건에 0=1과 같이 항상 거짓으로 평가되는 필터를 사용하면 된다. 이러한 방법은 merge_update_clause를 생략하는 것과는 다르다. merge_update_clause를 생략하는 경우에 데이터베이스는 조인을 수행하지만 필터를 사용할 경우에 데이터베이스는 조인을 하지 않고 무조건 삽입을 수행한다.
merge_insert_clause는 단독으로 명시될 수도 있고 merge_update_clause 와 같이 명시될 수도 있다. 두 가지 모두 명시될 경우 순서는 상관 없다.
-
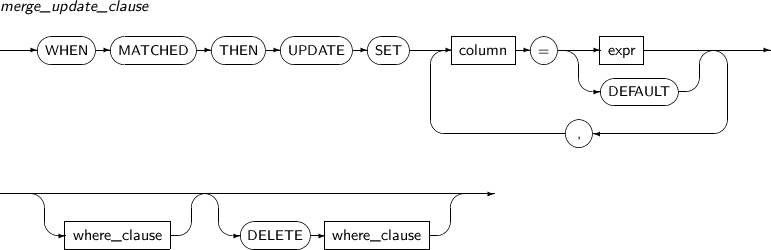
merge_update_clause
구성요소 설명 column 갱신을 수행할 컬럼의 이름을 명시한다. expr 컬럼의 값을 갱신하는 데 사용될 임의의 연산식이다. DEFAULT 컬럼이 값을 기본값으로 갱신할 때 사용된다. where_clause 갱신 조건의 설정을 위해서 where_clause를 명시한다. 원본 데이터에 대한 조건과 대상 데이터에 대한 조건 모두 명시될 수 있다. DELETE where_clause 갱신 중 데이터를 삭제하기 위해서 DELETE where_clause를 명시하면 된다.
이 DELETE where_clause에 의해 삭제되는 ROW는 갱신에 의해 영향을 받은 ROW 뿐이다. ROW가 삭제되면 설정된 모든 삭제 트리거가 작동된다.
-
merge_insert_clause
구성요소 설명 column 삽입을 수행할 컬럼의 이름을 명시한다. 이 부분을 생략하면, 대상 데이터 테이블의 컬럼의 수는 VALUES 절에 명시된 값의 수와 일치하여야 한다. expr 컬럼의 값을 삽입하는 데 사용될 임의의 연산식이다. DEFAULT 컬럼이 값을 기본값으로 삽입할 때 사용된다. where_clause 특정 조건을 만족시키는 ROW만을 삽입하고자 할 때에는 where_clause를 명시한다. 이 조건은 원본 데이터의 테이블의 값만을 참조할 수 있다. -
where_clause
구성요소 설명 condition 갱신 조건이나 삽입 조건을 설정하기 위해서 where_clause를 명시한다. condition에는 조건식을 명시한다.
-
-
예제
다음은 MERGE를 사용하는 예이다.
MERGE INTO BONUS USING PERSONNEL ON (B.PNUM = PERSONNEL.PNUM) WHEN MATCHED THEN UPDATE SET BONUS.BONUS = BONUS.BONUS*1.5 DELETE WHERE (PERSONNEL.SALARY > 3000) WHEN NOT MATCHED THEN INSERT VALUES (PERSONNEL.PNUM, PERSONNEL.SALARY*0.2);
Tibero는 다음의 DML 문장을 병렬로 수행할 수 있다.
-
INSERT INTO SELECT
병렬 DML도 병렬 질의와 마찬가지로 PARALLEL 힌트를 지정하여 사용할 수 있다. INSERT INTO SELECT 문장은 PARALLEL 힌트의 위치에 따라 어느 부분을 병렬화 할 것인지 지정할 수 있다.
SELECT 뒤에만 힌트를 주면 SELECT하는 부분만 병렬화되고 INSERT 뒤에만 힌트를 주면 실제 INSERT하는 작업만 병렬화하게 된다. 따라서 두 작업 모두 병렬화 하기 위해서는 INSERT, SELECT 뒤에 모두 힌트를 주어야 한다.
-
UPDATE
-
DELETE
DML을 병렬로 수행하기 위해서는 우선 다음과 같이 세션에 병렬 DML의 실행 여부를 설정해 주어야 한다.
SQL> ALTER SESSION ENABLE PARALLEL DML; Session altered.
위의 예에서처럼 ALTER SESSION 문장으로 세션의 속성을 변경 시키지 않으면 PARALLEL 힌트는 동작하지 않고 병렬 DML은 수행되지 않는다.
다음은 트랜잭션이 수행되는 중에 병렬 DML을 수행했을 때 발생하는 에러이다.
SQL> INSERT INTO TEMP_TBL VALUES (1, 1); 1 row inserted. SQL> ALTER SESSION ENABLE PARALLEL DML; TBR-12064: Cannot alter the session parallel DML state within a transaction
트랜잭션이 수행되는 중에는 COMMIT 또는 ROLLBACK 명령어로 현재 트랜잭션의 수행을 종료해야만 ALTER SESSION 문장을 수행할 수 있다.
병렬 DML을 수행할 때 트랜잭션과 관련해 다음 두 가지 제약조건이 있으며, 이러한 제약이 있는 것은 트랜잭션의 정합성을 보장하기 위해서이다.
-
병렬 DML을 수행한 트랜잭션에서는 병렬 DML로 수정한 테이블에 어떠한 접근도 할 수 없다.
-
같은 트랜잭션 내에서 수정한 테이블에 대해 병렬 DML로 접근하려 할 경우에도 병렬 DML을 수행할 수 없다.
다음은 병렬 DML을 수행한 트랜잭션에서는 병렬 DML로 수정한 테이블에 접근하려고 하는 경우 에러가 발생하는 예이다.
SQL> ALTER SESSION ENABLE PARALLEL DML;
Session altered.
SQL> INSERT /*+ parallel (3) */ INTO TEMP_TBL2 SELECT /*+ parallel (3) */ * FROM
TEMP_TBL;
100000 rows inserted.
SQL> SELECT COUNT(*) FROM TEMP_TBL2;
TBR-12063: cannot read/modify on object after modifying it in parallel다음은 같은 트랜잭션에서 수정한 테이블에 대해 병렬 DML로 접근하려 할 경우에 에러가 발생하는 예이다.
SQL> ALTER SESSION ENABLE PARALLEL DML;
Session altered.
SQL> INSERT INTO TEMP_TBL2 VALUES (1, 1);
1 row inserted.
SQL> INSERT /*+ parallel (3) */ INTO TEMP_TBL2 SELECT /*+ parallel (3) */ * FROM
TEMP_TBL;
TBR-12067: cannot modify an object in parallel after modifying it
병렬 DML은 다음 같은 경우에서는 수행되지 않는다.
-
삽입, 갱신, 삭제를 하려는 테이블에 트리거가 있는 경우
-
returning_clause가 있는 경우
-
대상 테이블에 대용량 객체형 컬럼이 있는 경우
-
대상 테이블의 인덱스가 online-rebuild를 수행 중인 경우
-
standby replication을 사용 중인 경우
-
self-referential integrity, delete cascade, deferred integrity 등이 있는 경우
-
분산 트랜잭션을 사용하는 경우
-
DDL, TCS, SCS를 사용하는 경우