내용 목차
본 장에서는 Tibero Active Cluster의 기본 개념과 구성요소, 프로세스, 실행 및 운영 방법을 설명한다.
Tibero Active Cluster(이하 TAC)는 확장성, 고가용성을 목적으로 제공하는 Tibero의 주요 기능이다. TAC 환경에서 실행 중인 모든 인스턴스는 공유된 데이터베이스를 통해 트랜잭션을 수행하며 공유된 데이터에 대한 접근은 데이터의 일관성과 정합성 유지를 위해 상호 통제하에 이뤄진다.
큰 업무를 작은 업무의 단위로 나누어 여러 노드 사이에 분산하여 수행할 수 있기 때문에 업무 처리 시간을 단축할 수 있다.
여러 시스템이 공유 디스크를 기반으로 데이터 파일을 공유한다. TAC 구성에 필요한 데이터 블록은 노드 간을 연결하는 고속 사설망을 통해 주고받음으로써 노드가 하나의 공유 캐시(shared cache)를 사용하는 것처럼 동작한다.
운영 중에 한 노드가 멈추더라도 동작 중인 다른 노드들이 서비스를 지속하게 된다. 이러한 과정은 투명하고 신속하게 처리된다.
다음은 TAC의 구조를 나타내는 그림이다.
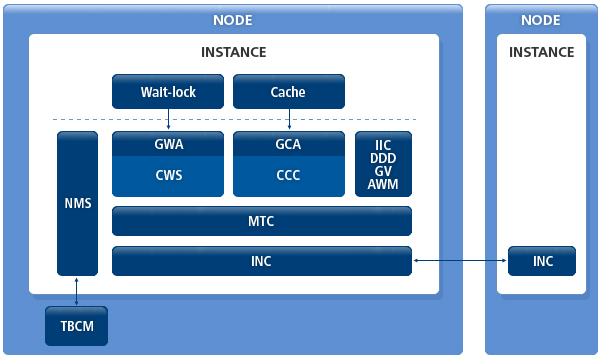
TAC의 구조는 다음과 같은 모듈로 구성되어 있다.
-
-
Cache layer에서 CCC 서비스를 사용하기 위한 인터페이스 역할을 수행하는 모듈이다.
-
CCC에 접근하기 위한 핸들인 CCC LKSB와 파라미터를 설정하고 관리하며 Cache layer에서 사용하는 block lock mode를 CCC에 맞게 변환한다.
-
CCC의 lock-down event에 맞춰 데이터 블록이나 Redo 로그를 디스크에 저장하는 기능과 DBWR가 Global wirte를 요청하거나 CCC에서 DBWR에게 block write를 요구하는 인터페이스를 제공한다.
-
CCC에서는 GCA를 통해 CR block, Global dirty block, current block을 주고받는다.
-
-
MTC(Message Transmission Control)
-
노드 간의 통신 메시지의 손실과 out-of-order 문제를 해결하는 모듈이다.
-
문제를 해결하기 위해 retransmission queue와 out-of-order message queue를 관리한다.
-
General Message Control(GMC)을 제공하여 CWS/CCC 이외의 모듈에서 노드 간의 통신이 안전하게 이루어지도록 보장한다.
현재 Inter-instance call(IIC), Distributed Deadlock Detection(이하 DDD), Automatic Workload Management에서 노드 간의 통신을 위해 GMC를 사용하고 있다.
-
-
-
노드 간의 네트워크 연결을 담당하는 모듈이다.
-
INC를 사용하는 사용자에게 네트워크 토폴로지(network topology)와 프로토콜을 투명하게 제공하며 TCP, UDP 등의 프로토콜을 관리한다.
-
-
-
TBCM으로부터 전달받은 정보(node id, ip address, port, incarnamtion number)와 node workload를 나타내는 가중치(weight)를 관리하는 모듈이다.
-
node 멤버십의 조회, 추가, 삭제 기능을 제공하며 이와 관련된 배경 프로세스로 NMGR이 있다.
-
TAC는 8개의 프로세스가 추가로 생성된다. 이러한 프로세스는 다음과 같은 그룹에 각각 포함된다.
-
Active Cluster Server(Message handler)
-
ACSn
클러스터 내의 원격 노드로부터 CWS/CCC의 lock operation과 reconfiguration 요청(request)을 받아 처리하고 응답하는 프로세스이다.
ACSn 프로세스는 다음과 같은 특징이 있다.
-
CR block request를 받아 주어진 스냅샷(snapshot)에 해당하는 CR block을 생성하고 요청자에게 전송한다.
-
Current block request를 받으면 local block cache에 존재하는 Current block을 읽어서 요청자에게 전송한다.
-
Global write request를 받아 주어진 데이터 블록이 dirty이면 BLKW가 이를 디스크에 기록하도록 지시한다.
-
MTC IIC request를 받아 처리한다.
-
MLD(Master Lookup Directory) lookup/remove request를 받아 처리한다.
-
ACS는 여러 개가 실행될 수 있기 때문에 숫자(1, 2, 3, ..., n)로 구분한다.
-
4 종류의 스레드(thread)로 구성된다.
스레드 설명 acfm(active cluster frame monitor)
ACS의 메인 스레드로서 나머지 스레드를 감독한다.
-
stop
-
resume
-
kill
dspc(dispatcher) 원격 노드로부터 메시지가 도착하기를 기다리며, 메시지가 도착하면 해당 소켓을 rcvr 스레드로 전달한다. rcvr(receiver) dspc 스레드로부터 받은 소켓을 읽어서 해당 메시지의 요청을 처리한다.
rcvr 스레드는 모든 dspc 스레드로부터 사용할 수 있는 공통 풀(pool)로 생성되며
ACF_RCVR_CNT초기화 파라미터에 설정된 값만큼 생성된다.sndr(sender) 세션으로부터 전송해야 할 메시지를 넘겨 받고 보내야 할 원격 노드의 소켓을 찾아 네트워크로 보내는 역할을 수행한다. -
-
-
-
Lock Assistant Server
-
LASW, LASC
CWS/CCC에서 세션을 담당하는 워킹 스레드가 처리해야 할 비동기적 업무를 대신 수행하는 프로세스이다.
LASW, LASC 프로세스는 다음과 같은 특징이 있다.
-
BAST를 맞거나 스스로 잠금을 설정할 때 캐시된 lock mode를 downgrade하기 전에 BLKW로부터 disk write notification이나 LOGW로부터 log flush를 기다린 후 master에게 lock downgrade를 통보한다(이 특징은 LASC 프로세스만이 수행할 수 있다).
-
BLKW가 master로부터 받은 global write request 처리를 완료한 후 LASC에게 통보해 준다. 또한 master에게 write done notify를 보낸다. 이 특징은 LASC 프로세스만이 수행할 수 있다.
-
shadow resource block를 reclaim하기 전에 master에게 MC lock에 대한 제거 요청을 보낸다. 요청을 보낸 후 이에 대한 응답을 받아서 처리한다.
-
-
-
Lock Daemon
-
LKDW, LKDC
주기적으로 lock resource을 관리하고 타임아웃을 체크하는 프로세스이다.
LKDW, LKDC 프로세스는 다음과 같은 특징이 있다.
-
DDD(Distributed Deadlock Detection)를 수행하기 위해 주기적으로 타임아웃이 발생한 lock waiter를 체크한다. 체크할 때 교착 상태가 발생하면 DDD를 시작한다.
-
MTC retransmission queue에 설정된 메시지를 주기적으로 검사해서 타임아웃이 발생한 메시지를 다시 전송한다.
-
주기적으로 TSN의 동기화를 수행한다(이 특징은 LKDW 프로세스만이 수행할 수 있다).
-
lock resource를 위한 공유 메모리가 부족하게 되면 resource block reclaiming을 시작하여 필요한 리소스를 확보한다.
-
-
-
Reconfiguration process
-
RCOW, RCOC
NMGR 프로세스로부터 node join 및 leave event를 받아 CWS/CCC lock remastering/recovery을 수행한다.
-
-
Node Manager
-
NMGR
TBCM과 통신하여 node join 및 leave event를 받아 처리하며 node 멤버십을 관리한다. 또한 RCOC, RCOW 프로세스에 의해 수행되는 CWS/CCC reconfiguration을 통제(suspend 또는 resume)한다.
-
TAC는 기본적으로 싱글 인스턴스일 때의 설정은 그대로 사용한다. 이 외에는 추가로 설정해야 할 초기화 파라미터와 주의 사항이 있다.
초기화 파라미터
다음은 TAC를 사용하기 위해 추가로 설정해야 하거나 주의해야 하는 초기화 파라미터의 예이다.
<$TB_SID.tip>
TOTAL_SHM_SIZE=4096M DB_CACHE_SIZE=2048M CLUSTER_DATABASE=Y THREAD=0 UNDO_TABLESPACE=UNDO0 LOCAL_CLUSTER_ADDR=192.168.1.1 LOCAL_CLUSTER_PORT=12345 CM_CLUSTER_MODE=ACTIVE_SHARED
| 초기화 파라미터 | 설명 |
|---|---|
TOTAL_SHM_SIZE | 인스턴스가 사용할 전체 공유 메모리의 크기를 설정한다. |
DB_CACHE_SIZE | TAC는 버퍼 캐시 이외에도 사용하는 공유 메모리가 많다. 따라서 버퍼 캐시의 크기를 싱글 인스턴스의 경우보다 더 작게 설정해야 한다. 일반적으로 전체 공유 메모리 크기의 절반 정도가 적절하다. |
CLUSTER_DATABASE | TAC를 사용할 때 설정한다. 초기화 파라미터의 값은 반드시 'Y'로 설정해야 한다. |
THREAD | Redo 스레드의 번호로 각 인스턴스마다 고유의 번호를 부여한다. |
UNDO_TABLESPACE | Undo 테이블 스페이스의 이름으로 각 인스턴스마다 고유하게 부여한다. |
LOCAL_CLUSTER_ADDR | TAC 인스턴스 간에 통신할 내부 IP 주소를 설정한다. |
LOCAL_CLUSTER_PORT | TAC 인스턴스 간에 통신할 내부 포트 번호를 설정한다. |
CM_CLUSTER_MODE | 초기화 파라미터의 값은 반드시 ACTIVE_SHARED로 설정해야 한다. TBCM과 관련된 설명은 “제9장 Tibero Cluster Manager”를 참고한다. |
다음은 TAC를 설정할 때 주의해야 할 사항이다.
-
Redo 스레드의 번호와 Undo 테이블 스페이스의 이름은 동일한 데이터베이스를 서비스하는 서버 사이에서 유일해야 한다. “10.5. TAC를 위한 데이터베이스 생성”에서 생성한 이름이어야 한다.
-
모든 서버의 인스턴스의 설정 파일에 CONTROL_FILES와 DB_CREATE_FILE_DEST는 물리적으로 같은 파일이거나 또는 같은 디바이스를 가리키도록 설정해야 한다.
TAC는 공유 디스크 기반의 클러스터 데이터베이스이다. 여러 데이터베이스 서버의 인스턴스가 물리적으로 같은 데이터베이스 파일을 보고 사용하기 때문에 데이터베이스 생성은 한 서버에서 한번만 수행하면 된다.
모든 서버의 인스턴스가 동일한 컨트롤 파일 및 데이터 파일을 읽고 쓰게 된다. 반면 TAC에서는 공유 디스크에서 데이터 접근의 경합을 최소화하기 위해 Redo 로그 및 Undo에 대해서는 인스턴스마다 별도의 파일을 가지고 있어야 한다. Redo 로그 및 Undo 정보는 각 서버의 인스턴스들이 별도의 파일에 저장하지만 복구 상황 등에 따라 다른 인스턴스의 정보를 읽어야 하므로 반드시 공유 디스크상에 존재해야 한다.
TAC를 위한 데이터베이스 생성 절차는 다음과 같다.
-
Tibero와 관련된 환경설정 파일을 설정한 후 TBCM을 기동한다.
$ tbcm -c ... ① ... $ tbcm -b LOCK ... ② ...
① TBCM 컨트롤 파일을 초기화하는 명령으로 'y'를 입력하면 초기화된다.
② TBCM을 기동했지만 Tibero를 직접 제어하지는 않는다.
-
NOMOUNT 모드로 Tibero를 기동한다.
$ tbboot -t NOMOUNT -c -
SYS 사용자로 접속한 후 CREATE DATABASE 문을 통해 데이터베이스를 생성한다.
[tibero@tester ~]$ tbsql sys/tibero SQL> CREATE DATABASE "TAC" ... ① ... USER sys IDENTIFIED BY tibero MAXINSTANCES 8 ... ② ... MAXDATAFILES 256 CHARACTER SET MSWIN949 LOGFILE GROUP 0 'log001' SIZE 50M, GROUP 1 'log011' SIZE 50M, GROUP 2 'log021' SIZE 50M MAXLOGFILES 100 MAXLOGMEMBERS 8 NOARCHIVELOG DATAFILE 'system001' SIZE 512M AUTOEXTEND ON NEXT 8M MAXSIZE 3G DEFAULT TEMPORARY TABLESPACE TEMP TEMPFILE 'temp001' SIZE 512M AUTOEXTEND ON NEXT 8M MAXSIZE 3G EXTENT MANAGEMENT LOCAL AUTOALLOCATE UNDO TABLESPACE UNDO0 DATAFILE 'undo001' SIZE 512M AUTOEXTEND ON NEXT 8M MAXSIZE 3G EXTENT MANAGEMENT LOCAL AUTOALLOCATE Database created.
① DB_NAME으로 TAC를 지정한다.
② 접근할 서버의 최대 인스턴스의 개수를 8로 지정한다.
기존의 CREATE DATABASE 문과 비교해 달라진 부분은 없다. 다만, 데이터베이스 파일을 공유할 인스턴스의 최대 개수를 나타내는 MAXINSTANCES 파라미터를 주의해야 한다. 이 파라미터의 값은 컨트롤 파일과 데이터 파일의 헤더 등에 영향을 미치며 설정된 값 이상으로 Tibero의 인스턴스를 추가할 수 없으므로 TAC를 위해 데이터베이스를 생성할 때 충분한 값을 설정해야 한다.
앞서 설명한 것처럼 각 서버의 인스턴스는 별도의 Redo 및 Undo 공간을 가져야 한다. CREATE DATABASE 문을 실행한 시점에 생성된 Undo 테이블 스페이스 및 Redo 로그 파일은 첫 번째 인스턴스를 위한 것으로 다른 인스턴스가 데이터베이스에 접근하기 위해서는 별도의 Redo 로그 그룹과 Undo 테이블 스페이스를 생성하는 것이 필요하다.
생성된 Redo 로그 그룹은 자동으로 0번의 Redo 스레드가 된다. 따라서 CREATE DATABASE 문을 실행하기 전에 서버 인스턴스의 환경설정 파일($TB_SID.tip)의
THREAD초기화 파라미터와UNDO_TABLESPACE초기화 파라미터는 다음과 같이 설정되어 있어야 한다.THREAD=0 UNDO_TABLESPACE=UNDO0
-
CREATE DATABASE 문을 실행하고 나면 Tibero가 자동으로 종료된다. Tibero를 다시 기동한 후 SYS 사용자로 접속하여 다음과 같이 Undo 테이블 스페이스와 새로운 Redo 로그 그룹을 만들고 DDL 문장을 수행한다.
[tibero@tester ~]$ tbboot [tibero@tester ~]$ tbsql sys/tibero SQL> CREATE UNDO TABLESPACE UNDO1 DATAFILE 'undo011' SIZE 512M AUTOEXTEND ON NEXT 8M MAXSIZE 3G EXTENT MANAGEMENT LOCAL AUTOALLOCATE Tablespace 'UNDO1' created.
SQL> ALTER DATABASE ADD LOGFILE THREAD 1 GROUP 3 'log031' size 50M; Database altered. SQL> ALTER DATABASE ADD LOGFILE THREAD 1 GROUP 4 'log041' size 50M; Database altered. SQL> ALTER DATABASE ADD LOGFILE THREAD 1 GROUP 5 'log051' size 50M; Database altered. SQL> ALTER DATABASE ENABLE PUBLIC THREAD 1; ... ① ... Database altered.① Redo 스레드를 활성화하는 DDL 문장을 실행한다.
Redo 로그 그룹을 추가하기 위한 기존의 DDL 문장과 같지만 THREAD 번호를 지정했다는 것에 주의해야 한다. 이 예제에서는 두 번째 인스턴스가 사용할 Undo 테이블 스페이스 UNDO1과 Redo 스레드 1을 위한 Redo 로그 그룹을 추가하고 활성화시키는 과정을 보여주고 있다.
Redo 스레드는 숫자로 지정하며 CREATE DATABASE 문을 실행할 시점에 생성한 Redo 로그 그룹이 0번 스레드가 되므로 반드시 1부터 지정해야 한다. 0번 스레드는 CREATE DATABASE 문을 실행할 시점에 자동으로 활성화된다.
주의할 점은 Redo 로그 그룹의 번호는 Redo 스레드 내에서가 아니라 데이터베이스 전체에서 유일해야 하므로 이미 사용된 0, 1, 2를 사용할 수 없다. 또한 최소한 두 개 이상의 Redo 로그 그룹이 존재해야만 해당 Redo 스레드를 활성화시킬 수 있다.
또 다른 인스턴스를 추가하려면 위와 같은 과정을 참고하여 Undo 테이블 스페이스와 Redo 스레드를 생성하고 스레드를 활성화한다.
-
TAC raw device 환경 또는 공유 파일 시스템이면서 DB_CREATE_FILE_DEST가 적절한 경로로 지정되지 않은 환경에서는 Tibero가 정상적으로 기동되지 않을 수 있다.
이와 같은 경우 아래와 같이 APM 관련 정보를 저장할 APM 전용 테이블 스페이스(_APM_TS)를 먼저 추가해야 한다.
[tibero@tester ~]$ tbsql sys/tibero SQL> CREATE TABLESPACE _APM_TS DATAFILE '<_APM_TS 위치>/apm_ts.dtf' ...; Tablespace '_APM_TS' created.
참고
이 과정을 생략하고 다음 단계를 수행한 경우 "Tibero 설치 안내서"의 "Appendix C. TAC 환경 구축"과 "C.4. 설치 후 문제 해결" 부분을 참고한다.
-
$TB_HOME/scripts 디렉터리에 있는 system.sh 스크립트 파일을 실행한다.
Windows 환경에서는 system.vbs 파일이다.
[tibero@tester scripts]$ system.sh $TB_HOME/bin/tbsvr Creating the role DBA... Creating system users & roles... Creating virtual tables(1)... Creating virtual tables(2)... Granting public access to _VT_DUAL... Creating the system generated sequences... Creating system packages: Running /home/tibero/tibero5/scripts/pkg_standard.sql... Running /home/tibero/tibero5/scripts/pkg_dbms_output.sql... Running /home/tibero/tibero5/scripts/pkg_dbms_lob.sql... Running /home/tibero/tibero5/scripts/pkg_dbms_utility.sql... Running /home/tibero/tibero5/scripts/pkg_dbms_obfuscation.sql... Running /home/tibero/tibero5/scripts/pkg_dbms_transaction.sql... Running /home/tibero/tibero5/scripts/pkg_dbms_random.sql... Running /home/tibero/tibero5/scripts/pkg_dbms_lock.sql... Running /home/tibero/tibero5/scripts/pkg_dbms_system.sql... Running /home/tibero/tibero5/scripts/pkg_dbms_job.sql... Running /home/tibero/tibero5/scripts/pkg_utl_raw.sql... Running /home/tibero/tibero5/scripts/pkg_utl_file.sql... Running /home/tibero/tibero5/scripts/pkg_tb_utility.sql... Creating public synonyms for system packages... ............................................
TAC는 모든 인스턴스가 같이 사용할 수 있는 공유 디스크의 공간과 인스턴스 간의 통신이 가능한 네트워크만 있으면 실행할 수 있다.
TAC를 실행하기 전에 준비해야 할 H/W 요구사항과 운영체제 설정은 다음과 같다.
-
공유 디스크의 공간
-
TAC의 실행과 운영을 위해서는 최소 7개의 공유 파일이 필요하다.
-
컨트롤 파일
-
Redo 로그 파일 2개
-
Undo 로그 파일
-
시스템 테이블 스페이스 파일
-
임시 테이블 스페이스 파일
-
TBCM 파일
-
-
인스턴스 하나를 추가 할 때마다 최소 3개의 공유 파일이 추가로 필요하다.
-
Redo 로그 파일 2개
-
Undo 로그 파일
-
-
-
공유 디스크의 권한
공유 파일 시스템을 사용할 경우에는 TAC가 사용할 디렉터리의 권한, RAW 파일 시스템을 사용할 경우에는 각 RAW 파일의 권한을 TAC가 읽고 쓸 수 있도록 설정한다.
-
내부 네트워크의 설정
TAC의 실행과 운영을 위해 내부 네트워크는 외부 네트워크와 분리하는 것이 데이터베이스 성능에 좋다. 내부 네트워크의 인터페이스와 IP, 속도 등을 점검한다.
참고
TAC에서 내부 네트워크를 구성할 때 크로스오버 케이블을 이용한 방식은 지원하지 않는다.
TAC를 처음 기동할 때는 데이터베이스를 생성해야 한다. 클러스터로 사용할 한 노드에서 생성하면 된다. TAC로 Tibero를 기동할 때는 TBCM이 필수이므로 TBCM를 먼저 초기화한 후 시작하고 Tibero를 NOMOUNT 모드로 기동한다.
참고
TBCM를 초기화한 후 Tibero를 처음 시작했을 때는 node 멤버십을 관리하는 초기화 시간이 필요하다. Tibero를 너무 빨리 기동하게 되면 TBCM은 node 멤버십에 포함되지 않은 인스턴스로 간주하고 강제로 종료된다. 따라서 15초 이상의 시간으로 기동할 것을 권장한다.
다음은 TBCM를 초기화하고 Tibero를 NOMOUNT 모드로 기동하는 예이다.
$tac1> tbcm -c This will erase all contents in [/home/tibero5/instance/cm], and cannot be recovered. Proceed? (y/N) y SUCCESS $tac1> tbcm -b Tibero 5 SP1 Copyright (c) 2008, 2009, 2011 TmaxData Corporation. All rights reserved. Tibero cluster manager started up. Local node name is (cm@xxx.x.x.x:xxxx). $tac1> tbboot -t NOMOUNT listener port = xxxx change core dump dir to /home/tibero5/bin/prof Tibero 5 SP1 Copyright (c) 2008, 2009, 2011 TmaxData Corporation. All rights reserved. Tibero instance started up (NOMOUNT mode). $tac1>
NOMOUNT 모드로 기동된 첫 번째 TAC의 인스턴스에 접속하여 데이터베이스를 만든 후 다른 클러스터의 인스턴스를
위한 Redo 로그, Undo 로그를 생성한다. 인스턴스의 $TB_SID.tip 환경설정 파일에 지정한
THREAD, UNDO_TABLESPACE 초기화
파라미터의 이름과 반드시 일치해야 한다.
데이터베이스 생성과 다른 인스턴스를 위한 환경설정 파일의 생성이 모두 완료하면 TAC를 기동할 수 있다.
다음은 다른 인스턴스를 모두 실행하고 TBCM, Tibero 순으로 TAC를 기동하는 예이다.
$tac2> tbcm -b Tibero 5 SP1 Copyright (c) 2008, 2009, 2011 TmaxData Corporation. All rights reserved. Tibero cluster manager started up. Local node name is (cm@xxx.x.x.x:xxxx). $tac2> tbboot listener port = xxxx change core dump dir to /home/tibero5/bin/prof Tibero 5 SP1 Copyright (c) 2008, 2009, 2011 TmaxData Corporation. All rights reserved. Tibero instance started up (NORMAL mode). $tac2>
$TB_HOME/scripts 디렉터리에 있는 cm_stat.sh 스크립트 파일을 통해 노드 및 인스턴스의 상태를 모니터링할 수 있다. TAC에 참여한 노드의 현재 상태, IP 정보 등을 주기적으로 확인할 수 있다.
Tibero는 글로벌 뷰(Global View)를 제공한다. 싱글 인스턴스에서 사용하는 모든 모니터링 뷰를 TAC의 인스턴스에서 조회할 수 있다.
다음은 모든 클러스터에 연결되어 있는 세션을 확인하는 예이다. tbSQL 유틸리티, tbAdmin 툴을 통해 다음과 같은 SQL 문장을 실행한다.
사용자의 프로그램은 TAC를 기본적으로 하나의 DBMS처럼 다룰 수 있다. 따라서 사용자는 하나의 DBMS에 접속한 것처럼 연결을 맺고 작업을 수행하면 된다.
장애가 발생했을 때 Failover 및 로드 밸런싱 기능은 클라이언트 라이브러리와 TAC에서 자동으로 처리된다. 이를 위해 클라이언트는 여러 대의 이중화 서버에 접속하는 것과 같이 Failover와 로드 밸런싱 기능을 설정한다.
참고
이중화 서버를 위한 클라이언트 설정은 “A.2. 이중화 서버 설정”, 로드 밸런싱 설정은 “A.3. 로드 밸런싱 설정”, Failover 설정은 “A.4. Failover 설정”을 참고한다.
클라이언트의 LOAD_BALANCE, USE_FAILOVER 설정만으로도 기본적인 로드 밸런싱과 Failover 기능이 사용자에게 제공된다. 클라이언트는 TAC를 구성하는 여러 노드 중 임의의 노드를 선택하여 접속하며, 해당 노드에 장애가 발생했을 때 다른 노드로 연결이 자동 전환된다. 이렇게 장애가 발생하면 수행 중이던 SQL 문장에서 에러가 나며, 다음 SQL부터는 새로운 노드에서 작업이 수행된다. 발생하는 SQL은 장애 유형에 따라 다르다.
이렇게 클라이언트의 설정만으로 제공되는 로드 밸런싱 기능은 별다른 부하를 발생시키지 않는다. 단, 서버의 부하 상황을 고려하지 않으므로, 정확한 의미의 로드 밸런싱은 아니다. 이것은 한꺼번에 서버와의 연결을 많이 맺고 오래 사용하는 목적에 알맞으며 3-tier(multi-tier) 방식에 유용하다. 또한 서버와의 연결과 끊김이 잦은 2-tier 방식에서도 TAC 서버에 로드 밸런싱 기능을 추가하여 서버의 부하 상황을 고려하는 것이 좋다.
다음은 서버 쪽에 로드 밸런싱을 설정하는 가장 기본적인 예이다.
[예 10.2] 서버 쪽 로드 밸런싱 설정
<$TB_SID.tip>
SERVER_SIDE_LOAD_BALANCE=LONG
LOAD_METRIC_AUTO_INTERVAL=Y
SERVER_LOAD_TOLERANCE=30
| 초기화 파라미터 | 설명 |
|---|---|
SERVER_SIDE_LOAD_BALANCE | 필수 항목으로 서버 쪽에 로드 밸런싱을 하는 방법을 설정하는 파라미터이다.
|
LOAD_METRIC_AUTO_INTERVAL | 옵션 항목으로 서버의 부하 상황을 수집하는 것을 자동으로 할지의 여부를 결정하는 파라미터이다. 이 파라미터는 부하의 변화가 많은 시간에는 자주 수집하고 반면에 부하의 변화가 거의 없는 시간에는 천천히 수집하도록 수집 주기가 자동으로 조절된다. 서버 쪽에 로드 밸런싱이 시작되면 각각의 TAC 서버는 주기적으로 부하 상황을 주고받으며 이를 수집한다. 수집 주기는 다음의 설정에 따라 다르다.
|
LOAD_METRIC_COLLECT_INTERVAL_MIN | 옵션 항목으로 자동 주기 조절 상태일 때 자주 수집할 때의 시간 간격을 설정하는 파라미터이다. (기본값: 1초) |
LOAD_METRIC_COLLECT_INTERVAL_MAX | 옵션 항목으로 자동 주기 조절 상태일 때 천천히 수집하도록 시간 간격을 설정하는 파라미터이다. (기본값: 10초) |
LOAD_METRIC_HISTORY_COUNT | 옵션 항목으로 기록할 수집된 부하 정보의 개수를 설정하는 파라미터이다. 수집된 부하 정보는 뷰(V$INSTANCEMETRIC, V$INSTANCEMETRIC_HISTORY)를 통해 확인할 수 있다. |
SERVER_LOAD_TOLERANCE | 옵션 항목으로 서버 간의 부하 상황에 대해서 어느 정도의 차이를 허용할 것인가를 설정하는 파라미터이다. 약간의 차이도 허용하지 않으면 클라이언트의 연결이 한쪽으로 치우치는 현상이 발생할 수 있으므로 이 파라미터를 설정한다. 다음은 SERVER_SIDE_LOAD_BALANCE 초기화 파라미터에 설정된 값에 따라 달라지는 SERVER_LOAD_TOLERANCE 초기화 파라미터의 의미이다.
|
참고
서버 쪽의 로드 밸런싱은 새로 연결을 시도하는 클라이언트에 대해서만 동작한다. 너무 많은 부하가 걸리거나 너무 적게 걸리더라도 이미 맺은 연결은 강제로 끊지 않는다.