내용 목차
하나의 데이터베이스 인스턴스 내에서 한 트랜잭션으로 묶인 SQL 문장이 모두 커밋되거나 롤백되듯이 네트워크로 연결된 여러 개의 데이터베이스 인스턴스가 참여하는 트랜잭션에서도 각각 다른 데이터베이스 인스턴스에서 수행한 SQL 문장이 모두 동시에 커밋되거나 롤백될 수 있는 방법이 필요하다.
이렇게 여러 개의 노드 또는 다른 종류의 데이터베이스가 참여하는 하나의 트랜잭션을 분산 트랜잭션(Distributed Transaction)이라고 한다. Tibero에서는 분산 트랜잭션을 처리하기 위해 XA와 데이터베이스 링크(DBLink)를 통해 지원한다.
Tibero는 X/Open DTP(Distributed Transaction Processing) 규약의 XA를 지원한다. XA는 2PC(Two-phase commit)를 이용하여 분산 트랜잭션을 처리한다.
다음은 XA가 어떻게 동작하는지를 나타내는 그림이다.
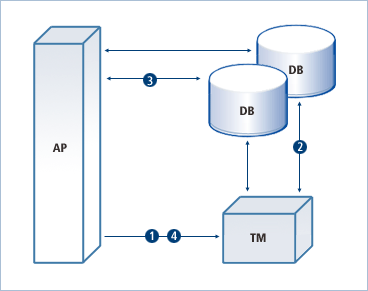
-
일반적으로 XA는 트랜잭션 매니저(TM: Transaction Manager, 이하 TM)에 의해 코디네이트된다. 가장 먼저 애플리케이션 프로그램(AP: Application Program, 이하 AP)은 TM에 분산 트랜잭션의 시작을 알린다.
-
TM은 AP의 요청을 받고 어떤 데이터베이스의 노드가 해당 분산 트랜잭션에 참여하는지 확인한다. 그 다음 각 데이터베이스 노드에 분산 트랜잭션의 시작을 알린다.
각 데이터베이스 노드에 분산 트랜잭션의 시작을 알릴 때 TM은 내부에 고유한 트랜잭션 ID(이하 XID)를 만들어서 함께 전달한다. 그러면 각 데이터베이스 노드는 이 XID와 관련된 분산 트랜잭션을 시작한다. 앞으로 AP로부터 들어오는 요청은 해당 분산 트랜잭션에 대한 작업이라고 인식한다.
-
AP는 각 데이터베이스에 SQL 문장을 전달함으로써 필요한 작업을 진행한다.
이때 각 데이터베이스는 전달 받은 요청을 해당 XID와 관련된 작업이라고 인지하고 SQL 문장을 실행한다.
-
모든 작업이 완료되면 AP는 TM에 분산 트랜잭션의 종료를 알린다.
TM은 해당 XID로 분산 트랜잭션에 참여했던 각 데이터베이스 노드에 커밋과 롤백을 동시에 하도록 지시한다. 일부 데이터베이스는 커밋을 하고, 일부 데이터베이스는 롤백을 하는 상황이 벌어지지 않도록 TM은 Two-phase commit mechanism을 통해 수행한다.
Two-phase commit mechanism은 분산 컴퓨팅 환경에서 트랜잭션에 참여하는 모든 데이터베이스가 정상적으로 수정되었음을 보장하는 두 단계 커밋 프로토콜이다. 분산 트랜잭션에 참여한 모든 데이터베이스가 모두 함께 커밋되거나 롤백되는 것을 보장한다.
Two-phase commit mechanism은 다음과 같이 두 단계로 작업이 이루어진다.
-
First Phase는 각 데이터베이스 노드에 커밋을 하기 위한 준비 요청 단계이다.
다음은 First Phase가 실행되는 과정이다.
-
TM은 각 데이터베이스 노드에 커밋을 준비하라는 prepare 메시지를 보낸다.
-
요청을 받은 각 데이터베이스는 커밋을 준비한다.
커밋을 하기 위한 준비 작업에는 필요한 리소스에 잠금(Lock)을 설정하거나 로그 파일을 저장하는 작업 등이 있다.
-
각 데이터베이스는 커밋 준비 여부에 따라 TM에 성공 또는 실패 여부를 알린다.
커밋 준비가 모두 끝나면 prepare가 성공한 것이고, 커밋 준비를 실패하면 prepare가 실패한 것이다.
-
-
TM은 참여한 모든 데이터베이스 노드로부터 prepare의 완료 메시지를 받을 때까지 대기한다.
이 단계에서는 전달 받은 prepare의 메시지에 따라 해당 결과가 다르다.
Two-phase commit mechanism에 의해 첫 번째 prepare 메시지를 받으면 데이터베이스는 분산 트랜잭션에 해당하는 리소스를 잠금 처리하거나 로그를 남김으로써 커밋할 준비를 한다. 그런데 prepare까지 마친 상태에서 네트워크의 이상으로 다음 메시지(커밋 또는 롤백)를 받지 못하는 경우가 발생할 수 있다.
데이터베이스는 해당 트랜잭션을 커밋해야 할지 롤백해야 할지 판단할 수 없다. 따라서 다음 메시지가 올 때까지 prepare된 리소스에 잠금 처리를 한 채로 기다리게 되는데 이러한 경우를 In-doubt 트랜잭션이라고 한다.
일반적으로 네트워크 또는 TM 측의 문제가 해결된다면 복구되는 즉시 TM은 In-doubt 트랜잭션에 커밋 또는 롤백 메시지를 다시 보낸다. 하지만 In-doubt 트랜잭션이 잡고 있는 리소스가 급하게 반환 되어야 하는 상황이 발생한다면 DBA는 임의로 In-doubt 트랜잭션을 커밋 또는 롤백시킴으로써 해당 리소스를 반환할 수 있다. 이러한 경우는 DBA의 판단에 의해 결정되므로 이후에 TM으로부터 전달되는 커밋 또는 롤백 메시지가 DBA가 결정한 판단과 다르다면 전체 분산 트랜잭션이 일부 커밋되거나 롤백되는 현상이 발생할 수 있다. 따라서 전체 분산 트랜잭션의 일관성을 위해 TM의 다음 요청을 기다려야 한다.
이러한 문제를 감수하더라도 In-doubt 트랜잭션을 처리해야 하는 경우가 발생한다면 DBA_2PC_PENDING 뷰를 이용하여 이를 해결한다.
DBA_2PC_PENDING는 현재 정체되고 있는 XA 트랜잭션 브랜치(XA Transaction Branch)의 정보를 보여주는 뷰이다.
다음은 XA 트랜잭션 브랜치의 정보를 조회하는 예이다. 본 예제에서는 XID와 FAIL_TIME 정보를 이용하여 커밋과 롤백을 수행할 브랜치를 선택한다.
[예 7.1] DBA_2PC_PENDING 뷰의 조회
SQL> SELECT LOCAL_TRAN_ID, XID, STATUS, FAIL_TIME, FORCE_TIME
FROM DBA_2PC_PENDING;
LOCAL_TRAN_ID
-------------------------------------
XID
-------------------------------------
STATUS FAIL_TIME FORCE_TIME
--------------- ---------- ----------
2.16.18
1.1000.1000
PREPARED 2006/12/11
1 selected.
DBA는 다음과 같이 원하는 XA 트랜잭션 브랜치에 커밋 명령을 실행할 수 있다. 그러면 해당 XA 트랜잭션 브랜치에서 잡고 있던 리소스는 반환되고 해당 트랜잭션은 커밋된다.
SQL> commit force '2.16.18'; Commit succeeded.
DBA는 강제 커밋(commit force)을 통해 롤백할 수 있다.
SQL> rollback force '2.16.18'; Rollback succeeded.
TM에 의한 정식 커밋이 아니고 DBA의 임의의 결정으로 커밋을 실행하면 해당 XA 트랜잭션 브랜치의 정보는 그대로 남아 있는다.
다음과 같이 FORCE_TIME에 DBA가 강제로 커밋한 시간이 남아 있음을 알 수 있다.
SQL> SELECT LOCAL_TRAN_ID, XID, STATUS, FAIL_TIME, FORCE_TIME
FROM DBA_2PC_PENDING;
LOCAL_TRAN_ID
-------------------------------------
XID
-------------------------------------
STATUS FAIL_TIME FORCE_TIME
--------------- ---------- ----------
1.1000.1000
FORCED_COMMIT 2006/12/11 2006/12/12
1 selected
해당 XA 트랜잭션 브랜치의 정보는 TM이 xa_forget을 이용하여 더 이상 XA 트랜잭션 브랜치 정보가 필요 없다고 판단하면 해당 정보를 제거한다. RM에서는 TM의 요청이 있기 전까지는 XA 트랜잭션 브랜치의 정보를 제거하지 않는다.
데이터베이스 링크는 원격 데이터베이스의 데이터를 마치 로컬 데이터베이스의 데이터처럼 접근할 수 있는 방법을 제공한다. 데이터베이스 링크를 사용하면 원격 데이터베이스의 데이터에 대한 접근, 수정이 용이하며 손쉽게 분산 트랜잭션을 처리할 수 있다. 분산 트랜잭션은 트랜잭션의 원자성을 보장하기 위해 XA와 마찬가지로 Two-phase commit mechanism을 사용한다.
데이터베이스 링크는 다음과 같은 접근 권한에 따라 생성 및 제거 방법이 다르다.
Public DBLink
데이터베이스 링크를 생성한 사용자와 다른 사용자들도 데이터베이스 링크를 이용할 수 있다. Public DBLink를 생성하기 위해서는 create public database link 권한이 있어야 한다.
다음은 Public DBLink를 생성하는 예이다.
create public database link public_tibero using 'remote_2';위의 예에서 using 절 이후의 'remote_2'는 연결할 데이터베이스를 가리키는 이름으로 tbdsn.tbr 파일에 해당 데이터베이스의 연결 정보가 저장되어 있어야 한다.
다음은 Public DBLink를 제거하는 예이다. Public DBLink는 drop public database link 권한을 가진 사용자만 제거할 수 있다.
drop public database link public_tibero;
Private DBLink
데이터베이스 링크를 생성한 사용자만 데이터베이스 링크를 사용할 수 있다. Private DBLink를 생성하기 위해서는 create database link 권한이 있어야 한다.
다음은 Private DBLink를 생성하는 예이다.
create database link remote_tibero using 'remote_1';위의 예에서는 remote_1은 데이터베이스에 연결하는 remote_ tibero라는 이름의 데이터베이스 링크를 생성한다. 이 데이터베이스 링크는 Private DBLink이므로 생성한 사용자 외에는 사용할 수 없다.
다음은 Private DBLink를 제거하는 예이다. Private DBLink는 생성한 사용자만 제거할 수 있다.
drop database link remote_tibero;
원격 데이터베이스와의 연결에 사용하는 계정을 설정하는 방법은 다음과 같이 두 가지가 있다.
| 설정 방법 | 설명 |
|---|---|
| 지정한 계정 | 지정한 ID와 패스워드를 사용해 원격 데이터베이스에 접속한다. 단, 지정한 ID와 패스워드를 가진 계정이 원격 데이터베이스에 존재해야 한다. 어떤 사용자가 사용하더라도 데이터베이스 링크를 생성할 때에는 지정한 ID와 패스워드를 사용해야 한다. |
| 현재 연결된 계정 | 현재 질의를 수행한 사용자의 ID와 패스워드를 사용해 원격 데이터베이스에 접속한다. 데이터베이스 링크를 사용하는 사용자의 ID와 패스워드가 원격 데이터베이스에 동일하게 존재해야 한다. 계정을 지정하지 않으면 기본으로 현재 연결된 계정으로 접속하도록 설정된다. 따라서 데이터베이스 링크를 사용하는 사용자별로 다른 ID와 패스워드를 사용한다. |
원격 데이터베이스에 연결하기 위한 계정은 CREATE SESSION 등의 권한을 가져야 하며, 데이터베이스 링크를 통해 원격 데이터베이스의 연결에 사용된 계정의 권한을 로컬 사용자가 획득하게 되므로 권한 관리에 유의해야 한다. 특히 Public DBLink의 경우에는 모든 로컬 사용자가 원격 데이터베이스에 대한 권한을 갖기 때문에 주의하여 사용해야 한다.
다음은 지정한 계정을 이용하는 데이터베이스 링크의 생성 예이다.
create database link remote_tibero connect to user1
identified by 'password' using 'remote_1';
다음은 현재 연결된 계정을 이용하는 데이터베이스 링크의 생성 예이다.
create database link remote_tibero using 'remote_1';
데이터베이스 링크를 통해 질의를 수행할 때 데이터베이스 링크의 대상이 Tibero가 아닌 다른 DBMS라면 각각의 DBMS를 위한 게이트웨이를 통해 데이터베이스 링크를 수행할 수 있다.
Tibero 서버는 다른 DBMS에 필요한 질의를 해당 게이트웨이에 전달한다. 게이트웨이는 원격 DBMS에 접속하여 Tibero 서버로부터 전달 받은 질의를 수행하고 그 결과를 다시 Tibero 서버로 전송한다.
다른 DBMS로의 데이터베이스 링크 기능을 사용하는 경우에는 해당 DBMS에 대한 게이트웨이 바이너리와 설정 파일이 필요하다.
본 절에서는 DBMS 벤더별로 게이트웨이의 종류를 설명하고, 게이트웨이와 Tibero 서버가 같은 머신에 존재하는 경우와 다른 머신에 존재하는 경우를 알아본다. 또한 게이트웨이에서 제공하는 옵션 및 로깅도 설명한다.
DBMS 벤더별 게이트웨이
다음은 Tibero에서 데이터베이스 링크 기능을 지원하고 있는 다른 DBMS의 종류와 게이트웨이 바이너리명이다.
| DBMS 벤더명 | 게이트웨이 바이너리명 | 프로그래밍 언어 | DBMS 버전 |
|---|---|---|---|
| Oracle | gw4orcl | C | Oracle 9i, 10g, 11g |
| DB2 | gw4db2 | C | DB2 V8, V9, V10 |
| MS-SQL Server | tbgateway.jar | Java | MS-SQL Server 2000, 2005, 2008 |
| Adaptive Server Enterprise(Sybase) | tbgateway.jar | Java | Sybase SQL Server 10.0.2 or later |
| GREENPLUM | tbgateway.jar | Java | GREENPLUM or PostgreSQL |
각각의 게이트웨이 바이너리는 DBMS의 버전에 따라 다를 수 있기 때문에 버전에 맞는 게이트웨이 바이너리를 사용할 것을 권장한다.
참고
DB2 게이트웨이의 경우 HP PA-RISC 머신은 지원하지 않으며, Solaris SPARC 머신에서는 v10 클라이언트를 지원하지 않는다.
게이트웨이 프로세스 생성 방식
일반적으로 사용되는 게이트웨이 사용 방식이며 Windows를 제외한 환경에서 사용 가능하다.
게이트웨이는 연결할 DBMS가 제공하는 라이브러리가 필요하다. 라이브러리를 Tibero 서버가 설치된 곳에서 사용할 수 있다면 Tibero 서버와 같은 머신 내에서 게이트웨이 프로세스를 생성하여 데이터베이스 링크 기능을 수행할 수 있다. 생성된 게이트웨이 프로세스는 해당 데이터베이스 링크를 사용하는 세션이 닫힐 때 종료된다.
다음은 Oracle 서버와 연결하는 데이터베이스 링크를 사용하기 위해 tbdsn.tbr 파일을 설정하는 예이다.
<tbdsn.tbr>
ora_dblink=(
(GATEWAY=(PROGRAM=gw4orcl)
(TARGET=orcl)
(TX_MODE=GLOBAL))
)
다음은 DB2 서버와 연결하는 데이터베이스 링크를 사용하기 위해 tbdsn.tbr 파일을 설정하는 예이다.
<tbdsn.tbr>
db2_dblink=(
(GATEWAY=(PROGRAM=gw4db2)
(TARGET=sample)
(TX_MODE=GLOBAL))
)
| 항목 | 설명 |
|---|---|
| PROGRAM | 게이트웨이 바이너리 위치에 대한 절대 경로이다. 게이트웨이 바이너리가 $TB_HOME/client/bin 디렉터리에 있는 경우 바이너리 이름만 명시할 수 있다. |
| TARGET | DBMS별로 다음과 같이 의미하는 것이 다르다.
|
| TX_MODE | 글로벌 트랜잭션(Global Transaction) 또는 로컬 트랜잭션(Local Transaction)으로 처리할지의 여부를 설정한다. 글로벌 트랜잭션은 커밋을 요청할 때 Two-phase commit으로 동작하고, 로컬 트랜잭션은 Two-phase commit으로 동작하지 않는다. TX_MODE의 값은 처리 여부에 따라 다음과 같이 설정할 수 있다.
|
| BYTES_CHARSET | 게이트웨이의 초기화 파라미터 ENCODING의 값을 무시하고 다른 문자 집합(character set)으로 변환할 때 설정한다. Tibero 서버에서 지원하는 문자 집합을 사용할 수 있다. |
| CONFIG | 게이트웨이 설정 파일 위치에 대한 절대 경로이다. |
만약 TARGET 서버의 문자 집합이 EUCKR이고 Tibero 서버의 문자 집합이 ASCII이면 SELECT를 할 때 ASCII 범위를 벗어나는 문자는 '?'로 표시되어 출력된다. 하지만 'BYTES_CHARSET=EUCKR'로 설정하면 게이트웨이 ENCODING과 Tibero 서버의 문자 집합과는 무관하게 EUCKR 문자로 처리하게 되어 SELECT를 할 때 정상적인 EUCKR 문자를 확인할 수 있다.
멀티 스레드 서버 방식
프로세스 생성 방식을 사용할 수 없을 때 사용되는 방식이며 Windows 환경에서는 이 방식만 지원된다.
사용자는 Tibero 서버와 같은 머신 또는 원격에 있는 머신에서 게이트웨이를 멀티 스레드 서버 방식으로 시작할 수 있다. Tibero 서버의 세션은 tbdsn.tbr 파일에 명시된 접속 정보를 통해 게이트웨이와 TCP/IP 통신을 한다. 멀티 스레드 서버 방식의 게이트웨이는 Tibero 서버의 세션으로부터 요청이 오면 미리 생성된 워킹 스레드 중 하나가 해당 요청을 처리한다.
다음은 Oracle 서버와 연결하는 데이터베이스 링크를 사용하기 위해 tbdsn.tbr 파일을 설정하는 예이다.
<tbdsn.tbr>
ora_link_remote=(
(GATEWAY=(LISTENER=(HOST=12.34.56.78)
(PORT=9999))
(TARGET=orcl)
(TX_MODE=GLOBAL))
)
다음은 DB2 서버와 연결하는 데이터베이스 링크를 사용하기 위해 tbdsn.tbr 파일을 설정하는 예이다.
<tbdsn.tbr>
db2_link_remote=(
(GATEWAY=(LISTENER=(HOST=12.34.56.78)
(PORT=9999))
(TARGET=sample)
(TX_MODE=GLOBAL))
)
| 항목 | 설명 |
|---|---|
| LISTENER |
|
| TARGET | DBMS별로 다음과 같이 의미하는 것이 다르다.
|
| TX_MODE | 글로벌 트랜잭션(Global Transaction) 또는 로컬 트랜잭션(Local Transaction)으로 처리할지의 여부를 설정한다. TX_MODE의 값은 처리 여부에 따라 다음과 같이 설정할 수 있다.
|
원격에 있는 게이트웨이를 사용하기 위해서는 먼저 원격에 있는 게이트웨이를 실행시켜야 한다.
다음은 Windows가 아닌 환경의 원격에서 Oracle 서버의 게이트웨이를 실행시키는 예이다.
$ gw4orcl
멀티 스레드 방식에서는 프로세스 생성 방식에서와는 다르게 게이트웨이와 Tibero 서버 사이의 연동 관계가 없기 때문에 게이트웨이를 종료시키기 위해서는 kill 명령 등으로 직접 프로세스를 종료해야 한다.
Windows 환경에서는 아래와 같이 게이트웨이를 서비스로 등록해서 사용해야 한다. (띄어쓰기 주의)
> sc create [리스너 이름] binPath= [게이트웨이 바이너리 위치]\gw4orcl.exe
서비스 등록 이후 제어판 > 관리도구 > 서비스에서 [리스너 이름]을 시작 또는 종료하면 된다.
공통 설정 부분
게이트웨이는 기본적으로 TBGW_HOME 환경변수를 통해 설정 파일을 읽고 로그 파일을 기록한다.
TBGW_HOME 환경변수가 설정되어 있지 않은 경우 디폴트 값은 ${TB_HOME}/client/gateway이다. Windows 환경에서는 디폴트 값이 %TB_HOME%\client\gateway로 설정된다.
게이트웨이가 사용하는 설정 파일과 로그 파일이 존재하는 디렉터리 구조는 다음과 같다.
$TBGW_HOME |--- DBMS 벤더명 |--- config | |--- tbgw.cfg |--- log | --- 게이트웨이의 로그 파일
위의 디렉터리 구조에서 $TBGW_HOME이라고 보이는 부분은 시스템 환경에 맞게 바꿔서 읽어야 한다.
- DBMS 벤더명/config
-
tbgw.cfg라는 게이트웨이 설정 파일이 있다. 사용자가 게이트웨이와 관련된 설정 값을 변경하고 싶을 때 생성하며, 위의 디렉터리 구조에 맞게 위치시킨다.
- DBMS 벤더명/log
-
게이트웨이와 관련된 로그 파일이 있다. 로그 파일은 DBMS 벤더명에 맞춰 생성된다. 로그 파일명은 DBMS 벤더 이름, 시간, pid, tid로 구성되어있으며 prefix는 게이트웨이이다.
tbgw.cfg 파일에 초기화 파라미터의 설정값을 명시함으로써 게이트웨이와 관련된 설정을 변경할 수 있다.
다음은 게이트웨이를 설정하는 예이다.
<tbgw.cfg>
LOG_DIR=${TBGW_HOME}/{DBMS 벤더명}/log
LOG_LVL=2
LISTENER_PORT=9999
MAX_LOG_SIZE=20k
FETCH_SIZE=32k
| 초기화 파라미터 | 설명 |
|---|---|
CHARACTER_SET | 게이트웨이의 문자집합을 설정한다. 만약 이 값이 설정되지 않은 경우 TB_NLS_LANG 환경변수에 정의된 값을 사용한다. (기본값: MSWIN949) |
FETCH_SIZE | 데이터베이스에 질의 처리를 할 때 한번에 가져오는 데이터의 크기를 설정한다. (기본값: 32KB , 최댓값: 64KB) |
IGNORE_WARNING | 원격 데이터베이스에서 발생한 경고 메시지를 무시할지 여부를 설정한다. (기본값: N) |
LOG_DIR | 게이트웨이의 로그 파일을 저장할 경로를 설정한다. (기본값: ${TBGW_HOME}/{DBMS 벤더명}/log) |
LOG_LVL | 로그 파일에 남길 로그 레벨을 설정한다. (기본값: 2) |
MAX_LOG_BACKUP_SIZE | 로그 백업 기능을 사용하는 경우 백업 로그 파일들의 최대 크기이다. (기본값: 0, 단위: Byte)
|
MAX_LOG_SIZE | 로그 파일의 최대 크기이다. (기본값: 0, 단위: Byte)
|
QUERY_WITH_UR | DB2용 게이트웨이에만 사용 가능한 옵션이다. 쿼리에 WITH UR 구문을 추가할지 여부를 설정한다. (기본값: N) |
SKIP_CHAR_CONV | Oracle용 게이트웨이에만 사용 가능한 옵션이다. (기본값: N)
|
다음은 게이트웨이를 리스너 모드로 사용할 때 설정할 수 있는 옵션이다.
| 옵션 | 설명 |
|---|---|
LISTENER_PORT | 리스너 포트 번호를 설정한다. 설정한 포트 번호의 값으로 포트가 오픈되며, 설정값+1의 추가 포트가 Statement Cancle을 처리하기 위해 오픈된다. (기본값: 9999) |
MIN_POOL_SIZE | 동시에 접속 가능한 최소 세션 개수를 설정한다. (기본값: 10) |
MAX_POOL_SIZE | 동시에 접속 가능한 최대 세션 개수를 설정한다. (기본값: 100, 최댓값: 128) |
게이트웨이 바이너리의 버전
게이트웨이 바이너리의 버전은 다음과 같은 명령을 실행하여 확인할 수 있다.
$ gw4orcl -v Tibero 5 SP1 Gateway for oracle (Build 70000) Linux Tibero_Linux 2.6.22-16-generic #1 SMP Mon Nov 24 17:50:35 GMT 2008 x86_64 GNU/Linux version (little-endian)
Java 게이트웨이는 멀티 스레드 서버 방식만 사용 가능하다.
멀티 스레드 서버 방식
다음은 MS-SQL 서버와 연결하는 데이터베이스 링크를 사용하기 위해 tbdsn.tbr 파일을 설정하는 예이다.
<tbdsn.tbr>
mssql_link_remote=(
(GATEWAY=(LISTENER=(HOST=12.34.56.78)
(PORT=9093))
(TARGET=192.168.16.25:1433:master)
(TX_MODE=LOCAL))
)
다음은 Sybase ASE 서버와 연결하는 데이터베이스 링크를 사용하기 위해 tbdsn.tbr 파일을 설정하는 예이다.
<tbdsn.tbr>
ase_link_remote=(
(GATEWAY=(LISTENER=(HOST=12.34.56.78)
(PORT=9093))
(TARGET=192.168.16.25:5000:master)
(TX_MODE=LOCAL))
)
다음은 GREENPLUM 및 PostgreSQL 서버와 연결하는 데이터베이스 링크를 사용하기 위해 tbdsn.tbr 파일을 설정하는 예이다.
<tbdsn.tbr>
gp_link_remote=(
(GATEWAY=(LISTENER=(HOST=12.34.56.78)
(PORT=9093))
(TARGET=192.168.16.25:5000:master)
(TX_MODE=LOCAL))
)
사용자는 ${TB_HOME}/client/bin에 있는 tbgateway.zip 파일을 설치할 디렉터리에 복사한 후 압축을 해제한다. 기본적으로 타깃 데이터베이스에 대한 JDBC 드라이버 파일(jconn3.jar, sqljdbc.jar)은 제공하지 않는다. 따라서 사용자는 해당 DBMS의 웹사이트를 접속하여 JDBC 드라이버 파일을 다운로드 후 LIB 디렉터리에 복사한다.
참고
SQLServer의 JDBC인 sqljdbc.jar 파일은 Java 6.0 이상의 환경에서는 사용할 수 없으므로 sqljdbc4.jar 파일을 사용한다.
Java 게이트웨이가 사용하는 설정 파일과 로그 파일이 존재하는 디렉터리 구조는 다음과 같다.
설치 디렉터리 |--- tbJavaGW |--- jgw.cfg |--- jgwlog.properties |--- tbgw |--- lib | |--- tbgateway.jar | |--- commons-collections.jar | |--- commons-pool.jar | |--- log4j-1.2.15.jar |--- log | --- 게이트웨이의 로그 파일
- tbJavaGW/jgw.cfg
-
게이트웨이 설정 파일이다. 사용자가 게이트웨이와 관련된 설정 값을 변경하고 싶을 때 생성하며 위의 디렉터리 구조에 맞게 위치시킨다.
- tbJavaGW/jgwlog.properties
-
로그에 대한 설정 파일이다. 로그 파일의 크기와 로그 레벨 등을 설정할 수 있다. 자세한 형식은 LOG4J를 참고한다.
- tbJavaGW/tbgw
-
Java 게이트웨이를 실행시키는 스크립트 파일이다.
- tbJavaGW/lib
-
Java 게이트웨이에서 사용하는 JAR 파일이 있는 디렉터리이다. 타깃 데이터베이스의 JDBC 드라이버도 해당 디렉터리에 있다.
- tbJavaGW/log
-
게이트웨이와 관련된 로그 파일이 생성된다.
jgw.cfg 파일에 초기화 파라미터의 설정 값을 명시함으로써 게이트웨이와 관련된 설정을 변경할 수 있다.
다음은 게이트웨이를 설정하는 예이다.
<jgw.cfg>
DATABASE=SQL_SERVER LISTENER_PORT=9093 INIT_POOL_SIZE=10 MAX_POOL_SIZE=100 MAX_CURSOR_CACHE_SIZE=100 ENCODING=MSWIN949 MAX_LONGVARCHAR=4K MAX_LONGRAW=4K
| 초기화 파라미터 | 설명 |
|---|---|
DATABASE | 타깃 데이터베이스를 설정한다.
|
LISTENER_PORT | 리스너의 포트 번호를 설정한다. 일반적인 요청의 처리를 위해 설정한 번호의 포트를 사용하며, Statement cancel등의 제어 요청 처리를 위해 설정에 1을 더한 번호의 포트를 추가로 사용한다. (기본값: 9093) |
INIT_POOL_SIZE | Java 게이트웨이가 시작할 때 미리 생성할 워킹 스레드의 개수를 설정한다. (기본값: 10) |
MAX_POOL_SIZE | Java 게이트웨이가 최대로 생성할 수 있는 워킹 스레드의 개수를 설정한다. (기본값: 100) |
MAX_CURSOR_CACHE_SIZE | 워킹 스레드 당 최대로 캐시 가능한 커서의 개수를 설정한다. (기본값: 100) |
ENCODING | Tibero 서버의 세션에 문자열을 전달할 때 사용할 인코딩을 설정한다. 단, Tibero 서버의 문자 집합과 일치시켜야 한다. 설정할 수 있는 문자 집합은 다음과 같다.
|
MAX_LONGVARCHAR | 게이트웨이는 LONG, CLOB 타입의 데이터를 일정 간격을 정하여 가져오는 방식(Deferred 형태)을 지원하지 않는다. CHAR나 VARCHAR 타입처럼 한 번에 읽어 오게 되는데 그때 읽어올 수 있는 최대 크기를 설정한다. (기본값: 4KB, 최댓값: 32KB) |
MAX_LONGRAW | 게이트웨이는 LONG RAW, BLOB 타입의 데이터를 일정 간격을 정하여 가져오는 방식을 지원하지 않는다. RAW처럼 한 번에 읽어 오게 되는데 그때 읽어올 수 있는 최대 크기를 설정한다. (기본값: 4KB, 최댓값: 32KB) |
Java 게이트웨이는 멀티 스레드 서버 방식으로 Tibero 서버와 직접적인 연동 관계가 없기 때문에 원격에 있는 게이트웨이를 사용하기 위해서는 먼저 아래 명령을 통하여 Java 게이트웨이를 실행시켜 주어야 한다. 또한 Java 게이트웨이를 종료시키기 위해서는 kill 명령 등으로 직접 프로세스를 종료해주어야 한다.
다음은 UNIX(또는 Linux) 계열의 환경에서 Java 게이트웨이를 실행하는 예이다.
$ ./tbgw ------------------------------- Name : TIBERO JAVA GATEWAY Port : 9093 ------------------------------- $
Windows 환경에서 Java 게이트웨이를 실행하기 위해서 Windows 서비스 등록을 통한 방법을 제공하고 있다. Java 게이트웨이를 서비스에 등록하기 위해서 다음의 모듈이 필요하다.
| 모듈 | 설명 |
|---|---|
| commons-daemon.jar | 서비스 등록, 해제를 위한 모듈이다. |
| prunsrv.exe | 실행 프로그램이다. |
| prunmgr.exe | 서비스 관리 프로그램이다. |
| service_gw.bat | Java 게이트웨이 등록, 해제를 위한 스크립트 파일이다. |
참고
commons-daemon.jar, prunscr.exe, prunmgr.exe 파일은 http://apache.tt.co.kr/commons/daemon/binaries/에서 다운로드 받을 수 있다. 다운로드 받은 파일들을 Java 게이트웨이 홈 디렉터리로 이동시킨다.
다음 명령으로 Java 게이트웨이 서비스를 등록할 수 있다.
c:\tbgateway> service_gw.bat install
이후 [관리도구] > [서비스]에서 " tbgateway"으로 등록된 Java 게이트웨이를 시작할 수 있다.
또는 아래 명령을 통해서 관리 프로그램을 실행시킬 수 있다.
c:\tbgateway> prunmgr.exe //ES//tbgateway
Java 게이트웨이 서비스 해제를 위해서는 다음 명령을 수행한다.
c:\tbgateway> service_gw.bat uninstall
Java 게이트웨이 바이너리의 버전
Java 게이트웨이 바이너리의 버전은 다음과 같은 명령을 실행하여 확인할 수 있다.
$ ./tbgw -v TIBERO tbgateway 5.0.68493 Usage: GatewayMain [PARAMETER1=VALUE] [PARAMETER2=VALUE] ... Parameters: CONFIG Config File path and name, default: jgw.cfg
데이터베이스 링크를 통해 접근할 수 있는 데이터베이스 객체의 종류는 다음과 같다.
-
테이블(LOB와 LONG 타입의 컬럼에는 접근할 수 없다)
-
뷰
-
시퀀스
데이터베이스 링크를 사용할 수 있는 SQL 문장은 SELECT, INSERT, UPDATE, DELETE 이다. 단, SELECT 문에서 FOR UPDATE 절은 사용할 수 없다.
Homogeneous DBLink로 구성된 분산 트랜잭션은 Global Consistency를 제공한다. 이를 위해 분산 트랜잭션에 참여한 데이터베이스 간에 TSN을 동기화하는 작업을 한다.
TSN을 동기화하는 작업은 데이터베이스 사이에 메시지를 교환할 때 이루어지며, 커밋할 때에는 모든 노드의 Commit TSN을 동일하게 동기화해야 한다.
정체되고 있는 TX에 대한 처리는 XA의 경우와 동일하다. 본 절에서는 Two-phase commit mechanism에서 XA와의 차이점을 설명한다.
commit point site
데이터베이스 링크를 사용한 분산 트랜잭션에서는 트랜잭션에 참여한 노드 중에서 commit point site를 선정한다.
commit point site는 Two-phase commit을 시작할 때 설정하며 세션 트리를 따라가며 가장 큰
commit point strength를 가진 노드를 선택한다. 각 데이터베이스는 commit point strength를
가지는데 이 값은 초기화 파라미터 COMMIT_POINT_STRENGTH로 설정할 수
있다.
commit point site는 Two-phase commit의 prepare phase에서 prepare를 하지 않는다. 대신 모든 노드가 prepare를 한 이후에 commit point site를 바로 커밋한다. 그 이후에 다른 노드들은 commit phase를 실행한다.
데이터베이스 링크에서 이와 같이 수정된 Two-phase commit을 사용하는 이유는 Global consistency를 보장하기 위해 생기는 오버헤드를 줄이기 위해서이다. 데이터베이스 링크에서 Global consistency를 보장하기 위해서는 모든 노드의 Commit TSN을 동일하게 해야 한다. Commit TSN은 prepare phase까지 완료한 노드 중 가장 큰 TSN으로 결정하고 commit phase에서 결정된 TSN을 사용해 커밋을 한다.
commit phase 전에는 Commit TSN을 모르기 때문에 다른 트랜잭션에서 해당 트랜잭션의 수정 정보의 조회 여부를 결정할 수 없다. 다른 트랜잭션에서 prepare된 TX가 수정한 내용에 접근하는 경우 다음과 같은 에러가 발생한다.
TBR-21019: lock held by in-doubt distributed transaction.
데이터베이스 링크를 사용할 때 prepare 상태에서 정체가 발생하는 경우 해당 데이터에 접근할 수 없기 때문에 In-doubt 트랜잭션으로 인한 문제가 발생된다.
이와 같은 문제를 경감하기 위해 트랜잭션에 참여한 노드 중 한 노드는 Prepare Phase를 거치지 않고, 트랜잭션이 in-doubt 상태가 되더라도 commit point site는 위와 같이 데이터를 접근하지 못하는 상황을 방지할 수 있도록 하였다. 따라서 commit point strength는 데이터 접근성이 많이 필요한 데이터베이스일수록 큰 값을 설정해야 한다.
Tibero에서는 생성한 데이터베이스 링크의 정보를 제공하기 위해 다음 표에 나열된 정적 뷰를 제공하고 있다.
| 정적 뷰 | 설명 |
|---|---|
| DBA_DB_LINKS | Tibero 내의 모든 데이터베이스 링크의 정보를 보여주는 뷰이다. DBA만 사용할 수 있는 뷰이다. |
| ALL_DB_LINKS | 현재 사용자가 이용할 수 있는 모든 데이터베이스 링크의 정보를 보여주는 뷰이다. |
| USER_DB_LINKS | 현재 사용자가 생성한 데이터베이스 링크의 정보를 보여주는 뷰이다. |
참고
정적 뷰에 대한 자세한 내용은 "Tibero 참조 안내서"를 참고한다.
V$DBLINK
동적 뷰 V$DBLINK는 해당 세션에서 원격 데이터베이스에 연결된 데이터베이스 링크의 정보를 보여주는 뷰이다.
사용자가 데이터베이스 링크를 통해 질의를 수행하면 원격 데이터베이스에 연결을 생성하고, 해당 질의 또는 트랜잭션이 종료되어도 연결을 해제하지 않고 계속 유지된다. 즉, 같은 데이터베이스 링크를 사용했을 때 발생하는 연결의 비용을 줄이기 위함이다. 이렇게 생성된 연결은 세션이 종료 또는 명시적으로 연결을 종료할 때까지 계속 유지된다.
다음은 remote_tibero를 통해 SELECT 문을 수행한 후 V$DBLINK를 통해 연결 정보를 조회하는 예이다.
SQL> select * from employee@remote_tibero; ID NAME --- --------- 1 KIM 2 LEE 3 HONG 3 rows selected. SQL> select * from V$DBLINK; DB_LINK OWNER_ID OPEN_CURSORS IN_TRANSACTION HETEROGENEOUS ------------- ---------- ------------ -------------- ------------- REMOTE_TIBERO 15 0 YES NO COMMIT_POINT_STRENGTH --------------------- 1 1 row selected.
현재 remote_tibero의 소유자의 ID는 15번이고, 현재 열려있는 커서는 없으며 트랜잭션을 수행하고 있다. 동일한 Tibero 서버에 대한 데이터베이스 링크이며, 원격 데이터베이스의 commit point strength는 1이다.
다음은 데이터베이스 링크 기능을 종료하는 예이다.
SQL> alter session close database link remote_tibero; TBR-12056: database link is in use. ... ① ... SQL> commit; ... ② ... Commit succeeded. SQL> alter session close database link remote_tibero; ... ③ ... Session altered. SQL> select * from V$DBLINK; ... ④ ... DB_LINK OWNER_ID OPEN_CURSORS IN_TRANSACTION HETEROGENEOUS -------------- ---------- ------------ -------------- ------------- COMMIT_POINT_STRENGTH --------------------- 0 row selected.
① 데이터베이스 링크 기능을 종료하려는 시도가 실패한 이유는 해당 데이터베이스 링크를 사용한 트랜잭션이 아직 수행 중이기 때문이다.
② commit 문을 통해 해당 트랜잭션을 종료한다.
③ 다시 데이터베이스 링크 기능의 종료를 시도한다.
④ 정상적으로 데이터베이스 링크가 종료되며 이를 확인하는 방법은 V$DBLINK를 통해 확인할 수 있다.