내용 목차
- 4.1. 개요
- 4.2. 함수 목록
- 4.2.1. ABS
- 4.2.2. ACOS
- 4.2.3. ADD_MONTHS
- 4.2.4. AGGR_CONCAT
- 4.2.5. APPENDCHILDXML
- 4.2.6. ASCII
- 4.2.7. ASCIISTR
- 4.2.8. ASIN
- 4.2.9. ATAN
- 4.2.10. ATAN2
- 4.2.11. AVG
- 4.2.12. BITAND
- 4.2.13. CAST
- 4.2.14. CEIL
- 4.2.15. CHARTOROWID
- 4.2.16. CHR
- 4.2.17. COALESCE
- 4.2.18. COMPOSE
- 4.2.19. CONCAT
- 4.2.20. CONVERT
- 4.2.21. CORR
- 4.2.22. COS
- 4.2.23. COSH
- 4.2.24. COUNT
- 4.2.25. COVAR_POP
- 4.2.26. COVAR_SAMP
- 4.2.27. CUME_DIST
- 4.2.28. CURRENT_DATE
- 4.2.29. CURRENT_TIME
- 4.2.30. CURRENT_TIMESTAMP
- 4.2.31. DBTIMEZONE
- 4.2.32. DECODE
- 4.2.33. DECOMPOSE
- 4.2.34. DELETEXML
- 4.2.35. DENSE_RANK
- 4.2.36. DUMP
- 4.2.37. EMPTY_BLOB
- 4.2.38. EMPTY_CLOB
- 4.2.39. EXISTSNODE
- 4.2.40. EXP
- 4.2.41. EXTRACT
- 4.2.42. EXTRACT(XML)
- 4.2.43. EXTRACTVALUE
- 4.2.44. FIRST
- 4.2.45. FIRST_VALUE
- 4.2.46. FLOOR
- 4.2.47. FROM_TZ
- 4.2.48. GREATEST
- 4.2.49. GROUPING
- 4.2.50. GROUPING_ID
- 4.2.51. GROUP_ID
- 4.2.52. HEXTORAW
- 4.2.53. INET_ATON
- 4.2.54. INET_NTOA
- 4.2.55. INITCAP
- 4.2.56. INSERTCHILDXML
- 4.2.57. INSERTCHILDXMLAFTER
- 4.2.58. INSERTCHILDXMLBEFORE
- 4.2.59. INSERTXMLAFTER
- 4.2.60. INSERTXMLBEFORE
- 4.2.61. INSTR
- 4.2.62. ISFRAGMENT
- 4.2.63. KURT
- 4.2.64. LAG
- 4.2.65. LAST_DAY
- 4.2.66. LAST
- 4.2.67. LAST_VALUE
- 4.2.68. LEAD
- 4.2.69. LEAST
- 4.2.70. LENGTH
- 4.2.71. LN
- 4.2.72. LNNVL
- 4.2.73. LOCALTIMESTAMP
- 4.2.74. LOG
- 4.2.75. LOWER
- 4.2.76. LPAD
- 4.2.77. LTRIM
- 4.2.78. MAX
- 4.2.79. MEDIAN
- 4.2.80. MIN
- 4.2.81. MOD
- 4.2.82. MONTHS_BETWEEN
- 4.2.83. NEW_TIME
- 4.2.84. NEXT_DAY
- 4.2.85. NLSSORT
- 4.2.86. NLS_INITCAP
- 4.2.87. NLS_LOWER
- 4.2.88. NLS_UPPER
- 4.2.89. NTILE
- 4.2.90. NULLIF
- 4.2.91. NUMTODSINTERVAL
- 4.2.92. NUMTOYMINTERVAL
- 4.2.93. NVL
- 4.2.94. NVL2
- 4.2.95. ORA_HASH
- 4.2.96. OVERLAPS
- 4.2.97. PERCENT_RANK
- 4.2.98. PERCENTILE_CONT
- 4.2.99. PERCENTILE_DISC
- 4.2.100. POWER
- 4.2.101. RANK
- 4.2.102. RATIO_TO_REPORT
- 4.2.103. RAWTOHEX
- 4.2.104. REGEXP_COUNT
- 4.2.105. REGEXP_INSTR
- 4.2.106. REGEXP_REPLACE
- 4.2.107. REGEXP_SUBSTR
- 4.2.108. REGR_AVGX
- 4.2.109. REGR_AVGY
- 4.2.110. REGR_COUNT
- 4.2.111. REGR_INTERCEPT
- 4.2.112. REGR_R2
- 4.2.113. REGR_SLOPE
- 4.2.114. REGR_SXX
- 4.2.115. REGR_SXY
- 4.2.116. REGR_SYY
- 4.2.117. REMAINDER
- 4.2.118. REPLACE
- 4.2.119. REVERSE
- 4.2.120. ROUND(number)
- 4.2.121. ROUND(date)
- 4.2.122. ROWIDTOCHAR
- 4.2.123. ROW_NUMBER
- 4.2.124. RPAD
- 4.2.125. RTRIM
- 4.2.126. SESSIONTIMEZONE
- 4.2.127. SIGN
- 4.2.128. SIN
- 4.2.129. SINH
- 4.2.130. SKEW
- 4.2.131. SQRT
- 4.2.132. STDDEV
- 4.2.133. STDDEV_POP
- 4.2.134. STDDEV_SAMP
- 4.2.135. SUBSTR
- 4.2.136. SUM
- 4.2.137. SYS_CONNECT_BY_PATH
- 4.2.138. SYS_CONTEXT
- 4.2.139. SYS_EXTRACT_UTC
- 4.2.140. SYS_GUID
- 4.2.141. SYSDATE
- 4.2.142. SYSTIME
- 4.2.143. SYSTIMESTAMP
- 4.2.144. TAN
- 4.2.145. TANH
- 4.2.146. TO_CHAR(character)
- 4.2.147. TO_CHAR(datetime)
- 4.2.148. TO_CHAR(number)
- 4.2.149. TO_CLOB
- 4.2.150. TO_DATE
- 4.2.151. TO_DSINTERVAL
- 4.2.152. TO_LOB
- 4.2.153. TO_MULTI_BYTE
- 4.2.154. TO_NCHAR
- 4.2.155. TO_NUMBER
- 4.2.156. TO_SINGLE_BYTE
- 4.2.157. TO_TIME
- 4.2.158. TO_TIMESTAMP
- 4.2.159. TO_TIMESTAMP_TZ
- 4.2.160. TO_YMINTERVAL
- 4.2.161. TRANSLATE
- 4.2.162. TRIM
- 4.2.163. TRUNC(number)
- 4.2.164. TRUNC(date)
- 4.2.165. TZ_OFFSET
- 4.2.166. TZ_SHIFT
- 4.2.167. UID
- 4.2.168. UNISTR
- 4.2.169. UPDATEXML
- 4.2.170. UPPER
- 4.2.171. USER
- 4.2.172. USERENV
- 4.2.173. VAR_POP
- 4.2.174. VAR_SAMP
- 4.2.175. VARIANCE
- 4.2.176. VSIZE
- 4.2.177. XMLAGG
- 4.2.178. XMLCAST
- 4.2.179. XMLCOMMENT
- 4.2.180. XMLCONCAT
- 4.2.181. XMLELEMENT
- 4.2.182. XMLEXISTS
- 4.2.183. XMLFOREST
- 4.2.184. XMLPARSE
- 4.2.185. XMLPI
- 4.2.186. XMLQUERY
- 4.2.187. XMLSERIALIZE
- 4.2.188. XMLTABLE
- 4.2.189. XMLTRANSFORM
본 장에서는 Tibero에서 제공하는 내장 함수에 대해 기술한다.
Tibero에서는 다양한 내장 함수를 제공하고 있다. 이러한 함수 중의 일부는 SQL 표준에 정의되어 있으며, 일부는 Tibero에서 추가적으로 제공하는 것이다. Tibero 의 함수는 크게 단일 로우 함수와 집단 함수로 구분할 수 있다.
일부 함수는 파라미터가 없는 것도 있지만, 대부분의 함수는 하나 이상의 파라미터를 입력으로 받는다. 또한 모든 함수는 하나의 출력 값을 반환한다. 각 파라미터는 데이터 타입이 정해져 있다. 정해진 데이터 타입 이외의 다른 타입의 값이 입력된 경우에는 “3.3.1. 연산식의 변환”에서 설명한 대로 데이터 타입의 변환을 시도한다. 데이터 타입의 변환이 불가능한 경우에는 에러를 반환한다. 또한, 범위를 넘는 값을 컬럼에 저장할 때에도 에러를 반환한다.
대부분의 함수는 파라미터 값으로 NULL이 입력된 경우 NULL을 반환한다. NULL이 입력된 경우에도 NULL을 반환하지 않는 함수로는 CONCAT, NVL, REPLACE 등이 있다.
함수의 반환값을 컬럼에 저장할 때에는 반환값의 범위에 유의해야 한다.
-
함수의 반환값이 NUMBER 타입인 경우
컬럼의 정밀도와 스케일 범위 내의 값이어야 한다.
-
CHAR 타입인 경우
컬럼의 최대 길이 범위 내의 값이어야 한다.
-
VARCHAR 타입인 경우
컬럼의 최대 길이 범위 내의 값이어야 한다.
단일 로우 함수는 하나의 로우로부터 컬럼 값을 파라미터로 입력 받는 함수이다. 함수의 파라미터는 반드시 컬럼 값만 입력받는 것은 아니고 실제 데이터를 직접 입력으로 받을 수도 있다.
단일 로우 함수는 SQL 문장 내의 어떤 연산식에도 포함될 수 있다.
집단 함수는 하나 이상의 로우로부터 컬럼 값을 파라미터로 입력받는 함수이다. 함수의 파라미터는 반드시 컬럼 값만 입력받는 것은 아니고 실제 데이터를 직접 입력으로 받을 수도 있다.
집단 함수는 SELECT 문의 SELECT 절, GROUP BY 절, HAVING 절에만 포함된다.
Tibero에서 제공하는 집단 함수에는 AVG, COUNT, MAX, MIN, SUM이 있다. 이러한 함수는 각각 파라미터로 주어진 컬럼에 대하여 평균, 개수, 최댓값, 최솟값, 합계를 구한다. 만약 파라미터로 실제 데이터 값이 주어지면 그 값을 그대로 반환한다.
SELECT 절
SELECT 문에서 SELECT 절의 집단 함수는 중첩될 수 있다. 단, 다른 위치의 집단 함수는 중첩되면 안 된다. 또한, SELECT 절의 집단 함수도 한 번의 중첩만을 허용한다.
따라서, 다음과 같은 집단 함수는 에러를 반환한다.
COUNT(SUM(AVG(SALARY)))
중첩된 집단 함수의 계산은 먼저 각 그룹에 대한 안쪽의 집단 함수를 계산하고, 여기에서 반환된 모든 값에 대하여 바깥쪽의 집단 함수를 계산한다. 예를 들어 SUM(AVG(SALARY)) 함수는 모든 그룹으로부터 SALARY 컬럼 값의 평균을 구하고, 그다음 모든 평균값의 합계를 구하여 반환한다.
집단 함수의 괄호 내에는 조건식이 아닌 임의의 연산식이 올 수 있다. SELECT 문에서 SELECT 절의 집단 함수는 다른 집단 함수를 포함하는 연산식이 올 수도 있다.
따라서, 다음과 같은 집단 함수도 유효하다.
SUM(AVG(SALARY) * COUNT(EMPNO) + 1.10)
COUNT 함수는 괄호 안에 애스터리스크(*)가 올 수도 있다. 이 경우 특정 컬럼이 아닌 전체 로우의 개수를 반환한다.
로우를 하나도 포함하지 않는 빈 테이블에 대해 집단 함수를 포함하는 SELECT 문을 실행하면, 결과 로우가 하나도 반환되지 않는다. 예외적으로, SELECT 절에 COUNT(*) 함수를 포함하면 0 값의 컬럼을 갖는 하나의 로우가 반환된다.
GROUP BY 절
집단 함수는 대개 SELECT 문 내에서 GROUP BY 절과 함께 사용한다. 집단 함수는 GROUP BY 절에 의하여 분리된 각 그룹에 포함된 모든 로우에 대하여 하나의 값을 반환한다. 만약 SELECT 문에서 GROUP BY 절을 포함하지 않으면, 전체 테이블을 하나의 그룹으로 인식한다.
다음의 SELECT 문은 GROUP BY 절을 포함한 예이다.
SELECT AVG(SALARY) FROM EMP GROUP BY DEPTNO;
위의 문장은 테이블 EMP 내의 모든 로우 중에서 같은 DEPTNO 컬럼 값을 갖는 로우의 그룹으로 분리하고, 각 그룹에 포함된 모든 직원의 SALARY 컬럼 값의 평균을 계산한다.
HAVING 절
SELECT 문에서 HAVING 절은 그룹에 대한 조건식을 포함한다. HAVING 절은 SELECT 절이나 GROUP BY 절에 포함된 컬럼 또는 그 이외의 컬럼에 대한 집단 함수를 포함할 수 있다.
다음의 SELECT 문은 HAVING 절을 포함한 예이다. 본 예제에서는 3명 이상의 직원이 소속된 부서에 대해서만 SALARY 컬럼 값의 평균을 계산한다.
SELECT AVG(SALARY) FROM EMP GROUP BY DEPTNO HAVING COUNT(EMPNO) >= 3;
집단 함수의 파라미터 앞에는 DISTINCT 또는 ALL 예약어를 포함시킬 수 있다. 이러한 예약어는 중복되는 컬럼 값에 대한 처리를 정의하며, DISTINCT는 중복을 제거하고, ALL은 중복을 허용한다.
예를 들어 한 그룹 내의 로우가 갖고 있는 SALARY 컬럼 값이 20000, 20000, 20000, 40000이라면, AVG(DISTINCT SALARY) 함수의 결과는 30000이며, AVG(ALL SALARY) 함수의 결과는 25000이다. 만약 아무 것도 지정하지 않으면 기본값은 ALL이다.
다음 표는 Tibero에서 제공하는 집단 함수목록이다.
| 집단 함수 | 설명 |
|---|---|
| AVG | 그룹 내의 모든 로우에 대한 expr 값의 평균을 구하는 함수이다. |
| CORR | 파라미터로 주어진 expr1가 expr2의 상관계수를 계산하는 함수이다. |
| COUNT | 쿼리가 반환하는 로우의 개수를 세는 함수이다. |
| COVAR_POP | expr1, expr2의 모공분산을 계산하는 함수이다. |
| COVAR_SAMP | expr1, expr2의 표본공분산을 계산하는 함수이다. |
| DENSE_RANK | 각 그룹별로 로우를 정렬한 다음 그룹 내의 각 로우에 대한 순위를 반환하는 함수이다. |
| FIRST | 정렬된 로우에서 처음에 해당하는 로우를 뽑아내어 명시된 집단함수를 적용한 결과를 반환한다. |
| LAST | 정렬된 로우에서 마지막에 해당하는 로우를 뽑아내어 명시된 집단함수를 적용한 결과를 반환한 다. |
| MAX | 그룹 내의 모든 로우에 대한 expr 값 중의 최댓값을 구하는 함수이다. |
| MIN | 그룹 내의 모든 로우에 대한 expr 값 중의 최솟값을 구하는 함수이다. |
| PERCENT_RANK | 파라미터로 주어진 값의 그룹 내의 위치를 나타내 주는 함수이다. |
| PERCENTILE_CONT | 연속 분포 모델에서 파라미터로 주어진 백분위 값에 해당하는 값을 계산하는 역 분포 함수이다. |
| PERCENTILE_DISC | 이산 분포를 가정한 역분산 함수로 분석 함수로도 사용할 수 있다. |
| RANK | 그룹별로 로우를 정렬한 후 그룹 내의 각 로우의 순위를 반환하는 함수이다. |
| 임의의 수치 데이터 쌍의 집합에 가장 맞는 선형 방정식을 구하기 위해 사용된다. | |
| STDDEV | expr의 표본 표준편차를 반환하는 함수이다. |
| STDDEV_POP | expr의 모표준편차를 반환하는 함수이다. |
| STDDEV_SAMP | expr의 누적 표본 표준편차를 반환하는 함수이다. |
| SUM | 그룹 내의 모든 로우에 대한 expr 값의 합계를 구하는 함수이다. |
| VARIANCE | expr의 분산을 반환한다. |
| VAR_POP | expr의 모분산을 반환한다. |
| VAR_SAMP | expr의 표본분산을 반환하는 함수이다. |
| XMLAGG | XML 조각을 받고, 이를 한데 모아 XML 문서로 만들어 반환하는 함수이다. |
분석 함수는 집단 함수와 마찬가지로 특정 로우 그룹에 대한 집계 값을 구하는 데 사용된다.
집단 함수와 다른 점은 하나의 로우 그룹에 속한 모든 로우가 하나의 집계 값을 공유하지 않는 다는 것이다. 각각의 로우에 대해 로우 그룹이 별개로 정의되며, 때문에 모든 로우가 별개로 각각 자신의 로우 그룹에 대한 집계 값을 갖게 된다. 이 로우 그룹을 분석 함수에서는 윈도우라고 부르며, analytic_clause 안에 정의가 된다. 윈도우 영역은 물리적인 로우의 개수로 정의될 수도 있고, 논리적인 어떤 계산 값을 통해서 정의될 수도 있다.
하나의 쿼리 블록 안에서 분석 함수는 ORDER BY 절을 제외하고 가장 마지막에 수행되는 연산이다. WHERE 절, GROUP BY 절, HAVING 절 모두 분석 함수가 수행되기 전에 먼저 적용된다. 그러므로 분석 함수는 SELECT 절 또는 ORDER BY 절에만 나올 수 있다.
analytic_function
분석 함수는 크게 analytic_function, argument, analytic_clause로 구성된다.
analytic_function의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 analytic_function 분석 함수의 이름을 명시한다. arguments 분석 함수의 파라미터를 명시한다. 함수에 따라 파라미터의 타입이 결정된다. OVER analytic_clause OVER analytic_clause를 사용해 함수를 분석 함수로 수행할 수 있다.
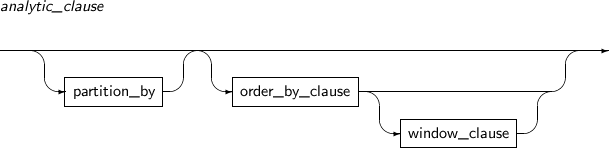
analytic_clause
OVER analytic_clause를 사용하여 함수를 분석 함수로 수행할 수 있다. 분석 함수는 ORDER BY 절을 제외한 다른 모든 절의 내용이 처리된 다음에 적용된다. 그러므로 분석 함수가 계산한 결과의 일부만 선택하고자 하면, 분석 함수를 수행한 쿼리를 뷰로 둘러싸고, 그 쿼리를 둘러싼 뷰에 WHERE 절을 적용하면 된다. analytic_clause 안에 분석 함수를 사용할 수는 없다. 그러나 부질의 내에 분석 함수를 사용하는 것은 가능하다.
analytic_clause의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 partition_by 분석 함수를 계산하기 전에 현재 질의 블록의 결과 집합을 분할한다. order_by_clause partition_by에 의해 분할된 하나의 파티션 내에서 로우를 어떻게 정렬할지를 명시한다. window_clause window_clause를 가질 수 있는 경우가 있다. 분석 함수의 order_by_clause를 명시할 경우에만 이 window_clause를 명시할 수 있다.
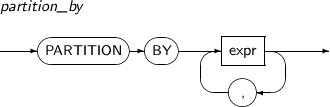
partition_by
분석 함수를 계산하기 전에 현재 질의 블록의 결과 집합을 expr 또는 expr의 리스트를 기준으로 분할한다. 이 절을 명시하지 않으면, 분석 함수의 윈도우는 전체 로우 집합 내에서 움직이게 된다.
하나의 질의 블록의 SELECT 절 또는 ORDER BY 절에 여러 개의 분석 함수를 명시할 수 있으며, 각각이 서로 다른 PARTITION BY 키를 갖는 것도 가능하다.
partition_by의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 expr expr이 취할 수 있는 값은 상수, 컬럼, 분석 함수가 아닌 함수로 구성된 연산식이다.
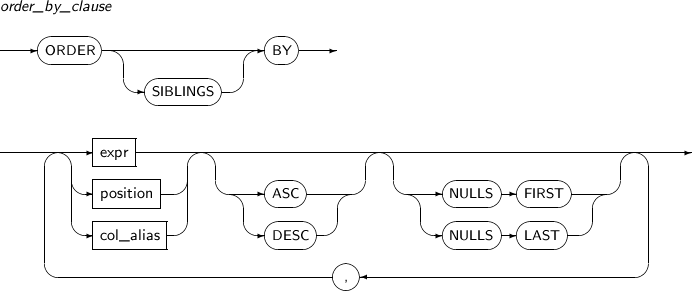
order_by_clause
partition_by에 의해 분할된 하나의 파티션 내에서 로우를 어떻게 정렬할지를 명시한다. 정렬에 사용되는 키 값은 여러 개를 명시할 수 있다.
분석 함수에서 사용되는 order_by_clause 내에서는 위치 상수(ORDER BY 1과 같은)를 사용할 수 없다. SIBLINGS 역시 사용할 수 없다. SELECT 리스트의 컬럼의 별칭도 사용할 수 없다. 그 이외에는 보통의 ORDER BY 절과 사용 방식이 같다.
분석 함수에 사용된 order_by_clause는 파티션 내의 로우의 순서를 결정할 뿐이지 분석 함수를 적용하고 난 쿼리 블록의 최종 결과 집합의 로우의 순서를 결정해 주는 것은 아니다. 이를 위해서는 쿼리 블록을 위한 별도의 ORDER BY 절을 추가로 명시해야만 한다.
order_by_clause의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 SIBLINGS order_by_clause는 계층 질의의 형제 노드 내에서 정렬 순서를 정의한다.
분석 함수에서는 사용할 수 없다.
expr 정렬의 키로 사용되는 연산식이다. position select_list에 명시된 expr의 위치를 지정한다.
분석 함수에서는 사용할 수 없다.
ASC 디폴트로, 정렬 순서를 명시한다.
ASC는 오름차순으로 정렬한다.
DESC 정렬 순서를 명시한다.
DESC는 내림차순으로 정렬한다.
NULLS FIRST NULL 값의 정렬 순서를 명시한다.
NULLS FIRST는 오름차순 정렬의 디폴트로 사용된다.
NULLS LAST NULL 값의 정렬 순서를 명시한다.
NULLS LAST는 내림차순 정렬의 디폴트로 사용된다.
window_clause
분석 함수에 따라 window_clause를 가질 수 있는 경우가 있다. 분석 함수의 order_by_clause를 명시할 경우에만 window_clause를 명시할 수 있다. window_clause를 명시하지 않았을 때는 필요한 경우에 디폴트 윈도우로 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW가 지정된다.
window_clause의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 ROWS
윈도우 타입을 ROW로 지정한다. 분석 함수는 현재 로우가 정의하는 윈도우 내의 로우에 대해서 계산이 된다. ROWS는 윈도우를 물리적인 로우 단위로 정의한다.
RANGE와는 달리 ROW로 지정된 Window의 로우는 order_by_clause를 통해 동률이 나왔을 경우 상이한 로우가 결과로 반환된다.
RANGE 윈도우 타입을 RANGE로 지정한다. RANGE는 현재 로우를 기준으로 논리적인 오프셋을 명시하여 윈도우를 정의한다.
ROW와는 달리 RANGE로 지정된 윈도우의 로우는 언제나 항상 똑같은 로우가 반환된다.
RANGE를 명시할 경우는 order_by_clause에 하나의 키만 명시할 수 있다.
RANGE로 정의된 윈도우의 경우 두 개의 로우가 order_by_clause로 인해 정렬한 결과가 동률일 때는 분석 함수의 결과 값은 항상 동일하다. “4.2.136. SUM”의 분석 함수 예제에서 이를 확인해 볼 수 있다.
BETWEEN ... AND 윈도우의 시작점과 끝점을 명시한다. AND 이전에 오는 것이 시작점, AND 이후에 오는 것이 끝점이다.
BETWEEN ... AND를 명시하지 않고 하나의 시점만 명시할 경우에는, 그 시점이 시작점이 되며 끝점은 현재 로우가 된다.
다음의 표는 Tibero에서 제공하는 분석 함수와 함수별 window_clause의 명시 가능 여부를 나타낸다.
| 분석 함수 | window_clause 명시 가능 여부 |
|---|---|
| AVG | 예 |
| CORR | 예 |
| COUNT | 예 |
| COVAR_POP | 예 |
| COVAR_SAMP | 예 |
| DENSE_RANK | 아니오 |
| FIRST | 아니오 |
| FIRST_VALUE | 예 |
| LAG | 아니오 |
| LAST | 아니오 |
| LAST_VALUE | 예 |
| LEAD | 아니오 |
| MAX | 예 |
| MIN | 예 |
| NTILE | 아니오 |
| PERCENT_RANK | 아니오 |
| PERCENTILE_CONT | 아니오 |
| PERCENTILE_DISC | 아니오 |
| RANK | 아니오 |
| RATIO_TO_REPORT | 아니오 |
| 예 | |
| ROW_NUMBER | 아니오 |
| STDDEV | 예 |
| STDDEV_POP | 예 |
| STDDEV_SAMP | 예 |
| SUM | 예 |
| VARIANCE | 예 |
| VAR_POP | 예 |
| VAR_SAMP | 예 |
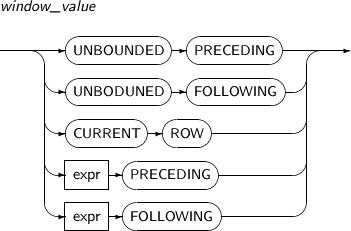
window_value
window_value의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 UNBOUNDED PRECEDING 시작점을 명시할 때 사용하며, 파티션의 첫 번째 로우를 지정한다. 끝점으로 사용할 수는 없다. UNBOUNDED FOLLOWING 끝점을 명시할 때 사용하며, 파티션의 맨 마지막 로우를 지정한다. 시작점으로 사용할 수는 없다. CURRENT ROW 시작점 또는 끝점으로 사용할 수 있으며, ROW 또는 RANGE를 명시했을 경우 현재 로우 또는 현재 로우에서 계산된 값을 의미한다.
시작점으로 명시했을 때는 끝점으로 expr PRECEDING을 사용할 수 없으며, 끝점으로 명시했을 경우는 시작점으로 expr FOLLOWING을 사용할 수 없다.
expr PRECEDING expr PRECEDING을 끝점에 명시했으면, 시작점은 항상 expr PRECEDING이 되어야 한다. expr FOLLOWING expr FOLLOWING을 시작점에 명시했으면, 끝점은 항상 expr FOLLOWING이 되어야 한다. 윈도우 타입별로 expr은 다음과 같이 달라진다.
-
윈도우 타입이 ROW일 경우에는 다음과 같다.
-
expr은 물리적인 오프셋을 지정한다. 이것은 양수이거나 양수로 계산되는 연산식이다.
-
시작점의 로우는 끝점의 로우보다 먼저 나와야 한다.
-
-
윈도우 타입이 RANGE일 경우에는 다음과 같다.
-
expr은 논리적인 오프셋을 지정한다. 이것은 0 또는 양수로 계산되는 연산식 또는 간격 리터럴이다. 간격 리터럴에 대해서는 “2.2. 리터럴”을 참고한다.
-
expr에 수치 값을 사용할 수 있는 경우는 order_by_clause의 expr의 데이터 타입이 NUMBER 또는 DATE 타입일 때이다.
-
expr에 간격 값을 사용할 수 있는 경우는 order_by_clause의 expr의 데이터 타입이 DATE 타입일 때이다.
-
-
본 절에서는 Tibero에서 제공하는 내장 함수에 대해 설명한다.
ABS는 주어진 파라미터 값의 절댓값(Absolute Value)을 구하는 함수이다.
ABS의 세부 내용은 다음과 같다.
-
문법
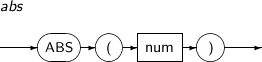
-
구성요소
구성요소 설명 num num은 수치 또는 수치 값으로 변환이 가능한 임의의 연산식이다. -
예제
다음은 ABS 함수를 사용하는 예이다.
SQL> SELECT ABS(15.5), ABS(-25.5) FROM DUAL; ABS(15.5) ABS(-25.5) ---------- ---------- 15.5 25.5 1 row selected.
ACOS는 num의 아크 코사인 값을 구하는 함수이다.
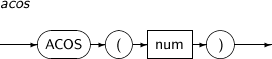
ACOS의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 num num은 -1~ 1 사이의 값을 가져야 한다.
반환값은 0 ~ pi 사이의 라디안(Radian)값이다.
num은 NUMBER 타입이거나 NUMBER 타입으로 변환될 수 있는 타입이어야 한다. 반환값의 타입은 NUMBER이다.
-
예제
다음은 ACOS 함수를 사용하는 예이다.
SQL> SELECT ACOS(.4) FROM DUAL; ACOS(.4) ---------- 1.15927948 1 row selected.
ADD_MONTHS는 date에 integer 만큼의 달을 더한 결과를 구하는 함수이다.
ADD_MONTHS의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 date date는 DATE 값을 반환하는 임의의 연산식이다. integer integer는 정수 값을 저장하는 데이터 타입이다. -
예제
다음은 ADD_MONTHS 함수를 사용하는 예이다.
SQL> SELECT ADD_MONTHS (DATE'2006-01-01', 1) FROM DUAL; ADD_MONTHS(DATE'2006-01-01',1) -------------------------------- 2006/02/01 1 row selected.
AGGR_CONCAT는 그룹 내의 모든 로우에 대해 문자열과 구분자를 접합하여 하나의 문자열로 만들어 반환하는 함수이다. NULL 값을 반환하는 로우는 결과로부터 제외된다.
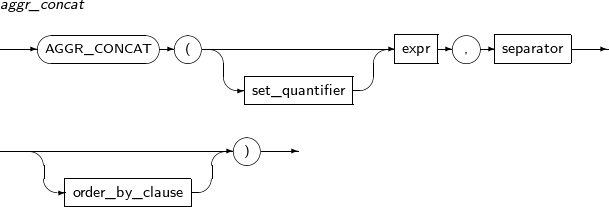
AGGR_CONCAT의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 set_quantifier 질의 결과에 중복된 로우의 허용, 비허용 여부를 지정한다.
다음 중에 하나를 지정할 수 있다.
-
DISTINCT, UNIQUE: 중복된 로우를 제거한다.
-
ALL: 모든 로우를 선택한다. (기본값)
expr 문자열이나 문자열로 변환될 수 있는 임의의 연산식이다. separator expr과 접합될 구분자를 나타내는 문자 리터럴이다. order_by_clause 접합할 문자열을 어떻게 정렬할지를 명시한다.
자세한 내용은 “4.1.3. 분석 함수”의 order_by_clause를 참고한다.
-
-
예제
다음은 AGGR_CONCAT 함수를 사용하는 예이다.
SQL> SELECT AGGR_CONCAT(NAME, ',') AS "EMPLOYEE" FROM EMP GROUP BY DEPT_ID; EMPLOYEE --------------------------------------------------------------------- Johnny Depp,Brad Pitt,Bruce Willis Will Smith,Nicolas Cage Jason Statham Angelina Jolie 4 rows selected.
APPENDCHILDXML은 XPath expression으로 지정된 노드에 사용자가 입력한 XML값을 이어붙이는 함수이다. 이미 존재하고 있는 노드들의 뒤부터 삽입된다.
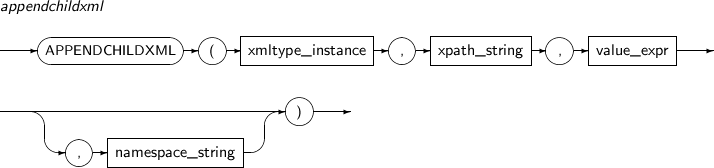
APPENDCHILDXML의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 XMLType_instance XML 타입 객체를 반환하는 임의의 연산식이다. XPath_string 하나 이상의 자식 노드가 삽입될 위치를 나타내는 XPath 연산식이다. value_expr 삽입될 하나 이상의 자식 노드를 나타내는 임의의 연산식이다. 이 연산식은 반드시 문자열로 변환 가능해야 한다. namespace_string XPath의 네임스페이스 정보를 나타낸다. 반드시 VARCHAR 타입이어야 한다. -
예제
다음은 APPENDCHILDXML 함수를 사용하는 예이다.
... INFO 컬럼 '<dept><id>1</id><id>2</id></dept>' ... SQL> UPDATE EMP SET INFO = APPENDCHILDXML(INFO, '/dept', XMLTYPE('<id>3</id>')); SQL> SELECT INFO FROM EMP; EMP ------------------------------------------- <dept><id>1</id><id>2</id><id>3</id></dept>
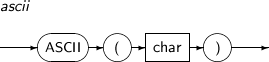
ASCII는 char의 첫 번째 문자에 대해서, 데이터베이스 문자 집합에서의 십진수 표시 값을 반환하는 함수이다. 만일 현재 데이터베이스의 문자 집합이 7bits ASCII라고 한다면, 이 함수는 ASCII 값을 반환한다. 만일 문자 집합이 EBCDIC이었다면, EBCDIC 값을 반환한다.
ASCII의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 char char는 CHAR, VARCAHR, NCHAR, NVARCHAR 타입 중 하나이다.
char이 CLOB 타입일 수는 없다. 하지만, 타입의 변환 함수를 통해 ASCII 함수를 호출할 수 있다.
-
예제
다음은 ASCII 함수를 사용하는 예이다.
SQL> SELECT ASCII('ABC') CODE FROM DUAL; CODE ---------- 65 1 row selected.
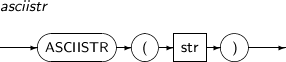
ASCIISTR은 주어진 문자열을 데이터베이스 문자 집합의 아스키 문자열로 반환한다. ASCII 이외의 문자는 \xxxx 형태로 변경된다. xxxx는 UTF-16 코드이다.
ASCIISTR의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다. -
예제
다음은 ASCII 함수를 사용하는 예이다. 데이터베이스 문자 집합은 'MSWIN949' 이다.
SQL> SELECT ASCIISTR('A한글B') FROM DUAL; ASCIISTR('A한글B') ------------------ A\D55C\AE00B 1 row selected.
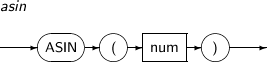
ASIN는 num의 아크 사인 값을 구하는 함수이다.
ASIN의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 num -1 ~ 1 사이의 값을 가져야 한다. 반환값은 -pil2 ~ pil2 사이의 라디안 값이다.
num은 NUMBER 타입이거나 NUMBER로 변환될 수 있는 타입이어야 한다.
반환값의 타입은 NUMBER이다.
-
예제
다음은 ASIN 함수를 사용하는 예이다.
SQL> SELECT ASIN(.4) FROM DUAL; ASIN(.4) ---------- .411516846 1 row selected.
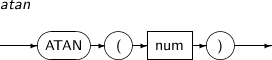
ATAN은 num의 아크 탄젠트 값을 구하는 함수이다.
ATAN의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 num num의 값은 제한이 없으며 반환값은 -pil2 ~ pil2 사이의 라디안 값이다.
num은 NUMBER 타입이거나 NUMBER 타입으로 변환될 수 있는 타입이어야 한다.
반환값의 타입은 NUMBER이다.
-
예제
다음은 ATAN 함수를 사용하는 예이다.
SQL> SELECT ATAN(.4) FROM DUAL; ATAN(.4) ---------- .380506377 1 row selected.
ATAN2는 아크 탄젠트 값을 구하는 함수이다. n과 m의 아크 탄젠트 값을 구한다. ATAN2(n, m)은 ATAN2(n/m)과 같다.
ATAN2의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 n, m n과 m은 NUMBER 타입이거나 NUMBER 타입으로 변환될 수 있는 타입이어야 한다.
반환값의 타입은 NUMBER이다.
n의 값은 제한이 없으며 반환값은 -pil2 ~ pil2 사이의 라디안 값이다.
-
예제
다음은 ATAN2 함수를 사용하는 예이다.
SQL> SELECT ATAN2(.3, .4) ATAN2 FROM DUAL; ATAN2 ---------- .643501109 1 row selected.
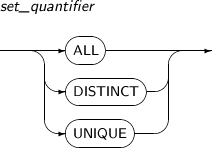
AVG는 그룹 내의 모든 로우에 대한 expr 값의 평균을 구하는 함수이다.
AVG의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 analytic_clause OVER analytic_clause를 사용해 함수를 분석 함수로 수행할 수 있다.
자세한 내용은 “4.1.3. 분석 함수”의 analytic_clause를 참고한다.
expr expr은 임의의 연산식이며, “3.3. 연산식”에서 이미 정의하였다. ALL ALL은 기본값이다. expr 값 중에서 중복되는 값을 제거하지 않고, 모든 값의 평균을 구한다. DISTINCT expr 앞에 DISTINCT 예약어를 포함시키면, 평균을 구하기 전에 expr 값 중에서 중복되는 값을 제거한다.
DISTINCT를 명시할 경우는 analytic_clause에서 query_partion_clause만 명시할 수 있다. order_by_clause는 명시할 수 없다.
oder_by_clause를 명시할 수 없으므로 window_clause 또한 명시할 수 없다.
UNIQUE UNIQUE는 DISTINCT와 동일하다. -
예제
다음은 AVG 함수를 사용하는 예이다.
SQL> SELECT AVG(SALARY) AVG FROM EMP GROUP BY DEPTNO; AVG ---------- 3255 1 row selected. -
분석 함수 예제
다음은 AVG 함수를 분석 함수로 사용하는 예이다.
SQL> SELECT ID, HIREDATE, SALARY, AVG(SALARY) OVER (ORDER BY HIREDATE ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS AAVG FROM EMP; ID HIREDATE SALARY AAVG ---------- ---------- ---------- ---------- 1 1987/01/06 20000 17500 5 1991/05/16 15000 14333.3333 4 1999/11/25 8000 9333.33333 2 2001/06/07 5000 6333.33333 8 2003/03/26 6000 6666.66667 6 2003/08/15 9000 6333.33333 7 2004/02/08 4000 6666.66667 3 2005/09/23 7000 5500 8 rows selected.
BITAND는 expr1과 expr2의 각 비트를 AND 연산한 결과를 구하는 함수이다.
BITAND의 세부 내용은 다음과 같다.
-
문법
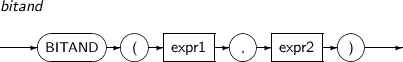
-
구성요소
구성요소 설명 expr1, expr2 expr1과 expr2는 정수 값을 반환하는 임의의 연산식이다. -
예제
다음은 BITAND 함수를 사용하는 예이다.
SQL> SELECT BITAND(3, 1), BITAND(4, 1) FROM DUAL; BITAND(3,1) BITAND(4,1) ----------- ----------- 1 0 1 row selected.
CAST는 하나의 데이터 타입에서 다른 데이터 타입으로 변경하는 함수이다.
CAST의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 문법 expr expr은 임의의 데이터 타입을 반환하는 임의의 연산식이다. typename typename은 변환할 데이터 타입의 이름을 명시한다. -
예제
다음은 CAST 함수를 사용하는 예이다.
SQL> SELECT CAST('1974-06-23' AS TIMESTAMP) TS FROM DUAL; TS -------------------------- 1974/06/23 00:00:00.000000 1 row selected.
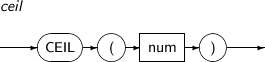
CEIL은 주어진 파라미터의 값보다 크거나 같은 가장 작은 정수를 구하는 함수이다.
CEIL의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 num num은 수치 값을 반환하는 임의의 연산식이다. -
예제
다음은 CEIL 함수를 사용하는 예이다.
SQL> SELECT CEIL(15.5), CEIL(-15.5), CEIL(25.0) FROM DUAL; CEIL(15.5) CEIL(-15.5) CEIL(25.0) ---------- ----------- ---------- 16 -15 25 1 row selected.
CHARTOROWID는 CHAR, VARCHAR, NCHAR, NVARCHAR 형식의 값을 ROWID 형식으로 변환하는 함수이다.
CHARTOROWID의 세부 내용은 다음과 같다.
-
문법
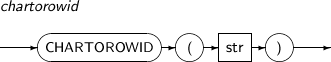
-
구성요소
구성요소 설명 str ROWID 형식으로 변환할 임의의 값이다. -
예제
다음은 CHARTOROWID 함수를 사용하는 예이다.
SQL> SELECT DEPT_ID FROM EMP WHERE ROWID = CHARTOROWID('AAAAUcAAAAAAAxPAAA'); DEPT_ID ------- 5 1 row selected.
CHR은 num에 대응하는 문자를 구하는 함수이다.
CHR의 세부 내용은 다음과 같다.
-
문법
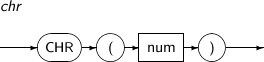
-
구성요소
구성요소 설명 num num은 수치 값을 반환하는 임의의 연산식이다. -
예제
다음은 CHR 함수를 사용하는 예이다.
SQL> SELECT CHR(68) || CHR(66) RSLT FROM DUAL; RSLT ---- DB 1 row selected.
COALESCE는 NULL이 아닌 첫 파라미터를 반환하는 함수이다. 모든 파라미터가 NULL 값을 갖는다면 NULL을 반환한다.
COALESCE의 세부 내용은 다음과 같다.
-
문법
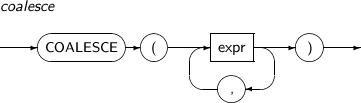
-
구성요소
구성요소 설명 expr expr은 다른 expr과 서로 동일하거나 호환할 수 있는 타입의 임의의 연산식이다. -
예제
다음은 COALESCE 함수를 사용하는 예이다.
SQL> SELECT COALESCE(NULL, 'A', 'B') FROM DUAL; COALESCE(NULL, 'A', 'B') ------------------------ A 1 row selected.
COMPOSE는 입력받은 문자열을 NFC 정규 형태의 유니코드 문자열로 변환하는 함수이다.
COMPOSE의 세부 내용은 다음과 같다.
-
문법
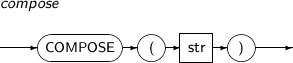
-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다. -
예제
다음은 COMPOSE 함수를 사용하는 예이다.
SQL> SELECT COMPOSE('o' || UNISTR('\0308')) FROM DUAL; COMPOSE('O'||UNISTR('\0308')) -------------------------------------------------------------------------------- ö 1 row selected.
CONCAT은 두 개의 문자열을 접합하여 하나의 문자열을 반환하는 함수이다. 접합 연산자(||)를 사용했을 때와 같은 결과를 얻는다. 두 파라미터 중에서 하나가 NULL이더라도 NULL을 반환하지는 않는다.
CONCAT의 세부 내용은 다음과 같다.
-
문법
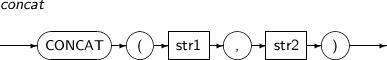
-
구성요소
구성요소 설명 str1, str2 str1과 str2는 문자열을 반환하는 임의의 연산식이다. -
예제
다음은 CONCAT 함수를 사용하는 예이다.
SQL> SELECT CONCAT('ABC', 'DEF') FROM DUAL; CONCAT('ABC', 'DEF') -------------------- ABCDEF 1 row selected.
CONVERT은 주어진 문자열을 다른 문자집합의 문자열로 변환한다. 대응하는 문자가 없다면 '?'로 대체된다.
CONVERT의 세부 내용은 다음과 같다.
-
문법
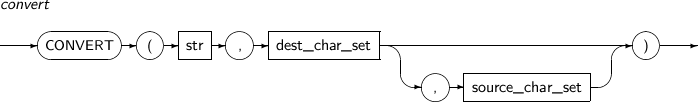
-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다. dest_char_set 변환하려는 문자 집합명을 명시한다.
-
데이터베이스 문자 집합명을 사용할 수 있다.
-
그 외에 ISO2022-KR, US8ICL 문자집합을 사용할 수 있다.
source_char_set str의 문자 집합명을 명시한다. 명시하지 않으면 데이터베이스 문자 집합명이 기본값으로 사용된다. -
-
예제
다음은 CONVERT 함수를 사용하는 예이다.
SQL> SELECT CONVERT('A한글B', 'US7ASCII', 'MSWIN949') FROM DUAL; CONVERT('A한글B','US7ASCII','MSWIN949') --------------------------------------- A??B 1 row selected.
CORR은 파라미터로 주어진 expr1가 expr2의 상관계수를 계산하는 함수이다. 분석 함수로도 사용할 수 있다. 이 함수는 모든 수치 데이터 타입과 수치 데이터 타입은 아니지만 묵시적으로 수치 데이터 타입으로 변환할 수 있는 데이터 타입을 파라미터로 받아 들인다. 입력된 파라미터의 수치 데이터 타입 또는 변환된 수치 데이터 타입을 반환한다.
Tibero에서는 다음의 공식을 사용해 상관계수를 계산한다.
COVAR_POP(expr1, expr2) / (STDDEV_POP(expr1) * STDDEV_POP(expr2))
CORR의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr1, expr2 expr1과 expr2는 수치 데이터 타입의 값을 반환하는 임의의 연산식이다. OVER analytic_clause OVER analytic_clause를 사용해 함수를 분석 함수로 수행할 수 있다.
자세한 내용은 “4.1.3. 분석 함수”의 analytic_clause를 참고한다.
-
예제
다음은 CORR 함수를 사용하는 예이다.
SQL> SELECT CORR(AGE, SAL) FROM EMP; CORR(AGE,SAL) ------------- -.21144410174 1 row selected.
-
분석 함수 예제
다음은 CORR 함수를 분석 함수로 사용하는 예이다.
SQL> SELECT DEPTNO, EMPNO, CORR(SAL, AGE) OVER (PARTITION BY DEPTNO) AS CORR FROM EMP; DEPTNO EMPNO CORR ---------- ---------- ---------- 10 7934 -.93645032 10 7839 -.93645032 10 7782 -.93645032 20 7566 .567780056 20 7788 .567780056 20 7876 .567780056 20 7902 .567780056 20 7369 .567780056 30 7654 -.33417865 30 7698 -.33417865 30 7521 -.33417865 30 7499 -.33417865 30 7844 -.33417865 30 7900 -.33417865 14 rows selected.
COS는 주어진 파라미터 값의 코사인(Cosine)값을 구하는 함수이다.
COS의 세부 내용은 다음과 같다.
-
문법
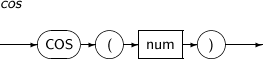
-
구성요소
구성요소 설명 num num은 실수 값을 반환하는 임의의 연산식이다. (단위: 라디안) -
예제
다음은 COS 함수를 사용하는 예이다.
SQL> SELECT COS(360 * 3.14159265359/180) FROM DUAL; COS(360 * 3.14159265359/180) ---------------------------- 1 1 row selected.
COSH는 주어진 파라미터 값의 하이퍼볼릭 코사인(Hyperbolic Cosine) 값을 구하는 함수이다.
COSH의 세부 내용은 다음과 같다.
-
문법
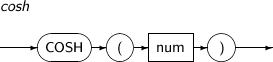
-
구성요소
구성요소 설명 num num은 실수 값을 반환하는 임의의 연산식이다. (단위: 라디안) -
예제
다음은 COSH 함수를 사용하는 예이다.
SQL> SELECT COSH(0) FROM DUAL; COSH(0) ---------- 1 1 row selected.
COUNT는 쿼리가 반환하는 로우의 개수를 세는 함수이다. 분석 함수로도 사용할 수 있다. COUNT 함수는 항상 숫자를 반환하고 NULL을 반환하는 경우는 없다.
COUNT의 세부 내용은 다음과 같다.
-
문법
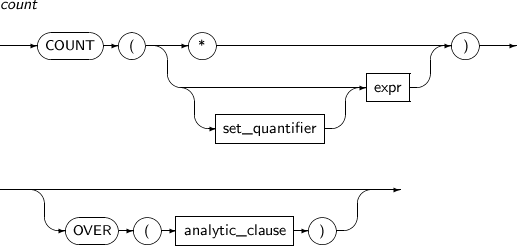
-
구성요소
구성요소 설명 set_quantifier 질의 결과에 중복된 로우의 허용, 비허용 여부를 지정한다. DISTINCT, UNIQUE, ALL을 지정할 수 있다.
-
DISTINCT, UNIQUE: 중복된 로우를 제거한다.
-
ALL: 모든 로우를 선택한다. (기본값)
* 애스터리스크(*)를 명시하면 중복된 로우와 그리고 NULL값을 포함한 모든 로우를 개수에 포함시킨다. expr expr을 명시할 경우는, COUNT 함수는 expr의 값이 NULL이 아닐 경우에만 로우를 개수에 포함시킨다.
DISTINCT를 명시함으로써 expr의 값을 구했을 때 중복을 제거한 로우만 셀 수 있다.
analytic_clause OVER analytic_clause를 사용해 함수를 분석 함수로 수행할 수 있다.
자세한 내용은 “4.1.3. 분석 함수”의 analytic_clause를 참고한다.
-
-
예제
다음은 COUNT 함수를 사용하는 예이다.
SQL> SELECT COUNT (*) FROM EMP; COUNT(*) ---------- 9 1 row selected. -
분석 함수 예제
다음은 COUNT 함수를 분석 함수로 사용하는 예이다.
SQL> SELECT NAME, SALARY, COUNT(*) OVER (ORDER BY SALARY RANGE BETWEEN 1000 PRECEDING AND 1000 FOLLOWING) AS W_COUNT FROM EMP; NAME SALARY W_COUNT -------------------- ---------- ---------- Paul 2000 4 Tom 2500 5 Jill 3000 6 Susan 3000 6 Matt 3200 5 Coon 4000 5 Josh 4500 2 Cathy 6000 2 Brad 6200 2 9 rows selected.
COVAR_POP는 expr1, expr2의 모공분산을 계산하는 함수이다. 분석 함수로도 사용할 수 있다.
이 함수는 모든 수치 데이터 타입과 수치 데이터 타입은 아니지만 묵시적으로 수치 데이터 타입으로 변환할 수 있는 데이터 타입을 파라미터로 받아 들인다. NUMBER 타입을 반환한다.
Tibero에서는 다음의 공식을 사용해 모공분산을 계산한다.
(SUM(expr1 * expr2) - SUM(expr2) * SUM(expr1) / n) / n
여기서 n은 expr1과 expr2 둘 모두가 NULL이 아닌 로우의 개수이다.
COVAR_POP의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr1, expr2 expr1과 expr2는 수치 데이터 타입의 값을 반환하는 임의의 연산식이다. OVER analytic_clause OVER analytic_clause를 사용해 함수를 분석 함수로 수행할 수 있다.
자세한 내용은 “4.1.3. 분석 함수”의 analytic_clause를 참고한다.
-
예제
다음은 COVAR_POP 함수를 사용하는 예이다.
SQL> SELECT COVAR_POP(AGE, SAL) AS COVAR_POP FROM EMP; COVAR_POP ---------- -642.09184 1 row selected.
-
분석 함수 예제
다음은 COVAR_POP 함수를 분석 함수로 사용하는 예이다.
SQL> SELECT DEPTNO, EMPNO, COVAR_POP(AGE, SAL) OVER (PARTITION BY DEPTNO) AS COVAR_POP FROM EMP; DEPTNO EMPNO COVAR_POP ---------- ---------- ---------- 10 7934 -4777.7778 10 7839 -4777.7778 10 7782 -4777.7778 20 7566 1470 20 7788 1470 20 7876 1470 20 7902 1470 20 7369 1470 30 7654 -480.55556 30 7698 -480.55556 30 7521 -480.55556 30 7499 -480.55556 30 7844 -480.55556 30 7900 -480.55556 14 rows selected.
COVAR_SAMP는 expr1, expr2의 표본공분산을 계산하는 함수이다. 분석 함수로도 사용할 수 있다.
이 함수는 모든 수치 데이터 타입과 수치 데이터 타입은 아니지만 묵시적으로 수치 데이터 타입으로 변환할 수 있는 데이터 타입을 파라미터로 받아 들인다. NUMBER 타입을 반환한다.
Tibero에서는 다음의 공식을 사용해 표본공분산을 계산한다.
(SUM(expr1 * expr2) - SUM(expr1) * SUM(expr2) / n) / (n-1)
여기서 n은 expr1, expr2 모두 NULL이 아닌 로우의 개수이다.
COVAR_SAMP의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr1, expr2 expr1과 expr2는 수치 데이터 타입의 값을 반환하는 임의의 연산식이다. OVER analytic_clause OVER analytic_clause를 사용해 함수를 분석 함수로 수행할 수 있다.
자세한 내용은 “4.1.3. 분석 함수”의 analytic_clause를 참고한다.
-
예제
다음은 COVAR_SAMP 함수를 사용하는 예이다.
SQL> SELECT COVAR_SAMP(AGE, SAL) AS COVAR_SAMP FROM EMP; COVAR_SAMP ---------- -691.48352 1 row selected.
-
분석 함수 예제
다음은 COVAR_SAMP 함수를 분석 함수로 사용하는 예이다.
SQL> SELECT DEPTNO, EMPNO, COVAR_SAMP(AGE, SAL) OVER (PARTITION BY DEPTNO) AS COVAR_SAMP FROM EMP; DEPTNO EMPNO COVAR_SAMP ---------- ---------- ---------- 10 7934 -7166.6667 10 7839 -7166.6667 10 7782 -7166.6667 20 7566 1837.5 20 7788 1837.5 20 7876 1837.5 20 7902 1837.5 20 7369 1837.5 30 7654 -576.66667 30 7698 -576.66667 30 7521 -576.66667 30 7499 -576.66667 30 7844 -576.66667 30 7900 -576.66667 14 rows selected.
CUME_DIST는 그룹 내의 누적 분포를 계산하는 함수이다. 반환값은 NUMBER 타입이며 0 보다 크고 1 보다 작거나 같은 값을 가진다.
누적 분포를 계산하는 방법은 그룹의 로우를 정렬 스펙으로 정렬한 뒤 파라미터로 주어진 값을 갖는 가상의 로우를 삽입한 위치를 계산하여 그룹의 로우 개수로 나누는 것이다.
CUME_DIST의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr expr은 한 그룹 안에서는 상수 값이어야 하며, order_by_clasuse의 표현식과 대응되어야 한다. order_by_clause 분할된 하나의 파티션 내에서 로우를 어떻게 정렬할지를 명시한다.
자세한 내용은 “4.1.3. 분석 함수”의 order_by_clause를 참고한다.
-
예제
다음은 CUME_DIST 함수를 사용하는 예이다.
SQL> SELECT CUME_DIST(1000, '1981/01/01') WITHIN GROUP (ORDER BY SAL, HIREDATE) AS "CUME_DIST" FROM EMP; CUME_DIST ---------- .2 1 row selected.
CURRENT_DATE는 현재 세션의 시간대를 기준으로 현재 날짜를 그레고리력으로 출력하는 함수이다.
CURRENT_DATE의 세부 내용은 다음과 같다.
-
문법

-
예제
다음은 CURRENT_DATE 함수를 사용하는 예이다.
SQL> SELECT CURRENT_DATE FROM DUAL; CURRENT_DATE ----------------------------------------------------- 2005/12/04 1 row selected.
CURRENT_TIME은 현재 세션의 시간대를 기준으로 현재 시간을 출력하는 함수이다.
CURRENT_TIME의 세부 내용은 다음과 같다.
-
문법

-
예제
다음은 CURRENT_TIME 함수를 사용하는 예이다.
SQL> SELECT CURRENT_TIME FROM DUAL; CURRENT_TIME -------------------------------- 20:23:18.383578 1 row selected.
CURRENT_TIMESTAMP는 현재 세션의 시간대를 기준으로 현재 날짜 및 시간을 출력하는 함수이다. 이 함수의 반환값은 TIMESTAMP WITH TIME ZONE 타입이다.
CURRENT_TIMESTAMP의 세부 내용은 다음과 같다.
-
문법
-
예제
다음은 CURRENT_TIMESTAMP 함수를 사용하는 예이다.
SQL> SELECT CURRENT_TIMESTAMP FROM DUAL; CURRENT_TIMESTAMP --------------------------------------------- 2005/12/04 20:22:26.391220 Asia/Seoul 1 row selected.
DBTIMEZONE는 데이터베이스의 시간대 정보를 오프셋([+|-]TZH:TZM) 형식이나 지역이름(TZR) 형식으로 반환하는 함수이다. Tibero에서는 항상 UTC를 반환한다.
DBTIMEZONE의 세부 내용은 다음과 같다.
-
문법
-
예제
다음은 DBTIMEZONE 함수를 사용하는 예이다.
SQL> SELECT DBTIMEZONE FROM DUAL; DBTIMEZONE ------------------------------------- UTC 1 row selected.
DECODE는 각 search를 비교하여, 같은 값을 가지는 search에 대응하는 result 값을 구하는 함수이다. 수치, 문자 데이터 타입 모두 파라미터로 사용할 수 있다. expr, search, result 그리고 default를 합해서 최대 255까지의 표현식을 사용할 수 있다.
DECODE의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr search와 데이터 타입이 동일하거나 암묵적 변환을 통해 동일한 타입으로 변환이 가능해야 한다. search expr에 대응되는 조건값이다.
모든 search의 타입은 첫 번째 search의 타입과 동일하거나 데이터 타입의 암묵적 변환이 가능해야 한다.
result search와 일치하는 경우 반환할 값이다.
모든 result의 타입은 첫 번째 result의 타입과 동일하거나 데이터 타입의 암묵적 변환이 가능해야 한다.
default 같은 값을 갖는 search가 없을 때 default에 명시된 값을 반환한다.
default의 값이 명시되지 않은 경우 NULL을 반환한다.
default의 타입은 첫 번째 result의 타입과 동일하거나 데이터 타입의 암묵적 변환이 가능해야 한다.
-
예제
다음은 DECODE 함수를 사용하는 예이다.
SQL> SELECT DECODE('1', 1, 'Male', 2, 'Female') FROM DUAL; DECODE('1',1,'MALE',2,'FEMALE') ------------------------------- Male 1 row selected.
DECOMPOSE는 입력받은 유니코드 문자열을 분해(decomposition)한 문자열을 반환하는 함수이다.
DECOMPOSE의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다. CANONICAL COMPOSE 함수를 통해 원본 문자열을 복원할 수 있는 정규 분해를 한다. COMPATIBILITY 호환 모드를 분해한다. 이 모드에서는 COMPOSE 함수를 통해 복원할 수 없다. -
예제
다음은 DECOMPOSE 함수를 사용하는 예이다.
SQL> SELECT DECOMPOSE('Châteaux') FROM DUAL; DECOMPOSE('Châteaux') ------------------------------------------------------------- Cha^teaux 1 row selected.
DELETEXML은 XPath expression으로 지정된 노드를 XML에서 제거하는 함수이다.
DELETEXML의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 xmltype_instance XMLType instance다. xpath_string Xpath expression으로 지우려는 XML Element의 위치를 나타낸다. namespace_string XPath_string의 네임스페이스 정보를 나타낸다. VARCHAR Type이어야 한다. -
예제
다음은 DELETEXML 함수를 사용하는 예이다.
SQL> UPDATE warehouses SET warehouse_spec = DELETEXML(warehouse_spec, '/Warehouse/Building/Owner') WHERE warehouse_id = 2; SQL> SELECT warehouse_id, warehouse_spec FROM warehouses WHERE warehouse_id in (2,3); ID WAREHOUSE_SPEC ---------- ----------------------------------- 2 <Warehouse> <Building>Rented</Building> <Area>50000</Area> <Docks>1</Docks> <DockType>Side load</DockType> <WaterAccess>Y</WaterAccess> <RailAccess>N</RailAccess> <Parking>Lot</Parking> <VClearance>12 ft</VClearance> </Warehouse> 3 <Warehouse> <Building>Rented <Owner>Grandco</Owner> <Owner>ThirdOwner</Owner> <Owner>LesserCo</Owner> </Building> <Area>85700</Area> <DockType/> <WaterAccess>N</WaterAccess> <RailAccess>N</RailAccess> <Parking>Street</Parking> <VClearance>11.5 ft</VClearance> </Warehouse>
DENSE_RANK는 각 그룹별로 로우를 정렬한 다음 그룹 내의 각 로우에 대한 순위를 반환하는 함수이다. 분석 함수로도 사용할 수 있다.
반환된 순위는 다음과 같은 특징이 있다.
-
데이터 타입은 NUMBER이다.
-
1부터 시작하는 연속적인 정수 값이다.
-
최댓값은 중복되는 값을 하나로 계산했을 때 전체 로우의 개수가 된다.
-
중복된 값이 나타났을 때 다음 순위의 값은 건너뛰지 않고 1이 증가한 값이 부여된다. 중복된 값은 모두 같은 순위의 값이 부여된다.
계산 방법은 다음과 같이 함수에 따라 달라진다.
| 함수 | 설명 |
|---|---|
| 집계 함수 | 파라미터 값으로 구성된 가상의 로우에 대한 순위 값을 계산하다. 파라미터는 각 그룹마다 상수 값을 가져야 하며 order_by_clause의 표현식과 대응되어야 한다. |
| 분석 함수 | 각 로우의 그룹 내 순위를 반환한다. 순위는 order_by_clause 내의 expr 값을 기준으로 정렬한 결과가 부여된다. |
DENSE_RANK의 세부 내용은 다음과 같다.
-
문법


-
구성요소
-
dense_rank_aggregation
구성요소 설명 expr 임의의 연산식이다. order_by_clause 분할된 하나의 파티션 내에서 로우를 어떻게 정렬할지를 명시한다.
자세한 내용은 “4.1.3. 분석 함수”의 order_by_clause를 참고한다.
-
dense_rank_analytic
구성요소 설명 partition_by 현재 질의 블록의 결과 집합을 expr 또는 expr의 리스트를 기준으로 분할한다.
자세한 내용은 “4.1.3. 분석 함수”의 partition_by를 참고한다.
order_by_clause 분할된 하나의 파티션 내에서 로우를 어떻게 정렬할지를 명시한다.
자세한 내용은 “4.1.3. 분석 함수”의 order_by_clause를 참고한다.
-
-
예제
다음은 DENSE_RANK 함수를 사용하는 예이다.
SQL> SELECT DEPTNO, DENSE_RANK(3000) WITHIN GROUP (ORDER BY SAL) AS DENSE_RANK FROM EMP GROUP BY DEPTNO; DEPTNO DENSE_RANK ---------- ---------- 10 3 20 4 30 6 3 rows selected. -
분석 함수 예제
다음은 DENSE_RANK 함수를 분석 함수로 사용하는 예이다.
SQL> SELECT NAME, DEPTID, SALARY, DENSE_RANK() OVER (PARTITION BY DEPTID ORDER BY SALARY) FROM EMP; NAME DEPTID SALARY DENSE_RANK -------------------- ---------- ---------- ---------- Paul 1 3000 1 Angela 1 3000 1 Nick 1 3200 2 Scott 1 4000 3 James 1 4000 3 John 1 4500 4 Joe 2 4000 1 Brad 2 4200 2 Daniel 2 5000 3 Tom 2 5000 3 Kathy 2 5000 3 Bree 2 6000 4 12 rows selected.
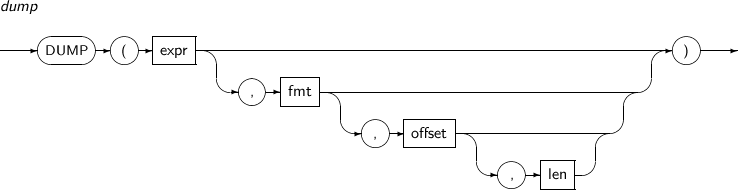
DUMP는 함수는 파라미터로 주어진 expr의 내부의 표현 정보를 반환하는 함수이다. 반환되는 값은 바이트 스트림과 길이 정보이며 VARCHAR2 타입이다. 단, LONG, CLOB, BLOB 타입에는 이 함수를 적용할 수 없다.
DUMP의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 expr 임의의 연산식이다. fmt 바이트 스트림의 형식을 지정한다. fmt는 다음의 값을 가질 수 있다.
-
8: 8진법 표현
-
10: 10진법 표현(기본값)
-
16: 16진법 표현
-
17: 문자 표현
offset 시작 오프셋을 나타낸다. len 표시할 byte의 길이를 지정한다.
expr의 값이 NULL이면 NULL을 출력한다.
-
-
예제
다음은 DUMP 함수를 사용하는 예이다.
SQL> SELECT DUMP(100) FROM DUAL; DUMP(100) ---------------- Len=2: 302,201 1 row selected.
EMPTY_BLOB은 BLOB 타입의 컬럼을 초기화하기 위해 빈 LOB Locator를 반환하는 함수이다.
EMPTY_BLOB의 세부 내용은 다음과 같다.
-
문법
-
예제
다음은 EMPTY_BLOB 함수를 사용하는 예이다.
SQL> UPDATE EMP SET PHOTO = EMPTY_BLOB();
EMPTY_CLOB은 CLOB 타입의 컬럼을 초기화하기 위해 비어 있는 LOB Locator를 반환하는 함수이다.
EMPTY_CLOB의 세부 내용은 다음과 같다.
-
문법
-
예제
다음은 EMPTY_CLOB 함수를 사용하는 예이다.
SQL> UPDATE NOVEL SET CONTENTS = EMPTY_CLOB();
EXISTSNODE는 XML 문서에서 질의한 XPath에 해당 노드가 있는지 검사하는 함수이다. 반환되는 값은 NUMBER 타입이며, 해당 노드가 있으면 1을 없으면 0을 반환한다.
EXISTSNODE의 세부 내용은 다음과 같다.
-
문법
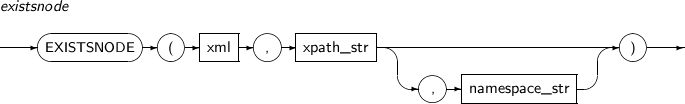
-
구성요소
구성요소 설명 xml 질의의 대상이 되는 XML 문서로, XMLType이다. xpath_str 질의할 XPath 문자열로, 최대 길이는 4000자이다. namespace_str XML 문서에서 네임스페이스 정보가 필요할 때 사용하는 옵션으로 VARCHAR 타입이다.
-
예제
다음은 EXISTSNODE 함수를 사용하는 예이다.
SQL> SELECT EXTRACT(employee_xmldoc, '/employee/department/dname') dname FROM employee_xml WHERE EXISTSNODE(employee_xmldoc, '/employee/department/dname') = 1; dname ---------- <dname>DB Lab</dname> 1 row selected.
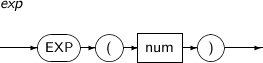
EXP는 자연 로그(Natural Log)의 밑(Base) e(= 2.7182818284…)의 주어진 파라미터의 제곱 값을 구하는 함수이다.
EXP의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 num 수치 값을 반환하는 임의의 연산식이다.
-
예제
다음은 EXP 함수를 사용하는 예이다.
SQL> SELECT EXP(2.0) FROM DUAL; EXP(2.0) ---------- 7.3890561 1 row selected.
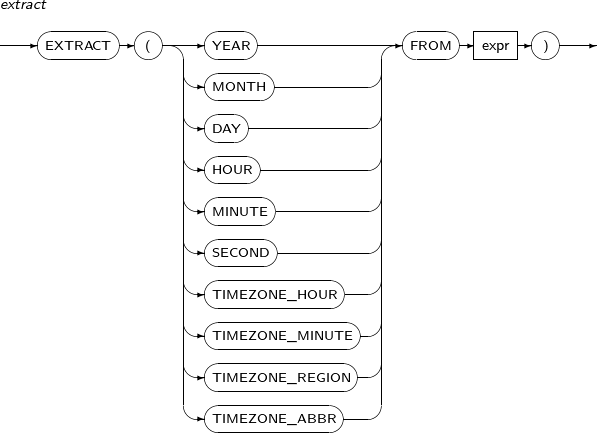
EXTRACT는 일시(날짜형) 또는 시간 간격(Interval) 값에서 특정 부분의 값을 추출하고 싶을 때 사용하는 함수이다. 반환되는 값은 그레고리력을 따른다. 값을 추출할 때는 추출할 값이 원래의 연산식에 존재해야만 한다.
EXTRACT의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 YEAR 연도를 저장하는 날짜형 데이터 타입이다. MONTH 달을 저장하는 날짜형 데이터 타입이다. DAY 날짜를 저장하는 데이터 타입이다. HOUR 시를 저장하는 데이터 타입이다. MINUTE 분을 저장하는 데이터 타입이다. SECOND 초를 저장하는 데이터 타입이다. TIMEZONE_HOUR 시간대 오프셋 시를 저장하는 데이터 타입이다. TIMEZONE_MINUTE 시간대 오프셋 분을 저장하는 데이터 타입이다. TIMEZONE_REGION 시간대 지역이름을 저장하는 데이터 타입이다. TIMEZONE_ABBR 시간대 일광 절약시간 약어를 저장하는 데이터 타입이다.
-
예제
다음은 EXTRACT 함수를 사용하는 예이다.
SQL> SELECT EXTRACT (MONTH FROM DATE'1996-04-01') FROM DUAL; EXTRACT(MONTHFROMDATE'1996-04-01') ---------------------------------- 4 1 row selected.
EXTRACT(XML)는 XML 문서에서 XPath를 이용하여 해당 XML의 노드를 반환하는 함수이다.
EXTRACT(XML)의 세부 내용은 다음과 같다.
-
문법
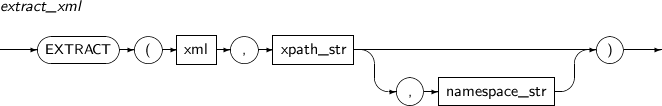
-
구성요소
구성요소 설명 xml 질의의 대상이 되는 XML 문서로, XMLType이다. xpath_str 질의할 XPath 문자열로, 최대 길이는 4000자이다. namespace_str XML 문서에서 네임스페이스 정보가 필요할 때 사용하는 옵션으로 VARCHAR 타입이다.
-
예제
다음은 EXTRACT(XML) 함수를 사용하는 예이다.
SQL> SELECT EXTRACT(employee_xmldoc, '/employee/department/dname') dname FROM employee_xml; dname --------------------- <dname>DB Lab</dname> 1 row selected.
EXTRACTVALUE는 XML 문서에서 XPath를 이용하여 해당 값을 VARCHAR 타입으로 반환하는 함수이다.
EXTRACTVALUE의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 xml 질의의 대상이 되는 XML 문서로, XMLType이다. xpath_str 질의할 XPath 문자열로, 최대 길이는 4000자이다. namespace_str XML 문서에서 네임스페이스 정보가 필요할 때 사용하는 옵션으로 VARCHAR 타입이다.
-
예제
다음은 EXTRACTVALUE 함수를 사용하는 예이다.
SQL> SELECT EXTRACTVALUE(employee_xmldoc, '/employee/department/dname') dname FROM employee_xml; dname ------ DB Lab 1 row selected.
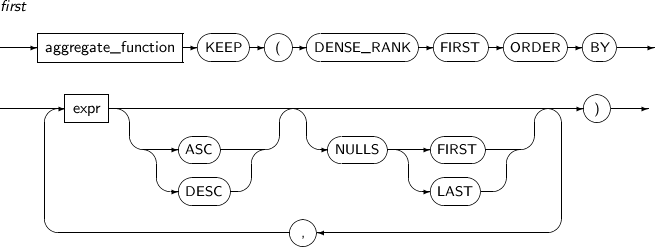
FIRST는 정렬된 로우에서 처음에 해당하는 로우를 뽑아내어 명시된 집단함수를 적용한 결과를 반환한다. 현재 분석 함수는 지원하지 않는다.
FIRST 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 aggregate_function 사용가능한 집단 함수는 AVG, COUNT, MIN, MAX, SUM, STADDEV 그리고 VARIANCE이다. expr 임의의 연산식이다.
-
예제
다음은 FIRST 함수를 사용하는 예이다.
SQL> SELECT MIN(COMM) KEEP (DENSE_RANK FIRST ORDER BY SAL), MAX(COMM) KEEP (DENSE_RANK FIRST ORDER BY SAL) FROM EMP WHERE JOB = 'SALESMAN'; MIN(COMM)KEEP(DENSE_RANKFIRSTORDERBYSAL) MAX(COMM)KEEP(DENSE_RANKFIRSTORDERBYSAL) ---------------------------------------- ---------------------------------------- 500 1400 1 row selected.
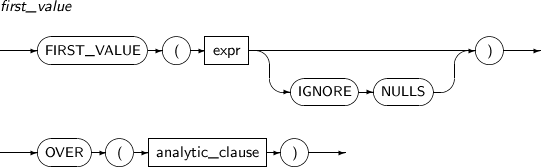
FIRST_VALUE는 정렬된 로우에서 첫 번째 값을 반환하는 분석함수이다. IGNORE NULLS를 명시하면 NULL이 아닌 첫 번째 값을 반환한다. 만약 모든 값이 NULL이라면 NULL을 반환한다.
FIRST_VALUE 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 expr 임의의 연산식이다.
-
예제
다음은 FIRST_VALUE 함수를 사용하는 예이다.
SELECT DEPTNO, ENAME, SAL, FIRST_VALUE(ENAME) OVER (PARTITION BY DEPTNO ORDER BY SAL ASC ROWS UNBOUNDED PRECEDING) AS LOWEST_SAL FROM EMP; DEPTNO ENAME SAL LOWEST_SAL ---------- ---------- ---------- ---------- 10 MILLER 1300 MILLER 10 CLARK 2450 MILLER 10 KING 5000 MILLER 20 SMITH 800 SMITH 20 ADAMS 1100 SMITH 20 JONES 2975 SMITH 20 SCOTT 3000 SMITH 20 FORD 3000 SMITH 30 JAMES 950 JAMES 30 WARD 1250 JAMES 30 MARTIN 1250 JAMES 30 TURNER 1500 JAMES 30 ALLEN 1600 JAMES 30 BLAKE 2850 JAMES 14 rows selected.
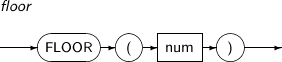
FLOOR는 주어진 파라미터의 값보다 작거나 같은 가장 큰 정수를 구하는 함수이다.
FLOOR의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 num 수치 값을 반환하는 임의의 연산식이다.
-
예제
다음은 FLOOR 함수를 사용하는 예이다.
SQL> SELECT FLOOR(15.5), FLOOR(-15.5), FLOOR(25.0) FROM DUAL; FLOOR(15.5) FLOOR(-15.5) FLOOR(25.0) ----------- ------------ ----------- 15 -16 25 1 row selected.
FROM_TZ는 주어진 TIMESTAMP 값과 시간대를 이용하여 TIMESTAMP WITH TIME ZONE 값으로 바꿔주는 함수이다.
FROM_TZ의 세부 내용은 다음과 같다.
-
문법
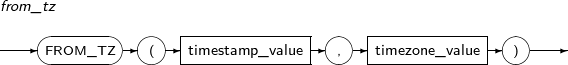
-
구성요소
구성요소 설명 timestamp_value 시간값을 반환하는 임의의 연산식이다. timezone_value 시간대 지역이름이나 오프셋을 반환하는 임의의 연산식이다.
-
예제
다음은 FROM_TZ 함수를 사용하는 예이다.
SQL> SELECT FROM_TZ(TIMESTAMP '2002/01/24 08:48:53', '8:00') FROM DUAL; FROM_TZ(TIMESTAMP'2002/01/2408:48:53','8:00') --------------------------------------------- 2002/01/24 08:48:53.000000 +08:00 1 row selected.
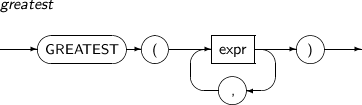
GREATEST는 파라미터 중 가장 큰 값을 구하는 함수이다.
GREATEST의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 expr 임의의 연산식이다. 처음 expr의 타입이 함수의 반환 타입이 된다.
두 번째 expr부터는 처음 expr과 동일한 타입 또는 암묵적 변환이 가능한 타입이어야 한다.
expr 중 하나의 값이 NULL이면 함수는 NULL을 반환한다.
-
예제
다음은 GREATEST 함수를 사용하는 예이다.
SQL> SELECT GREATEST(1, 3, 2) FROM DUAL; GREATEST(1,3,2) --------------- 3 1 row selected.
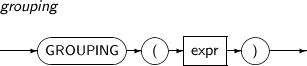
GROUPING은 Superaggreagate 로우와 Regular grouped 로우를 구분하기 위하여 사용하는 함수이다. ROLLUP과 CUBE는 Superaggreagate 로우를 생성하는데, 이 때 모든 값의 집합은 NULL로 표현된다. GROUPING 함수를 사용하면 로우의 컬럼 값 NULL과 Superaggreagate 로우에서 모든 값의 집합을 나타내기 위한 값 NULL을 구분할 수 있다. expr의 값이 모든 값의 집합을 나타낸다. NULL일 경우에는 1을 반환하고, 그렇지 않을 경우에는 0을 반환한다. 반환된 값은 NUMBER 타입이다.
GROUPING의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 expr GROUP BY 절에 명시된 expr 중의 하나와 대응하여야 한다.
-
예제
다음은 GROUPING 함수를 사용하는 예이다.
SQL> SELECT DECODE(GROUPING(DNO),1,'ALL',DNO) AS DNO, DECODE(GROUPING(JOB),1,'ALL',JOB) AS JOB, SUM(PAY) AS PAY FROM PERSONNEL GROUP BY CUBE(DNO, JOB) ORDER BY DNO, JOB; DNO JOB PAY ---------- -------------------- ---------- 10 ANALYST 5950 10 MANAGER 1000 10 PRESIDENT 7000 10 ALL 13950 20 CLERK 4000 20 MANAGER 3974 20 ALL 7974 30 MANAGER 3550 30 SALESMAN 4250 30 ALL 7800 ALL ANALYST 5950 ALL CLERK 4000 ALL MANAGER 8524 ALL PRESIDENT 7000 ALL SALESMAN 4250 ALL ALL 29724 16 rows selected.
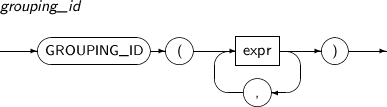
GROUPING_ID는 로우의 GROUPING 비트 벡터(Bit Vector)에 해당하는 NUMBER를 반환하는 함수이다.
GROUPING_ID는 여러 GROUPING 함수의 결과를 비트 벡터로 통합하는 것과 같다. GROUPING_ID 함수를 사용하면 다수의 GROUPING 함수를 사용하는 것을 피할 수 있으며, 로우 필터링의 조건을 보다 쉽게 표현할 수 있다. GROUPING_ID를 이용한 로우 필터링은 GROUPING_ID = n과 같은 조건으로 간단히 처리할 수 있다.
GROUPING_ID는 GROUPING 함수와, ROLLUP 또는 CUBE가 사용된 SELECT 문에서만 사용할 수 있다. GROUP BY가 여러 번 사용된 질의의 경우 특정 로우의 GROUP BY 수준을 결정하기 위해서는 GROUPING 함수를 여러 번 사용해야 하는데, 이는 복잡한 SQL 문장을 생성하게 된다. GROUPING_ID는 이러한 경우에 유용하다.
GROUPING_ID의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 expr GROUP BY clause에 명시된 expr 중의 하나와 대응하여야 한다.
-
예제
다음은 GROUPING_ID 함수를 사용하는 예이다.
SQL> SELECT DECODE(GROUPING(DNO),1,'ALL',DNO) AS DNO, DECODE(GROUPING(JOB),1,'ALL',JOB) AS JOB, GROUPING(DNO) AS GD, GROUPING(JOB) AS GJ, GROUPING_ID(DNO, JOB) AS DJ, GROUPING_ID(DNO, JOB) AS JD, SUM(PAY) AS PAY FROM PERSONNEL GROUP BY CUBE(DNO, JOB) ORDER BY DNO, JOB; DNO JOB GD GJ DJ JD PAY ---------- -------------------- ---- ---- ---- ---- ---------- 10 ANALYST 0 0 0 0 5950 10 MANAGER 0 0 0 0 1000 10 PRESIDENT 0 0 0 0 7000 10 ALL 0 1 1 2 13950 20 CLERK 0 0 0 0 4000 20 MANAGER 0 0 0 0 3974 20 ALL 0 1 1 2 7974 30 MANAGER 0 0 0 0 3550 30 SALESMAN 0 0 0 0 4250 30 ALL 0 1 1 2 7800 ALL ANALYST 1 0 2 1 5950 ALL CLERK 1 0 2 1 4000 ALL MANAGER 1 0 2 1 8524 ALL PRESIDENT 1 0 2 1 7000 ALL SALESMAN 1 0 2 1 4250 ALL ALL 1 1 3 3 29724 16 rows selected.
GROUP_ID는 GROUP BY의 결과에서 중복된 그룹을 구분하는 함수이다. 이는 쿼리 결과에서 중복된 그룹을 걸러내는 데 유용하게 쓰인다. 중복된 그룹 로우를 구분할 수 있는 NUMBER 타입의 값을 반환한다. 이 함수는 GROUP BY 절이 사용된 SELECT 문에만 사용할 수 있다.
GROUP_ID의 세부 내용은 다음과 같다.
-
문법
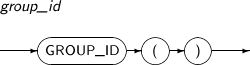
-
예제
다음은 GROUP_ID 함수를 사용하는 예이다.
SQL> SELECT depart_num, group_id() FROM employees GROUP BY depart_num; DEPART_NUM GROUP_ID() ------------- ---------- 10 1 20 0 30 0 3 rows selected.
HEXTORAW는 16진수로 표현된 문자열의 RAW 값을 구하는 함수이다.
HEXTORAW의 세부 내용은 다음과 같다.
-
문법
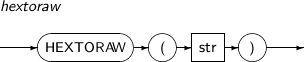
-
구성요소
구성요소 설명 str 16진수 형태의 문자열 값을 반환하는 임의의 연산식이다.
-
예제
다음은 RAW 컬럼이 있는 테이블을 만들고, HEXTORAW 함수를 이용해 16진수의 값을 컬럼에 삽입하는 예이다.
SQL> SELECT HEXTORAW(UTL_RAW.CAST_TO_RAW('DB')) COL FROM DUAL; COL ------------------------- 4442 1 row selected.
INET_ATON은 문자열 형식의 네트워크 주소를 파라미터로 받아 들여 그 주소에 해당하는 수치 값을 반환하는 함수이다. 4bytes와 8bytes의 주소 모두 사용할 수 있다.
반환된 값을 저장하기 위해서는 UNSIGEND INT를 사용해야 한다. SIGNED INT를 사용하면 주소의 첫 옥텟(Octet)의 값이 127보다 크면 올바로 저장되지 않는다.
INET_ATON의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 expr 문자열 형식의 네트워크 주소이다.
-
예제
다음은 INET_ATON 함수를 사용하는 예이다.
SQL> SELECT INET_ATON('123.255.0.1') FROM DUAL; INET_ATON('123.255.0.1') ------------------------ 2080309249 1 row selected.
INET_NTOA는 수치 값의 네트워크 주소를 받아들여 문자열 형식으로 된 네트워크 주소를 반환하는 함수이다.
INET_NTOA의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 expr 네트워크 주소를 수치 값으로 표현한 것이다.
-
예제
다음은 INET_NTOA 함수를 사용하는 예이다.
SQL> SELECT INET_NTOA(2080309249) FROM DUAL; INET_NTOA(2080309249) -------------------------------------------------------------------- 123.255.0.1 1 row selected.
INITCAP는 첫 문자는 대문자, 나머지는 소문자로 변환된 문자열을 구하는 함수이다.
INITCAP의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다. -
예제
다음은 INITCAP 함수를 사용하는 예이다.
SQL> SELECT INITCAP('tiBero') FROM DUAL; INITCAP('TIBERO') ----------------- Tibero 1 row selected.
INSERTCHILDXML은 XPath expression으로 지정된 노드의 자식 노드에 사용자가 입력한 XML값을 삽입하는 함수이다. INSERTXMLBEFORE 함수와 비교해 본다.
INSERTCHILDXML의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 xmltype_instance XML 타입 객체를 반환하는 임의의 연산식이다. xpath_string 하나 이상의 자식 노드가 삽입될 위치를 나타내는 XPath 연산식이다. child_expr 삽입될 자식 노드의 원소나 속성을 나타내는 임의의 연산식이다. value_expr 삽입될 하나 이상의 자식 노드를 나타내는 임의의 연산식이다. 이 연산식은 반드시 문자열로 변환 가능해야 한다. namespace_string XPath의 네임스페이스 정보를 나타낸다. 반드시 VARCHAR 타입이어야 한다. -
예제
다음은 INSERTCHILDXML 함수를 사용하는 예이다.
... INFO 컬럼 '<dept>research</dept>' ... SQL> UPDATE EMP SET INFO = INSERTCHILDXML(INFO, '/dept', 'id', XMLTYPE('<id>1</id>')); SQL> SELECT INFO FROM EMP; EMP ------------------------------------------- <dept>research<id>1</id></dept>
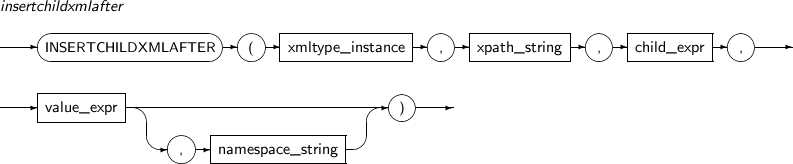
INSERTCHILDXMLAFTER은 XPath expression으로 지정된 노드에 사용자가 입력한 XML값을 삽입하는 함수이다. 이전에 존재하고 있는 자식 노드들의 뒤부터 삽입된다.
INSERTCHILDXMLAFTER의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 XMLType_instance XML 타입 객체를 반환하는 임의의 연산식이다. XPath_string 하나 이상의 자식 노드가 삽입될 위치를 나타내는 XPath 연산식이다. child_expr 삽입될 자식 노드의 원소나 속성을 나타내는 임의의 연산식이다. value_expr 삽입될 하나 이상의 자식 노드를 나타내는 임의의 연산식이다. 이 연산식은 반드시 문자열로 변환 가능해야 한다. namespace_string XPath의 네임스페이스 정보를 나타낸다. 반드시 VARCHAR 타입이어야 한다. -
예제
다음은 INSERTCHILDXMLAFTER 함수를 사용하는 예이다.
... INFO 컬럼 '<dept><id>1</id></dept>' ... SQL> UPDATE EMP SET INFO = INSERTCHILDXMLAFTER(INFO, '/dept', 'id[1]', XMLTYPE('<id>2</id>')); SQL> SELECT INFO FROM EMP; EMP ------------------------------------------- <dept><id>1</id><id>2</id></dept>
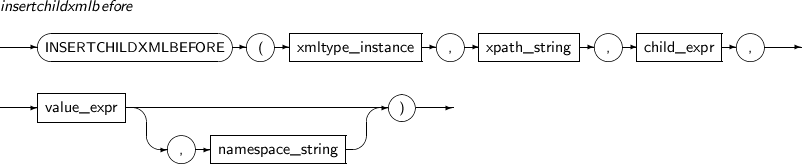
INSERTCHILDXMLBEFORE은 XPath expression으로 지정된 노드에 사용자가 입력한 XML값을 삽입하는 함수이다. 이전에 존재하고 있는 자식 노드들의 앞부터 삽입된다.
INSERTCHILDXMLBEFORE의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 XMLType_instance XML 타입 객체를 반환하는 임의의 연산식이다. XPath_string 하나 이상의 자식 노드가 삽입될 위치를 나타내는 XPath 연산식이다. child_expr 삽입될 자식 노드의 원소나 속성을 나타내는 임의의 연산식이다. value_expr 삽입될 하나 이상의 자식 노드를 나타내는 임의의 연산식이다. 이 연산식은 반드시 문자열로 변환 가능해야 한다. namespace_string XPath의 네임스페이스 정보를 나타낸다. 반드시 VARCHAR 타입이어야 한다. -
예제
다음은 INSERTCHILDXMLBEFORE 함수를 사용하는 예이다.
... INFO 컬럼 '<dept><id>1</id></dept>' ... SQL> UPDATE EMP SET INFO = INSERTCHILDXMLBEFORE(INFO, '/dept', 'id[1]', XMLTYPE('<id>2</id>')); SQL> SELECT INFO FROM EMP; EMP ------------------------------------------- <dept><id>2</id><id>1</id></dept>
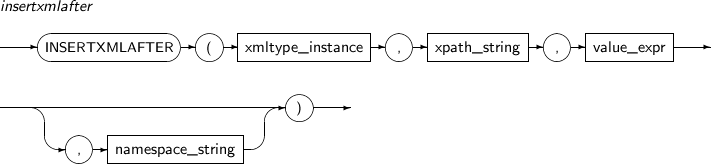
INSERTXMLAFTER은 XPath expression으로 지정된 노드에 사용자가 입력한 XML값을 삽입하는 함수이다. 이전에 존재하고 있는 노드들의 뒤부터 삽입된다.
INSERTXMLAFTER의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 XMLType_instance XML 타입 객체를 반환하는 임의의 연산식이다. XPath_string 하나 이상의 자식 노드가 삽입될 위치를 나타내는 XPath 연산식이다. value_expr 삽입될 하나 이상의 자식 노드를 나타내는 임의의 연산식이다. 이 연산식은 반드시 문자열로 변환 가능해야 한다. namespace_string XPath의 네임스페이스 정보를 나타낸다. 반드시 VARCHAR 타입이어야 한다. -
예제
다음은 INSERTXMLAFTER 함수를 사용하는 예이다.
... INFO 컬럼 '<dept>research</dept>' ... SQL> UPDATE EMP SET INFO = INSERTXMLAFTER(INFO, '/dept', XMLTYPE('<dept>sales</dept>')); SQL> SELECT INFO FROM EMP; EMP ------------------------------------------- <dept>research</dept> <dept>sales</dept>
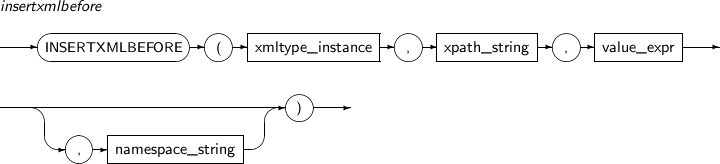
INSERTXMLBEFORE은 XPath expression으로 지정된 노드에 사용자가 입력한 XML값을 삽입하는 함수이다. 이전에 존재하고 있는 노드들의 이전 부터 삽입된다.
INSERTXMLBEFORE의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 XMLType_instance XML 타입 객체를 반환하는 임의의 연산식이다. XPath_string 하나 이상의 자식 노드가 삽입될 위치를 나타내는 XPath 연산식이다. value_expr 삽입될 하나 이상의 자식 노드를 나타내는 임의의 연산식이다. 이 연산식은 반드시 문자열로 변환 가능해야 한다. namespace_string XPath의 네임스페이스 정보를 나타낸다. 반드시 VARCHAR 타입이어야 한다. -
예제
다음은 INSERTXMLBEFORE 함수를 사용하는 예이다.
... INFO 컬럼 '<dept>research</dept>' ... SQL> UPDATE EMP SET INFO = INSERTXMLBEFORE(INFO, '/dept', XMLTYPE('<dept>sales</dept>')); SQL> SELECT INFO FROM EMP; EMP ------------------------------------------- <dept>sales</dept> <dept>research</dept>
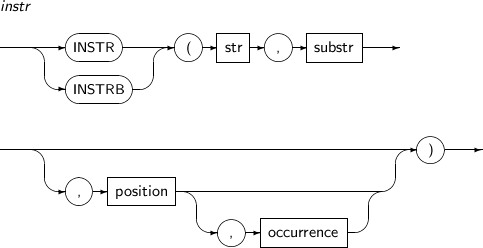
INSTR은 문자열 str 내에서 문자열 substr을 찾아 그 위치를 반환하는 함수이다. 추가로 INSTRB 함수는 문자 대신 byte 단위로 위치를 계산하여 그 위치를 반환한다.
INSTR, INSTRB의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 str, substr 모두 문자열을 반환하는 임의의 연산식이다. 만약 문자열 str 내에서 문자열 substr을 발견하지 못하면 0을 반환한다.
문자열의 위치 값은 1부터 시작된다.
position 0이 아닌 정수 값을 반환하는 임의의 연산식이다. (기본값: 1)
position이 주어지면 문자열 str의 position 위치에서부터 탐색을 시작한다. 만약 position이 음수이면 문자열 str의 뒤에서부터 탐색을 시작한다.
occurrence 0이 아닌 정수 값을 반환하는 임의의 연산식이다. (기본값: 1)
occurrence가 주어지면 탐색 문자열 내에서 occurrence 번째에 나타나는 문자열 substr의 위치를 반환한다. occurrence는 양의 정수이어야 한다.
-
예제
다음은 INITCAP 함수를 사용하는 예이다.
SQL> SELECT INSTR('ABCDEABCDEABCDE', 'CD') FROM DUAL; INSTR('ABCDEABCDEABCDE','CD') ----------------------------- 3 1 row selected. SQL> SELECT INSTR('ABCDEABCDEABCDE', 'CD', 5, 2) FROM DUAL; INSTR('ABCDEABCDEABCDE','CD',5,2) --------------------------------- 13 1 row selected.
ISFRAGMENT은 xmltype_instance가 fragment이면 1을 반환하고, well-formed document이면 0을 반환하는 함수이다.
ISFRAGMENT의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 xmltype_instance 질의의 대상이 되는 XML 문서로, XMLType이다. -
예제
다음은 ISFRAGMENT 함수를 사용하는 예이다.
SQL> select isfragment(XMLTYPE('<a><b>1</b></a>')) from dual; ISFRAGMENT(XMLTYPE('<A><B>1</B></A>')) -------------------------------------- 0 1 row selected. SQL> select isfragment(XMLCONCAT(XMLTYPE('<a>1</a>'), XMLTYPE('<b>2</b>'))) from dual; ISFRAGMENT(XMLCONCAT(XMLTYPE('<A>1</A>'),XMLTYPE('<B>2</B>'))) -------------------------------------------------------------- 1 1 row selected.
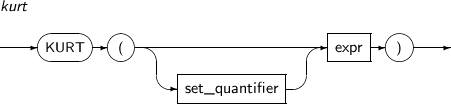
KURT는 expr의 첨도를 반환하는 함수이다. 파라미터의 수치 데이터 타입 또는 변환된 수치 데이터 타입을 반환한다.
KURT의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 set_quantifier 질의 결과에 중복된 로우의 허용, 비허용 여부를 지정한다. DISTINCT, UNIQUE, ALL을 지정할 수 있다.
-
DISTINCT, UNIQUE: 중복된 로우를 제거한다.
-
ALL: 모든 로우를 선택한다. (기본값)
expr 모든 수치 데이터 타입 또는 수치 데이터 타입은 아니지만 묵시적으로 수치 데이터 타입으로 변환할 수 있는 임의의 연산식이다. -
-
예제
다음은 KURT 함수를 사용하는 예이다.
SQL> SELECT KURT(SAL) FROM EMP; KURT(SAL) ---------- 1.31945327 1 row selected.
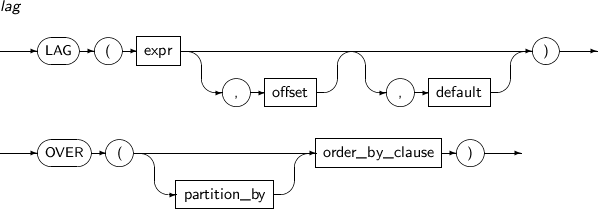
LAG는 자기 자신과 조인하지 않고도 한 테이블에서 여러 개의 로우를 동시에 볼 수 있는 분석 함수이다. LAG는 명시된 수만큼 현재 로우에서 앞서 있는 로우에 접근을 제공한다.
LAG의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 expr expr에 LAG를 포함한 다른 분석 함수를 명시할 수 없다. 즉, 분석 함수를 중첩해서 사용할 수는 없다. offset 접근 횟수를 offset에 명시한다. offset을 명시하지 않으면 1로 간주된다. default offset이 Window의 범위를 초과하면 default에서 지정한 값이 반환된다.
default를 명시하지 않으면 NULL이 반환된다.
partition_by 현재 질의 블록의 결과 집합을 expr을 기준으로 분할한다.
자세한 내용은 “4.1.3. 분석 함수”의 partition_by를 참고한다.
order_by_clause 분할된 하나의 파티션 내에서 로우를 어떻게 정렬할지를 명시한다.
자세한 내용은 “4.1.3. 분석 함수”의 order_by_clause를 참고한다.
-
예제
다음은 LAG 함수를 사용하는 예이다.
SQL> SELECT NAME, DEPTID, SALARY, LAG (SALARY, 2, 0) OVER (PARTITION BY DEPTID ORDER BY SALARY) PSAL FROM EMP; NAME DEPTID SALARY PSAL -------------------- ---------- ---------- ---------- Paul 1 3000 0 Angela 1 3000 0 Nick 1 3200 3000 Scott 1 4000 3000 James 1 4000 3200 John 1 4500 4000 Joe 2 4000 0 Brad 2 4200 0 Daniel 2 5000 4000 Tom 2 5000 4200 Kathy 2 5000 5000 Bree 2 6000 5000 12 rows selected.
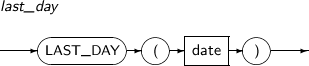
LAST_DAY는 파라미터에 명시된 날짜를 포함하는 연월의 마지막 날로 변환된 날짜를 구하는 함수이다.
LAST_DAY의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 date 날짜 값을 반환하는 임의의 연산식이다. -
예제
다음은 LAST_DAY 함수를 사용하는 예이다.
SQL> SELECT LAST_DAY('2005/06/22') FROM DUAL; LAST_DAY('2005/06/22') ----------------------------------------------------------------- 2005-06-30 1 row selected.
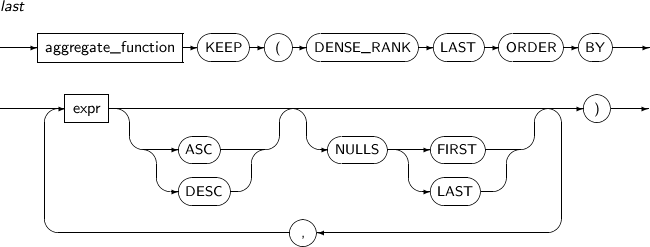
LAST는 정렬된 로우에서 마지막에 해당하는 로우를 뽑아내어 명시된 집단함수를 적용한 결과를 반환한다. 현재 분석 함수는 지원하지 않는다.
LAST 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 aggregate_function 사용가능한 집단 함수는 AVG, COUNT, MIN, MAX, SUM, STADDEV 그리고 VARIANCE이다. expr 임의의 연산식이다.
-
예제
다음은 LAST 함수를 사용하는 예이다.
SQL> SELECT DEPTNO, MIN(HIREDATE) KEEP (DENSE_RANK LAST ORDER BY SAL) MIN_HIREDATE, MAX(HIREDATE) KEEP (DENSE_RANK LAST ORDER BY SAL) MAX_HIREDATE FROM EMP GROUP BY DEPTNO; DEPTNO MIN_HIREDATE MAX_HIREDATE ---------- -------------------------------- -------------------------------- 10 1981/11/17 1981/11/17 20 1981/12/03 1987/04/19 30 1981/05/01 1981/05/01 3 rows selected.
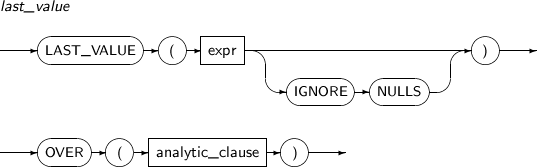
LAST_VALUE는 정렬된 로우에서 마지막 값을 반환하는 분석함수이다. IGNORE NULLS를 명시하면 NULL이 아닌 첫 번째 값을 반환한다. 만약 모든 값이 NULL이라면 NULL을 반환한다.
LAST_VALUE 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 expr 임의의 연산식이다.
-
예제
다음은 LAST_VALUE 함수를 사용하는 예이다.
SELECT DEPTNO, ENAME, LAST_VALUE(ENAME) OVER (PARTITION BY DEPTNO ORDER BY HIREDATE ASC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS NEW_EMP FROM EMP; DEPTNO ENAME NEW_EMP ---------- ---------- ---------- 10 CLARK MILLER 10 KING MILLER 10 MILLER MILLER 20 SMITH ADAMS 20 JONES ADAMS 20 FORD ADAMS 20 SCOTT ADAMS 20 ADAMS ADAMS 30 ALLEN JAMES 30 WARD JAMES 30 BLAKE JAMES 30 TURNER JAMES 30 MARTIN JAMES 30 JAMES JAMES 14 rows selected.
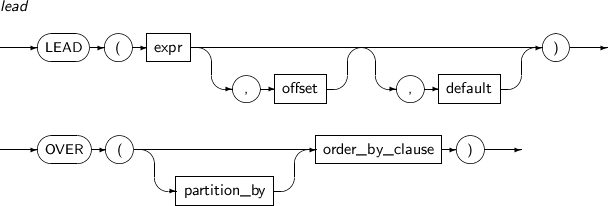
LEAD는 자기 자신과 조인하지 않고도 한 테이블에서 여러 개의 로우를 동시에 볼 수 있는 분석 함수이다. LEAD는 명시된 수만큼 현재 로우에서 뒤에 나오는 로우에 접근을 제공한다.
LEAD의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 expr expr에 LEAD를 포함한 다른 분석 함수를 명시할 수 없다. 즉, 분석 함수를 중첩해서 사용할 수는 없다. offset 접근 횟수를 offset에 명시한다. offset을 명시하지 않으면 1로 간주된다. default offset이 Window의 범위를 초과하면 default에서 지정한 값이 반환된다.
default를 명시하지 않으면 NULL이 반환된다.
partition_by 현재 질의 블록의 결과 집합을 expr을 기준으로 분할한다.
자세한 내용은 “4.1.3. 분석 함수”의 partition_by를 참고한다.
order_by_clause 분할된 하나의 파티션 내에서 로우를 어떻게 정렬할지를 명시한다.
자세한 내용은 “4.1.3. 분석 함수”의 order_by_clause를 참고한다.
-
예제
다음은 LEAD 함수를 사용하는 예이다.
SQL> SELECT NAME, DEPTID, SALARY, LEAD (SALARY, 2, 0) OVER (PARTITION BY DEPTID ORDER BY SALARY) PSAL FROM EMP; NAME DEPTID SALARY PSAL -------------------- ---------- ---------- ---------- Paul 1 3000 3200 Angela 1 3000 4000 Nick 1 3200 4000 Scott 1 4000 4500 James 1 4000 0 John 1 4500 0 Joe 2 4000 5000 Brad 2 4200 5000 Daniel 2 5000 5000 Tom 2 5000 6000 Kathy 2 5000 0 Bree 2 6000 0 12 rows selected.
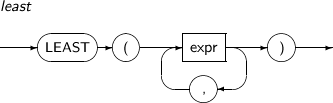
LEAST는 파라미터 중 가장 작은 값을 가지는 파라미터를 구하는 함수이다.
LEAST의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 expr 임의의 연산식이다.
첫 파라미터 이후의 모든 파라미터는 첫 파라미터의 타입으로 암묵적으로 변환된 후 비교된다.
expr 중 하나의 값이 NULL이면 함수는 NULL을 반환한다.
-
예제
다음은 LEAST 함수를 사용하는 예이다.
SQL> SELECT LEAST(1, 3, 2) FROM DUAL; LEAST(1,3,2) ------------ 1 1 row selected.
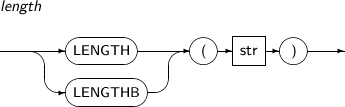
LENGTH는 주어진 파라미터의 문자열의 길이를 반환하는 함수이다. 추가로 LENGTHB 함수는 문자열의 길이를 문자 대신 byte 단위로 계산한다.
LENGTH의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다. -
예제
다음은 LENGTH 함수를 사용하는 예이다.
SQL> SELECT LENGTH('ABCDEFG') FROM DUAL; LENGTH('ABCDEFG') ----------------- 7 1 row selected.
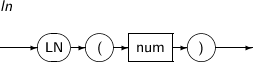
LN은 주어진 파라미터의 자연 로그 값을 구하는 함수이다.
LN의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 num 수치 값을 반환하는 임의의 연산식이며, 0보다 큰 실수를 반환한다. -
예제
다음은 LN 함수를 사용하는 예이다.
SQL> SELECT TO_CHAR(LN(2.7182818284),'99') FROM DUAL; TO_CHAR(LN(2.7182818284),'99') ------------------------------ 1 1 row selected.
LNNVL은 condition의 계산 값이 FALSE이거나 UNKNOWN이면 TRUE를 반환하고, TRUE이면 FALSE를 반환하는 함수이다. 일반적으로 사용자가 직접 이 함수를 사용할 일은 거의 없지만, 쿼리를 최적화하는 과정에서 사용할 수 있다.
LNNVL의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 condition 임의의 조건식이다. 조건식에 관한 자세한 내용은 “3.4. 조건식”을 참고한다. -
예제
다음은 LNNVL 함수를 사용하는 예이다.
SQL> SELECT 1 FROM DUAL WHERE LNNVL (1 = 2); 1 ---------- 1 1 row selected.
LOCALTIMESTAMP는 현재 날짜 및 시간을 출력하는 함수이다. 이 함수의 반환값은 TIMESTAMP 타입이다.
LOCALTIMESTAMP의 세부 내용은 다음과 같다.
-
문법
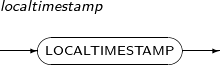
-
예제
다음은 LOCALTIMESTAMP 함수를 사용하는 예이다.
SQL> SELECT LOCALTIMESTAMP FROM DUAL; LOCALTIMESTAMP ------------------------------------- 2011/04/14 16:55:23.375613 1 row selected.
LOG는 밑을 num1으로 하는 num2의 로그 값을 반환하는 함수이다.
LOG의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 num1, num2 num1과 num2는 0보다 큰 실수 값을 반환하는 임의의 연산식이며, num1은 1이면 안 된다. -
예제
다음은 LOG 함수를 사용하는 예이다.
SQL> SELECT LOG(2, 8) FROM DUAL; LOG(2,8) ---------- 3 1 row selected.
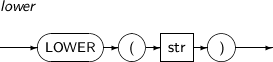
LOWER는 문자열 str 내의 모든 영문자를 소문자로 변환하여 반환하는 함수이다.
LOWER의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다. -
예제
다음은 LOWER 함수를 사용하는 예이다.
SQL> SELECT LOWER('ABCDEFG123') FROM DUAL; LOWER('ABCDEFG123') ------------------- abcdefg123 1 row selected.
LPAD는 expr2를 expr1의 왼쪽에 반복적으로 붙인 길이 num의 문자열을 구하는 함수이다.
대부분의 문자 집합에서는 반환되는 문자열의 문자 수와 길이가 동일하지만, 한글과 같은 멀티 바이트 문자 집합의 경우에는 두 값이 다를 수 있다.
LPAD의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr1 문자열 또는 CLOB 타입, BLOB 타입을 반환하는 임의의 연산식이다.
expr1의 길이가 num 보다 큰 경우 expr1에서 왼쪽부터 num 만큼의 문자열을 반환한다.
expr2 문자열 또는 CLOB 타입, BLOB 타입을 반환하는 임의의 연산식이다.
expr2가 명시되지 않은 경우 공백 문자가 사용된다.
num num은 수치 값을 반환하는 임의의 연산식이다.
num은 터미널에 출력되는 길이를 의미한다.
-
예제
다음은 LPAD 함수를 사용하는 예이다.
SQL> SELECT LPAD('LPAD', 10, '-=') FROM DUAL; LPAD('LPAD',10,'-=') -------------------- -=-=-=LPAD 1 row selected.
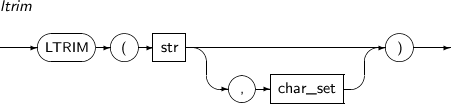
LTRIM은 문자열 str의 왼쪽으로부터 문자열 char_set 내에 포함된 모든 문자를 제거하는 함수이다.
LTRIM의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다. char_set 문자열을 반환하는 임의의 연산식이다.
만약 파라미터 char_set의 값이 없으면, 기본값으로 공백 문자 하나를 갖는다.
-
예제
다음은 LTRIM 함수를 사용하는 예이다.
SQL> SELECT LTRIM(' ABCDE') FROM DUAL; LTRIM('ABCDE') -------------- ABCDE 1 row selected. SQL> SELECT LTRIM('XYXABCDEXYX', 'XY') FROM DUAL; LTRIM('XYXABCDEXYX','XY') ------------------------- ABCDEXYX 1 row selected.
MAX는 그룹 내의 모든 로우에 대한 expr 값 중의 최댓값을 구하는 함수이다. 분석 함수로도 사용할 수 있다. 이 함수를 분석 함수로 사용할 때 DISTINCT 예약어를 명시하면 analytic_clause에서 query_partition_clause만 명시할 수 있다. order_by_clause는 명시할 수 없다.
MAX의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 set_quantifier 질의 결과에 중복된 로우의 허용, 비허용 여부를 지정한다. DISTINCT, UNIQUE, ALL을 지정할 수 있다.
-
DISTINCT, UNIQUE: 중복된 로우를 제거한다.
-
ALL: 모든 로우를 선택한다. (기본값)
expr 임의의 연산식이다.
expr 앞에 DISTINCT 예약어를 포함하면, 최댓값을 구하기 전에 expr 값 중에서 중복된 값을 먼저 제거한다.
analytic_clause OVER analytic_clause를 사용해 함수를 분석 함수로 수행할 수 있다.
자세한 내용은 “4.1.3. 분석 함수”의 analytic_clause를 참고한다.
-
-
예제
다음은 MAX 함수를 사용하는 예이다.
SQL> SELECT DEPTID, MAX(SALARY) FROM EMP2 GROUP BY DEPTID; DEPTID MAX(SALARY) ---------- ----------- 1 4500 2 6000 2 rows selected. -
분석 함수 예제
다음은 MAX 함수를 분석 함수로 사용하는 예이다.
SQL> SELECT NAME, DEPTID, SALARY, MAX(SALARY) OVER (PARTITION BY DEPTID) AS MSAL FROM EMP2; NAME DEPTID SALARY MSAL -------------------- ---------- ---------- ---------- Paul 1 3000 4500 Nick 1 3200 4500 Scott 1 4000 4500 John 1 4500 4500 Bree 2 6000 6000 Daniel 2 5000 6000 Joe 2 4000 6000 Brad 2 4200 6000 8 rows selected.
MEDIAN은 파라미터로 주어진 expr의 그룹 안에서의 중간 값을 계산하는 함수이다. 분석 함수로도 사용할 수 있다. 계산을 할 때 NULL 값은 무시한다.
계산 방법과 계산 결과는 PERCENTILE_CONT에 파라미터 값 0.5를 사용한 것과 동일하다.
MEDIAN의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr 수치 값을 반환하는 임의의 연산식이다. analytic_clause OVER analytic_clause를 사용해 함수를 분석 함수로 수행할 수 있다.
자세한 내용은 “4.1.3. 분석 함수”의 analytic_clause를 참고한다.
-
예제
다음은 MEDIAN 함수를 사용하는 예이다.
SQL> SELECT DEPTNO, MEDIAN(SAL) FROM EMP AS MEDIAN GROUP BY DEPTNO; DEPTNO MEDIAN(SAL) ---------- ----------- 10 2450 20 2975 30 1375 3 rows selected. -
분석 함수 예제
다음은 MEDIAN 함수를 분석 함수로 사용하는 예이다.
SQL> SELECT DEPTNO, EMPNO, MEDIAN(SAL) OVER (PARTITION BY DEPTNO) AS MEDIAN FROM EMP; DEPTNO EMPNO MEDIAN ---------- ---------- ---------- 10 7934 2450 10 7782 2450 10 7839 2450 20 7369 2975 20 7876 2975 20 7566 2975 20 7788 2975 20 7902 2975 30 7900 1375 30 7521 1375 30 7654 1375 30 7844 1375 30 7499 1375 30 7698 1375 14 rows selected.
MIN은 그룹 내의 모든 로우에 대한 expr 값 중의 최솟값을 구하는 함수이다. 분석 함수로도 사용할 수 있다.
이 함수를 분석 함수로 사용할 때 DISTINCT 예약어를 명시하면 analytic_clause에서 query_partition_clause만 명시할 수 있다. order_by_clause는 명시할 수 없다.
MIN의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 set_quantifier 질의 결과에 중복된 로우의 허용, 비허용 여부를 지정한다. DISTINCT, UNIQUE, ALL을 지정할 수 있다.
-
DISTINCT, UNIQUE: 중복된 로우를 제거한다.
-
ALL: 모든 로우를 선택한다. (기본값)
expr 임의의 연산식이다.
expr 앞에 DISTINCT 예약어를 포함하면, 최솟값을 구하기 전에 expr 값 중에서 중복된 값을 먼저 제거한다.
analytic_clause OVER analytic_clause를 사용해 함수를 분석 함수로 수행할 수 있다.
자세한 내용은 “4.1.3. 분석 함수”의 analytic_clause를 참고한다.
-
-
예제
다음은 MIN 함수를 사용하는 예이다.
SQL> SELECT DEPTID, MIN(SALARY) FROM EMP2 GROUP BY DEPTID; DEPTID MIN(SALARY) ---------- ---------- 1 3000 2 4000 2 rows selected. -
분석 함수 예제
다음은 MIN 함수를 분석 함수로 사용하는 예이다.
SQL> SELECT NAME, DEPTID, SALARY, MIN(SALARY) OVER (PARTITION BY DEPTID) AS MSAL FROM EMP2; NAME DEPTID SALARY MSAL -------------------- ---------- ---------- ---------- Paul 1 3000 3000 Nick 1 3200 3000 Scott 1 4000 3000 John 1 4500 3000 Bree 2 6000 4000 Daniel 2 5000 4000 Joe 2 4000 4000 Brad 2 4200 4000 8 rows selected.
MOD는 num1을 num2로 나눈 나머지를 반환하는 함수이다. 이 함수는 num1 또는 num2가 음수이면 전통적인 모듈러스(Modulus) 함수와는 다른 결과를 반환한다.
MOD 함수는 다음과 같이 정의할 수 있다.
MOD(num1, num2) = SIGN(num1) * MOD1(ABS(num1), ABS(num2))
위의 수식에서 MOD1은 전통적인 모듈러스 함수이며, num1과 num2가 모두 양수이면 MOD 함수와 같은 결과를 반환한다. 위의 SIGN 함수는 num1이 양수이면 +1, 음수이면 -1을 반환하며, ABS 함수는 num1과 num2의 절댓값을 반환한다.
MOD의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 num1, num2 임의의 수치 값을 반환하는 연산식이다. -
예제
다음은 MOD 함수를 사용하는 예이다.
SQL> SELECT MOD(13, 5), MOD(13, -5), MOD(-13, 5), MOD(-13, -5) FROM DUAL; MOD(13,5) MOD(13,-5) MOD(-13,5) MOD(-13,-5) ---------- ---------- ---------- ---------- 3 3 -3 -3 1 row selected.
MONTHS_BETWEEN은 date1과 date2 사이의 개월 차를 구하는 함수이다. 두 날짜 사이의 일수를 31로 나눈 값을 반환한다.
MONTHS_BETWEEN의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 date1, date2 날짜를 반환하는 임의의 연산식이다. -
예제
다음은 MONTHS_BETWEEN 함수를 사용하는 예이다.
SQL> SELECT MONTHS_BETWEEN(LAST_DAY('2005/06/22'), '2005/06/22') FROM DUAL; MONTHS_BETWEEN(LAST_DAY('2005/06/22'),'2005/06/22') --------------------------------------------------- .258064516129032 1 row selected.
NEW_TIME는 timezone1에 속해있는 date값을 timezone2에 해당하는 날짜/시간값으로 변환하여 그 결과를 반환하는 함수이다.
NEW_TIME의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 date 날짜를 반환하는 임의의 연산식이다. timezone1 시간대값을 반환하는 임의의 연산식으로 다음 문자열들을 사용할 수 있다.
-
AST, ADT: 대서양 표준시, 대서양 일광 절약시간
-
BST, BDT: 베링 표준시, 베링 일광 절약시간
-
CST, CDT: 중부 표준시, 중부 일광 절약시간
-
EST, EDT: 동부 표준시, 동부 일광 절약시간
-
GMT: 그리니치 표준시
-
HST, HDT: 알래스카-하와이 표준시, 알래스카-하와이 일광 절약시간
-
MST, MDT: 산악 표준시, 산악 일광 절약시간
-
NST: 뉴펀들랜드 표준시
-
PST, PDT: 태평양 표준시, 태평양 일광 절약시간
-
YST, YDT: 유콘 표준시, 유콘 일광 절약시간
timezone2 시간대 값을 반환하는 임의의 연산식으로 timezone1과 동일한 문자열들을 사용할 수 있다. -
-
예제
다음은 NEW_TIME 함수를 사용하는 예이다.
SQL> SELECT NEW_TIME(TO_DATE('1982/12/13 15:28:00', 'YYYY/MM/DD HH24:MI:SS'), 'EST', 'YST') NEW_TIME FROM DUAL; NEW_TIME -------------------------------- 1982/12/13 11:28:00 1 row selected.
NEXT_DAY는 date와 가장 가까운 다음 요일 str의 날짜를 반환하는 함수이다.
NEXT_DAY의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 date 날짜를 반환하는 임의의 연산식이다. str 요일을 나타내는 문자열 값이다. -
예제
다음은 NEXT_DAY 함수를 사용하는 예이다.
SQL> SELECT NEXT_DAY('2005/06/22', 'MONDAY') FROM DUAL; NEXT_DAY('2005/06/22','MONDAY') -------------------------------- 2005/06/27 1 row selected.
NLSSORT는 str를 정렬하기 위해 사용되는 문자 바이트를 반환하는 함수이다.
NLSSORT의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 str 정렬하기 위한 문자열 값이다.
-
CHAR, VARCHAR, NCHAR, NVARCHAR 타입의 데이터가 올 수 있다.
nls_param str를 정렬하기 위해 사용할 문자 집합을 정의하는 파라미터이다.
-
CHAR, VARCHAR, NCHAR, NVARCHAR 타입의 데이터가 올 수 있다.
-
'NLS_SORT=sort'와 같은 형식으로 정의할 수 있다. 정의하지 않으면 세션에 정의된 값을 사용한다.
-
-
예제
다음은 NLSSORT 함수를 사용하는 예이다.
SQL> CREATE TABLE T (NAME VARCHAR(10)); SQL> INSERT INTO T VALUES('jclee'); SQL> INSERT INTO T VALUES('À voir'); SQL> SELECT NAME FROM T ORDER BY NLSSORT(NAME, 'NLS_SORT=german'); NAME ---------- À voir jclee 2 rows selected.
NLS_INITCAP은 각 단어의 첫 글자를 대문자로, 다른 나머지 글자는 소문자로 변환하는 함수이다.
str에는 CHAR, VARCHAR, NCHAR, NVARCHAR 형식의 문자열이 올 수 있고, 결과는 입력된 str의 문자 집합과 동일한 형식의 값이 반환된다. nls_param은 'NLS_SORT=sort'와 같은 형식으로 정의될 수 있으며, 정의되지 않았을 경우에는 세션에 정의된 값을 사용하게 된다.
NLS_INITCAP의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 str 변환하기 위한 문자열 값이다.
-
CHAR, VARCHAR, NCHAR, NVARCHAR 타입의 데이터가 올 수 있다.
-
변환 결과는 입력된 str의 문자 집합과 동일한 형식의 값이 반환된다.
nls_param str를 변환하기 위해 사용할 문자 집합을 정의하는 파라미터이다.
-
CHAR, VARCHAR, NCHAR, NVARCHAR 타입의 데이터가 올 수 있다.
-
'NLS_SORT=sort'와 같은 형식으로 정의할 수 있다. 정의하지 않으면 세션에 정의된 값을 사용한다.
-
-
예제
다음은 NLS_INITCAP 함수를 사용하는 예이다.
SQL> SELECT NLS_INITCAP('ijland','NLS_SORT=XDutch') "NLS_INITCAP" FROM DUAL; NLS_INITCAP ----------- IJland 1 row selected.
NLS_LOWER는 입력된 문자열을 모두 소문자로 변환하는 함수이다.
NLS_LOWER의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 str 변환하기 위한 문자열 값이다.
-
CHAR, VARCHAR, NCHAR, NVARCHAR 타입의 데이터가 올 수 있다.
nls_param str를 변환하기 위해 사용할 문자 집합을 정의하는 파라미터이다.
-
CHAR, VARCHAR, NCHAR, NVARCHAR 타입의 데이터가 올 수 있다.
-
'NLS_SORT=sort'와 같은 형식으로 정의할 수 있다. 정의하지 않으면 세션에 정의된 값을 사용한다.
-
-
예제
다음은 NLS_LOWER 함수를 사용하는 예이다.
SQL> SELECT NLS_LOWER('GROBE','NLS_SORT=XGerman') "NLS_LOWER" FROM DUAL; NLS_LOWER -------- grobe 1 row selected.
NLS_UPPER는 입력된 문자열을 모두 대문자로 변환하는 함수이다.
NLS_UPPER의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 str 변환하기 위한 문자열 값이다.
-
CHAR, VARCHAR, NCHAR, NVARCHAR 타입의 데이터가 올 수 있다.
nls_param str를 변환하기 위해 사용할 문자 집합을 정의하는 파라미터이다.
-
CHAR, VARCHAR, NCHAR, NVARCHAR 타입의 데이터가 올 수 있다.
-
'NLS_SORT=sort'와 같은 형식으로 정의할 수 있다. 정의하지 않으면 세션에 정의된 값을 사용한다.
-
-
예제
다음은 NLS_UPPER 함수를 사용하는 예이다.
SQL> SELECT NLS_UPPER('große','NLS_SORT=XGerman') "NLS_UPPER" FROM DUAL; NLS_UPPER --------- GROSSE 1 row selected.
NTILE은 그룹 내의 정렬된 행을 expr개의 버킷으로 나누어 버킷의 번호를 지정해 주는 분석 함수이다.
NTILE의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr expr이 정수가 아니면 소수점 이하를 버린 값을 사용한다.
expr에 LEAD를 포함한 다른 분석 함수를 명시할 수 없다. 즉, 분석 함수를 중첩해서 사용할 수는 없다.
-
예제
다음은 NTILE 함수를 사용하는 예이다.
SQL> SELECT NTILE(5) OVER (ORDER BY SAL) AS NTILE FROM EMP; NTILE ---------- 1 1 1 2 2 2 3 3 3 4 4 4 5 5 14 rows selected.
NULLIF는 만약 expr1과 expr2의 값이 동일하면 NULL을 반환하고, 그렇지 않으면 expr1 값을 반환하는 함수이다.
NULLIF의 세부 내용은 다음과 같다.
-
문법
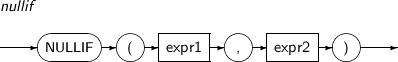
-
구성요소
구성요소 설명 expr1 임의의 연산식이며, expr1에 NULL이 올 수 없다. expr2 임의의 연산식이다. -
예제
다음은 NULLIF 함수를 사용하는 예이다.
SQL> SELECT NVL (NULLIF ('A', 'A'), 'Same') FROM DUAL; NVL(NULLIF('A','A'),'SAME') --------------------------- Same 1 row selected.
NUMTODSINTERVAL은 입력으로 들어온 값을 날짜-시간 구간 형식으로 변환하는 함수이다.
NUMTODSINTERVAL의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr 변환할 입력 값이다. interval_unit 변환의 단위를 나타내는 값이다.
DAY, HOUR, MINUTE, SECOND 중 하나의 값만 올 수 있다.
-
예제
다음은 NUMTODSINTERVAL 함수를 사용하는 예이다.
SQL> SELECT NUMTODSINTERVAL (10, 'DAY') "NUMTODSINTERVAL" FROM DUAL; NUMTODSINTERVAL ----------------------------- +000000010 00:00:00.000000000 1 row selected.
NUMTOYMINTERVAL은 입력으로 들어온 값을 년도-달 구간 형식으로 변환하는 함수이다.
NUMTOYMINTERVAL의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr 변환할 입력 값이다. interval_unit 변환의 단위를 나타내는 값이다.
YEAR, MONTH 중 하나의 값만 올 수 있다.
-
예제
다음은 NUMTOYMINTERVAL 함수를 사용하는 예이다.
SQL> SELECT NUMTOYMINTERVAL (10, 'YEAR') "NUMTOYMINTERVAL" FROM DUAL; NUMTOYMINTERVAL --------------- +000000010-00 1 row selected.
NVL은 expr1이 NULL이 아니면 expr1을 반환하고, expr1이 NULL이면 expr2를 반환하는 함수이다.
NVL의 세부 내용은 다음과 같다.
-
문법
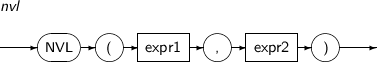
-
구성요소
구성요소 설명 expr1 임의의 연산식이다. expr2 임의의 연산식이다. -
예제
다음은 NVL 함수를 사용하는 예이다.
SQL> SELECT NAME, ID, NVL(TO_CHAR(MGRID, '99'), 'N/A') MID FROM EMP3; NAME ID MID -------------------- ---------- --- Paul 1 N/A John 2 1 Linda 3 1 Lucas 4 N/A Kathy 5 4 5 rows selected.
NVL2는 expr1이 NULL이 아니면 expr2를 반환하고 NULL이면 expr3를 반환하는 함수이다.
NVL2의 세부 내용은 다음과 같다.
-
문법
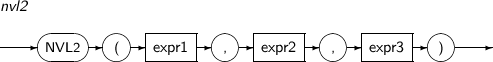
-
구성요소
구성요소 설명 expr1 임의의 연산식이다. expr2 임의의 연산식이다.
expr2의 데이터 타입에 따라 반환되는 타입이 결정된다.
expr3 임의의 연산식이다.
expr3은 expr2의 데이터 타입으로 암묵적으로 변환된다.
-
예제
다음은 NVL2 함수를 사용하는 예이다.
SQL> SELECT NVL2(DUMMY, 'NOT NULL', 'NULL') FROM DUAL; NVL2(DUMMY, 'NOT NULL', 'NULL') ------------------------------- NOT NULL 1 row selected.
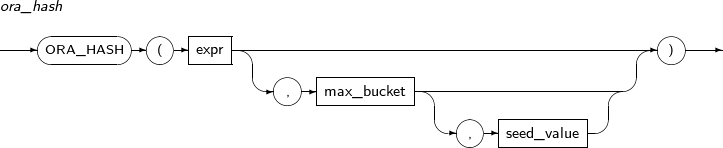
ORA_HASH는 주어진 데이터에 대해 해쉬값을 계산하고 그 결과를 반환하는 함수이다.
ORA_HASH의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 expr 해쉬값을 계산하기 위한 데이터를 나타내는 임의의 연산식이다. LONG과 LOB을 제외한 모든 타입을 사용할 수 있다. max_bucket 최대 버킷 크기를 나타내는 숫자 연산식이다. 0~4294967295 사이의 값을 사용할 수 있다. (기본값: 4294967295) seed_value 같은 데이터에 대해 해쉬값의 변화를 줄 수 있는 숫자 연산식이다. 0~4294967295 사이의 값을 사용할 수 있다. (기본값: 0) -
예제
다음은 ORA_HASH 함수를 사용하는 예이다.
SQL> SELECT ORA_HASH(512, 10, 5) FROM DUAL; ORA_HASH(512,10,5) ------------------ 4 1 row selected.
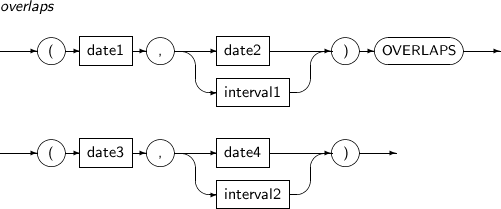
OVERLAPS는 두 개의 시간 간격이 서로 겹치는지의 여부를 알아보는 함수이다. 겹칠 때는 TRUE를, 겹치지 않을 때는 FALSE를 반환한다. 시간 간격은 시작점과 끝점이 한 쌍으로 명시된다. 시작점 또는 끝점은 DATE, TIMESTAMP 타입이 가능하며, 끝점에 대해서 추가로 INTERVAL을 명시하는 것도 가능하다.
OVERLAPS의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 date1, date3 시작 날짜를 나타낸다. DATE 또는 TIMESTAMP 타입이다. date2, date4 끝 날짜를 나타낸다. DATE 또는 TIMESTAMP 타입이다. interval1, interval2 날짜의 간격을 나타내는 간격 리터럴이다. -
예제
다음은 OVERLAPS 함수를 사용하는 예이다.
SQL> SELECT 1 FROM DUAL WHERE (DATE'1999-01-01', DATE'2000-01-01') OVERLAPS (DATE'1999-03-01', INTERVAL '1' YEAR); 1 ---------- 1 1 row selected.
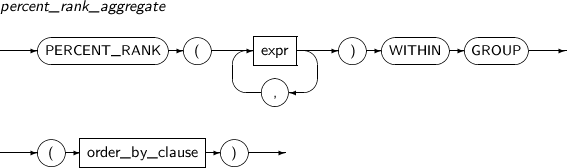
PERCENT_RANK는 파라미터로 주어진 값의 그룹 내의 위치를 나타내 주는 함수이다. 반환되는 값은 0 ~ 1사이의 값이고 NUMBER 타입이다. 분석 함수로도 사용할 수 있다.
계산 방법은 다음과 같이 함수에 따라 달라진다.
| 함수 | 설명 |
|---|---|
| 집계 함수 | 주어진 파라미터로 구성된 가상의 로우의 RANK 값을 계산하여 1을 빼고 그룹 안의 로우의 개수로 나눈다. 파라미터의 값은 그룹 안에서는 상수 값을 가져야 하며 ORDER BY절의 표현식과 대응되어야 한다. |
| 분석 함수 | 주어진 파라미터로 구성된 가상의 로우의 RANK 값에서 1을 뺀 값을 그룹 안의 로우의 개수에서 1을 뺀 값으로 나눈다. |
PERCENT_RANK의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr 수치 값을 반환하는 임의의 연산식이다. partition_by 현재 질의 블록의 결과 집합을 expr 또는 expr의 리스트를 기준으로 분할한다.
자세한 내용은 “4.1.3. 분석 함수”의 partition_by를 참고한다.
order_by_clause 분할된 하나의 파티션 내에서 로우를 어떻게 정렬할지를 명시한다.
자세한 내용은 “4.1.3. 분석 함수”의 order_by_clause를 참고한다.
-
예제
다음은 PERCENT_RANK 함수를 사용하는 예이다.
SQL> SELECT PERCENT_RANK(1000) WITHIN GROUP (ORDER BY SAL) AS PERCENT_RANK FROM EMP; PERCENT_RANK ------------ .14285714286 1 row selected. -
분석 함수 예제
다음은 PERCENT_RANK 함수를 분석 함수로 사용하는 예이다.
SQL> SELECT PERCENT_RANK() OVER (PARTITION BY DEPTNO ORDER BY SAL) AS PERCENT_RANK FROM EMP; PERCENT_RANK ------------ 0 .5 1 0 .25 .5 .75 .75 0 .2 .2 .6 .8 1 14 rows selected.
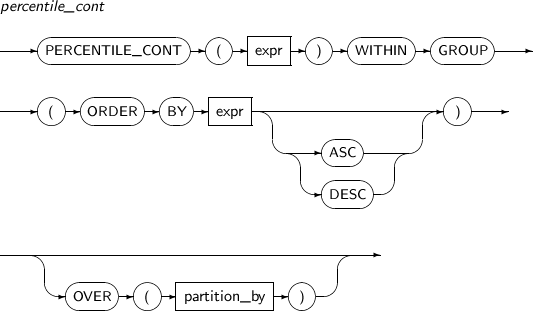
PERCENTILE_CONT는 연속 분포 모델에서 파라미터로 주어진 백분위 값에 해당하는 값을 계산하는 역분포 함수이다. 분석 함수로도 사용할 수 있다. 계산을 할 때 NULL 값은 무시한다.
파라미터의 표현식의 값은 백분위 값으로 그룹 내에서 0에서 1사이의 상수여야 한다. ORDER BY 절의 표현식은 보간을 계산할 수 있는 수치 또는 날짜형의 데이터 타입이어야 한다.
PERCENTILE_CONT는 정렬 스펙에 맞게 정렬한 후 보간법에 따라 계산한다. 이를 위해 다음과 같이 RN, CRN, FRN 값을 계산한다.
RN=(1+(P*(N-1))) CRN=CEILING(RN) FRN=FLOOR(RN)
| 구분 | 설명 |
|---|---|
| P | 파라미터로 주어진 백분위 값이다. |
| N | 그룹 내의 NULL이 아닌 로우의 개수이다. |
최종 결과는 CRN과 FRN이 같다면 RN번째 행의 expr의 값이고, 다르다면 다음과 같이 계산한다.
(CRN-RN) * (value of expr at FRN) + (RN-FRN) * (value of expr at CRN)
PERCENTILE_CONT의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 expr 수치 값을 반환하는 임의의 연산식이다. ASC
DESC
-
ORDER BY ASC는 결과를 오름차순으로 정렬한다. (기본값)
-
ORDER BY DESC는 결과를 내림차순으로 정렬한다.
partition_by 현재 질의 블록의 결과 집합을 expr 또는 expr의 리스트를 기준으로 분할한다.
자세한 내용은 “4.1.3. 분석 함수”의 partition_by를 참고한다.
-
-
예제
다음은 PERCENTILE_CONT 함수를 사용하는 예이다.
SQL> SELECT DEPTNO, PERCENTILE_CONT(0.35) WITHIN GROUP (ORDER BY SAL) FROM EMP GROUP BY DEPTNO; DEPTNO PERCENTILE_CONT(0.35)WITHINGRO ---------- ------------------------------- 10 2105 20 1850 30 1250 3 rows selected. -
분석 함수 예제
다음은 PERCENTILE_CONT 함수를 분석 함수로 사용하는 예이다.
SQL> SELECT DEPTNO, EMPNO, PERCENTILE_CONT(0.35) WITHIN GROUP (ORDER BY SAL) OVER (PARTITION BY DEPTNO) FROM EMP; DEPTNO EMPNO PERCENTILE_CONT(0.35)WITHINGRO ---------- ---------- ------------------------------- 10 7934 2105 10 7782 2105 10 7839 2105 20 7369 1850 20 7876 1850 20 7566 1850 20 7788 1850 20 7902 1850 30 7900 1250 30 7521 1250 30 7654 1250 30 7844 1250 30 7499 1250 30 7698 1250 14 rows selected.
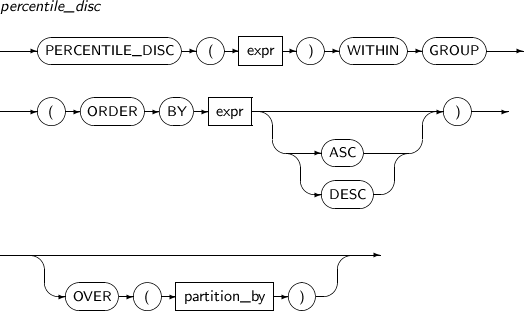
PERCENTILE_DISC는 이산 분포를 가정한 역분산 함수로 분석 함수로도 사용할 수 있다. 계산을 할 때 NULL 값은 무시한다.
파라미터의 표현식의 값은 백분위 값으로 그룹 내에서 0 ~ 1사이의 상수이어야 한다. ORDER BY 절로 정렬을 할 수 있는 타입이어야 한다.
PERCENTILE_DISC의 값을 계산하기 위해 다음과 같이 RN을 계산한다. 계산된 결과 값은 CRN에 해당하는 행의 expr 값이다.
RN=N*P CRN=CEILING(RN)
PERCENTILE_DISC의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 expr 수치 값을 반환하는 임의의 연산식이다. ASC
DESC
-
ORDER BY ASC는 결과를 오름차순으로 정렬한다. (기본값)
-
ORDER BY DESC는 결과를 내림차순으로 정렬한다.
partition_by 현재 질의 블록의 결과 집합을 expr 또는 expr의 리스트를 기준으로 분할한다.
자세한 내용은 “4.1.3. 분석 함수”의 partition_by를 참고한다.
-
-
예제
다음은 PERCENTILE_DISC 함수를 사용하는 예이다.
SQL> SELECT DEPTNO, PERCENTILE_DISC(0.15) WITHIN GROUP (ORDER BY SAL) AS PERCENTILE_DISC FROM EMP GROUP BY DEPTNO; DEPTNO PERCENTILE_DISC ---------- --------------- 10 1300 20 800 30 950 3 rows selected. -
분석 함수 예제
다음은 PERCENTILE_DISC 함수를 분석 함수로 사용하는 예이다.
SQL> SELECT DEPTNO, PERCENTILE_DISC(0.15) WITHIN GROUP (ORDER BY SAL) OVER (PARTITION BY DEPTNO) AS PERCENTILE_DISC FROM EMP; DEPTNO PERCENTILE_DISC ---------- --------------- 10 1300 10 1300 10 1300 20 800 20 800 20 800 20 800 20 800 30 950 30 950 30 950 30 950 30 950 30 950 14 rows selected.
POWER는 num1의 num2 제곱 값(num1num2)을 반환하는 함수이다.
POWER의 세부 내용은 다음과 같다.
-
문법
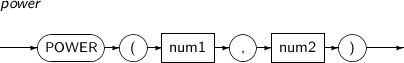
-
구성요소
구성요소 설명 num1, num2 수치 값을 반환하는 임의의 연산식이다.
num1이 음수인 경우 num2는 정수이어야 한다.
-
예제
다음은 POWER 함수를 사용하는 예이다.
SQL> SELECT POWER(2, 3) FROM DUAL; POWER(2,3) ---------- 8 1 row selected.
RANK는 그룹별로 로우를 정렬한 후 그룹 내의 각 로우의 순위를 반환하는 함수이다. 분석 함수로도 사용할 수 있다.
순위의 데이터 타입은 NUMBER이다. 순위를 산정할 때 동률이 나타났을 경우는 동률인 모든 로우에 대해 같은 순위가 부여된다. 그 다음 부여되는 순위는 같은 순위가 부여된 로우의 개수만큼 증가된 값이 부여된다. 따라서 순위는 연속된 숫자가 아닐 수도 있다.
계산 방법은 다음과 같이 함수에 따라 달라진다.
| 함수 | 설명 |
|---|---|
| 집계 함수 | 파라미터 값으로 구성된 가상의 로우에 대한 순위 값을 계산하다. 파라미터는 각 그룹마다 상수 값을 가져야 하며 order_by_clause의 표현식과 대응되어야 한다. |
| 분석 함수 | 각 로우의 그룹 내 순위를 반환한다. 순위는 order_by_clause 내의 expr 값을 기준으로 정렬한 결과가 부여된다. |
RANK의 세부 내용은 다음과 같다.
-
문법


-
구성요소
구성요소 설명 expr 수치 값을 반환하는 임의의 연산식이다. ASC
DESC
-
ORDER BY ASC는 결과를 오름차순으로 정렬한다. (기본값)
-
ORDER BY DESC는 결과를 내림차순으로 정렬한다.
partition_by 현재 질의 블록의 결과 집합을 expr 또는 expr의 리스트를 기준으로 분할한다.
자세한 내용은 “4.1.3. 분석 함수”의 partition_by를 참고한다.
-
-
예제
다음은 RANK 함수를 사용하는 예이다.
SQL> SELECT DEPTNO, RANK(3000) WITHIN GROUP (ORDER BY SAL) AS RANK FROM EMP GROUP BY DEPTNO; DEPTNO RANK ---------- ---------- 10 3 20 4 30 7 3 rows selected. -
분석 함수 예제
다음은 RANK 함수를 분석 함수로 사용하는 예이다.
SQL> SELECT NAME, DEPTID, SALARY, RANK() OVER (PARTITION BY DEPTID ORDER BY SALARY) FROM EMP; NAME DEPTID SALARY RANK()OVER -------------------- ---------- ---------- ---------- Paul 1 3000 1 Angela 1 3000 1 Nick 1 3200 3 Scott 1 4000 4 James 1 4000 4 John 1 4500 6 Joe 2 4000 1 Brad 2 4200 2 Daniel 2 5000 3 Tom 2 5000 3 Kathy 2 5000 3 Bree 2 6000 6 12 rows selected.
RATIO_TO_REPORT는 값의 집합의 합에 대한 집합 하나의 값의 비율을 계산하는 분석 함수이다. 이 함수는 expr 값이 NULL이면 반환값 역시 NULL이다.
값의 집합은 partition_by에 의해 결정된다. partition_by의 값을 명시하지 않으면 질의 결과로 반환된 모든 행을 대상으로 계산을 실행한다.
RATIO_TO_REPORT의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr expr은 수치 값을 반환하는 임의의 연산식이다.
expr에 RATIO_TO_REPORT 함수를 포함한 다른 분석 함수를 명시할 수 없다. 즉, 분석 함수를 중첩할 수 없다. 그러나 다른 내장 함수는 expr에 명시할 수 있다.
partition_by 현재 질의 블록의 결과 집합을 expr 또는 expr의 리스트를 기준으로 분할한다.
자세한 내용은 “4.1.3. 분석 함수”의 partition_by를 참고한다.
-
예제
다음은 RATIO_TO_REPORT 함수를 사용하는 예이다.
SQL> SELECT TYPE, AMOUNT, RATIO_TO_REPORT(AMOUNT) OVER () RATIO FROM ASSETS; TYPE AMOUNT RATIO -------------------- ---------- ---------- funds 200 .1 stock 500 .25 real_estate 1000 .5 cash 300 .15 4 rows selected.
RAWTOHEX는 문자열 raw 값을 16진수로 표현된 VARCHAR2 타입의 문자열로 바꾸는 함수이다.
RAWTOHEX의 세부 내용은 다음과 같다.
-
문법
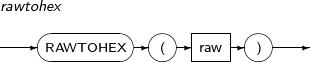
-
구성요소
구성요소 설명 raw 문자열 값을 반환하는 임의의 연산식이다. 단, CLOB, BLOB, LONG, LONG RAW, XMLTYPE, GEOMETRY 등의 타입은 사용할 수 없다.
-
예제
다음은 RAWTOHEX 함수를 사용하는 예이다.
SQL> SELECT RAWTOHEX('AB') FROM DUAL; RAWTOHEX('AB') -------------- 4142 1 row selected.
REGEXP_COUNT는 입력 문자열 내에서 정규표현식으로 주어진 패턴이 몇 번이나 일치하는지 반환하는 함수이다.
REGEXP_COUNT의 세부 내용은 다음과 같다.
-
문법
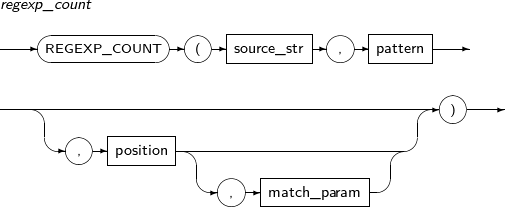
-
구성요소
구성요소 설명 source_str 문자열을 반환하는 임의의 연산식이다.
CHAR, VARCHAR2, NCHAR, NVARCHAR2 타입을 사용할 수 있다.
pattern 정규표현식으로 작성된 문자열을 반환하는 임의의 연산식이다.
CHAR, VARCHAR2, NCHAR, NVARCHAR2 타입을 사용할 수 있고, 만약 source_str과 타입이 다를 경우 source_str 타입으로 변환된다.
position 숫자값을 반환하는 임의의 연산식으로 패턴검사를 시작할 위치를 지정한다.
(기본값: 1)
match_param 문자열을 반환하는 임의의 연산식으로 패턴을 어떤 방법으로 검사할지를 지정한다. 여러 개를 동시에 지정할 수 있다.
다음과 같은 값을 사용할 수 있다.
-
'i': 대소문자를 구분하지 않는다.
-
'c': 대소문자를 구분한다.
-
'n': 점(.)이 줄바꿈 문자도 포함한다.
-
'm': 입력문자열이 한줄 이상이다.
-
'x': pattern의 공백문자를 무시한다.
예를 들어 'ic'와 같이 상호충돌하는 값을 지정하였을 경우엔 마지막 값만 사용한다. 즉, 'ic'는 대소문자를 구분한다.
-
-
예제
다음은 REGEXP_COUNT 함수를 사용하는 예이다.
SQL> SELECT REGEXP_COUNT('abcabcabc','abc', 2) FROM DUAL; REGEXP_COUNT('ABCABCABC','ABC',2) --------------------------------- 2 1 row selected.
REGEXP_INSTR는 입력 문자열 내에서 정규표현식으로 주어진 패턴이 일치하는지 위치를 반환하는 함수이다. 만약 입력 문자열과 일치하지 않으면 0을 반환한다.
REGEXP_INSTR의 세부 내용은 다음과 같다.
-
문법
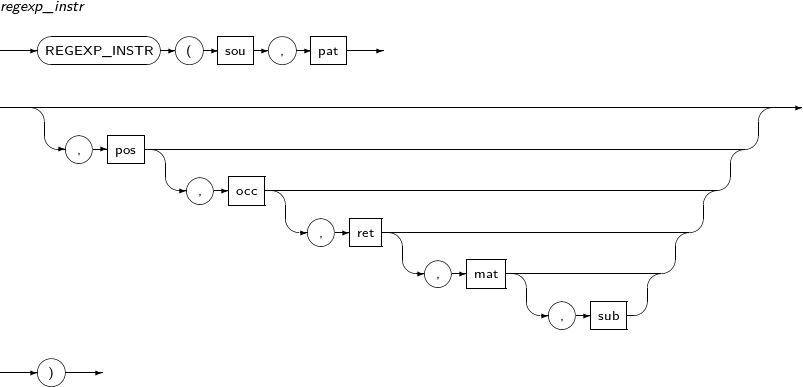
-
구성요소
구성요소 설명 sou
(source_str)
문자열을 반환하는 임의의 연산식이다.
CHAR, VARCHAR2, NCHAR, NVARCHAR2 타입을 사용할 수 있다.
pat
(pattern)
정규표현식으로 작성된 문자열을 반환하는 임의의 연산식이다.
CHAR, VARCHAR2, NCHAR, NVARCHAR2 타입을 사용할 수 있고, 만약 source_str과 타입이 다를 경우 source_str 타입으로 변환된다.
pos
(position)
숫자값을 반환하는 임의의 연산식으로 패턴검사를 시작할 위치를 지정한다.
(기본값: 1)
occ
(occurrence)
숫자값을 반환하는 임의의 연산식으로 패턴을 몇번 검사할지를 지정한다.
(기본값: 1)
ret
(return_option)
숫자값을 반환하는 임의의 연산식이다.
-
0: 패턴과 일치하는 문자열의 처음 위치를 반환한다. (기본값)
-
1: 패턴과 일치하는 문자열 다음 문자의 위치를 반환한다.
mat
(match_param)
문자열을 반환하는 임의의 연산식으로 패턴을 어떤 방법으로 검사할지를 지정한다. REGEXP_COUNT 함수와 같은 특성을 가진다. sub
(sub_expr)
숫자값을 반환하는 임의의 연산식으로 0부터 9까지 사용할 수 있다. (기본값: 0)
sub_expr은 pattern에서 괄호로 감싸진 각 그룹들을 왼쪽부터 숫자로 지정한다.
예를 들어 '(tibero(is(a)(rdbms)))'와 같은 정규표현식이 주어졌을 때 모두 4개의 그룹이 존재하고, 왼쪽부터 "tiberoisardbms", "isardbms", "a", "rdbms"이며 각 1, 2, 3, 4에 해당된다.
-
-
예제
다음은 REGEXP_INSTR 함수를 사용하는 예이다.
SQL> SELECT REGEXP_INSTR('abcabcabc','abc', 2) FROM DUAL; REGEXP_INSTR('ABCABCABC','ABC',2) --------------------------------- 4 1 row selected.
REGEXP_REPLACE는 입력 문자열내에서 정규표현식으로 주어진 패턴을 탐색하여 다른 문자열로 대치하는 함수이다.
REGEXP_REPLACE의 세부 내용은 다음과 같다.
-
문법
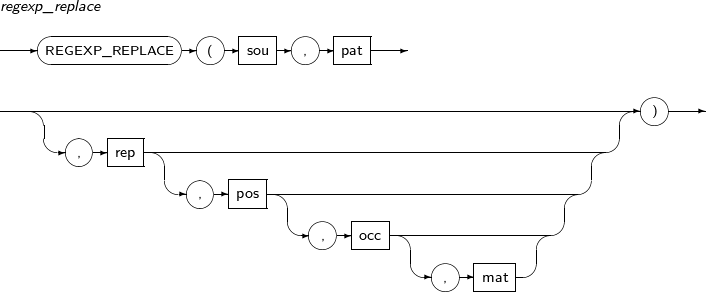
-
구성요소
구성요소 설명 sou
(source_str)
문자열을 반환하는 임의의 연산식이다.
CHAR, VARCHAR2, NCHAR, NVARCHAR2 타입을 사용할 수 있다.
pat
(pattern)
정규표현식으로 작성된 문자열을 반환하는 임의의 연산식이다.
CHAR, VARCHAR2, NCHAR, NVARCHAR2 타입을 사용할 수 있고, 만약 source_str과 타입이 다를 경우 source_str 타입으로 변환된다.
rep
(replace_str)
문자열을 반환하는 임의의 연산식이다.
CHAR, VARCHAR2, NCHAR, NVARCHAR2 타입을 사용할 수 있고, 만약 source_str과 타입이 다를 경우 source_str 타입으로 변환된다.
pos
(position)
숫자값을 반환하는 임의의 연산식으로 패턴검사를 시작할 위치를 지정한다.
(기본값: 1)
occ
(occurrence)
숫자값을 반환하는 임의의 연산식으로 패턴을 몇번 검사할지를 지정한다.
(기본값: 1)
mat
(match_param)
문자열을 반환하는 임의의 연산식으로 패턴을 어떤 방법으로 검사할지를 지정한다. REGEXP_COUNT 함수와 같은 특성을 가진다. -
예제
다음은 REGEXP_REPLACE 함수를 사용하는 예이다.
SQL> SELECT REGEXP_REPLACE('aaaaaaa','([[:alpha:]])', 'x') FROM DUAL; REGEXP_REPLACE('AAAAAAA','([[:ALPHA:]])','X') --------------------------------------------- xxxxxxx 1 row selected.
REGEXP_SUBSTR는 입력 문자열내에서 정규표현식으로 주어진 패턴을 탐색하여 해당 문자열을 반환하는 함수이다.
REGEXP_SUBSTR의 세부 내용은 다음과 같다.
-
문법
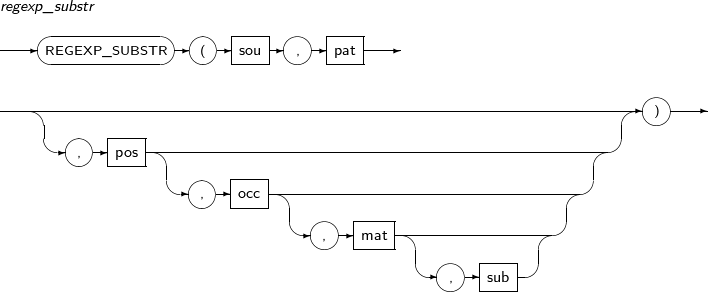
-
구성요소
구성요소 설명 sou
(source_str)
문자열을 반환하는 임의의 연산식이다.
CHAR, VARCHAR2, NCHAR, NVARCHAR2 타입을 사용할 수 있다.
pat
(pattern)
정규표현식으로 작성된 문자열을 반환하는 임의의 연산식이다.
CHAR, VARCHAR2, NCHAR, NVARCHAR2 타입을 사용할 수 있고, 만약 source_str과 타입이 다를 경우 source_str 타입으로 변환된다.
pos
(position)
숫자값을 반환하는 임의의 연산식으로 패턴검사를 시작할 위치를 지정한다.
(기본값: 1)
occ
(occurrence)
숫자값을 반환하는 임의의 연산식으로 패턴을 몇번 검사할지를 지정한다.
(기본값: 1)
mat
(match_param)
문자열을 반환하는 임의의 연산식으로 패턴을 어떤 방법으로 검사할지를 지정한다. REGEXP_COUNT 함수와 같은 특성을 가진다. sub
(sub_expr)
숫자값을 반환하는 임의의 연산식으로 0부터 9까지 사용할 수 있다. (기본값: 0)
REGEXP_INSTR 함수와 같은 특성을 가진다.
-
예제
다음은 REGEXP_SUBSTR 함수를 사용하는 예이다.
SQL> SELECT REGEXP_SUBSTR('123456','3.*5', 1) FROM DUAL; REGEXP_SUBSTR('123456','3.*5',1) -------------------------------- 345 1 row selected.
REGR_AVGX는 임의의 수치 데이터 쌍의 집합에 가장 맞는 선형 방정식을 구하는 함수로, 집합 함수와 분석 함수로 사용된다.
입력으로 숫자 데이터 또는 숫자 데이터로 변환 가능한 데이터형을 갖는다. 인자로 받은 종속변수(expr1) 또는 독립변수(expr2)의 값이 NULL이면 계산에서 제외되며 모든 로우가 NULL의 쌍이면 NULL을 결과로 낸다.
REGR_AVGX는 독립변수(expr2)의 평균을 계산하는 함수이다. 즉, NULL의 쌍을 제거한 후에 "AVG(expr2)"를 계산한다.
REGR_AVGX의 세부 내용은 다음과 같다.
-
문법
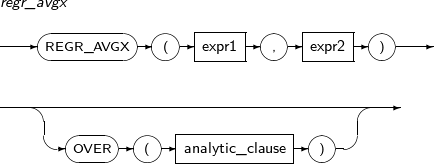
-
구성요소
구성요소 설명 expr1 수치 값을 반환하는 임의의 연산식이다. 종속변수에 해당한다. expr2 수치 값을 반환하는 임의의 연산식이다. 독립변수에 해당한다. -
예제
다음은 함수를 사용하는 예이다.
SQL> SELECT * FROM XY; X Y ---------- ---------- 1 1 2 3 2 rows selected. SQL> SELECT REGR_AVGX(Y,X) FROM XY; REGR_AVGX(Y,X) -------------- 1.5 1 row selected.
REGR_AVGX는 임의의 수치 데이터 쌍의 집합에 가장 맞는 선형 방정식을 구하는 함수로, 집합 함수와 분석 함수로 사용된다.
입력으로 숫자 데이터 또는 숫자 데이터로 변환 가능한 데이터형을 갖는다. 인자로 받은 종속변수(expr1) 또는 독립변수(expr2)의 값이 NULL이면 계산에서 제외되며 모든 로우가 NULL의 쌍이면 NULL을 결과로 낸다.
REGR_AVGY는 종속변수(expr1)의 평균을 계산하는 함수이다. 즉, NULL의 쌍을 제거한 후에 "AVG(expr1)"를 계산한다.
REGR_AVGY의 세부 내용은 다음과 같다.
-
문법
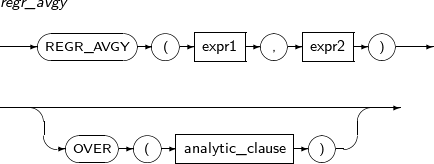
-
구성요소
구성요소 설명 expr1 수치 값을 반환하는 임의의 연산식이다. 종속변수에 해당한다. expr2 수치 값을 반환하는 임의의 연산식이다. 독립변수에 해당한다. -
예제
다음은 함수를 사용하는 예이다.
SQL> SELECT * FROM XY; X Y ---------- ---------- 1 1 2 3 2 rows selected. SQL> SELECT REGR_AVGY(Y,X) FROM XY; REGR_AVGY(Y,X) -------------- 2 1 row selected.
REGR_COUNT는 임의의 수치 데이터 쌍의 집합에 가장 맞는 선형 방정식을 구하는 함수로, 집합 함수와 분석 함수로 사용된다.
입력으로 숫자 데이터 또는 숫자 데이터로 변환 가능한 데이터형을 갖는다. 인자로 받은 종속변수(expr1) 또는 독립변수(expr2)의 값이 NULL이면 계산에서 제외되며 모든 로우가 NULL의 쌍이면 NULL을 결과로 낸다.
REGR_COUNT는 회귀 직선을 구성하는데 사용된 NULL이 아닌 (expr1, expr2) 쌍의 계수를 반환한다.
REGR_COUNT의 세부 내용은 다음과 같다.
-
문법
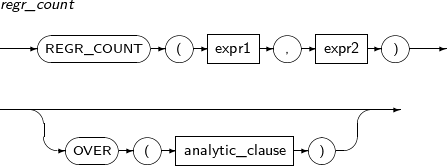
-
구성요소
구성요소 설명 expr1 수치 값을 반환하는 임의의 연산식이다. 종속변수에 해당한다. expr2 수치 값을 반환하는 임의의 연산식이다. 독립변수에 해당한다. -
예제
다음은 함수를 사용하는 예이다.
SQL> SELECT * FROM XY; X Y ---------- ---------- 1 1 2 3 2 rows selected. SQL> SELECT REGR_COUNT(Y,X) FROM XY; REGR_COUNT(Y,X) --------------- 2 1 row selected.
REGR_INTERCEPT는 임의의 수치 데이터 쌍의 집합에 가장 맞는 선형 방정식을 구하기 위해 사용되는 함수, 집합 함수와 분석 함수로 사용된다.
입력으로 숫자 데이터 또는 숫자 데이터로 변환 가능한 데이터형을 갖는다. 인자로 받은 종속변수(expr1) 또는 독립변수(expr2)의 값이 NULL이면 계산에서 제외되며 모든 로우가 NULL의 쌍이면 NULL을 결과로 낸다.
REGR_INTERCEPT는 회귀 직선의 Y 절편을 계산해서 다음의 결과를 반환한다.
AVG(exr1) - REGR_SLOPE(expr1, expr2) × AVG(expr2)
이때 REGR_SLOPE의 결과가 NULL이면 최종 결과는 NULL이 된다.
REGR_INTERCEPT의 세부 내용은 다음과 같다.
-
문법
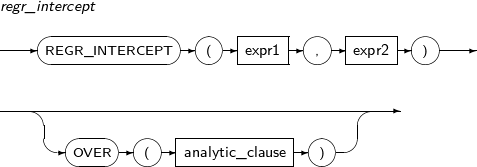
-
구성요소
구성요소 설명 expr1 수치 값을 반환하는 임의의 연산식이다. 종속변수에 해당한다. expr2 수치 값을 반환하는 임의의 연산식이다. 독립변수에 해당한다. -
예제
다음은 함수를 사용하는 예이다.
SQL> SELECT * FROM XY; X Y ---------- ---------- 1 1 2 3 2 rows selected. SQL> SELECT REGR_INTERCEPT(Y,X) FROM XY; REGR_INTERCEPT(Y,X) ------------------- -1 1 row selected.
REGR_R2는 임의의 수치 데이터 쌍의 집합에 가장 맞는 선형 방정식을 구하는 함수로, 집합 함수와 분석 함수로 사용된다.
입력으로 숫자 데이터 또는 숫자 데이터로 변환 가능한 데이터형을 갖는다. 인자로 받은 종속변수(expr1) 또는 독립변수(expr2)의 값이 NULL이면 계산에서 제외되며 모든 로우가 NULL의 쌍이면 NULL을 결과로 낸다.
REGR_R2는 회귀에 대한 결정 계수(R-squared 또는 적합도)를 계산하는 함수로 VAR_POP(expr1)과 VAR_POP(expr2)의 값에 따라 아래와 같은 계산식을 이용한다.
-
VAR_POP(expr2) = 0이면 : NULL
-
VAR_POP(expr1) = 0이고 VAR_POP(expr2) > 0이면 : 1
-
VAR_POP(expr1) > 0이고 VAR_POP(expr2) > 0이면 : POWER(CORR(expr1, expr2),2)
REGR_R2의 세부 내용은 다음과 같다.
-
문법
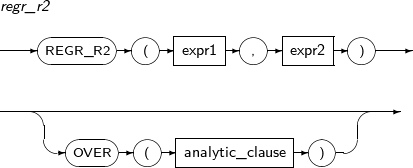
-
구성요소
구성요소 설명 expr1 수치 값을 반환하는 임의의 연산식이다. 종속변수에 해당한다. expr2 수치 값을 반환하는 임의의 연산식이다. 독립변수에 해당한다. -
예제
다음은 함수를 사용하는 예이다.
SQL> SELECT * FROM XY; X Y ---------- ---------- 1 1 2 3 2 rows selected. SQL> SELECT REGR_R2(Y,X) FROM XY; REGR_R2(Y,X) ------------ 1 1 row selected.
REGR_SLOPE는 임의의 수치 데이터 쌍의 집합에 가장 맞는 선형 방정식을 구하는 함수로, 집합함수와 분석함수로 사용된다.
입력으로 숫자 데이터 또는 숫자 데이터로 변환 가능한 데이터형을 갖는다. 인자로 받은 종속변수(expr1) 또는 독립변수(expr2)의 값이 NULL이면 계산에서 제외되며 모든 로우가 NULL의 쌍이면 NULL을 결과로 낸다.
REGR_SLOPE는 다음의 공식으로 회귀 직선(Regression Line)의 기울기를 계산해서 결과를 반환한다.
COVAR_POP(expr1, expr2) / VAR_POP(expr2)
이때 VAR_POP의 결과가 0이면 최종 결과는 NULL이 된다.
REGR_SLOPE의 세부 내용은 다음과 같다.
-
문법
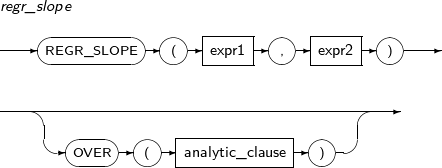
-
구성요소
구성요소 설명 expr1 수치 값을 반환하는 임의의 연산식이다. 종속변수에 해당한다. expr2 수치 값을 반환하는 임의의 연산식이다. 독립변수에 해당한다. -
예제
다음은 함수를 사용하는 예이다.
SQL> SELECT * FROM XY; X Y ---------- ---------- 1 1 2 3 2 rows selected. SQL> SELECT REGR_SLOPE(Y,X) FROM XY; REGR_SLOPE(Y,X) --------------- 2 1 row selected. SQL> SELECT REGR_SLOPE(X,Y) FROM XY; REGR_SLOPE(X,Y) --------------- .5 1 row selected.
REGR_SXX는 임의의 수치 데이터 쌍의 집합에 가장 맞는 선형 방정식을 구하는 함수로, 집합 함수와 분석 함수로 사용된다.
입력으로 숫자 데이터 또는 숫자 데이터로 변환 가능한 데이터형을 갖는다. 인자로 받은 종속변수(expr1) 또는 독립변수(expr2)의 값이 NULL이면 계산에서 제외되며 모든 로우가 NULL의 쌍이면 NULL을 결과로 낸다.
REGR_SXX는 다음의 계산식으로 회귀 분석을 위한 진단 통계를 계산하는데 사용하는 보조 함수이다.
REGR_COUNT(expr1, expr2) × VAR_POP(expr2)
REGR_SXX의 세부 내용은 다음과 같다.
-
문법
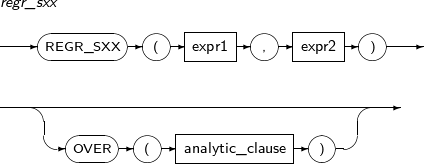
-
구성요소
구성요소 설명 expr1 수치 값을 반환하는 임의의 연산식이다. 종속변수에 해당한다. expr2 수치 값을 반환하는 임의의 연산식이다. 독립변수에 해당한다. -
예제
다음은 함수를 사용하는 예이다.
SQL> SELECT * FROM XY; X Y ---------- ---------- 1 1 2 3 2 rows selected. SQL> SELECT REGR_SXX(Y,X) FROM XY; REGR_SXX(Y,X) ------------- .5 1 row selected.
REGR_SXY는 임의의 수치 데이터 쌍의 집합에 가장 맞는 선형 방정식을 구하는 함수로, 집합 함수와 분석 함수로 사용된다.
입력으로 숫자 데이터 또는 숫자 데이터로 변환 가능한 데이터형을 갖는다. 인자로 받은 종속변수(expr1) 또는 독립변수(expr2)의 값이 NULL이면 계산에서 제외되며 모든 로우가 NULL의 쌍이면 NULL을 결과로 낸다.
REGR_SXY는 회귀 분석을 위한 진단 통계를 계산하는데 사용하는 보조 함수이다. 계산식은 다음과 같다.
REGR_COUNT(expr1, expr2) × COVAR_POP(expr1, expr2)
REGR_SXY의 세부 내용은 다음과 같다.
-
문법
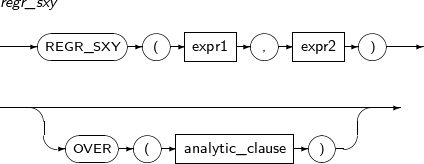
-
구성요소
구성요소 설명 expr1 수치 값을 반환하는 임의의 연산식이다. 종속변수에 해당한다. expr2 수치 값을 반환하는 임의의 연산식이다. 독립변수에 해당한다. -
예제
다음은 함수를 사용하는 예이다.
SQL> SELECT * FROM XY; X Y ---------- ---------- 1 1 2 3 2 rows selected. SQL> SELECT REGR_SXY(Y,X) FROM XY; REGR_SXY(Y,X) ------------- 1 1 row selected.
REGR_SYY는 임의의 수치 데이터 쌍의 집합에 가장 맞는 선형 방정식을 구하는 함수로, 집합 함수와 분석 함수로 사용된다.
입력으로 숫자 데이터 또는 숫자 데이터로 변환 가능한 데이터형을 갖는다. 인자로 받은 종속변수(expr1) 또는 독립변수(expr2)의 값이 NULL이면 계산에서 제외되며 모든 로우가 NULL의 쌍이면 NULL을 결과로 낸다. REGR_SYY는 회귀 분석을 위한 진단 통계를 계산하는데 사용하는 보조 함수이다.
계산식은 다음과 같다.
REGR_COUNT(expr1, expr2) × VAR_POP(expr1)
REGR_SYY의 세부 내용은 다음과 같다.
-
문법
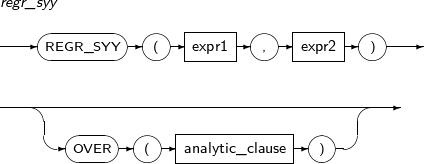
-
구성요소
구성요소 설명 expr1 수치 값을 반환하는 임의의 연산식이다. 종속변수에 해당한다. expr2 수치 값을 반환하는 임의의 연산식이다. 독립변수에 해당한다. -
예제
다음은 함수를 사용하는 예이다.
SQL> SELECT * FROM XY; X Y ---------- ---------- 1 1 2 3 2 rows selected. SQL> SELECT REGR_SYY(Y,X) FROM XY; REGR_SYY(Y,X) ------------- 2 1 row selected.
REMAINDER은 num1을 num2로 나눈 나머지를 반환하는 함수이다.
REMAINDER의 세부 내용은 다음과 같다.
-
문법
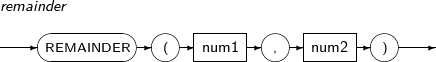
-
구성요소
구성요소 설명 num1, num2 num1이나 num2는 숫자형 타입이거나 숫자형 타입으로 변환될 수 있는 타입이어야 한다. -
예제
다음은 REMAINDER 함수를 사용하는 예이다.
SQL> SELECT REMAINDER(3, 2) FROM DUAL; REMAINDER(3,2) -------------- -1 1 row selected.
REPLACE는 문자열 str 내에서 문자열 substr을 탐색하여 문자열 replace_str로 치환하는 함수이다.
REPLACE의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다. substr 문자열을 반환하는 임의의 연산식이다. 만약 substr이 NULL이면 str을 그대로 반환한다. replace_str 문자열을 반환하는 임의의 연산식이다. 만약 replace_str이 NULL이거나 지정되지 않으면, str 내의 모든 substr은 제거된다. -
예제
다음은 REPLACE 함수를 사용하는 예이다.
SQL> SELECT REPLACE('ABCDEFG', 'CD') FROM DUAL; REPLACE('ABCDEFG','CD') ----------------------- ABEFG 1 row selected. SQL> SELECT REPLACE('ABCDEFG', 'CD', 'XY') FROM DUAL; REPLACE('ABCDEFG','CD','XY') ---------------------------- ABXYEFG 1 row selected.
REVERSE는 주어진 문자열을 거꾸로 출력하는 함수이다.
REVERSE의 세부 내용은 다음과 같다.
-
문법
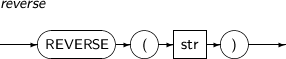
-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다. -
예제
다음은 REVERSE 함수를 사용하는 예이다.
SQL> SELECT REVERSE('TIBERO') FROM DUAL; REVERSE('TIBERO') ----------------- OREBIT 1 row selected.
ROUND(number)는 num1을 소수점 아래 num2+1 위치에서 반올림한 값을 반환하는 함수이다.
ROUND(number)의 세부 내용은 다음과 같다.
-
문법
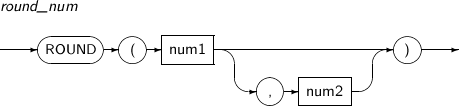
-
구성요소
구성요소 설명 num1 수치 값을 반환하는 임의의 연산식이다. num2 수치 값을 반환하는 임의의 연산식이다.
num2는 정수가 되어야 한다. 만약 num2가 지정되지 않았거나 0이면 소수점 첫째 자리에서 반올림한다.
num2가 음수이면 소수점 위의 자리에서 반올림한다.
-
예제
다음은 ROUND(number) 함수를 사용하는 예이다.
SQL> SELECT ROUND(345.678), ROUND(345.678, 2), ROUND(345.678, -1) FROM DUAL; ROUND(345.678) ROUND(345.678,2) ROUND(345.678,-1) -------------- ---------------- ----------------- 346 345.68 350 1 row selected.
ROUND(date)는 date를 format에 명시된 단위로 반올림한 결과를 반환하는 함수이다.
ROUND(date)의 세부 내용은 다음과 같다.
-
문법
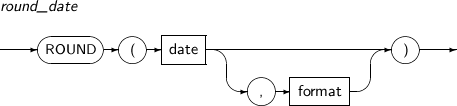
-
구성요소
구성요소 설명 date 날짜를 반환하는 임의의 연산식이다. format 반올림 단위를 명시하는 포맷 모델을 나타내는 문자열이다.
format이 명시되지 않으면 'DD' 형식의 문자열을 이용하여 가장 가까운 날로 반올림한다. format으로 'YEAR', 'MONTH', 'DAY' 등을 사용할 수 있다.
ROUND(date) 함수의 format에 명시할 수 있는 형식 문자열은 다음과 같다.
-
CC, SCC : year 4자리 중 아래 2자리로 반올림/버림 후 1년 큰 값이다. (예: xx01년)
-
IYYY, IYY, IY, I : ISO year 값에 대해 7월 1일 전/후로 반올림 또는 버림을 한다.
-
SYYYY, YYYY, YYY, YY, Y, YEAR, SYEAR : year 값에 대해 7월 1일 전/후로 반올림 또는 버림을 한다.
-
Q : 분기 값에 대해 각 분기의 두 번째 달의 16번째 날 전/후로 반올림 또는 버림을 한다.
-
MONTH, MON, MM, RM : month 값에 대해 16번째 날 전/후로 반올림 또는 버림을 한다.
-
WW : 그 해의 첫 번째 날(1월 1일)을 한 주의 시작으로 해서, week 값에 대해 반올림 또는 버림을 한다.
-
IW : 그 주의 월요일을 한 주의 시작으로 해서, week 값에 대해 반올림 또는 버림을 한다.
-
W : 그 달의 첫 번째 날(1일)과 같은 요일이 되도록 week 값에 대해 반올림 또는 버림을 한다.
-
DDD, DD, J : day 값에 대해 오후 12시 전/후로 반올림 또는 버림을 한다.
-
DAY, DY, D : week 값에 대해 수요일 오후 12시 전/후로 반올림 또는 버림을 한다.
-
HH24, HH12, HH : hour 값에 대해 30분 전/후로 반올림 또는 버림을 한다.
-
MI : minute 값에 대해 30초 전/후로 반올림 또는 버림을 한다.
-
-
예제
다음은 ROUND(date) 함수를 사용하는 예이다.
SQL> SELECT ROUND(TO_DATE('2005/06/22'), 'YEAR') AS TO_DATE FROM DUAL; TO_DATE -------------------------------- 2005/01/01 1 row selected. SQL> SELECT TO_CHAR(ROUND(TO_DATE('1998/6/20', 'YYYY/MM/DD'), 'CC'), 'YYYY/MM/DD') AS TO_DATE FROM DUAL; TO_DATE ---------- 2001/01/01 1 row selected. SQL> SELECT TO_CHAR(ROUND(TO_DATE('-3741/01/02', 'SYYYY/MM/DD'), 'CC'), 'SYYYY/MM/DD') AS TO_DATE FROM DUAL; TO_DATE ----------- -3700/01/01 1 row selected. SQL> SELECT TO_CHAR(ROUND(TO_DATE('2005/01/26 12:30:14', 'YYYY/MM/DD HH24:MI:SS'), 'DY'), 'YYYY/MM/DD') AS TO_DATE FROM DUAL; TO_DATE ---------- 2005/01/30 1 row selected. SQL> SELECT ROUND(TO_DATE('2005/01/26 12:30:14', 'YYYY/MM/DD HH24:MI:SS')) AS TO_DATE FROM DUAL; TO_DATE -------------------------------- 2005/01/27 1 row selected.
ROWIDTOCHAR는 ROWID의 값을 VARCHAR 타입의 값으로 변환하는 함수이다.
ROWIDTOCHAR의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 rowid VARCHAR 타입으로 변환할 값이다. -
예제
다음은 ROWIDTOCHAR 함수를 사용하는 예이다.
SQL> SELECT LAST_NAME FROM EMP WHERE ROWIDTOCHAR(ROWID) LIKE "%AAAF%'; LAST_NAME ---------- King 1 row selected.
ROW_NUMBER는 함수가 적용된 모든 로우(파티션의 모든 로우 또는 질의에 의해 반환되는 모든 로우)에 대하여 order_by_clause에 명시된 순서대로 1부터 시작되는 유일한 번호를 부여하는 분석 함수이다.
ROW_NUMBER 함수를 사용하여 top-N, bottom-N, inner-N 보고를 구현할 수 있다. 일관된 결과를 얻기 위해서는 질의는 결정된 정렬 순서를 보장하여야 한다.
ROW_NUMBER의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 partition_by 현재 질의 블록의 결과 집합을 expr 또는 expr의 리스트를 기준으로 분할한다.
자세한 내용은 “4.1.3. 분석 함수”의 partition_by를 참고한다.
order_by_clause 분할된 하나의 파티션 내에서 로우를 어떻게 정렬할지를 명시한다.
자세한 내용은 “4.1.3. 분석 함수”의 order_by_clause를 참고한다.
-
예제
다음은 ROW_NUMBER 함수를 사용하는 예이다.
SQL> SELECT JOB_ID, LAST_NAME, SALARY FROM ( SELECT JOB_ID, LAST_NAME, SALARY, ROW_NUMBER() OVER (PARTITION BY JOB_ID ORDER BY SALARY) RN FROM EMPLOYEES_DEMO ) WHERE RN <= 1; JOB_ID LAST_NAME SALARY ---------- ------------------------- ---------- AD_PRES King 24000 AD_VP Kochhar 17000 IT_PROG Ernst 6000 3 rows selected.
RPAD는 expr2를 expr1의 오른쪽에 반복적으로 붙인 길이가 num인 문자열을 구하는 함수이다.
대부분의 문자 집합에서는 반환되는 문자열의 문자의 수와 길이가 동일하지만, 한글과 같은 멀티 바이트 문자 집합의 경우에는 두 값이 다를 수 있다.
RPAD의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr1 문자열 또는 CLOB 타입, BLOB 타입을 반환하는 임의의 연산식이다.
expr1의 길이가 num 보다 크면, expr1에서 왼쪽부터 num 만큼의 문자열을 반환한다.
expr2 문자열 또는 CLOB 타입, BLOB 타입을 반환하는 임의의 연산식이다.
expr2가 명시되지 않으면 공백 문자가 사용된다.
num 수치 값을 반환하는 임의의 연산식이다.
num은 터미널에 출력되는 길이를 의미한다.
-
예제
다음은 RPAD 함수를 사용하는 예이다.
SQL> SELECT RPAD('RPAD', 10, '-=') FROM DUAL; RPAD('RPAD',10,'-=') -------------------- RPAD-=-=-= 1 row selected.
RTRIM은 문자열 str의 오른쪽으로부터 문자열 char_set 내에 포함된 모든 문자를 제거하는 함수이다.
RTRIM의 세부 내용은 다음과 같다.
-
문법
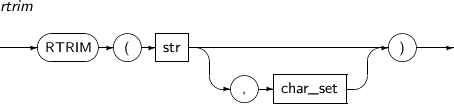
-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다. char_set 문자열을 반환하는 임의의 연산식이다.
만약 파라미터 char_set의 값이 없으면, 기본값으로 공백 문자 하나를 갖는다.
-
예제
다음은 RTRIM 함수를 사용하는 예이다.
SQL> SELECT RTRIM('ABCDE ') FROM DUAL; RTRIM('ABCDE') -------------- ABCDE 1 row selected. SQL> SELECT RTRIM('XYXABCDEXYX', 'XY') FROM DUAL; RTRIM('XYXABCDEXYX','XY') ------------------------- XYXABCDE 1 row selected.
SESSIONTIMEZONE는 현재 세션의 시간대를 출력하는 함수이다.
SESSIONTIMEZONE의 세부 내용은 다음과 같다.
-
문법

-
예제
다음은 SESSIONTIMEZONE 함수를 사용하는 예이다.
SQL> SELECT SESSIONTIMEZONE FROM DUAL; SESSIONTIMEZONE ------------------------- Asia/Seoul 1 row selected.
SIGN은 num이 음수이면 -1을 반환하고, 0이면 0을 양수이면 +1을 반환하는 함수이다.
SIGN의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 num 수치 값을 반환하는 임의의 연산식이다. -
예제
다음은 SIGN 함수를 사용하는 예이다.
SQL> SELECT SIGN(-10), SIGN(0), SIGN(15.5) FROM DUAL; SIGN(-10) SIGN(0) SIGN(15.5) ---------- ---------- ---------- -1 0 1 1 row selected.
SIN은 주어진 파라미터 값의 사인(sine) 값을 구한다.
SIN의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 num 실수 값을 반환하는 임의의 연산식이다. (단위: 라디안) -
예제
다음은 SIN 함수를 사용하는 예이다.
SQL> SELECT SIN(3.141592654 / 2.0) FROM DUAL; SIN(3.141592654/2.0) -------------------- 1 1 row selected.
SINH은 주어진 파라미터 값의 하이퍼볼릭 사인 값을 구하는 함수이다.
SINH의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 num 실수 값을 반환하는 임의의 연산식이다. (단위: 라디안) -
예제
다음은 SINH 함수를 사용하는 예이다.
SQL> SELECT SINH(1) FROM DUAL; SINH(1) ---------- 1.17520119 1 row selected.
SKEW는 expr의 왜도를 반환하는 함수이다. 이 함수는 모든 수치 데이터 타입과 수치 데이터 타입은 아니지만 묵시적으로 수치 데이터 타입으로 변환할 수 있는 데이터 타입을 파라미터로 받아 들인다. 입력된 파라미터의 수치 데이터 타입 또는 변환된 수치 데이터 타입을 반환한다.
SKEW의 세부 내용은 다음과 같다.
-
문법
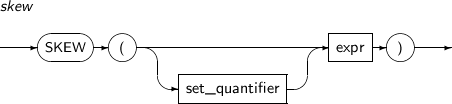
-
구성요소
구성요소 설명 set_quantifier 질의 결과에 중복된 로우의 허용, 비허용 여부를 지정한다. DISTINCT, UNIQUE, ALL을 지정할 수 있다.
-
DISTINCT, UNIQUE: 중복된 로우를 제거한다.
-
ALL: 모든 로우를 선택한다. (기본값)
expr 측정할 연산식을 명시한다. -
-
예제
다음은 SKEW 함수를 사용하는 예이다.
SQL> SELECT SKEW(SAL) FROM EMP; SKEW(SAL) ---------- 1.17469474 1 row selected.
SQRT는 주어진 파라미터 값의 제곱근(Square Root)을 구하는 함수이다.
SQRT의 세부 내용은 다음과 같다.
-
문법
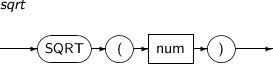
-
구성요소
구성요소 설명 num 0 이상의 실수 값을 반환하는 임의의 연산식이다. -
예제
다음은 SQRT 함수를 사용하는 예이다.
SQL> SELECT SQRT(2.0) FROM DUAL; SQRT(2.0) ---------- 1.41421356 1 row selected.
STDDEV는 expr의 표본 표준편차를 반환하는 함수이다. 분석 함수로도 사용할 수 있다. Tibero는 표준편차의 값을 VARIANCE 집합 함수 값의 제곱근으로 계산한다.
이 함수는 모든 수치 데이터 타입과 수치 데이터 타입은 아니지만 묵시적으로 수치 데이터 타입으로 변환할 수 있는 데이터 타입을 파라미터로 받아 들인다. 입력된 파라미터의 수치 데이터 타입 또는 변환된 수치 데이터 타입을 반환한다.
STDDEV_SAMP 함수와 STDDEV 함수의 차이점은 입력 데이터의 크기가 단 하나의 로우일 경우 STDDEV 함수는 0을 반환하는 반면 STDDEV_SAMP 함수는 NULL 값을 반환한다는 것이다.
STDDEV의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr 수치 값을 반환하는 임의의 연산식이다. analytic_clause OVER analytic_clause를 사용해 함수를 분석 함수로 수행할 수 있다.
자세한 내용은 “4.1.3. 분석 함수”의 analytic_clause를 참고한다.
-
예제
다음은 STDDEV 함수를 사용하는 예이다.
SQL> SELECT STDDEV(AGE) FROM EMP_AGE; STDDEV(AGE) ----------- 3.034981237 1 row selected.
-
분석 함수 예제
다음은 STDDEV 함수를 분석 함수로 사용하는 예이다.
SQL> SELECT DEPTNO, EMPNO, STDDEV(SAL) OVER (PARTITION BY DEPTNO) AS STDDEV FROM EMP; DEPTNO EMPNO STDDEV ---------- ---------- ---------- 10 7934 1893.62967 10 7839 1893.62967 10 7782 1893.62967 20 7566 1123.3321 20 7788 1123.3321 20 7876 1123.3321 20 7902 1123.3321 20 7369 1123.3321 30 7654 668.331255 30 7698 668.331255 30 7521 668.331255 30 7499 668.331255 30 7844 668.331255 30 7900 668.331255 14 rows selected.
STDDEV_POP는 expr의 모표준편차를 반환하는 함수이다. 분석 함수로도 사용할 수 있다. Tibero는 모표준편차의 값을 VARIANCE_POP 집합 함수 값의 제곱근으로 계산한다. 이 함수는 파라미터의 수치 데이터 타입 또는 변환된 수치 데이터 타입을 반환한다.
STDDEV_POP의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr 수치 데이터 타입 또는 수치 데이터 타입은 아니지만 묵시적으로 수치 데이터 타입으로 변환할 수 있는 데이터 타입을 갖는 임의의 연산식이다. analytic_clause OVER analytic_clause를 사용해 함수를 분석 함수로 수행할 수 있다.
자세한 내용은 “4.1.3. 분석 함수”의 analytic_clause를 참고한다.
-
예제
다음은 STDDEV_POP 함수를 사용하는 예이다.
SQL> SELECT STDDEV_POP(AGE) FROM EMP_AGE; STDDEV_POP(AGE) --------------- 2.8792360097776 1 row selected.
-
분석 함수 예제
다음은 STDDEV_POP 함수를 분석 함수로 사용하는 예이다.
SQL> SELECT DEPTNO, EMPNO, STDDEV_POP(SAL) OVER (PARTITION BY DEPTNO) AS STDDEV_POP FROM EMP; DEPTNO EMPNO STDDEV_POP ---------- ---------- ---------- 10 7934 1546.14215 10 7839 1546.14215 10 7782 1546.14215 20 7566 1004.73877 20 7788 1004.73877 20 7876 1004.73877 20 7902 1004.73877 20 7369 1004.73877 30 7654 610.100174 30 7698 610.100174 30 7521 610.100174 30 7499 610.100174 30 7844 610.100174 30 7900 610.100174 14 rows selected.
STDDEV_SAMP는 expr의 누적 표본 표준편차를 반환하는 함수이다. 분석 함수로도 사용할 수 있다. Tibero는 누적 표본 표준편차의 값을 VARIANCE_SAMP 집합 함수 값의 제곱근으로 계산한다. 이 함수는 파라미터의 수치 데이터 타입 또는 변환된 수치 데이터 타입을 반환한다.
STDDEV_SAMP의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr 수치 데이터 타입 또는 수치 데이터 타입은 아니지만 묵시적으로 수치 데이터 타입으로 변환할 수 있는 데이터 타입을 갖는 임의의 연산식이다. analytic_clause OVER analytic_clause를 사용해 함수를 분석 함수로 수행할 수 있다.
자세한 내용은 “4.1.3. 분석 함수”의 analytic_clause를 참고한다.
-
예제
다음은 STDDEV_SAMP 함수를 사용하는 예이다.
SQL> SELECT STDDEV_SAMP(AGE) FROM EMP_AGE; STDDEV_SAMP(AGE) ---------------- 3.03498123735734 1 row selected.
-
분석 함수 예제
다음은 STDDEV_SAMP 함수를 분석 함수로 사용하는 예이다.
SQL> SELECT DEPTNO, EMPNO, STDDEV_SAMP(SAL) OVER (PARTITION BY DEPTNO) AS STDDEV_SAMP FROM EMP; DEPTNO EMPNO STDDEV_SAMP ---------- ---------- ----------- 10 7782 1893.62967 10 7839 1893.62967 10 7934 1893.62967 20 7566 1123.3321 20 7902 1123.3321 20 7876 1123.3321 20 7369 1123.3321 20 7788 1123.3321 30 7521 668.331255 30 7844 668.331255 30 7499 668.331255 30 7900 668.331255 30 7698 668.331255 30 7654 668.331255 14 rows selected.
SUBSTR은 문자열 str 내의 position 위치로부터 length 길이의 문자열을 추출하여 반환하는 함수이다. 추가로 SUBSTRB 함수는 SUBSTR 함수와 동일하지만, 위치를 계산할 때 문자가 아닌 byte를 단위로 사용한다.
SUBSTR의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다.
문자열 내의 문자의 위치는 1부터 시작된다.
position 정수 값을 반환하는 임의의 연산식이다.
문자열 내의 문자의 위치는 1부터 시작된다. 만약 position이 0이면 1로 처리하고, position이 0보다 작으면 문자열 str의 뒤에서부터 추출한다.
length 정수 값을 반환하는 임의의 연산식이다.
문자열 내의 문자의 위치는 1부터 시작된다. 만약 length가 지정되지 않으면 str의 position 위치에서부터 마지막까지 문자열을 추출하며, length가 1보다 작으면 NULL을 반환한다.
-
예제
다음은 SUBSTR 함수를 사용하는 예이다.
SQL> SELECT SUBSTR('ABCDEFG', 3), SUBSTR('ABCDEFG', 3, 2) FROM DUAL; SUBSTR('ABCDEFG',3) SUBSTR('ABCDEFG',3,2) ------------------- --------------------- CDEFG CD 1 row selected. SQL> SELECT SUBSTR('ABCDEFG', -3), SUBSTR('ABCDEFG', -3, 2) FROM DUAL; SUBSTR('ABCDEFG',-3) SUBSTR('ABCDEFG',-3,2) -------------------- ---------------------- EFG EF 1 row selected.
SUM은 그룹 내의 모든 로우에 대한 expr 값의 합계를 구하는 함수이다. 분석 함수로도 사용할 수 있다.
이 함수를 분석 함수로 사용할 때 DISTINCT 예약어를 명시하면 analytic_clause에서 query_partition_clause만 명시할 수 있다. order_by_clause는 명시할 수 없다.
SUM의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 set_quantifier 질의 결과에 중복된 로우의 허용, 비허용 여부를 지정한다. DISTINCT, UNIQUE, ALL을 지정할 수 있다.
-
DISTINCT, UNIQUE: 중복된 로우를 제거한다.
-
ALL: 모든 로우를 선택한다. (기본값)
expr 임의의 연산식이다.
expr 앞에 DISTINCT 예약어를 포함하면, 합계를 구하기 전에 expr 값 중에서 중복된 것을 먼저 제거한다.
analytic_clause OVER analytic_clause를 사용해 함수를 분석 함수로 수행할 수 있다.
자세한 내용은 “4.1.3. 분석 함수”의 analytic_clause를 참고한다.
-
-
예제
다음은 SUM 함수를 사용하는 예이다.
SQL> SELECT DEPTID, SUM(SALARY) FROM EMP2 GROUP BY DEPTID; DEPTID SUM(SALARY) ---------- ---------- 1 14700 2 19200 2 rows selected. -
분석 함수 예제
다음은 SUM 함수를 분석 함수로 사용하는 예이다.
SQL> SELECT NAME, DEPTID, SALARY, SUM(SALARY) OVER (PARTITION BY DEPTID) FROM EMP2; NAME DEPTID SALARY SUM(SALARY) -------------------- ---------- ---------- ---------- Paul 1 3000 14700 Nick 1 3200 14700 Scott 1 4000 14700 John 1 4500 14700 Bree 2 6000 19200 Daniel 2 5000 19200 Joe 2 4000 19200 Brad 2 4200 19200 8 rows selected. SQL> SELECT NAME, SALARY, SUM(SALARY) OVER (ORDER BY SALARY RANGE UNBOUNDED PRECEDING) FROM EMP3; NAME SALARY SUM(SALARY) -------------------- ---------- ---------- Paul 3000 3000 Nick 3200 9400 Scott 3200 9400 John 3500 12900 Bree 4000 16900 Daniel 4500 25900 Joe 4500 25900 7 rows selected.
SYS_CONNECT_BY_PATH는 루트(Root)에서 노드(Node)까지의 컬럼 값의 경로(Path)를 반환하는 함수이다. 이 함수는 계층 질의에 대해서만 유효하다. 반환된 경로에서 컬럼 값은 char에 의해 분리된다.
SYS_CONNECT_BY_PATH의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr, char expr, char 모두 CHAR, VARCHAR2, NCHAR, NVARCHAR2 중에서 어느 타입이어도 된다.
반환된 문자열은 VARCHAR2 타입이며, 컬럼과 같은 문자 집합이다.
-
예제
다음은 SYS_CONNECT_BY_PATH 함수를 사용하는 예이다.
SQL> SELECT ENAME, CONNECT_BY_ROOT ENAME MANAGER, SYS_CONNECT_BY_PATH(ENAME, '-') PATH FROM EMP2 WHERE LEVEL > 1 CONNECT BY PRIOR EMPNO = MGRNO START WITH ENAME = 'Clark'; ENAME MANAGER PATH --------------- --------------- ----------------------- Martin Clark -Clark-Martin James Clark -Clark-Martin-James Alicia Clark -Clark-Martin-Alicia Ramesh Clark -Clark-Ramesh Allen Clark -Clark-Ramesh-Allen JohnClark Clark -Ramesh-John Ward Clark -Clark-Ramesh-John-Ward 7 rows selected.
SYS_CONTEXT는 문맥 네임스페이스(CONTEXT NAMESPACE)와 관련된 파라미터의 값을 반환하는 함수이다. 문맥 네임스페이스와 파라미터는 문자열이나 표현식으로 정의할 수 있으며, 함수의 반환값은 VARCHAR 타입이다.
SYS_CONTEXT의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 namespace 문맥 네임스페이스를 정의하는 값이다. para 문맥 네임스페이스와 관련된 파라미터 이름이다. Tibero에서 디폴트로 제공하고 있는 문맥 네임스페이스는 USERENV이다.
-
USERENV 파라미터
파라미터 설명 CLIENT_IDENTIFIER DBMS_SESSION.SET_IDENTIFIER 프러시저에 의해 정의된 클라이언트 식별자를 반환한다. CURRENT_SCHEMA 현재 활성화된 스키마 이름을 반환한다. 이 값은 ALTER SESSION SET CURRENT_SCHEMA 구문에 의해 변경될 수 있다. CURRENT_SCHEMAID 현재 활성화된 스키마 식별번호를 반환한다. DB_NAME DB_NAME 초기화 파라미터에 의해 정의된 데이터베이스의 이름을 반환한다. HOST 클라이언트가 실행 중인 장비의 이름을 반환한다. INSTANCE_NAME 현재 인스턴스의 이름을 반환한다. INSTANCE 현재 인스턴스의 식별번호를 반환한다. IP_ADDR
IP_ADDRESS
클라이언트의 IP 주소를 반환한다. LANG 'LANGUAGE' 파라미터의 약어를 반환한다. LANGUAGE 데이터베이스의 문자집합 이름을 반환한다. MODULE DBMS_APPLICATION_INFO.SET_MODULE 프러시저에 의해 정의된 모듈 이름을 반환한다. NETWORK_PROTOCOL 양방향 통신을 위한 네트워크 프로토콜의 이름을 반환한다. OS_USER 클라이언트 프로세스의 OS 사용자 이름을 반환한다. SCHEMA 클라이언트의 접속 스키마 이름을 반환한다. SCHEMAID 클라이언트의 접속 사용자 식별번호를 반환한다. SERVER_HOST 현재 인스턴스가 실행 중인 장비의 이름을 반환한다. SESSION_USER 클라이언트의 접속 사용자 이름을 반환한다. SESSIONID 세션 감시 식별번호를 반환한다. TERMINAL 클라이언트의 OS 식별자를 반환한다. TID 현재 세션 식별번호를 반환한다.
-
-
예제
다음은 SYS_CONTEXT 함수를 사용하는 예이다.
SQL> SELECT SYS_CONTEXT('USERENV', 'TID') "TID" FROM DUAL; TID --- 1 1 row selected.
SYS_EXTRACT_UTC는 시간대 정보를 포함하는 시간값을 UTC(Coordinated Universal Time) 시간대로 변환하여 반환하는 함수이다.
SYS_EXTRACT_UTC의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 datetime_with_timezone 시간대 정보를 포함한 시간값을 반환하는 임의의 연산식이다. -
예제
다음은 SYS_EXTRACT_UTC 함수를 사용하는 예이다.
SQL> SELECT SYS_EXTRACT_UTC(TIMESTAMP '1994/07/23 21:13:08 -8:00') FROM DUAL; SYS_EXTRACT_UTC(TIMESTAMP'1994/07/2321:13:08-8:00') --------------------------------------------------- 1994/07/24 05:13:08.000000 1 row selected.
SYS_GUID는 시스템 전체에서 유일한 값을 반환하는 함수이다. 반환값은 16bytes이고 스레드 번호, 호스트 이름, 접속 시간, 시퀀스 번호 등의 조합으로 이루어진 RAW 타입의 값이다.
SYS_GUID의 세부 내용은 다음과 같다.
-
문법
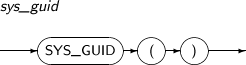
-
예제
다음은 SYS_GUID 함수를 사용하는 예이다.
SQL> SELECT SYSGUID() "SYS_GUID" FROM DUAL; SYS_GUID -------------------------------- 120000000080087893B1484201000000 1 row selected.
SYSDATE는 현재의 날짜와 시간을 반환하는 함수이다. 이 함수는 파라미터가 없으며, 괄호가 따라오지 않는다. 이 함수의 반환값은 DATE 타입이다.
SYSDATE의 세부 내용은 다음과 같다.
-
문법

-
예제
다음은 SYSDATE 함수를 사용하는 예이다.
SQL> SELECT SYSDATE FROM DUAL; SYSDATE ---------- 2009-12-03 1 row selected.
SYSTIME은 현재 시간을 반환하는 함수이다. 이 함수는 파라미터가 없으며, 괄호가 따라 오지 않는다. 이 함수의 반환값은 TIME 타입이다.
SYSTIME의 세부 내용은 다음과 같다.
-
문법

-
예제
다음은 SYSTIME 함수를 사용하는 예이다.
SQL> SELECT SYSTIME FROM DUAL; SYSTIME --------------- 13:42:05.455775 1 row selected.
SYSTIMESTAMP는 현재의 날짜와 시간 및 시간대를 반환하는 함수이다. 이 함수의 반환값은 TIMESTAMP WITH TIME ZONE 타입이다.
SYSTIMESTAMP의 세부 내용은 다음과 같다.
-
문법

-
예제
다음은 SYSTIMESTAMP 함수를 사용하는 예이다.
SQL> SELECT SYSTIMESTAMP FROM DUAL; SYSTIMESTAMP ----------------------------------------- 2009/12/03 13:42:45.816763 Asia/Seoul 1 row selected.
TAN는 주어진 파라미터의 탄젠트(Tangent) 값을 구하는 함수이다.
TAN의 세부 내용은 다음과 같다.
-
문법
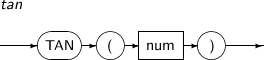
-
구성요소
구성요소 설명 num 실수 값을 반환하는 임의의 연산식이다. (단위: 라디안) -
예제
다음은 TAN 함수를 사용하는 예이다.
SQL> SELECT TAN(3.141592654 * 45.0 / 180.0) FROM DUAL; TAN(3.141592654*45.0/180.0) --------------------------- 1.0000000002051 1 row selected.
TANH는 주어진 파라미터의 하이퍼볼릭 탄젠트 값을 구하는 함수이다.
TANH의 세부 내용은 다음과 같다.
-
문법
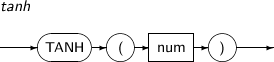
-
구성요소
구성요소 설명 num 실수 값을 반환하는 임의의 연산식이다. (단위: 라디안) -
예제
다음은 TANH 함수를 사용하는 예이다.
SQL> SELECT TANH(1) FROM DUAL; TANH(1) ---------- .761594156 1 row selected.
TO_CHAR(character)는 CLOB 타입의 데이터를 데이터베이스 문자 집합을 사용한 문자열로 변환해 주는 함수이다.
TO_CHAR(character)의 세부 내용은 다음과 같다.
-
문법
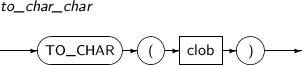
-
구성요소
구성요소 설명 clob 문자열로 변환할 CLOB 타입의 데이터이다. -
예제
다음은 TO_CHAR(character) 함수를 사용하는 예이다.
SQL> SELECT TO_CHAR(contents) FROM BOOK;
TO_CHAR(datetime)은 파라미터로 주어진 날짜형 데이터 타입과 간격 리터럴의 값을 format에 따라 문자열로 변환하여 반환하는 함수이다.
TO_CHAR(datetime)의 세부 내용은 다음과 같다.
-
문법
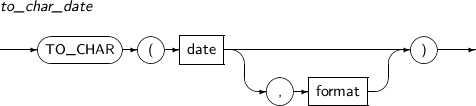
-
구성요소
구성요소 설명 date 날짜형의 값을 반환하는 임의의 연산식이다. format 날짜형 형식의 문자열이다.
만약 format이 지정되지 않으면 디폴트 형식에 따라 문자열로 변환한다.
날짜형 형식의 문자열은 “2.3.2. 날짜형 타입”에서 구체적으로 설명되었다.
-
예제
다음은 TO_CHAR(datetime) 함수를 사용하는 예이다.
SQL> SELECT TO_CHAR(SYSDATE) FROM DUAL; TO_CHAR(SYSDATE) -------------------------------- 2006/12/06 1 row selected. SQL> SELECT TO_CHAR(SYSDATE, 'DD/MM/YY DY') FROM DUAL; TO_CHAR(SYSDATE,'DD/MM/YYDY') ----------------------------- 06/12/06 WED 1 row selected.
TO_CHAR(number)는 파라미터로 주어진 NUMBER 타입의 값을 format에 따라 문자열로 변환하여 반환하는 함수이다.
TO_CHAR(number)의 세부 내용은 다음과 같다.
-
문법
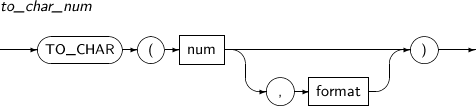
-
구성요소
구성요소 설명 num NUMBER 타입의 값을 반환하는 임의의 연산식이다. format NUMBER 타입의 형식 문자열이다.
만약 format이 지정되지 않으면 디폴트로 모든 유효 숫자를 문자열로 변환한다.
NUMBER 타입의 형식 문자열은 “2.3.1. NUMBER 타입”에서 구체적으로 설명되었다.
-
예제
다음은 TO_CHAR (number) 함수를 사용하는 예이다.
SQL> SELECT TO_CHAR(MIN(SALARY)) FROM EMP; TO_CHAR(MIN(SALARY)) -------------------- 3000 1 row selected. SQL> SELECT TO_CHAR(MIN(SALARY), '$99,999,99') FROM EMP; TO_CHAR(MIN(SAL),'$99,999,99') ------------------------------ $30,00 1 row selected.
TO_CLOB은 파라미터로 주어진 lob_column 또는 char을 CLOB 타입으로 변환하는 함수이다.
TO_CLOB의 세부 내용은 다음과 같다.
-
문법
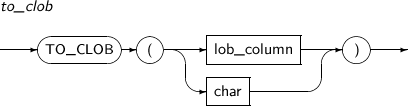
-
구성요소
구성요소 설명 lob_column CHAR 타입, VARCHAR 타입 또는 CLOB 타입의 컬럼이다. char 문자열을 반환하는 임의의 연산식이다. -
예제
다음은 TO_CLOB 함수를 사용하는 예이다.
SQL> SELECT TO_CLOB('tibero') FROM DUAL; TO_CLOB('TIBERO') ----------------- tibero 1 row selected.
TO_DATE은 문자열 str을 format에 따라 DATE 타입의 값으로 변환하여 반환하는 함수이다.
TO_DATE의 세부 내용은 다음과 같다.
-
문법
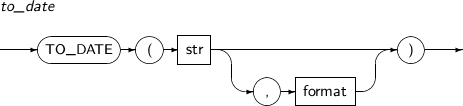
-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다. format 날짜형 형식의 문자열이다.
만약 format이 지정되지 않으면 디폴트 형식으로 변환을 수행한다.
-
예제
다음은 TO_DATE 함수를 사용하여 DATE 타입의 데이터를 반환하는 예이다.
SQL> SELECT TO_DATE('25/12/2004', 'DD/MM/YYYY') FROM DUAL; TO_DATE('25/12/2004','DD/MM/YYYY') ---------------------------------- 2004/12/25 1 row selected.
TO_DSINTERVAL은 CHAR, VARCHAR2, NCHAR, NVARCHAR2 타입의 문자열을 INTERVAL DAY TO SECOND 타입으로 변환하는 함수이다.
TO_DSINTERVAL의 세부 내용은 다음과 같다.
-
문법
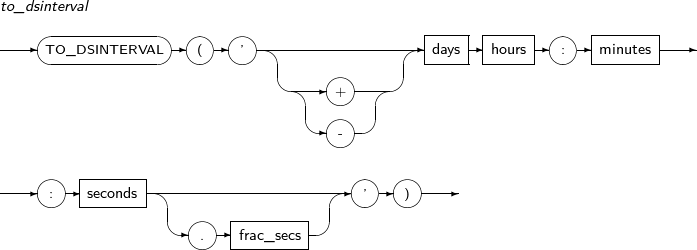
-
구성요소
구성요소 설명 days 0~999999999 사이의 정수이다. hours 0~23 사이의 정수이다. minutes, seconds 0~59 사이의 정수이다. frac_secs 0~999999999 사이의 정수이다. -
예제
다음은 TO_DSINTERVAL 함수를 사용하여 2008년 3월 20일을 기준으로 50일 전의 날짜를 구하는 예이다.
SQL> SELECT DATE '2008-03-20' - TO_DSINTERVAL('50 00:00:00') BEFORE FROM DUAL; BEFORE ---------------------- 2008-01-30 1 row selected.
TO_LOB은 LONG 값을 CLOB, LONG RAW 값을 BLOB 값으로 변환하는 함수이다. LONG 또는 LONG RAW 타입의 컬럼만을 인자로 가지며 INSERT 문의 서브쿼리와 UPDATE 문의 컬럼 값을 갱신하는 서브쿼리에만 사용할 수 있다.
TO_LOB의 세부 내용은 다음과 같다.
-
문법
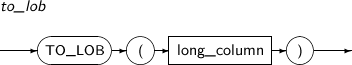
-
구성요소
구성요소 설명 long_column LONG 타입 또는 LONG RAW 타입의 컬럼이다. -
예제
다음은 TO_LOB 함수를 사용하는 예이다.
SQL> CREATE TABLE LONG_TABLE (ID NUMBER, LONG_COL LONG); Table 'LONG_TABLE' created. SQL> INSERT INTO LONG_TABLE VALUES (1, 'first'); 1 row inserted. SQL> CREATE TABLE CLOB_TABLE AS 2 SELECT ID, TO_LOB(LONG_COL) CLOB_COL FROM LONG_TABLE; Table 'CLOB_TABLE' created. SQL> SELECT * FROM CLOB_TABLE; ID CLOB_COL ---------- ---------- 1 first 1 row selected. SQL> INSERT INTO LONG_TABLE VALUES (2, 'second'); 1 row inserted. SQL> INSERT INTO LONG_TABLE VALUES (3, 'third'); 1 row inserted. SQL> INSERT INTO CLOB_TABLE 2 SELECT ID, TO_LOB(LONG_COL) FROM LONG_TABLE WHERE ID = 2; 1 row inserted. SQL> SELECT * FROM CLOB_TABLE; ID CLOB_COL ---------- ---------- 1 first 2 second 2 rows selected. SQL> UPDATE CLOB_TABLE 2 SET CLOB_COL = (SELECT TO_LOB(LONG_COL) FROM LONG_TABLE WHERE ID = 3) 3 WHERE ID = 2; 1 row updated. SQL> SELECT * FROM CLOB_TABLE; ID CLOB_COL ---------- ---------- 1 first 2 third 2 rows selected.
TO_MULTI_BYTE는 입력으로 들어온 파라미터 str의 값을 상응하는 MULTI-BYTE 문자로 변환하는 함수이다. 입력으로 올 수 있는 파라미터의 형식은 VARCHAR, CHAR, NCHAR, NVARCHAR 타입이고, 반환 형식은 입력 형식과 같다.
TO_MULTI_BYTE의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 str MULTI-BYTE 문자로 변환할 값이다. -
예제
다음은 TO_MULTI_BYTE 함수를 사용하는 예이다.
SQL> SELECT DUMP(TO_MULTI_BYTE('A')) "TO_MULTI_BYTE" FROM DUAL; TO_MULTI_BYTE -------------- Len=2: 163,193 1 row selected.
TO_NCHAR는 CHAR, VARCHAR, CLOB, NCLOB 타입의 입력 값을 NATIONAL 문자 집합의 값으로 변환하는 함수이다.
TO_NCHAR의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 str NATIONAL 문자 집합으로 변환할 문자를 나타내는 값이다. -
예제
다음은 TO_NCHAR 함수를 사용하는 예이다.
SQL> SELECT TO_NCHAR(LAST_NAME) "LAST_NAME" FROM EMP WHERE EMP_ID = 5; LAST_NAME --------- Braun 1 row selected.
TO_NUMBER는 문자열 str을 format에 따라 NUMBER 타입의 값으로 변환하여 반환하는 함수이다.
TO_NUMBER의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다. format NUMBER 타입의 형식 문자열이다.
만약 format이 지정되지 않으면 디폴트 형식으로 변환을 수행한다.
-
예제
다음은 TO_NUMBER 함수를 사용하는 예이다.
SQL> SELECT TO_NUMBER('$35,000.00', '$99,999.99') FROM DUAL; TO_NUMBER('$35,000.00','$99,999.99') ------------------------------------ 35000 1 row selected.
TO_SINGLE_BYTE는 입력으로 들어온 파라미터 str의 값을 상응하는 SINGLE-BYTE 문자로 변환하는 함수이다. 입력으로 올 수 있는 파라미터의 형식은 VARCHAR, CHAR, NCHAR, NVARCHAR 타입이고, 반환 형식은 입력 형식과 같다.
TO_SINGLE_BYTE의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 str SINGLE-BYTE 문자로 변환할 값이다. -
예제
다음은 TO_SINGLE_BYTE 함수를 사용하는 예이다.
SQL> SELECT DUMP(TO_SINGLE_BYTE(TO_MULTI_BYTE('A'))) "TO_SINGLE_BYTE" FROM DUAL; TO_SINGLE_BYTE -------------------------------------------------------------------------------- Len=1: 65 1 row selected.
TO_TIME은 문자열 str을 format에 따라 TIME 타입의 값으로 변환하여 반환하는 함수이다.
TO_TIME의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다. format 날짜형 형식의 문자열이다.
만약 format이 지정되지 않으면 디폴트 형식으로 변환을 수행한다.
-
예제
다음은 TO_TIME 함수를 사용하는 예이다.
SQL> SELECT TO_TIME ('12:07:15.50', 'HH24:MI:SS.FF') FROM DUAL; TO_TIME('12:07:15.50','HH24:MI:SS.FF') -------------------------------------- 12:07:15.500000000 1 row selected.
TO_TIMESTAMP는 문자열 str을 format에 따라 TIMESTAMP 타입의 값으로 변환하여 반환하는 함수이다.
TO_TIMESTAMP의 세부 내용은 다음과 같다.
-
문법
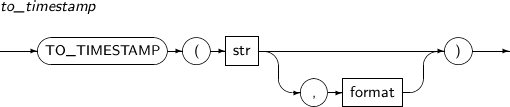
-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다. format 날짜형 형식의 문자열이다.
만약 format이 지정되지 않으면 디폴트 형식으로 변환을 수행한다.
-
예제
다음은 TO_TIMESTAMP 함수를 사용하는 예이다.
SQL> SELECT TO_TIMESTAMP('2009/05/21 12:07:15.50','yyyy-mm-dd HH24:MI:SS.FF') FROM DUAL; TO_TIMESTAMP('2009/05/2112:07:15.50','YYYY-MM-DDHH24:MI:SS.FF') ----------------------------------------------------------------- 2009/05/21 12:07:15.500000 1 row selected.
TO_TIMESTAMP_TZ는 문자열 str을 format에 따라 TIMESTAMP WITH TIME ZONE 타입의 값으로 변환하여 반환하는 함수이다.
TO_TIMESTAMP_TZ의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다.
만약 문자열에 시간대 정보가 포함되지 않은 경우 세션의 디폴트 시간대를 사용한다.
format 날짜형 형식의 문자열이다.
만약 format이 지정되지 않으면 디폴트 형식으로 변환을 수행한다.
-
예제
다음은 TO_TIMESTAMP_TZ 함수를 사용하는 예이다.
SQL> SELECT TO_TIMESTAMP_TZ('1998/09/27 22:05:21.089','YYYY-MM-DD HH24:MI:SS.FF') FROM DUAL; TO_TIMESTAMP_TZ('1998/09/2722:05:21.089','YYYY-MM-DDHH24:MI:SS.FF') ------------------------------------------------------------------ 1998/09/27 22:05:21.089000 Asia/Seoul 1 row selected. SQL> SELECT TO_TIMESTAMP_TZ('2015-10-3 2:17:09.0 +03:00', 'YYYY-MM-DD HH24:MI:SS.FF TZH:TZM') FROM DUAL; TO_TIMESTAMP_TZ('2015-10-32:17:09.0+03:00','YYYY-MM-DDHH24:MI:SS.FFTZH:TZM') ------------------------------------------------------------------------------- 2015/10/03 02:17:09.000000 +03:00 1 row selected.
TO_YMINTERVAL은 CHAR, VARCHAR2, NCHAR, NVARCHAR2 타입의 문자열을 INTERVAL YEAR TO MONTH 타입으로 변환하는 함수이다.
TO_YMINTERVAL의 세부 내용은 다음과 같다.
-
문법
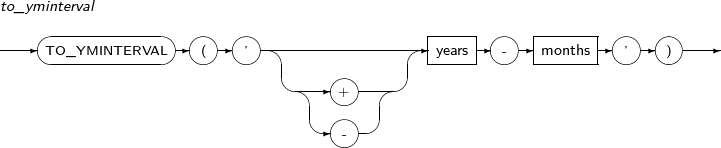
-
구성요소
구성요소 설명 years 0~999999999 사이의 정수이다. months 0~11 사이의 정수이다. -
예제
다음은 TO_YMINTERVAL 함수를 사용하여 2008년 3월 20일을 기준으로 2년 7개월 이후의 날짜를 구하는 예이다.
SQL> SELECT DATE '2008-03-20' + TO_YMINTERVAL('2-7') AFTER FROM DUAL; AFTER ---------------------- 2010-10-20 1 row selected.
TRANSLATE는 문자열 str 내의 각각의 문자가 문자열 from_str에 포함되어 있다면, 해당 문자를 문자열 from_str에서의 위치와 동일한 위치에 있는 문자열 to_str의 문자로 변환시키는 함수이다.
TRANSLATE의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다. from_str 문자열을 반환하는 임의의 연산식이다.
문자열 from_str의 길이가 문자열 to_str의 길이보다 긴 경우 문자열 from_str 내에는 to_str 대응되지 않는 문자가 포함된다.
만약 이렇게 to_str과 대응되지 않는 from_str의 문자가 문자열 str에 포함되어 있다면 해당 문자는 모두 제거된다.
to_str 문자열을 반환하는 임의의 연산식이다. -
예제
다음은 TRANSLATE 함수를 사용하는 예이다.
SQL> SELECT TRANSLATE('ABCXYDEFZ', 'ABCDE', '12345') FROM DUAL; TRANSLATE('ABCXYDEFZ','ABCDE','12345') -------------------------------------- 123XY45FZ 1 row selected. SQL> SELECT TRANSLATE('ABCXYDEFZ', 'ABCDE', '123') FROM DUAL; TRANSLATE('ABCXYDEFZ','ABCDE','123') ------------------------------------ 123XYFZ 1 row selected.
TRIM은 문자열 str의 앞과 뒤에서 trim_character와 같은 문자를 모두 제거하는 함수이다.
TRIM의 세부 내용은 다음과 같다.
-
문법
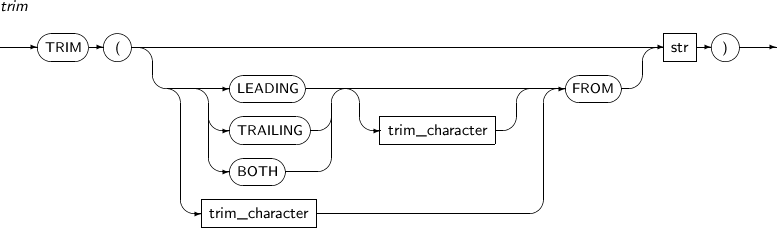
-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다. LEADING trim_character 앞에 LEADING이 오면 str의 앞에서만 문자를 제거한다. TRAILING trim_character 앞에 TRAILING이 오면 str의 뒤에서만 문자를 제거한다. BOTH trim_character 앞에 BOTH가 오거나 아무 것도 오지 않으면 str의 앞과 뒤에서 문자를 제거한다. trim_character trim_character는 길이가 1인 문자이다.
trim_character가 지정되지 않으면 공백 문자(스페이스)를 제거한다.
-
예제
다음은 TRIM 함수를 사용하는 예이다.
SQL> SELECT TRIM(' ABCDE '), LENGTH(TRIM(' ABCDE ')) FROM DUAL; TRIM('ABCDE') LENGTH(TRIM('ABCDE')) ------------- --------------------- ABCDE 5 1 row selected. SQL> SELECT TRIM(LEADING 'X' FROM 'XXYXABCDEXYXX') FROM DUAL; TRIM(LEADING'X'FROM'XXYXABCDEXYXX') ----------------------------------- YXABCDEXYXX 1 row selected. SQL> SELECT TRIM(TRAILING 'X' FROM 'XXYXABCDEXYXX') FROM DUAL; TRIM(TRAILING'X'FROM'XXYXABCDEXYXX') ------------------------------------ XXYXABCDEXY 1 row selected. SQL> SELECT TRIM('X' FROM 'XXYXABCDEXYXX') FROM DUAL; TRIM('X'FROM'XXYXABCDEXYXX') ---------------------------- YXABCDEXYs 1 row selected.
TRUNC(number)는 num1을 소수점 아래 num2 위치에서 버림(Truncation)한 값을 반환하는 함수이다.
TRUNC(number)의 세부 내용은 다음과 같다.
-
문법
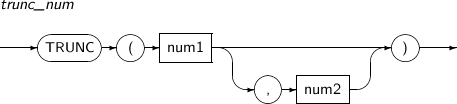
-
구성요소
구성요소 설명 num1 수치 값을 반환하는 임의의 연산식이다. num2 수치 값을 반환하는 임의의 연산식이다.
num2는 정수가 되어야 한다. 만약 num2가 주어지지 않거나 0이면 소수점 자리에서 버림을 한다.
num2가 음수이면 소수점 위의 자리에서 버림을 한다.
-
예제
다음은 TRUNC(number)를 사용하는 예이다.
SQL> SELECT TRUNC(345.678), TRUNC(345.678, 2), TRUNC(345.678, -1) FROM DUAL; TRUNC(345.678) TRUNC(345.678,2) TRUNC(345.678,-1) -------------- ---------------- ----------------- 345 345.67 340 1 row selected.
TRUNC(date)는 date를 format에 명시된 단위로 버림한 결과를 반환하는 함수이다.
참고
TRUNC(date)함수의 format에 명시할 수 있는 형식 문자열은 ROUND(date) 함수와 동일하다.
TRUNC(date)의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 date 날짜를 반환하는 임의의 연산식이다. format 버림 단위를 명시하는 형식 문자열이다.
format이 명시되지 않는다면 'DD' 형식 문자열을 이용하여 가장 가까운 날로 버림된다. format으로 'YEAR', 'MONTH', 'DAY' 등을 사용할 수 있다.
-
예제
다음은 TRUNC(date) 함수를 사용하는 예이다.
SQL> SELECT TRUNC(TO_DATE('2005/06/22', 'YYYY/MM/DD'), 'YEAR') FROM DUAL; TRUNC(TO_DATE('2005/06/22','YYYY/MM/DD'),'YEAR') ----------------------------------------------------------------- 2005-01-01 1 row selected. SQL> SELECT TO_CHAR(TRUNC(TO_DATE( '1998/6/20', 'YYYY/MM/DD'), 'CC'), 'YYYY/MM/DD') FROM DUAL; TO_CHAR(TRUNC(TO_DATE('1998/6/20','YYYY/MM/DD'),'CC'),'YYYY/MM/DD') ------------------------------------------------------------------- 1901/01/01 1 row selected. SQL> SELECT TO_CHAR(TRUNC(TO_DATE('-3741/01/02', 'SYYYY/MM/DD'), 'CC'), 'SYYYY/MM/DD') FROM DUAL; TO_CHAR(TRUNC(TO_DATE('-3741/01/02','SYYYY/MM/DD'),'CC'),'SYYYY/MM/DD') ----------------------------------------------------------------------- -3800/01/01 1 row selected. SQL> SELECT TO_CHAR(TRUNC(TO_DATE( '2005/01/26 12:30:14', 'YYYY/MM/DD HH24:MI:SS'), 'DY'), 'YYYY/MM/DD') FROM DUAL; TO_CHAR(TRUNC(TO_DATE('2005/01/2612:30:14','YYYY/MM/DDHH24:MI:SS'),'DY'),'YYYY/M -------------------------------------------------------------------------------- 2005/01/23 1 row selected. SQL> SELECT TRUNC(TO_DATE( '2005/01/26 12:30:14', 'YYYY/MM/DD HH24:MI:SS')) FROM DUAL; TRUNC(TO_DATE('2005/01/2612:30:14','YYYY/MM/DDHH24:MI:SS')) ----------------------------------------------------------------- 2005-01-26 1 row selected.
TZ_OFFSET은 주어진 시간대를 오프셋 형식으로 반환하는 함수이다.
TZ_OFFSET의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 timezone_name 시간대 지역 이름을 반환하는 문자열이다. [+|-]hh:mi 시간대 오프셋 값을 반환하는 문자열이다. SESSIONTIMEZONE 현재 세션의 시간대 값을 반환하는 함수이다. -
예제
다음은 TZ_OFFSET을 사용하는 예이다.
SQL> SELECT TZ_OFFSET('-5:00') FROM DUAL; TZ_OFFSET('-5:00') ------------------------------ -05:00 1 row selected.
TZ_SHIFT는 주어진 시간대를 특정 시간대로 변환하는 함수이다.
TZ_SHIFT의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 expr 시간대 정보를 포함한 시간값을 반환하는 임의의 연산식이다. timezone_name 시간대 지역 이름을 반환하는 문자열이다. [+|-]hh:mi 시간대 오프셋 값을 반환하는 문자열이다. SESSIONTIMEZONE 현재 세션의 시간대 값을 반환하는 함수이다. -
예제
다음은 TZ_SHIFT을 사용하는 예이다.
SQL> SELECT TZ_SHIFT(FROM_TZ(TIMESTAMP '2002-09-08 21:00:00', '00:00'), '+09:00') SEOUL FROM DUAL; SEOUL --------------------------------- 2002/09/09 06:00:00.000000 +09:00 1 row selected.
UID는 현재 세션을 생성한 사용자의 ID를 반환하는 함수이다. 사용자 ID는 Tibero의 시스템 내에서 그 사용자를 식별해주는 유일한 정수 값이다. 파라미터는 없으며 괄호를 생략한다.
UID의 세부 내용은 다음과 같다.
-
문법
-
예제
다음은 UID 함수를 사용하는 예이다.
SQL> SELECT UID FROM DUAL; UID ---------- 7171 1 row selected.
UNISTR는 유니코드 문자열을 입력받아 다국어 문자집합으로 인코딩된 문자열을 반환하는 함수이다. 입력으로 사용하는 유니코드 문자열은 '\xxxx' 형태이며, 여기서 'xxxx'는 UCS-2 포맷으로 인코딩된 16진수 문자열이다.
UNISTR의 세부 내용은 다음과 같다.
-
문법
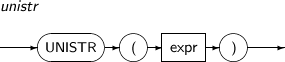
-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다. -
예제
다음은 UNISTR 함수를 사용하는 예이다.
SQL> SELECT UNISTR('\00E5\00F1\00F6') FROM DUAL; UNISTR('\00E5\00F1\00F6') ------------------------- åñö 1 row selected.
UPDATEXML은 XPath expression과 XMLType instance의 쌍으로 입력된 인자들로 XMLType_instance의 각 해당 xpath들을 value_expr의 value로 치환하는 함수이다. 실제 xml column값이 바뀌지 않고, 바뀐 XMLType instance가 반환된다. 만약 해당 xpath에 해당하는 node가 존재하지 않으면 원래의 바뀌지 않은 xmltype instance가 반환된다.
UPDATEXML의 세부 내용은 다음과 같다.
-
문법
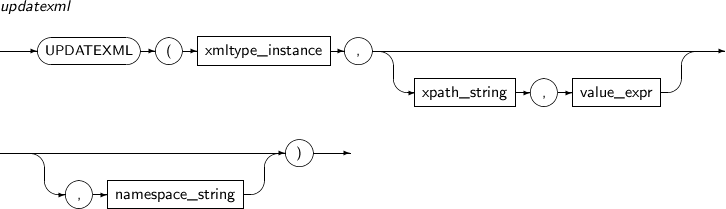
-
구성요소
구성요소 설명 XMLType_instance XMLType instance다. XPath_string Xpath expression으로 갱신할 곳의 자식 노드들이 갱신된다. value_expr update할 곳의 자식 노드들이 값이다. namespace_string XPath_string의 네임스페이스 정보를 나타낸다. VARCHAR Type이어야 한다. -
예제
다음은 UPDATEXML 함수를 사용하는 예이다.
SQL> SELECT warehouse_name, EXTRACT(warehouse_spec, '/Warehouse/Docks') "Number of Docks" FROM warehouses WHERE warehouse_name = 'San Francisco'; WAREHOUSE_NAME Number of Docks -------------------- -------------------- San Francisco <Docks>1</Docks> SQL> UPDATE warehouses SET warehouse_spec = UPDATEXML(warehouse_spec, '/Warehouse/Docks/text()',4) WHERE warehouse_name = 'San Francisco'; 1 row updated. SQL> SELECT warehouse_name, EXTRACT(warehouse_spec, '/Warehouse/Docks') "Number of Docks" FROM warehouses WHERE warehouse_name = 'San Francisco'; WAREHOUSE_NAME Number of Docks -------------------- -------------------- San Francisco <Docks>4</Docks>
UPPER는 문자열 str 내의 모든 영문자를 대문자로 변환하여 반환하는 함수이다.
UPPER의 세부 내용은 다음과 같다.
-
문법
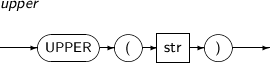
-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다. -
예제
다음은 UPPER 함수를 사용하는 예이다.
SQL> SELECT UPPER('ABCdefg123') FROM DUAL; UPPER('ABCDEFG123') ------------------- ABCDEFG123 1 row selected.
USER는 현재 세션을 생성한 사용자의 이름을 반환하는 함수이다. 파라미터는 없으며 괄호를 생략한다.
USER의 세부 내용은 다음과 같다.
-
문법
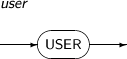
-
예제
다음은 USER 함수를 사용하는 예이다.
SQL> SELECT USER FROM DUAL; USER ------------------------------ JOE 1 row selected.
USERENV는 현재 세션의 정보를 보여주는 함수이다.
참고
USERENV 함수에서 제공하는 파라미터는 “4.2.138. SYS_CONTEXT”를 참고한다.
USERENV의 세부 내용은 다음과 같다.
-
문법
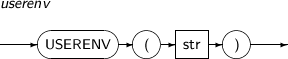
-
구성요소
구성요소 설명 str 문자열을 반환하는 임의의 연산식이다. -
예제
다음은 USERENV 함수를 사용하는 예이다.
SQL> SELECT USERENV('TID') FROM DUAL; USERENV('TID') ---------------------------------------------------------------- 7 1 row selected.
VAR_POP은 expr의 모분산을 반환한다. 모분산을 계산할 때 NULL 값은 무시된다. 이 함수는 파라미터의 수치 데이터 타입 또는 변환된 수치 데이터 타입을 반환한다. 이 함수를 공집합에 적용하면 NULL 값을 반환한다.
이 함수는 다음과 같은 계산식으로 계산을 수행한다.
(SUM(expr2) - SUM(expr)2 / COUNT(expr)) / COUNT(expr)
VAR_POP의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr 수치 데이터 타입 또는 수치 데이터 타입은 아니지만 묵시적으로 수치 데이터 타입으로 변환할 수 있는 데이터 타입을 반환하는 임의의 연산식이다. analytic_clause OVER analytic_clause를 사용해 함수를 분석 함수로 수행할 수 있다.
자세한 내용은 “4.1.3. 분석 함수”의 analytic_clause를 참고한다.
-
예제
다음은 VAR_POP 함수를 사용하는 예이다.
SQL> SELECT VAR_POP(AGE) FROM EMP_AGE; VAR_POP(AGE) ------------ 8.29 1 row selected. -
분석 함수 예제
다음은 VAR_POP 함수를 분석 함수로 사용하는 예이다.
SQL> SELECT DEPTNO, EMPNO, VAR_POP(SAL) OVER (PARTITION BY DEPTNO) AS VAR_POP FROM EMP; DEPTNO EMPNO VAR_POP ---------- ---------- ---------- 10 7934 2390555.56 10 7839 2390555.56 10 7782 2390555.56 20 7566 1009500 20 7788 1009500 20 7876 1009500 20 7902 1009500 20 7369 1009500 30 7654 372222.222 30 7698 372222.222 30 7521 372222.222 30 7499 372222.222 30 7844 372222.222 30 7900 372222.222 14 rows selected.
VAR_SAMP는 expr의 표본분산을 반환하는 함수이다. 표본분산을 계산할 때 NULL 값은 무시된다. 이 함수는 파라미터의 수치 데이터 타입 또는 변환된 수치 데이터 타입을 반환한다. 이 함수를 공집합에 적용하면 NULL 값을 반환한다.
이 함수는 다음과 같은 계산식으로 계산을 수행한다.
(SUM(expr2) - SUM(expr)2 / COUNT(expr)) / (COUNT(expr) - 1)
VAR_SAMP의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr 수치 데이터 타입 또는 수치 데이터 타입은 아니지만 묵시적으로 수치 데이터 타입으로 변환할 수 있는 데이터 타입을 반환하는 임의의 연산식이다. analytic_clause OVER analytic_clause를 사용해 함수를 분석 함수로 수행할 수 있다.
자세한 내용은 “4.1.3. 분석 함수”의 analytic_clause를 참고한다.
-
예제
다음은 VAR_SAMP 함수를 사용하는 예이다.
SQL> SELECT VAR_SAMP(AGE) FROM EMP_AGE; VAR_SAMP(AGE) ------------- 9.21111111111 1 row selected.
-
분석 함수 예제
다음은 VAR_SAMP 함수를 분석 함수로 사용하는 예이다.
SQL> SELECT DEPTNO, EMPNO, VAR_SAMP(SAL) OVER (PARTITION BY DEPTNO) AS VAR_SAMP FROM EMP; DEPTNO EMPNO VAR_SAMP ---------- ---------- ---------- 10 7934 3585833.33 10 7839 3585833.33 10 7782 3585833.33 20 7566 1261875 20 7788 1261875 20 7876 1261875 20 7902 1261875 20 7369 1261875 30 7654 446666.667 30 7698 446666.667 30 7521 446666.667 30 7499 446666.667 30 7844 446666.667 30 7900 446666.667 14 rows selected.
VARIANCE는 expr의 분산을 반환한다. 분석 함수로도 사용할 수 있다. 이 함수는 파라미터의 수치 데이터 타입 또는 변환된 수치 데이터 타입을 반환한다. 이 함수를 공집합에 적용하면 NULL 값을 반환한다.
Tibero에서는 분산을 다음과 같이 계산한다.
-
expr의 로우의 수가 1이면 0을 반환한다.
-
expr의 로우의 수가 1보다 크면 VAR_SAMP 함수의 값을 반환한다.
VARIANCE의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr 수치 데이터 타입 또는 수치 데이터 타입은 아니지만 묵시적으로 수치 데이터 타입으로 변환할 수 있는 데이터 타입을 반환하는 임의의 연산식이다. analytic_clause OVER analytic_clause를 사용해 함수를 분석 함수로 수행할 수 있다.
자세한 내용은 “4.1.3. 분석 함수”의 analytic_clause를 참고한다.
-
예제
다음은 VARIANCE 함수를 사용하는 예이다.
SQL> SELECT VARIANCE(AGE) FROM EMP_AGE; VARIANCE(AGE) ------------- 9.21111111111 1 row selected.
-
분석 함수 예제
다음은 VARIANCE 함수를 분석 함수로 사용하는 예이다.
SQL> SELECT DEPTNO, EMPNO, VARIANCE(SAL) OVER (PARTITION BY DEPTNO) AS VARIANCE FROM EMP; DEPTNO EMPNO VARIANCE ---------- ---------- ----------- 10 7934 3585833.333 10 7839 3585833.333 10 7782 3585833.333 20 7566 1261875 20 7788 1261875 20 7876 1261875 20 7902 1261875 20 7369 1261875 30 7654 446666.6667 30 7698 446666.6667 30 7521 446666.6667 30 7499 446666.6667 30 7844 446666.6667 30 7900 446666.6667 14 rows selected.
VSIZE는 expr을 표현하기 위해 내부적으로 사용되는 byte 크기를 반환하는 함수이다.
VSIZE의 세부 내용은 다음과 같다.
-
문법
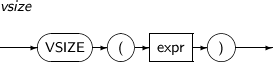
-
구성요소
구성요소 설명 expr 임의의 연산식이다.
expr이 NULL이면 함수는 NULL을 반환한다.
-
예제
다음은 VSIZE 함수를 사용하는 예이다.
SQL> SELECT VSIZE(SYSDATE) FROM DUAL; VSIZE(SYSDATE) -------------- 8 1 row selected.
XMLAGG는 집합 함수이다. XML 조각을 받고, 이를 한데 모아 XML 문서로 만들어 반환하는 함수이다. NULL 값을 반환하는 파라미터는 결과로부터 제외된다.
XMLAGG의 세부 내용은 다음과 같다.
-
문법
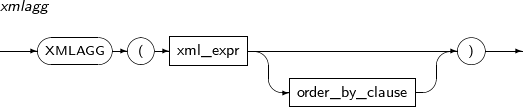
-
구성요소
구성요소 설명 xml_expr XML 문장을 반환하는 임의의 연산식이다. order_by_clause XML 문장들을 어떻게 정렬할지를 명시한다.
자세한 내용은 “4.1.3. 분석 함수”의 order_by_clause를 참고한다.
-
예제
다음은 XMLAGG 함수를 사용하는 예이다.
SQL> SELECT XMLELEMENT("EMPLOYEE", XMLAGG(XMLELEMENT("NAME",NAME)), XMLELEMENT("AGE",AGE)) AS "EMPLOYEE" FROM EMP_AGE GROUP BY AGE; EMPLOYEE --------------------------------------------------------------------- <EMPLOYEE><NAME>Jim Clark</NAME><NAME>John Ronaldo</NAME><NAME>Choi S efo</NAME><NAME>Titicaca Eboue</NAME><AGE>27</AGE></EMPLOYEE> <EMPLOYEE><NAME>Mirko Fedor</NAME><NAME>Doug Bush</NAME><AGE>28</AGE> </EMPLOYEE> <EMPLOYEE><NAME>Razor Ramon</NAME><AGE>34</AGE></EMPLOYEE> <EMPLOYEE><NAME>Mike Thai</NAME><NAME>Ryu Hayabusa</NAME><NAME>Sebast ian Panucci</NAME><AGE>31</AGE></EMPLOYEE> 4 rows selected.
XMLCAST는 첫 번째 파라미터의 값을 두 번째 파라미터에서 지정한 SQL 데이터 타입으로 변환하는 함수이다.
XMLCAST의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr XML 문장을 반환하는 임의의 연산식이다. typename 변환할 SQL 데이터 타입의 이름을 명시한다. -
예제
다음은 XMLCAST 함수를 사용하는 예이다.
SQL> SELECT XMLCAST( XMLQUERY('/BOOK' PASSING C1 RETURNING CONTENT) AS VARCHAR(100)) CAST_VALUE FROM XMLTBL; CAST_VALUE -------------------------------------------------------------------------------- Introduction to TIBERO Tibero team 1 row selected.
XMLCOMMENT는 expr의 결과로 XML 주석을 만드는 함수이다. <!--string-->와 같은 포맷의 XMLType을 반환한다.
XMLCOMMENT의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 expr XML 주석의 내용이 될 문자열이다.
만약 expr이 NULL이면 함수는 NULL을 반환한다.
-
예제
다음은 XMLCOMMENT 함수를 사용하는 예이다.
SQL> SELECT XMLCOMMENT('Tibero') AS "XMLCOMMENT" FROM DUAL; XMLCOMMENT ---------------------------------------------------------------------- <!--Tibero--> 1 row selected.
XMLCONCAT는 입력으로 나열된 모든 XMLType 객체들을 접합한 결과를 반환한다. 임의의 expr이 NULL일 경우엔 해당 expr을 무시하고, 모든 expr이 NULL일 경우엔 NULL을 반환한다.
XMLCONCAT의 세부 내용은 다음과 같다.
-
문법
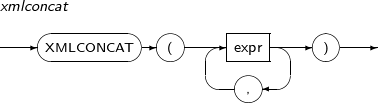
-
구성요소
구성요소 설명 expr XMLType 객체를 반환하는 연산식이다. -
예제
다음은 XMLCONCAT 함수를 사용하는 예이다.
SQL> SELECT XMLCONCAT(XMLTYPE('<Tibero>TIBERO</Tibero>'), XMLTYPE('<Tibero></Tibero>')) AS "XMLCONCAT" FROM DUAL; XMLCONCAT -------------------------------------------------------------- <Tibero>TIBERO</Tibero><Tibero></Tibero> 1 row selected.
XMLELEMENT는 identifier로는 엘리먼트(Element)의 이름을 받고, 엘리먼트의 속성 집합을 옵션으로 받으며, 엘리먼트의 내용을 구성하는 파라미터를 받는 함수이다. 이 함수는 중첩된 구조를 가진 XML 문서를 생성하기 위해서 보통은 중첩되어 사용된다.
XMLELEMENT의 세부 내용은 다음과 같다.
-
문법
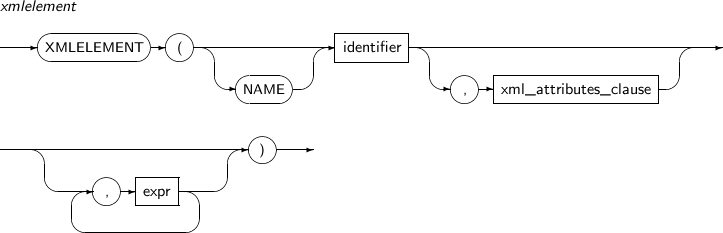
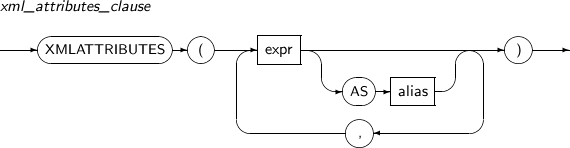
-
구성요소
-
xmlelement
구성요소 설명 identifier identifier의 값은 XML의 enclosing tag로 사용되기 때문에 반드시 제공되어야 한다. identifier의 크기는 4000자까지이며, 컬럼명 또는 컬럼에 대한 참조일 필요는 없지만 표현식 또는 NULL 값일 수도 없다.
엘리먼트의 내용을 구성하는 개체는 XMLATTRIBUTES 예약어 이후에 명시한다.
xml_attributes_clause XML의 속성(attribute)을 표현하기 위한 문법이다. 엘리먼트의 값을 나타낸다. expr 엘리먼트의 내용을 구성하는 연산식이다. -
xml_attributes_clause
구성요소 설명 expr expr이 컬럼이면 AS 절을 생략할 수 있으며, Tibero는 컬럼명을 엘리먼트 이름으로 사용한다.
expr이 NULL이면, 해당 value expression에 어떠한 속성도 생성되지 않는다.
value expression은 XMLELEMENT의 expr을 의미한다.
alias AS 절을 이용하여 expr의 별칭을 명시할 때의 c_alias의 크기는 최대 4000자이다.
-
-
예제
다음은 XMLELEMENT 함수를 사용하는 예이다.
SQL> SELECT XMLELEMENT("DEPT", XMLELEMENT("DNAME",DNAME), XMLELEMENT("LOCATION",LOC)) AS "DEPT" FROM DEPT; DEPT --------------------------------------------------------------------- <DEPT><DNAME>ACCOUNTING</DNAME><LOCATION>NEW YORK</LOCATION></DEPT> <DEPT><DNAME>RESEARCH</DNAME><LOCATION>DALLAS</LOCATION></DEPT> <DEPT><DNAME>SALES</DNAME><LOCATION>CHICAGO</LOCATION></DEPT> <DEPT><DNAME>OPERATIONS</DNAME><LOCATION>BOSTON</LOCATION></DEPT> 4 rows selected.
XMLEXISTS는 XQuery 표현식의 결과가 비어 있는지의 여부를 검사하는 함수이다. 이 함수의 반환값이 비어 있지 않으면 TRUE를, 비어 있으면 FALSE인 Boolean 값이다. 단, 이 함수는 Linux IA64, HP PA-RISC, Windows 환경에서 지원하지 않는다.
XMLEXISTS의 세부 내용은 다음과 같다.
-
문법
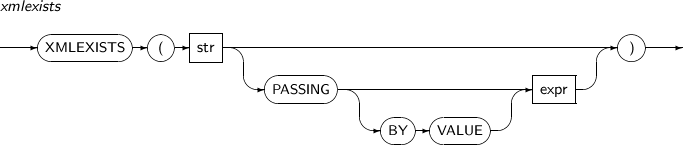
-
구성요소
구성요소 설명 str XML 문서에 질의할 XQuery 문자열이다. expr XMLType이 결과인 표현식이다.
표현식의 결과가 XMLType이 아니면 에러를 발생한다.
-
예제
다음은 XMLEXISTS 함수를 사용하는 예이다.
SQL> SELECT OBJECT_VALUE AS "DEPT" FROM DEPT_XMLTABLE WHERE XMLEXISTS('/DEPT[DNAME="ACCOUNTING"]' PASSING OBJECT_VALUE); DEPT ---------------------------------------------------------------------- <DEPT><DNAME>ACCOUNTING</DNAME><LOC>NEW YORK</LOC></DEPT> 1 row selected.
XMLForest는 파라미터 각각을 XML로 변환하고, 변환된 파라미터를 결합하여 반환하는 함수이다.
XMLFOREST의 세부 내용은 다음과 같다.
-
문법
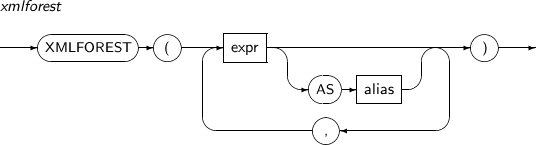
-
구성요소
구성요소 설명 expr expr이 컬럼이면 AS 절을 생략할 수 있으며, Tibero는 컬럼명을 엘리먼트 이름으로 사용한다.
expr이 NULL이면, 해당 value expression에 어떠한 속성도 생성되지 않는다.
alias AS 절을 이용하여 expr의 별칭을 명시할 때의 c_alias의 크기는 최대 4000자이다. -
예제
다음은 XMLFOREST 함수를 사용하는 예이다.
SQL> SELECT XMLELEMENT("DEPT", XMLFOREST(DNAME,LOC)) AS "DEPT" FROM DEPT; DEPT ---------------------------------------------------------------------- <DEPT><DNAME>ACCOUNTING</DNAME><LOC>NEW YORK</LOC></DEPT> <DEPT><DNAME>RESEARCH</DNAME><LOC>DALLAS</LOC></DEPT> <DEPT><DNAME>SALES</DNAME><LOC>CHICAGO</LOC></DEPT> <DEPT><DNAME>OPERATIONS</DNAME><LOC>BOSTON</LOC></DEPT> 4 rows selected.
XMLPARSE는 expr로부터 XMLType을 만드는 함수이다.
XMLPARSE의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 DOCUMENT expr의 결과는 반드시 루트가 하나인 XML 문서이어야 한다. CONTENT expr의 결과는 XML 값이어야 한다. expr expr의 결과는 반드시 문자열 타입이어야 한다. WELLFORMED CONTENT의 경우 데이터베이스 내부적으로 WELLFORMED CHECK를 하지 않는다. -
예제
다음은 XMLPARSE 함수를 사용하는 예이다.
SQL> SELECT XMLPARSE(CONTENT 'ABC<NAME>Park</NAME><ID>123</ID>' WELLFORMED) AS PO FROM DUAL; PO ---------------------------------------------------------------------- ABC<NAME>Park</NAME><ID>123</ID> 1 row selected.
XMLPI는 XML 문서의 PI 문법을 생성하는 함수이다. XMLType을 반환한다.
XMLPI의 세부 내용은 다음과 같다.
-
문법
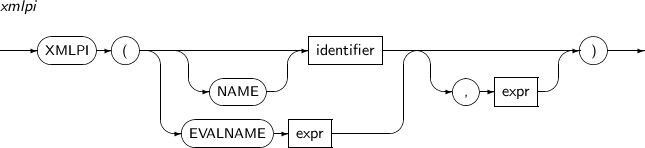
-
구성요소
구성요소 설명 identifier XML 문서의 PI 문법에서 name에 들어갈 문자열이다.
XML 내부에서 사용하는 예약어 또는 물음표(?), >를 포함할 수 없다.
expr 문자열이 결과인 expr이다. 생략되면, 길이가 0인 문자열로 간주된다. -
예제
다음은 XMLPI 함수를 사용하는 예이다.
SQL> SELECT XMLPI(NAME "RDBMS", 'Tibero') AS XMLPI FROM DUAL; XMLPI --------------------------------------------- <?RDBMS Tibero?> 1 row selected.
XMLQUERY는 지정된 XML 쿼리를 이용하여 해당 XML 데이터를 가져오는 함수이다. XMLType을 반환한다. 단, 이 함수는 Linux IA64, HP PA-RISC, Windows 환경에서 지원하지 않는다.
XMLQUERY의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 str XML 문서에 질의할 XQuery 문자열이다. 최대 4000자이다. expr 질의의 대상이 되는 XML 문서가 결과인 표현식이다. XMLType이어야 한다. -
예제
다음은 XMLQUERY 함수를 사용하는 예이다.
SQL> SELECT XMLQUERY('1, 2, 5' RETURNING CONTENT) AS XMLQRY FROM DUAL; XMLQRY --------------------------------------------- 1 2 5
XMLSERIALIZE는 expr로부터 문자열이나 LOB 객체를 만드는 함수이다.
XMLSERIALIZE의 세부 내용은 다음과 같다.
-
문법

-
구성요소
구성요소 설명 DOCUMENT expr의 결과는 반드시 루트가 하나인 XML 문서이어야 한다. CONTENT expr의 결과는 XML 값이어야 한다. expr XML 문서를 반환하는 임의의 연산식이다. datatype 결과 타입을 지정한다. VARCHAR2와 CLOB을 사용할 수 있다. (기본값: CLOB) -
예제
다음은 XMLSERIALIZE 함수를 사용하는 예이다.
SQL> SELECT XMLSERIALIZE(CONTENT XMLTYPE('<A>123</A>')) AS XMLSERI FROM DUAL; XMLSERI --------------------------------------------- <A>123</A> 1 row selected.
XMLTABLE은 XML 문서에 XML Query를 질의한 결과를 테이블 형태로 반환하는 함수이다. 각 컬럼의 값은 XML Query의 결과 XML에서 XPath를 통해 설정하며, 타입 지정을 통해서 해당 데이터 타입으로 설정되어 반환된다. 단, 이 함수는 Linux IA64, HP PA-RISC, Windows 환경에서 지원하지 않는다.
XMLTABLE의 세부 내용은 다음과 같다.
-
문법



-
구성요소
구성요소 설명 xquery_str XML 문서에 질의할 XML Query이다. 최대 길이는 4000자로 제한된다. xmlnamespace_clause의 str XML Query를 질의할 특정 네임스페이스를 지정할 수 있다. 필요 없으면 생략할 수 있다. xml_passing_clause의 expr XML Query를 질의할 XML 문서이다. xmltable_column의 datatype 결과 컬럼의 데이터 타입을 명시한다. xmltable_column의 str 결과 컬럼의 이름을 명시한다. 문자열이며 최대 4000자이다. xmltable_column의 expr 해당 XPath에 값이 없을 경우 기본값이다. 이 문법이 생략되면 NULL이 기본값이다. -
예제
다음은 XMLTABLE 함수를 사용하는 예이다.
SQL> SELECT warehouse_name warehouse, warehouse2."Water", warehouse2."Rail" FROM warehouses, XMLTABLE('/Warehouse' PASSING warehouses.warehouse_spec COLUMNS "Water" varchar2(6) PATH '/Warehouse/WaterAccess', "Rail" varchar2(6) PATH '/Warehouse/RailAccess') warehouse2; WAREHOUSE Water Rail ----------------------------------- ------ ------ Southlake, Texas Y N San Francisco Y N New Jersey N N Seattle, Washington N Y 4 rows selected.
XMLTRANSFORM은 xmltype_instance를 xslt_document에 표현된 형식으로 변형하는 함수이다. parammap을 통해 xslt_document에 정의된 파라미터를 입력할 수 있다. 단, Windows 64 bit, HP UX/PA-RISC는 지원하지 않는다.
XMLTRANSFORM의 세부 내용은 다음과 같다.
-
문법
-
구성요소
구성요소 설명 xmltype_instance 질의의 대상이 되는 XML 문서로, XMLType이다. xslt_document 변형 형식이 표현된 XSLT 문서로, XMLType이다. parammap XSLT 문서에 정의된 파라미터를 입력할 수 있다.
name1=value1 name2=value2 ... 형식의 문자열이다.
-
예제
다음은 XMLTRANSFORM 함수를 사용하는 예이다.
SQL> select XMLTRANSFORM(XMLTYPE('<root/>'), XMLTYPE('<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:fo="http://www.w3.org/1999/XSL/Format" exclude-result-prefixes="fo"> <xsl:output method="xml"/><xsl:param name="par1"/> <xsl:param name="par2"/><xsl:template match="/"> <output><param1><xsl:value-of select="$par1"/></param1> <param2><xsl:value-of select="$par2"/></param2></output> </xsl:template></xsl:stylesheet>'), 'par1="a" par2="b"') as result from dual; RESULT -------------------------------------------------------------------------------- <output><param1>a</param1><param2>b</param2></output> 1 row selected.