내용 목차
본 장에서는 Tibero의 주요 기능과 프로세스 구조, 디렉터리 구조를 간단히 설명한다.
현재 기업의 비즈니스는 폭발적인 데이터의 증가와 다양한 환경 및 플랫폼의 등장으로 빠르게 확장되고 있다. 새로운 비즈니스 환경이 도래함에 따라 보다 더 효율적이고 유연한 데이터 서비스와 정보의 처리, 데이터 관리 기능이 필요하게 되었다.
Tibero는 이러한 변화에 맞춰 기업 비즈니스 구현의 기반이 되는 데이터베이스 인프라 구성을 지원하며 고성능, 고가용성 및 확장성의 문제를 해결하는 엔터프라이즈 데이터베이스 관리 시스템이다.
기존 DB의 단점을 보완하기 위해 Tibero는 독자적인 Tibero Thread Architecture를 채택하고 구현하였다. 한정된 서버 프로세스의 CPU 및 메모리 등의 시스템 리소스를 효율적으로 사용하면서 뛰어난 성능과 안정성 및 확장성을 보장하고 편리한 개발 환경과 관리 기능을 제공한다.
Tibero는 초기 설계부터 대규모 사용자, 대용량 데이터, 강화된 안정성, 향상된 호환성 측면 등에서 다른 DBMS와 차별화를 고려하여 개발되었다.
Tibero는 이처럼 기업이 원하는 최적의 데이터베이스 환경을 제공하는 대표적인 DB이다.
대용량의 데이터를 관리하고 안정적인 비즈니스의 연속성을 보장하는 데이터 관리 솔루션인 Tibero는 DB 환경에서 요구되는 주요 기능을 다음과 같이 갖추고 있다.
-
분산 데이터베이스 링크(Distributed Database Link)
데이터베이스 인스턴스별로 각각 서로 다른 데이터를 저장하는 기능이다. 이 기능을 통해 원격 데이터베이스에 저장된 데이터를 네트워크를 통해 읽기 및 쓰기를 수행할 수 있다.
또한 이 기능은 다양한 벤더의 DB 제품을 연결하여 읽기 및 쓰기를 수행할 수 있다.
-
현재 운영 중인 데이터베이스에서 변경된 모든 내용을 Standby DB로 복제하는 기능이다. 즉, 네트워크를 통해서 변경 로그(Change log)만 전송하면 Standby DB에서 데이터에 적용하는 방식이다.
-
기업용 DB의 최대 이슈인 고가용성과 고성능을 모두 해결하는 기능이다. Tibero DB는 고가용성과 고성능을 보장하기 위해 Tibero Active Cluster 기술을 보유하고 있다.
이 기술로 인해 여러 개의 데이터베이스 인스턴스가 공유 디스크를 이용하여 동일한 데이터베이스를 공유할 수 있다. 이때 각 데이터베이스 인스턴스는 내부의 데이터베이스 캐시(Database cache) 사이의 일관성을 유지하는 기술이 매우 중요하다. 따라서 이러한 기술도 Tibero Active Cluster에 포함하여 제공하고 있다. 보다 자세한 내용은 “제10장 Tibero Active Cluster”를 참고한다.
-
병렬 쿼리 처리(Parallel Query Processing)
기업의 데이터 크기는 계속적으로 증가하고 있다. 대용량 데이터를 처리하기 위해 서버의 리소스를 최대한 활용할 수 있는 병렬 처리 기술이 필수적으로 요구되고 있다.
Tibero는 이러한 요구사항에 맞추어 온라인 트랜잭션 처리(On-Line Transaction Processing, 이하 OLTP) 환경에 최적화된 기능을 제공할 뿐만 아니라 OLAP(Online Analytical Processing) 환경에 최적화된 SQL 병렬 처리 기능을 제공하고 있다. 이로 인해 쿼리는 빠른 응답 속도로 수행되며 기업의 빠른 의사 결정을 돕는다.
-
쿼리 최적화기는 스키마 객체의 통계 정도를 바탕으로 다양한 데이터 처리 경로들을 고려하여 어떤 실행 계획이 가장 효율적인지를 결정한다.
쿼리 최적화기는 논리적으로 다음과 같은 단계를 통해 수행된다.
-
주어진 SQL 문을 처리하는 다양한 실행 계획들을 만들어 낸다.
-
데이터의 분산도에 대한 통계 정보와 테이블, 인덱스, 파티션 등의 특징을 고려하여 각각의 실행 계획의 비용을 계산한다. 여기서 비용이란 특정 실행 계획을 수행하는 데 필요한 상대 시간을 나타내고, 최적화기는 I/O, CPU, 메모리 등의 컴퓨터 자원을 고려하여 그 비용을 계산해 낸다.
-
실행 계획들의 비용을 비교하여 가장 비용이 작은 계획을 선택한다.
쿼리 최적화기의 주요 기능은 다음과 같다.
-
최적화 목표
사용자는 최적화기의 최종 목표를 바꿀 수도 있는데 다음의 두 가지 목표를 선택할 수 있다.
구분 설명 전체 처리 시간 ALL_ROWS 힌트를 사용하면 최적화기는 마지막 row까지 얻어내는 시간을 최대한 단축하도록 최적화한다. 최초 반응 시간 FIRST_ROWS 힌트를 사용하면 최적화기는 첫 번째 row를 얻어내는 시간을 최대한 단축하도록 최적화한다. -
질의 변형
질의의 형태를 바꿔서 더 좋은 실행 계획을 만들 수 있도록 한다. 질의 변형의 예에는 뷰 병합, 부질의 언네스트, 실체화 뷰의 사용 등이 있다.
-
데이터 접근 경로 결정
데이터를 데이터베이스로부터 꺼내오는 작업은 전체 테이블 스캔, 인덱스 스캔, rowid 스캔 등의 다양한 방법을 통해서 수행될 수 있다. 각 방법마다 필요한 데이터의 양이나 필터링의 형태 등에 따라 장단점이 있어서 질의에 따라 최적의 접근 방식이 다르다.
-
조인 처리 방식 결정
여러 테이블에서 데이터를 꺼내오게 되는 조인의 경우 최적화기는 조인의 순서와 방법을 결정해야 한다. 여러 테이블 간의 조인일 때 어떤 테이블을 먼저 조인할지에 대한 순서와 각각의 조인에 있어서 중첩 루프 조인, 합병 조인, 해시 조인 등의 다양한 방법 중 어떤 것을 사용할지가 실행 속도에 큰 영향을 미치게 된다.
-
비용 추정
각각의 실행 계획에 대해 비용을 추정한다. 비용 추정을 위해서 필요한 predicate의 선택도나 각 실행 단계에서 데이터의 row 수 등을 통계 정보를 사용해서 추정하고 이를 바탕으로 각 단계에서의 비용을 추정한다.
-
Tibero는 데이터베이스의 영속성과 일관성을 유지하기 위하여 SQL문장의 묶음인 트랜잭션을 다음의 4가지 성질을 통해 보장한다.
-
Atomicity
All-or-nothing으로 트랜잭션이 행한 모든 일이 적용되던가 아니면 모두 적용되지 않아야 함을 의미한다. Tibero에서는 이를 위하여 undo 데이터를 사용한다.
-
Consistency
트랜잭션이 데이터베이스의 Consistency를 깨뜨리는 일은 여러 방면에서 생겨날 수 있다. 간단한 예는 table과 index 간에 서로 다른 내용을 담고 있어서 Consistency가 깨지는 것이다. 이를 막기 위해 Tibero에서는 트랜잭션이 적용한 일들 중 일부만 자신이나 남에게 적용되는 것을 막고 있다. 즉, 테이블만 수정했고 아직 인덱스를 수정하지 않은 상태라고 해도 다른 트랜잭션에서는 이를 예전 모습으로 돌려 보아서 테이블과 인덱스가 항상 Consistency가 맞는 형태로 보이게 된다.
-
Isolation
트랜잭션은 혼자만 돌고 있는 것처럼 보이게 된다. 물론 다른 트랜잭션이 수정한 데이터에 접근할 때는 이를 기다릴 수는 있지만 다른 트랜잭션이 수정 중이므로 접근할 수 없다고 에러가 나지는 않는다. 이를 위해 Tibero에서는 Multi version concurrency control 기법과 row-level locking 기법을 사용한다.
데이터를 참조하는 경우에는 MVCC 기법을 이용하여 다른 트랜잭션과 무관하게 참조 가능하며, 데이터를 수정할 때도 row level의 fine-grained lock control을 통하여 최소한의 충돌만을 일으키고 같은 데이터에 접근한다고 해도 단지 기다림으로써 이를 해결한다.
-
Durability
Tibero에서는 이를 위하여 Redo 로그와 write-ahead logging 기법을 사용한다. 트랜잭션이 커밋할 때에 해당 Redo 로그가 디스크에 기록되어 트랜잭션의 영속성을 보장해 준다. 또한 블럭이 디스크에 내려가기 전에 항상 Redo 로그가 먼저 내려가서 데이터베이스 전체가 일관성을 지니게 한다.
Tibero는 fine-grained lock control을 보장해 주기 위하여 row level locking을 사용한다. 즉, 데이터 최소 단위인 Row 단위의 locking을 통하여 최대한의 concurrency를 보장해 준다. 많은 Row들을 수정한다고 해도 테이블에 lock이 걸려서 concurrent한 DML이 수행되지 못하는 상황은 발생하지 않는다. 이러한 기법을 통해 OLTP 환경에서 더욱 강력한 성능을 발휘하고 있다.
Tibero는 대규모 사용자 접속을 수용하는 다중 프로세스 및 다중 스레드 기반의 아키텍처를 갖추고 있다.
다음은 Tibero의 프로세스 구조를 나타내는 그림이다.
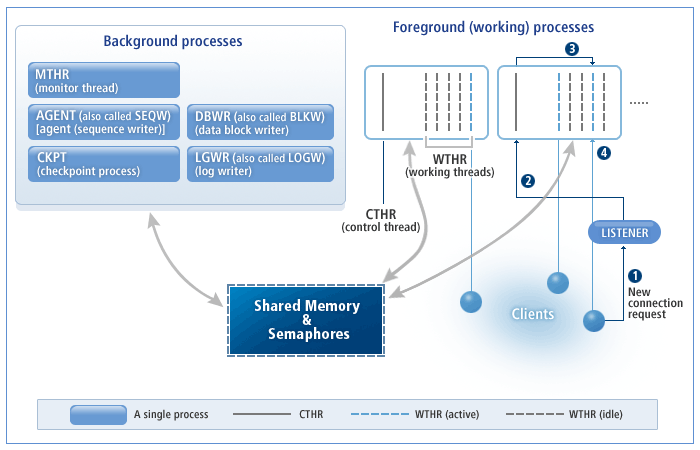
Tibero의 프로세스는 크게 3가지로 구성된다.
-
리스너(Listener)
-
워킹 프로세스(Working Process 또는 Foreground Process)
-
백그라운드 프로세스(Background Process)
리스너(Listener)는 클라이언트의 새로운 접속 요청을 받아 이를 유휴한 워킹 프로세스에 할당한다. 즉, 클라이언트와 워킹 프로세스간의 중계 역할을 담당하며 이는 별도의 실행 파일인 tblistener를 사용하여 작업을 수행한다.
다음은 [그림 1.1]를 기준으로 클라이언트의 새로운 접속 요청이 이루어지는 순서이다.
워킹 프로세스(Working Process)는 클라이언트와 실제로 통신을 하며 사용자의 요구 사항을 처리하는 프로세스이다.
이 프로세스의 개수는 WTHR_PROC_CNT 초기화 파라미터로 조절할 수
있으며, 일단 Tibero가 기동된 뒤에는 변경할 수 없다. 따라서 시스템 환경을 고려하여 적절한 값을
설정해야 한다.
참고
초기화 파라미터에 대한 자세한 내용은 "Tibero 참조 안내서"를 참고한다.
Tibero는 효율적인 리소스의 활용을 위해 스레드(Thread) 기반으로 작업을 수행한다. Tibero를 설치하면 기본적으로 하나의 워킹 프로세스 안에는 1개의 컨트롤 스레드와 10개의 워킹 스레드가 존재한다.
프로세스당 워킹 스레드 개수는 _WTHR_PER_PROC 초기화 파리미터로 조절할
수 있으며, WTHR_PROC_CNT처럼 일단 Tibero가 기동된 뒤에는 변경할 수 없다. 따라서
시스템 환경을 고려하여 적절한 값을 설정해야 한다.
WTHR_PROC_CNT와
_WTHR_PER_PROC 초기화 파라미터 값을 직접 바꾸는 것 보다는
MAX_SESSION_COUNT 초기화 파라미터를 통해 서버에서 제공하는 최대 세션 개수를
지정할 것을 권장한다.
MAX_SESSION_COUNT 값에 따라
WTHR_PROC_CNT와 _WTHR_PER_PROC
값이 자동으로 설정된다. 만약 WTHR_PROC_CNT와
_WTHR_PER_PROC를 직접 설정할 경우
WTHR_PROC_CNTWTHR_PROC_CNT *
_WTHR_PER_PROC 값이
MAX_SESSION_COUNT 값과 같게 두 값을 설정해야 한다.
워킹 프로세스는 컨트롤 스레드와 워킹 스레드를 통해 다음과 같은 작업을 수행한다.
컨트롤 스레드
워킹 프로세스마다 하나씩 존재하며 다음과 같은 역할을 담당한다.
-
Tibero가 기동될 때 초기화 파라미터에 설정된 수만큼 워킹 스레드를 생성한다.
-
클라이언트의 새로운 접속 요청이 오면 현재 유휴한 워킹 스레드에 클라이언트의 접속을 할당한다.
-
시그널 처리를 담당한다.
워킹 스레드
워킹 스레드는 클라이언트와 1:1로 통신하며, 클라이언트가 보내는 메시지를 받아 처리하고, 그 결과를 돌려준다. 주로 SQL 파싱, 최적화 수행 등 DBMS가 하는 작업 대부분이 워킹 프로세스에서 일어난다.
그리고 워킹 스레드는 하나의 클라이언트와 접속하므로 Tibero에 동시 접속이 가능한 클라이언트 수는
WTHR_PROC_CNT *
_WTHR_PER_PROC이다. Tibero는 세션 멀티플렉싱(Session
multiplexing)을 지원하지 않으므로 하나의 클라이언트 접속은 곧 하나의 세션과 같다. 그러므로 최대 세션이 생성될 수
있는 개수는 WTHR_PROC_CNT *
_WTHR_PER_PROC를 연산한 값과 같다.
워킹 스레드는 클라이언트와 접속이 끊긴다고 해도 없어지지 않으며, Tibero가 기동될 때 생성된 이후부터 종료할 때까지 계속 존재하게 된다. 이러한 구조에서는 클라이언트와 접속을 빈번하게 발생시키더라도 매번 스레드를 생성하거나 제거하지 않으므로 시스템의 성능을 높일 수 있다.
반면 실제 클라이언트의 수가 적더라도 초기화 파라미터에 설정된 개수만큼 스레드를 생성해야 하므로 운영체제의 리소스를 계속 소모하는 단점은 있으나, 운영체제 대부분이 유휴한 스레드 하나를 유지하는 데 드는 리소스는 매우 적으므로 시스템을 운영하는 데는 별 무리가 없다.
주의
많은 수의 워킹 스레드가 동시에 작업을 수행하려고 할 때 심한 경우 운영체제에 과도한 부하를 일으켜 시스템 성능이 크게 저하될 수 있다. 그러므로 대규모 시스템을 구축할 경우에는 Tibero와 클라이언트의 애플리케이션 프로그램 사이에 미들웨어를 설치하여 3-tier 구조로 시스템을 구축할 것을 권장한다.
백그라운드 프로세스(Background Process)는 클라이언트의 접속 요청을 직접 받지 않고 워킹 스레드나 다른 백그라운드 프로세스가 요청할 때 또는 정해진 주기에 따라 동작하는 주로 시간이 오래 걸리는 디스크 작업을 담당하는 독립된 프로세스이다.
백그라운드 프로세스에 속해 있는 프로세스는 다음과 같다.
-
감시 프로세스의 영문 약자를 보면 프로세스가 아닌 스레드로 나타나 있지만 실제로는 하나의 독립된 프로세스이다. 리스너를 제외하고 Tibero가 기동할 때 최초로 생성되며 Tibero가 종료하면 맨 마지막에 프로세스를 끝마친다.
Tibero가 기동할 때 다른 프로세스를 생성하거나 주기적으로 각 프로세스의 상태를 점검하는 역할을 담당한다. 또한 교착 상태(deadlock)도 검사한다.
-
시퀀스 프로세스(AGENT 또는 SEQW: sequence writer)
시스템 유지를 위해 주기적으로 처리해야 하는 Tibero 내부의 작업을 담당한다. 4 SP1까지는 시퀀스 캐시(sequence cache)의 값을 디스크에 저장하는 작업도 담당했으나, 5 이후로 각 워킹 스레드가 담당하는 것으로 변경되었다. 사용자의 혼란을 피하기 위해 SEQW라는 명칭은 유지된다.
시퀀스를 사용하는 방법에 대한 내용은 “4.7.1. 시퀀스 생성, 변경, 제거”를 참고한다.
-
데이터 블록 쓰기 프로세스(DBWR: data block writer 또는 BLKW)
사용자가 수정한 데이터 블록을 주기적으로 디스크에 기록한다. 기록된 데이터 블록은 주로 워킹 스레드가 직접 읽어온다.
-
체크포인트 프로세스(CKPT: checkpoint process)
체크포인트는 주기적으로 또는 클라이언트의 요청에 따라 메모리에 있는 변경된 모든 데이터 블록을 디스크에 기록하는 작업이다. Tibero에 장애가 발생하면 이를 복구하기 위해 걸리는 시간이 한계 수치를 넘지 않도록 예방하는 효과가 있다. 이러한 체크포인트를 관리하는 프로세스가 체크포인트 프로세스이다.
클라이언트가 직접 체크포인트를 요청하는 방법은 "Tibero SQL 참조 안내서"의 ALTER SYSTEM CHECKPOINT 문을 참고한다.
-
로그 쓰기 프로세스(LGWR: log writer 또는 LOGW)
Redo 로그 파일을 디스크에 기록하는 프로세스이다. 로그 파일에는 데이터베이스의 데이터에 대한 모든 변경 사항을 저장하고 있으며 빠른 트랜잭션 처리와 복구를 위해 사용된다.
로그 파일에 대한 자세한 내용은 “3.3. 로그 파일”을 참고한다.
Tibero가 설치되면 다음과 같은 디렉터리가 생성된다.
$TB_HOME +- bin | +- client | | | +- bin | +- config | +- include | +- lib | +- ssl | | | | | +- man | | | +- man1 | | | +- man3 | | | +- man5 | | | +- man7 | | +- misc | +- epa | | | | | +- java | | | | | +- config | | +- lib | +- win32 | +- win64 | +- config | +- database | +- $TB_SID | | | +- psm | +- instance | | | +- $TB_SID | | | +- audit | +- log | | +- dbmslog | | +- lsnr | | +- tracelog | +- path | +- lib | +- license | | | +- oss_licenses | +- scripts +- pkg
위의 디렉터리 구조에서 $TB_SID라고 보이는 부분은 각각의 시스템 환경에 맞는 서버의 SID로 바꿔서 읽어야 한다.
Tibero에서 사용하는 고유의 디렉터리는 다음과 같다.
- bin
-
Tibero의 실행 파일과 서버 관리를 위한 유틸리티가 위치한 디렉터리이다. 이 디렉터리에 속한 파일 중에서 tbsvr과 tblistener는 Tibero를 구성하는 실행 파일이며, tbboot와 tbdown은 각각 Tibero를 기동하고 종료하는 역할을 담당한다.
tbsvr과 tblistener 실행 파일은 반드시 tbboot 명령어를 이용하여 실행되어야 하며, 절대로 직접 실행해서는 안 된다.
- client/bin
-
Tibero의 클라이언트 실행 파일이 있는 디렉터리이다. 이 디렉터리에는 다음과 같은 유틸리티가 있다.
유틸리티에 대한 내용은 "Tibero 유틸리티 안내서"를 참고한다. 단, tbpc 유틸리티는 "Tibero tbESQL/C 안내서"를 참고한다.
- client/config
-
Tibero의 클라이언트 프로그램을 실행하기 위한 설정 파일이 위치하는 디렉터리이다.
- client/include
-
Tibero의 클라이언트 프로그램을 작성할 때 필요한 헤더 파일이 위치하는 디렉터리이다.
- client/lib
-
Tibero의 클라이언트 프로그램을 작성할 때 필요한 라이브러리 파일이 위치하는 디렉터리이다. 이에 대한 자세한 내용은 "Tibero 애플리케이션 개발자 안내서"와 "Tibero tbESQL/C 안내서"를 참고한다.
- client/ssl
-
서버 보안을 위한 인증서와 개인 키를 저장하는 디렉터리이다.
- client/epa
-
External Procedure와 관련된 설정 파일과 로그 파일이 있는 디렉터리이다. 이에 대한 자세한 내용은 "Tibero External Procedure 안내서"를 참고한다.
- client/win32
-
32bit Windows용 ODBC/OLE DB 드라이버가 위치하는 디렉터리이다.
- client/win64
-
64bit Windows용 ODBC/OLE DB 드라이버가 위치하는 디렉터리이다.
- config
-
Tibero의 환경설정 파일이 위치하는 디렉터리이다. 이 위치에 존재하는 $TB_SID.tip 파일이 Tibero의 환경설정을 결정한다.
- database/$TB_SID
-
Tibero의 데이터베이스 정보를 별도로 설정하지 않는 한 모든 데이터베이스 정보가 이 디렉터리와 그 하위 디렉터리에 저장된다. 이 디렉터리에는 데이터 자체에 대한 메타데이터(metadata)뿐만 아니라 다음과 같은 종류의 파일이 있다.
- database/$TB_SID/psm
-
tbPSM 프로그램을 컴파일드 모드(Compiled mode)로 컴파일하는 경우 컴파일된 파일이 저장되는 디렉터리이다. 하지만 현재 Tibero에서는 인터프리터 모드만을 지원하고 있다. 이에 대한 자세한 내용은 "Tibero tbPSM 안내서"를 참고한다.
- instance/$TB_SID/audit
-
데이터베이스 사용자가 시스템 특권 또는 스키마 객체 특권을 사용하는 것을 감시(Audit)한 내용을 기록한 파일이 저장되는 디렉터리이다.
- instance/$TB_SID/log
-
Tibero의 Trace 로그 파일과 DBMS 로그 파일이 저장되는 디렉터리이다.
Trace 로그 파일과 DBMS 로그 파일은 데이터베이스를 사용할수록 계속 누적되어 저장된다. 또한, 전체 디렉터리의 최대 크기를 지정할 수 있으며, Tibero는 그 지정된 크기를 넘어가지 않도록 오래된 파일을 삭제한다.
DBMS 로그 파일을 설정하는 초기화 파라미터는 다음과 같다.
초기화 파라미터 설명 DBMS_LOG_FILE_SIZE DBMS 로그 파일 하나의 최대 크기를 설정한다. DBMS_LOG_TOTAL_SIZE_LIMIT DBMS 로그 파일이 저장된 디렉터리의 최대 크기를 설정한다. TRACE_LOG_FILE_SIZE Trace 로그 파일 하나의 최대 크기를 설정한다. TRACE_LOG_TOTAL_SIZE_LIMIT Trace 로그 파일이 저장된 디렉터리의 최대 크기를 설정한다. - instance/$TB_SID/path
-
Tibero의 프로세스 간에 통신을 위한 소켓 파일이 있는 디렉터리이다. Tibero가 운영 중일 때 이 위치에 존재하는 파일을 읽거나 수정해서는 안 된다.
- lib
-
Tibero 서버에서 Spatial과 관련된 함수를 사용하기 위한 라이브러리 파일이 있는 디렉터리이다.
- license
-
Tibero의 라이선스 파일(license.xml)이 있는 디렉터리이다. XML 형식이므로 일반 텍스트 편집기로도 라이선스의 내용을 확인할 수 있다.
- license/oss_licenses
-
반드시 준수해야 하는 오픈소스 라이선스에 대한 정보를 확인할 수 있는 디렉터리이다.
- scripts
-
Tibero의 데이터베이스를 생성할 때 사용하는 각종 SQL 문장이 있는 디렉터리이다. 또한, Tibero의 현재 상태를 보여주는 각종 뷰의 정의도 이 디렉터리에 있다.
- scripts/pkg
-
Tibero에서 사용하는 패키지의 생성문이 저장되는 디렉터리이다.