내용 목차
SELECT 구문은 하나 이상의 테이블, 뷰로부터 원하는 데이터를 조회한다.
SELECT의 세부 내용은 다음과 같다.
-
문법


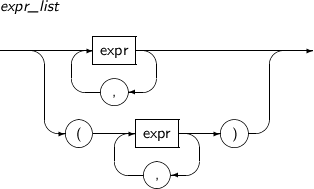
-
특권
SELECT ANY TABLE 시스템 특권을 가진 사용자는 모든 테이블과 모든 뷰를 조회할 수 있다. 테이블을 조회하기 위해서는 테이블을 사용자가 소유하고 있거나, 그 객체에 대해 SELECT 스키마 오브젝트 특권을 가지고 있어야 한다.
뷰의 기반 테이블을 조회하기 위해서는 다음의 두 가지 조건을 동시에 만족해야 한다.
-
사용자가 뷰를 가지고 있거나 뷰에 대한 SELECT 스키마 오브젝트 특권이 있어야 한다.
-
뷰가 속한 스키마의 사용자가 뷰의 기반 테이블을 가지고 있거나 기반 테이블에 대해 SELECT 스키마 오브젝트 특권을 가지고 있어야 한다.
-
-
구성요소
-
select
구성요소 설명 with_clause 부질의를 정의하고 이름을 만든다. subquery 질의를 명시한다. for_update_clause 질의 결과로 반환된 모든 ROW에 잠금을 설정하여 다른 사용자가 읽거나 갱신하지 못하도록 한다.
설정된 잠금은 현재 트랜잭션이 종료될 때까지 계속 유지된다. for_update_clause는 부질의 안에는 포함할 수 없다. 둘 이상의 테이블 또는 뷰에 조인 질의를 수행하는 경우 for_update_clause는 모든 테이블 또는 뷰에 잠금을 설정한다.
for_update_clause는 질의 결과의 ROW가 기반 테이블 내의 유일한 ROW로 결정될 수 없는 질의 문장에는 포함될 수 없다. 따라서, 다음과 같은 질의 문장 안에는 포함할 수 없다.
-
SELECT 절에 DISTINCT를 포함하는 문장
-
둘 이상의 테이블 또는 뷰에 대한 집합 또는 백 연산을 포함하는 문장
-
GROUP BY 절을 포함하거나 SELECT 절에 집단 함수(Aggregate function)를 포함하는 문장
-
-
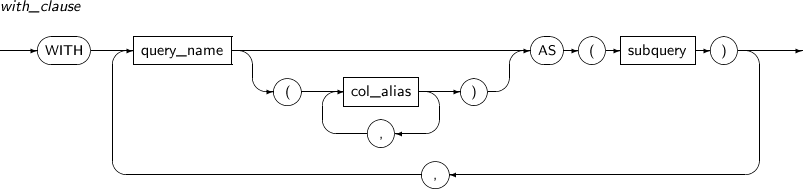
with_clause
구성요소 설명 query_name 부질의의 이름이다. 주 질의와 현재 부질의 다음에 정의되는 부질의에 query_name을 명시하여 사용한다. col_alias subquery의 컬럼명을 재정의한다. subquery 질의를 명시한다. with_clause의 제약조건은 다음과 같다.
-
query_name으로 정의한 부질의 안에서 query_name을 참조할 수 없다.
-
-
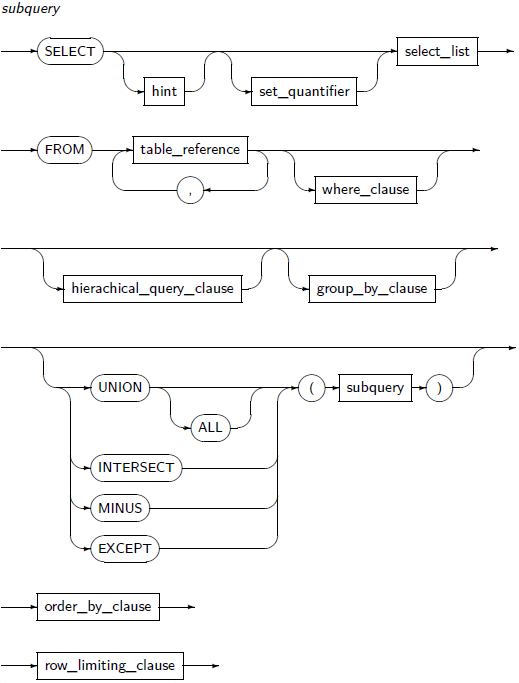
subquery
구성요소 설명 hint 힌트를 사용한다. 힌트는 일종의 지시문으로 최적화기의 특정 행동을 지시하거나 최적화기의 실행 계획을 변경한다. 자세한 내용은 “2.8. 힌트”를 참고한다. set_quantifier 질의 결과에 중복된 ROW의 허용, 비허용 여부를 지정한다.
DISTINCT, UNIQUE, ALL을 지정할 수 있다.
-
DISTINCT, UNIQUE: 중복된 ROW를 제거한다.
-
ALL: 모든 ROW를 선택한다. (기본값)
select_list 질의의 결과로 반환할 연산식을 명시한다.
select_list에는 다음과 같은 제약조건이 있다. 만약 group_by_clause가 명시되어 있다면 select_list에서는 다음에 명시된 연산식의 조합만을 사용할 수 있다.
-
상수
-
집합 함수 (aggregation function)
-
group_by_clause에 사용된 연산식으로 조합된 연산식
조인 뷰에서 ROWID를 선택하면 마지막에 명시된 키 보존 테이블의 ROWID가 선택된다. 키 보존 테이블이 없다면, ROWID를 선택할 수 없다.
동일한 컬럼명을 가지는 2개 이상의 테이블 또는 뷰가 조인된 경우 특정 컬럼을 선택하기 위해서는 컬럼명이 테이블명 또는 별칭과 함께 명시되어야 한다.
FROM 질의의 대상이 되는 하나 이상의 테이블, 뷰, 부질의를 명시한다. table_reference 질의할 테이블, 뷰, 인라인 뷰 등을 명시하고 조인 관계를 설정한다. where_clause WHERE 절을 통하여 조건식을 만족하는 ROW만을 검색 할 수 있으며, WHERE 절이 생략된 경우에는 질의의 대상이 되는 객체의 모든 ROW를 반환한다. 자세한 내용은 “3.4. 조건식”을 참고한다. hierarchical_query_clause 하나의 테이블 또는 조인된 둘 이상의 테이블의 ROW 간의 계층 관계를 정의하여 검색할 수 있다.
이러한 질의를 계층 질의라고 하며 START WITH … CONNECT BY 절을 이용하여 수행할 수 있다. CONNECT BY 절에는 다른 조건식에는 사용되지 않는 PRIOR 연산자가 포함된다. 계층 질의에서 정렬을 하고 싶다면 ORDER SIBLINGS BY 절을 사용한다. 자세한 내용은 “5.5. 계층 질의”를 참고한다.
group_by_clause 질의 결과로 반환된 ROW를 하나 이상의 그룹으로 분리하기 위하여 GROUP BY 절을 이용한다. CUBE 또는 ROLLUP 확장을 사용했을 경우는 ROW를 모아놓은 그룹을 다시 모아 추가로 상위 그룹을 형성할 수 있다.
그룹으로 분리하기 위한 연산식은 하나 이상이 될 수 있으며, HAVING 절을 이용하여 원하는 그룹을 반환할 수 있다.
그룹으로 분리된 결과는 정렬되어 반환되지 않을 수도 있으며, 이러한 경우에 ORDER BY 절을 이용하여 최종 결과를 정렬할 수 있다.
GROUP BY 절의 연산식으로 부질의, 대용량 객체형 데이터 타입의 컬럼을 사용할 수 없다.
UNION (ALL) 양쪽 질의 결과에서 중복된 ROW를 제거하고 새로운 하나의 질의 결과를 만든다. 예약어 ALL을 명시하면 중복된 ROW를 제거하지 않는다. INTERSECT 양쪽 질의 결과에 동일하게 나타난 ROW를 모아 새로운 하나의 질의 결과를 만든다. MINUS MINUS 예약어 이전에 명시된 질의 결과에서 이후에 명시된 질의 결과에 동일하게 나타나는 ROW를 제거해서 새로운 하나의 질의 결과를 만든다. EXCEPT EXCEPT는 MINUS와 동일하다. EXCEPT 예약어 이전에 명시된 질의 결과에서 이후에 명시된 질의 결과에 동일하게 나타나는 ROW를 제거해서 새로운 하나의 질의 결과를 만든다. order_by_clause 검색 결과의 ROW를 정렬하여 반환하기 위해 ORDER BY 절을 이용한다.
정렬 순서를 지정하기 위해 컬럼의 이름을 포함하는 연산식이 올 수 있으며, 특정 컬럼의 위치 또는 컬럼의 별칭을 이용할 수 있다.
정렬 순서를 지정하기 위해 여러 가지 기준이 지정된 경우에는 먼저 지정된 기준에 따라 정렬을 수행하고 순서를 가리기 불가능한 경우에 다음 기준을 이용하게 된다.
row_limiting_clause 검색 결과의 수를 제한하기 위해 OFFSET, FETCH 절을 이용한다.
OFFSET절을 사용하여 전체 검색 결과 중 시작되는 ROW의 NUMBER를 지정할 수 있으며, FETCH절을 사용하여 몇 개의 ROW를 가져올 지 결정할 수 있다.
order_by_clause의 제약조건은 다음과 같다.
-
select_list에 예약어 DISTINCT가 사용되면 order_by_clause에서 select_list에 명시된 expr의 조합만을 정렬의 키로 사용할 수 있다.
-
LOB, LONG 등과 같은 대용량 객체형 데이터 타입의 컬럼을 사용할 수 없다.
-
group_by_clause가 명시되어 있다면 아래의 4가지 expr만 order_by_clause에서 사용할 수 있다.
개수 가능한 expr 1 상수 2 집합 함수 3 분석 함수 4 group_by_clause에 사용된 expr의 조합
-
-
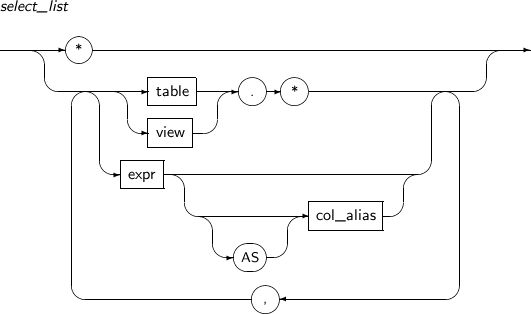
select_list
구성요소 설명 애스터리스크(*) FROM 절에 명시된 테이블과 뷰의 모든 컬럼을 선택한다. table.* , view.* 명시된 테이블 또는 뷰의 모든 컬럼을 선택한다. expr 반환할 값을 계산하는 연산식이다. AS 별칭을 명시할 때 사용하는 예약어로 생략할 수 있다. col_alias select_list에 명시된 연산식에 별칭을 설정한다.
동일한 질의에서는 order_by_clause에만 별칭을 사용할 수 있다.
-
table_reference
구성요소 설명 query_table_expr 조회할 스키마 객체를 명시한다. flashback_query_clause 테이블, 뷰 또는 부질의의 예전 데이터를 보기 위해 명시한다. tab_alias 테이블, 뷰 또는 부질의에 대한 별칭을 명시한다. join_clause FROM 절에 명시된 테이블, 뷰, 부질의 간의 조인 관계를 명시한다. -
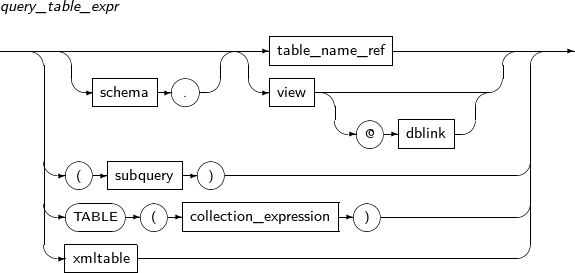
query_table_expr
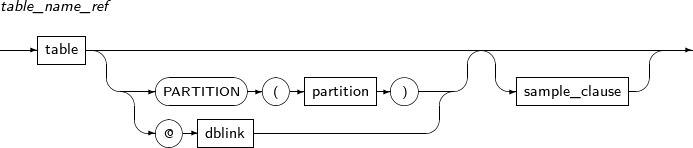
구성요소 설명 schema 테이블이나 뷰가 속한 스키마를 명시한다. 생략하면 현재 사용자의 스키마로 인식된다. table 테이블의 이름을 명시한다. PARTITION (partition) 특정 파티션의 이름을 명시한다. 테이블 전체가 아니라 명시된 파티션만 읽는다. dblink 데이터베이스 링크의 이름 전체 또는 부분을 명시한다.
데이터베이스 링크를 명시할 때는 반드시 앞에 '@'를 붙여야 한다.
링크는 다음과 같은 제약조건이 있다.
-
원격 테이블에서는 Tibero에서 지원하지 않는 사용자 정의 타입 또는 REF 객체에 대한 질의를 할 수 없다.
-
원격 테이블에서는 Tibero에서 지원하지 않는 ANYTYPE, ANYDATA 또는 ANYDATASET 타입의 컬럼에 대한 질의를 할 수 없다.
view 뷰의 이름을 명시한다. sample_clause 테이블의 데이터를 무작위로 일부만 읽도록 한다. subquery 부질의를 명시한다. collection_expression 파이프라인드 테이블 함수(Pipelined Table Function)을 명시한다. 함수의 결과값을 테이블처럼 이용할 수 있게 해준다. 자세한 설명과 예제는 "Tibero tbPSM 안내서"의 "제9장 파이프라인드 테이블 함수"를 참조한다. xmltable XMLTABLE 함수를 명시한다. -
-
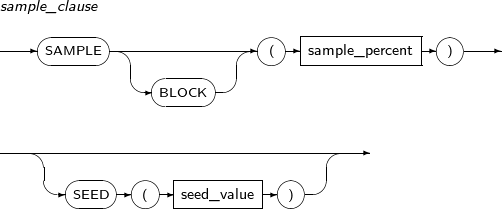
sample_clause
구성요소 설명 BLOCK 키워드를 명시하면 데이터 블록을 샘플링하고 명시하지 않으면 ROW를 샘플링한다. sample_percent 샘플링할 ROW 또는 블록의 비율을 설정한다.
이 값은 .000001부터 100 사이의 값을 가진다. 100은 포함하지 않는다.
seed_value 이 값이 같다면 다음 수행에서 동일한 샘플링 데이터를 취한다.
명시하지 않으면 다음 수행할 때 다른 데이터를 얻게된다. 이 값은 0부터 4294967295 사이의 값을 가진다.
-
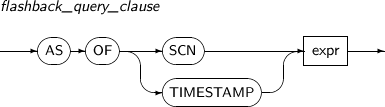
flashback_query_clause
구성요소 설명 expr 예전 시점을 나타내는 표현식이다.
-
SCN 또는 TIMESTAMP를 통해 특정 시점을 명시할 수 있다.
-
AS OF SCN을 사용하면 expr은 NUMBER 값이어야 한다.
-
AS OF TIMESTAMP를 사용하면 expr은 TIMESTAMP 값이어야 한다.
flashback_query_clause는 다음과 같은 제약조건이 있다.
-
expr에 컬럼, 부질의를 사용할 수 없다.
-
with_clause에 정의된 부질의를 참조하려고 table_reference에 사용된 query_name에는 사용할 수 없다.
-
-
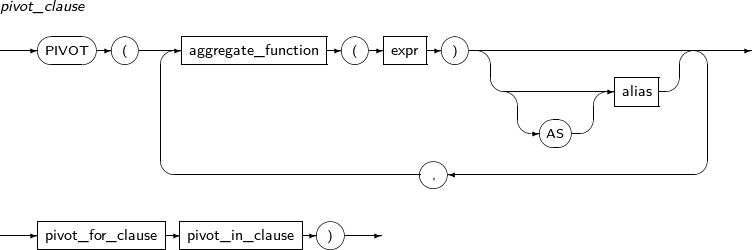
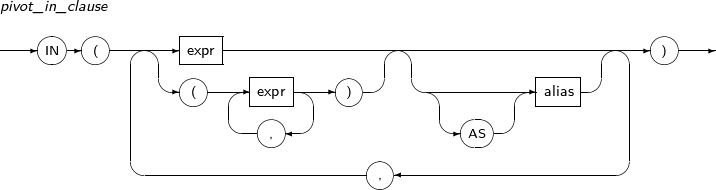
pivot_clause
피봇은 테이블의 행을 열로 바꾼다. 동일 그룹에 속한 행에 집합함수를 적용해서 새로운 열의 값으로 사용한다. 집합함수를 적용할 그룹을 결정하기 위한 GROUP BY 절은 사용하지 않는다. pivot_clause에 명시되지 않은 query_table_expr의 컬럼이 묵시적으로 GROUP BY 표현식으로 사용된다.
구성요소 설명 aggregate_function 컬럼의 값을 생성할 집합 함수를 명시한다.
alias를 명시하면 pivot_in_clause에서 생성된 컬럼명에 '_'와 alias를 추가로 붙여서 새로운 컬럼명을 생성한다.
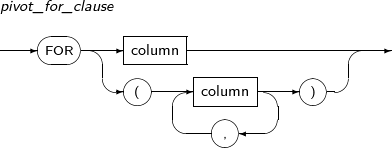
pivot_for_clause 피봇할 컬럼을 명시한다. pivot_in_clause 피봇할 컬럼의 값을 명시한다.
명시된 개수 많큼 새로운 컬럼이 만들어지고 값 별로 집함 함수를 적용해서 컬럼값을 계산한다. 명시되지 않은 값은 집함 함수에 적용되지 않는다.
alias를 사용하지 않으면 명시된 값을 컬럼명으로 사용한다.
-
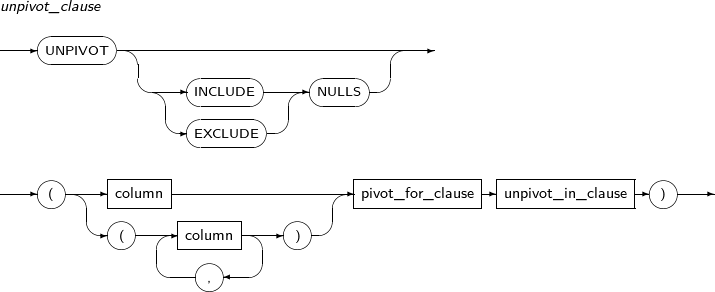
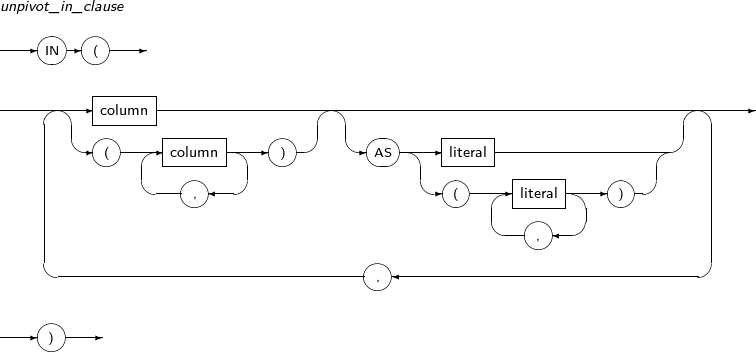
unpivot_clause
UNPIVOT은 테이블의 열을 행으로 바꾼다. 한 로우의 여러 컬럼을 여러 로우의 동일 컬럼으로 변환한다.
구성요소 설명 INCLUDE|EXCLUDE NULLS INCLUDE NULLS는 NULL 값을 포함해서 로우를 생성한다.
EXCLUDE NULLS이 명시되면 NULL 값으로 이루어진 로우를 생성하지 않는다. 명시하지 않으면 EXCLUDE NULLS가 기본값이다.
column UNPIVOT된 쿼리 결과에 생성되는 측정값 컬럼의 컬럼명을 명시한다.
UNPIVOT을 수행해서 보고자 하는 결과값을 측정값이라고 한다. 동일한 타입이거나 최종 결과 타입으로 변환이 가능한 타입이어야 한다.
pivot_for_clause UNPIVOT된 쿼리 결과에 생성되는 설명값 컬럼의 컬럼명을 명시한다. 이 컬럼에 채워지는 값은 측정값을 설명하는 용도로 사용된다. unpivot_in_clause column의 값은 측정값 컬럼의 값이 된다.
literal을 명시하면 설명값 컬럼의 값으로 사용된다. 명시하지 않으면 컬럼명을 값으로 사용한다.
-
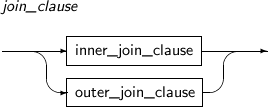
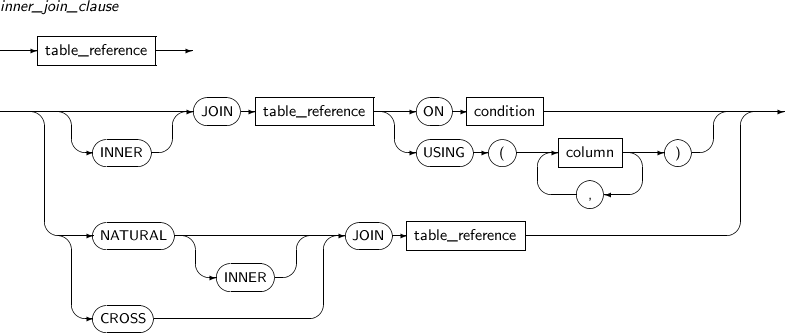
join_clause
구성요소 설명 inner_join_clause 내부 조인을 생성한다. 내부 조인 조건을 만족하는 ROW의 조인 결과만 조인된다. 내부(Inner)조인과 자연(Natural) 조인을 명시할 수 있다.
명시하지 않는다면 내부 조인이 된다.
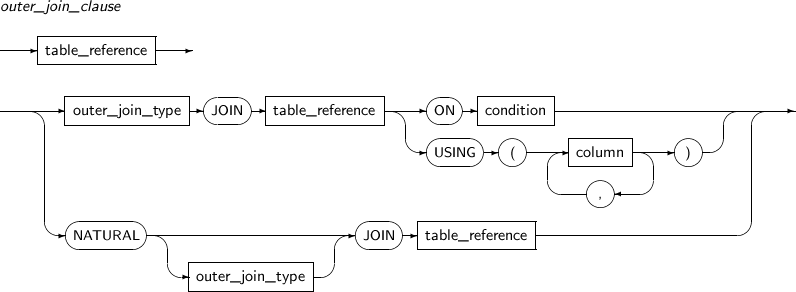
outer_join_clause 조인 조건에 맞는 모든 ROW와 한 쪽 테이블에서 조인 조건을 만족하지 않는 ROW가 선택된다.
조건을 만족하지 못한 ROW는 모든 컬럼이 NULL 값을 가지는 ROW와 조인되어 선택된다.
-
inner_join_clause
구성요소 설명 INNER 내부 조인을 명시한다. ON 절이나 USING 절에 의해 생성된 조인 조건을 만족하는 ROW만 조인된다. ON condition 조인 조건을 명시한다. USING column 두 테이블에서 동일한 이름을 가지는 컬럼을 명시한다. 명시된 컬럼명을 가지는 양 쪽 컬럼에 대해서 각각 동등 비교 조건을 모두 만족해야 한다는 조인 조건이 생성된다.
조인된 조건으로 사용된 컬럼은 조인된 ROW에 하나만 포함되고 테이블 이름이나 별칭과 함께 참조할 수 없다.
NATURAL 자연 조인을 명시한다. 두 테이블에서 동일한 이름을 갖는 컬럼은 각각 동등 비교 조건을 모두 만족해야 한다는 조인 조건이 생성된다.
조인 조건으로 사용된 컬럼은 조인된 ROW에 하나만 포함되고 테이블 이름이나 별칭과 함께 참조할 수 없다.
CROSS 크로스 조인을 생성한다. 조인 되는 두 테이블의 모든 ROW가 조인된다. -
outer_join_clause
옵션 설명 outer_join_type 외부 조인의 타입을 명시한다. ON condition 조인 조건을 명시한다. USING column 두 테이블에서 동일한 이름을 가지는 컬럼을 명시한다. 명시된 컬럼명을 가지는 양 쪽 컬럼에 대해서 각각 동등 비교 조건을 모두 만족해야 한다는 조인 조건이 생성된다.
조인된 조인 조건으로 사용된 컬럼은 조인된 ROW에 하나만 포함되고 테이블 이름이나 별칭과 함께 참조할 수 없다.
NATURAL 자연 조인을 명시한다. 두 테이블에서 동일한 이름을 갖는 컬럼은 각각 동등 비교 조건을 모두 만족해야 한다는 조인 조건이 생성된다.
조인 조건으로 사용된 컬럼은 조인된 ROW에 하나만 포함되고 테이블 이름이나 별칭과 함께 참조할 수 없다.
-
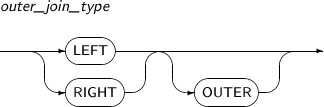
outer_join_type
구성요소 설명 LEFT 왼쪽 외부 조인을 명시한다. 왼쪽 테이블의 모든 컬럼이 선택된다. RIGHT 오른쪽 외부 조인을 명시한다. 오른쪽 테이블의 모든 컬럼이 선택된다. OUTER 생략할 수 있으며, 특별한 의미는 없다. -
cross_join_clause
구성요소 설명 table_reference 조인할 테이블, 뷰, 인라인 뷰 등을 명시한다. -
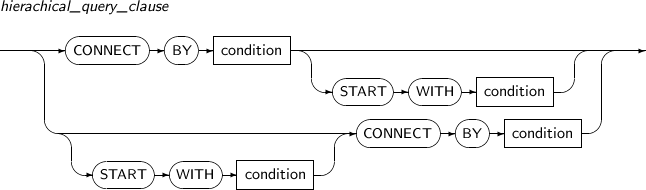
hierarchical_query_clause
구성요소 설명 CONNECT BY ROW의 상하 관계를 정의하는 조건식을 명시한다. START WITH 계층 내의 루트 ROW를 지정하기 위한 조건식을 명시한다. condition 조건식을 명시한다. -
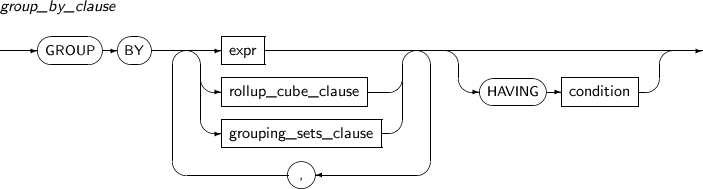
group_by_clause
구성요소 설명 expr 그룹을 분리하기 위한 연산식을 명시한다. rollup_cube_clause ROLLUP과 CUBE 연산을 명시한다. grouping_sets_clause GROUPING SETS을 명시한다. HAVING condition 원하는 그룹만 반환하도록 하는 조건식을 명시한다. -
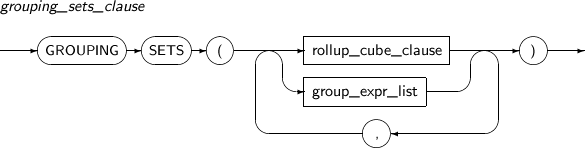
grouping_sets_clause
구성요소 설명 GROUPING SETS GROUPING SETS 뒤에 명시된 여러 개의 연산식을 바탕으로 선택된 ROW를 그룹으로 나누고, 각 그룹에 하나의 요약 정보 ROW를 반환한다.
CUBE 또는 ROLLUP은 모든 연산식 조합에 대하여 그룹을 나누지만 GROUPING SETS를 사용하면 원하는 연산식만으로 그룹을 나누기 때문에 좀 더 효과적이다. 여러 개의 연산식에 대하여 GROUP BY를 수행한 결과에 UNION ALL을 한 것과 같은 결과를 갖기 때문에 중복된 ROW를 만들어 낼 수 있다.
GROUPING SETS 뒤에 CUBE 또는 ROLLUP을 연산식 조합으로 명시 할 수 있는데 이런 경우에는 CUBE 또는 ROLLUP의 모든 연산식 조합을 직접 풀어 GROUPING SETS 뒤에 명시한 것과 같은 결과를 갖는다.
GROUPING SETS 뒤에 여러 개의 CUBE 또는 ROLLUP을 사용한 경우에는 각 연산식 조합의 cross product로 모든 연산식 조합을 계산하여 수행한다.
-
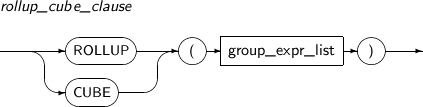
rollup_cube_clause
구성요소 설명 ROLLUP 질의에서 선택된 ROW를 ROLLUP 뒤의 n개의 연산식 중 앞에서부터 n, n-1, n-2, ...0 개의 연산식을 기반으로 하여 그룹으로 나누고, 각각의 그룹에 하나의 ROW를 반환한다.
예를 들어 SUM 집단 함수와 같이 사용했을 경우는 중간 중간의 소계를 계산하기 위한 방법으로 이것을 사용할 수 있다. 이 경우 SUM은 가장 아래 레벨의 소계에서부터 전체 총계까지를 모두 계산해 낸다.
CUBE CUBE 뒤에 명시된 연산식의 가능한 모든 조합으로 선택된 ROW를 그룹으로 나누고, 각 그룹에 하나의 요약 정보 ROW를 반환한다.
CUBE를 사용하여 교차표 값을 생성할 수 있다.
요약 정보는 그룹별 결과가 우선 출력되고, 그룹들의 요약 정보를 합친 결과가 나오는 순으로 출력되는데, 최종 결과 ROW는 전체의 요약 정보가 나오게 된다. 하지만, 반대로 전체 요약 정보부터 그룹들의 요약 정보, 그룹별 요약 정보 순으로 결과를 출력하고 싶은 경우에는 SUMMARY_FIRST_IN_GROUPBY_CUBE 파라미터를 켜줌으로써 출력 순서를 변경할 수가 있다.
group_expr_list 리스트 연산식으로 구성된 묶음이다. -
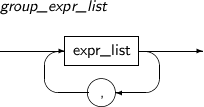
group_expr_list
구성요소 설명 expr_list 리스트 연산식이다. -
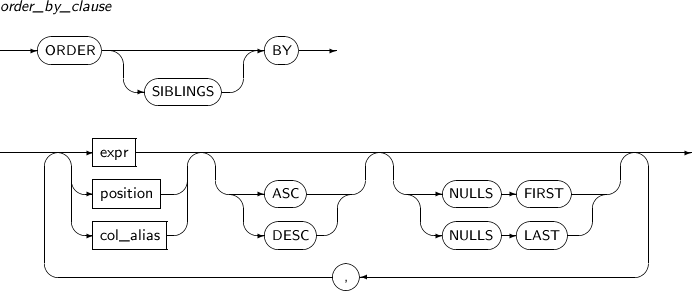
order_by_clause
구성요소 설명 SIBLINGS hierarchical_query_clause가 명시된 질의에 사용할 수 있다.
order_by_clause는 계층 질의의 형제 노드 내에서 정렬 순서를 정의하게 된다.
expr 정렬의 키로 사용되는 연산식이다. position select_list에 명시된 expr의 위치를 지정한다.
해당 위치의 expr이 정렬에 사용된다. 정수 값을 사용해야 한다.
col_alias 컬럼의 별칭을 명시한다. ASC 오름차순으로 정렬한다. (기본값) DESC 내림차순으로 정렬한다. 이 부분을 생략하면 ASC로 인식한다. NULLS FIRST NULL 값의 정렬 순서를 명시한다. NULLS FIRST는 내림차순 정렬의 디폴트로 사용된다. NULLS LAST NULL 값의 정렬 순서를 명시한다. NULLS LAST는 오름차순 정렬의 디폴트로 사용된다. -
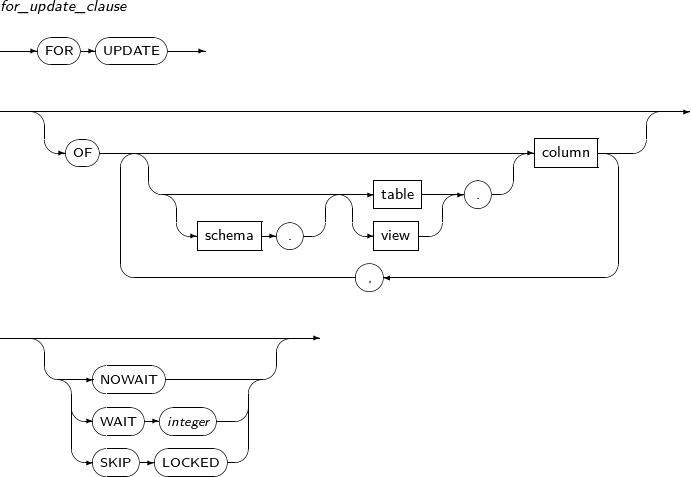
for_update_clause
구성요소 설명 OF column 일부 테이블 또는 뷰에만 잠금을 설정하고자 할 때에 사용한다.
OF 예약어 뒤에 잠금을 설정하고자 하는 테이블의 컬럼을 나열한다. 이때, 컬럼의 별칭은 사용할 수 없다.
schema 스키마의 이름을 명시한다. 생략하면 현재 사용자의 스키마로 인식된다. table 테이블의 이름을 명시한다. view 뷰의 이름을 명시한다. NOWAIT 해당 ROW에 다른 사용자가 설정한 잠금이 있어도 해제될 때까지 기다리지 않는다. WAIT 해당 ROW에 다른 사용자가 설정한 잠금이 있는 경우 해제될 때까지 integer 만큼의 시간(초) 동안 시도한다.
지정되지 않으면 잠금이 해제될 때까지 기다린다.
SKIP LOCKED 해당 ROW에 다른 사용자가 설정한 잠금이 있는 경우 해당 ROW를 건너뛰고 다음 ROW로 넘어간다. -
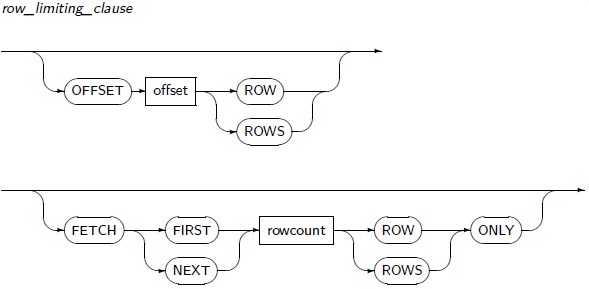
row_limiting_clause
구성요소 설명 OFFSET OFFSET 키워드를 사용하여 몇 개의 row를 건너뛸 것인지 결정한다. offset은 숫자 혹은 숫자 값으로 표현되는 식이어야 한다. 이 키워드를 지정하지 않으면 0으로 간주되어 첫 번째 row부터 결과 집합을 전달한다. ROW | ROWS 두 키워드는 의미적으로 명확성만 제공해줄 뿐 상호 교환하여 사용 가능하다. FETCH 전달할 결과 집합의 row 수를 지정한다. 이 키워드를 지정하지 않으면 offset + 1 행부터 시작하여 모든 결과 집합을 전달한다. FIRST | NEXT 두 키워드는 의미적으로 명확성만 제공해줄 뿐 상호 교환하여 사용 가능하다. rowcount rowcount는 숫자 혹은 숫자 값으로 표현되는 식이어야 한다. rowcount가 offset + 1부터 시작해서 전달할 수 있는 모든 결과 집합의 row 수보다 클 경우 모든 가능한 결과 집합을 전달한다. ROW | ROWS 두 키워드는 의미적으로 명확성만 제공해줄 뿐 상호 교환하여 사용 가능하다. ONLY 지정한 row 수만 정확하게 반환할 때 사용한다. -
집합 연산자
2개의 SELECT 문의 결과를 하나의 결과 집합으로 결합하는데 사용된다.
select_list에 대응되는 컬럼의 타입과 개수는 일치해야 한다. 컬럼의 길이는 다를 수 있다. 참조되는 컬럼의 이름은 제일 좌측에 명시된 SELECT문의 select_list 절이 사용된다. SELECT 문이 집합 연산자에 의해 결합되는 경우 왼쪽에서 오른쪽 순서로 질의를 수행하게 된다. 자세한 내용은 “5.4. 집합 연산자”를 참고한다.
-
-
예제
다음은 SELECT를 사용하는 예이다.
SELECT * FROM EMP; SELECT ENAME, SALARY * 1.05 FROM EMP WHERE DEPTNO = 5; SELECT ENAME, SALARY, DEPT.* FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO; SELECT ENAME, SALARY, LOC FROM EMP NATURAL JOIN DEPT; SELECT ENAME FROM EMP WHERE DEPTNO = 5 UNION SELECT ENAME FROM EMP WHERE DEPTNO = 7; SELECT DEPTNO, MAX(SALARY) FROM EMP GROUP BY DEPTNO HAVING DEPTNO >= 5; SELECT DISTINCT DEPTNO FROM EMP; SELECT * FROM EMP WHERE DEPTNO = 5 FOR UPDATE; SELECT ENAME, D.* FROM EMP E, DEPT D WHERE E.DEPTNO = D.DEPTNO FOR UPDATE OF LOC;
다음은 시간을 사용해서 FLASHBACK 쿼리를 수행한 예이다.
SQL> create table todo (item varchar2(20), duedate date); Table 'TODO' created. SQL> insert into todo values ('결혼식 참석', '2012-04-01'); 1 row inserted. SQL> insert into todo values ('장보기', '2011-12-28'); 1 row inserted. SQL> commit; Commit completed. SQL> select systimestamp from dual; SYSTIMESTAMP ----------------------------------------------------------------- 2011/12/28 18:41:33.854889 1 row selected. SQL> select * from todo; ITEM DUEDATE -------------------- -------------------------------- 결혼식 참석 2012/04/01 장보기 2011/12/28 2 rows selected. SQL> insert into todo values ('신문대금납부', '2011-12-31'); 1 row inserted. SQL> commit; Commit completed. SQL> select * from todo; ITEM DUEDATE -------------------- -------------------------------- 결혼식 참석 2012/04/01 장보기 2011/12/28 신문대금납부 2011/12/31 3 rows selected. SQL> select * from todo as of timestamp '2011/12/28 18:41:33.854889'; ITEM DUEDATE -------------------- -------------------------------- 결혼식 참석 2012/04/01 장보기 2011/12/28 2 rows selected.다음은 TSN을 사용해서 FLASHBACK 쿼리를 수행한 예이다. 동적뷰 V$TSN_TIME을 이용하면 TSN과 시간의 맵핑 정보를 알 수 있다.
SQL> create table todo (item varchar2(20), duedate date); Table 'TODO' created. SQL> insert into todo values ('결혼식 참석', '2012-04-01'); 1 row inserted. SQL> insert into todo values ('장보기', '2011-12-28'); 1 row inserted. SQL> commit; Commit completed. SQL> select systimestamp from dual; SYSTIMESTAMP ----------------------------------------------------------------- 2011/12/29 09:48:35.494024 1 row selected. SQL> select * from todo; ITEM DUEDATE -------------------- -------------------------------- 결혼식 참석 2012/04/01 장보기 2011/12/28 2 rows selected. SQL> insert into todo values ('신문대금납부', '2011-12-31'); 1 row inserted. SQL> commit; Commit completed. SQL> select systimestamp from dual; SYSTIMESTAMP ----------------------------------------------------------------- 2011/12/29 09:49:05.635549 1 row selected. SQL> select * from todo; ITEM DUEDATE -------------------- -------------------------------- 결혼식 참석 2012/04/01 장보기 2011/12/28 신문대금납부 2011/12/31 3 rows selected. SQL> select * from v$tsn_time where time >= '2011/12/29 09:48:35.494024' and time <= '2011/12/29 09:49:05.635549'; TSN TIME ---------- ----------------------------------------------------------------- 12347 2011/12/29 09:48:36.018269 12347 2011/12/29 09:48:37.019113 12348 2011/12/29 09:48:38.020786 12348 2011/12/29 09:48:39.021757 12348 2011/12/29 09:48:40.022545 12349 2011/12/29 09:48:42.023222 12350 2011/12/29 09:48:43.722855 12350 2011/12/29 09:48:45.023568 12350 2011/12/29 09:48:46.024370 12351 2011/12/29 09:48:48.024938 12351 2011/12/29 09:48:49.025834 12352 2011/12/29 09:48:50.026523 12352 2011/12/29 09:48:51.027325 12352 2011/12/29 09:48:52.028122 12353 2011/12/29 09:48:54.027811 12353 2011/12/29 09:48:55.027850 12353 2011/12/29 09:48:56.028738 12354 2011/12/29 09:48:58.029017 12354 2011/12/29 09:48:59.030678 12355 2011/12/29 09:49:00.031466 12357 2011/12/29 09:49:02.033270 12357 2011/12/29 09:49:03.033251 12358 2011/12/29 09:49:04.034311 TSN TIME ---------- ----------------------------------------------------------------- 12358 2011/12/29 09:49:05.034333 24 rows selected. SQL> select * from todo as of scn 12350; ITEM DUEDATE -------------------- -------------------------------- 결혼식 참석 2012/04/01 장보기 2011/12/28 2 rows selected.다음은 PIVOT/UNPIVOT을 사용하는 예이다.
SQL> SELECT * FROM (SELECT deptno, job, sal FROM emp ) PIVOT (SUM(sal) salary_sum FOR deptno IN (10 dept10 ,20 dept20, 30 dept30) ); JOB DEPT10_SALARY_SUM DEPT20_SALARY_SUM DEPT30_SALARY_SUM --------- ----------------- ----------------- ----------------- MANAGER 2450 2975 2850 PRESIDENT 5000 SALESMAN 5600 ANALYST 6000 CLERK 1300 1900 950 5 rows selected. SQL> CREATE VIEW pivoted_emp as SELECT * FROM (SELECT deptno, job, sal FROM emp ) PIVOT (SUM(sal) salary_sum FOR deptno IN (10 dept10 ,20 dept20, 30 dept30) ); View 'PIVOTED_EMP' created. SQL> SELECT * FROM pivoted_emp UNPIVOT ( salary_sum FOR department IN (dept10_salary_sum as 10, dept20_salary_sum as 20, dept30_salary_sum as 30) ); JOB DEPARTMENT SALARY_SUM --------- ---------- ---------- MANAGER 10 2450 MANAGER 20 2975 MANAGER 30 2850 PRESIDENT 10 5000 SALESMAN 30 5600 ANALYST 20 6000 CLERK 10 1300 CLERK 20 1900 CLERK 30 950 9 rows selected. SQL> SELECT * FROM pivoted_emp UNPIVOT INCLUDE NULLS ( salary_sum FOR department IN (dept10_salary_sum as 10, dept20_salary_sum as 20, dept30_salary_sum as 30) ); JOB DEPARTMENT SALARY_SUM --------- ---------- ---------- MANAGER 10 2450 MANAGER 20 2975 MANAGER 30 2850 PRESIDENT 10 5000 PRESIDENT 20 PRESIDENT 30 SALESMAN 10 SALESMAN 20 SALESMAN 30 5600 ANALYST 10 ANALYST 20 6000 ANALYST 30 CLERK 10 1300 CLERK 20 1900 CLERK 30 950 15 rows selected.
조인(Join)은 두 개 또는 여러 개의 테이블이나 뷰로부터 로우를 결합하는 질의이다. Tibero에서는 FROM 절에 다수의 테이블이 있을 때 조인을 실행한다.
질의의 SELECT 절에서 조인 테이블에 속하는 컬럼을 선택할 수 있다. 만일 조인될 테이블 중에 같은 이름의 컬럼이 2개 이상이 있다면 테이블 이름을 함께 명시해 모호함을 없애야 한다.
대부분의 조인 질의는 서로 다른 두 테이블의 컬럼을 비교하는 WHERE 절의 조건을 포함한다. 이런 조건을 조인 조건 (Join Condition)이라고 한다.
조인을 실행하기 위해서 각 테이블의 로우를 하나씩 가져와 조인 조건이 TRUE로 결정되는 경우에만 결합한다. 조인 조건에 포함되는 컬럼이 반드시 SELECT절에 포함될 필요는 없다.
세 개 이상의 테이블을 조인할 때는 우선 두 개의 테이블과 그 두 테이블의 컬럼에 대응 되는 조인 조건을 이용해서 조인을 한다. 그 후에, 그 두 테이블의 조인 결과의 컬럼과 세 번째 조인할 테이블의 컬럼에 해당하는 조인 조건으로 조인하여 새로운 결과를 만든다.
Tibero는 이러한 과정을 하나의 결과가 나올 때까지 반복한다. 최적화기(Optimizer)는 조인 조건과 테이블에 대한 인덱스와 통계 정보를 사용해 테이블 간의 조인 순서를 정한다. WHERE 절에 조인 조건 이외에 테이블에 하나에 대한 조건도 있을 수 있는데, 이러한 조건은 조인 질의로 반환되는 로우를 더욱 한정한다.
카티션 프로덕트
조인 질의에서 테이블에 대한 조인 조건이 없을 경우 카티션 프로덕트(Cartesian Products)를 반환한다. 카티션 프로덕트는 테이블의 한 로우가 다른 테이블의 모든 로우와 결합되는 것을 말한다.
예를 들어 100개의 로우를 가지는 두 개의 테이블의 카티션 프로덕트는 100 * 100 = 10,000로우이다. 카티션 프로덕트는 이렇게 결과가 너무 많기 때문에 거의 사용되지 않는다. 특별히 카티션 프로덕트가 필요한 경우가 아니라면, 항상 조인 조건을 포함해야 한다. 만일 3개 이상의 테이블을 조인 할 때 그 중 2개의 테이블에 대한 조인 조건이 없었다면, 최적화기는 되도록 카티션 프로덕트가 생기지 않도록 조인순서를 정할 것이다.
동등 조인(Equi Join)은 동등 연산자(=)로 구성된 조인 조건을 포함한 조인이다. 동등 조인은 정해진 컬럼에 대해 같은 값을 가지는 로우를 결합하여 결과로 반환한다.
자체 조인(Self Join)은 하나의 테이블을 사용해서 자신에게 조인하는 것을 의미한다. 동일한 하나의 테이블이 FROM 절에 두 번 사용되기 때문에 별칭을 사용하여 컬럼을 구분한다.
간단한 조인(Simple Join)이라고도 불리는 내부 조인(Inner Join)은 조인 조건을 만족하는 로우만 반환하는 2개 이상의 테이블에 대한 조인이다.
외부 조인(Outer Join)은 일반 조인을 확장한 결과를 출력한다. 외부 조인은 조인 조건을 만족하는 로우뿐만 아니라, 한 테이블의 어떤 로우에 대해 반대편 테이블의 모든 로우가 조인 조건을 만족하지 못하는 경우에도 그 로우를 출력한다.
외부 조인은 왼쪽 외부 조인, 오른쪽 외부 조인, 완전 외부 조인이 있다.
-
왼쪽 외부 조인(left outer join)
-
오른쪽 외부 조인(right outer join)
-
테이블 A와 B를 조인하는 경우 조인 조건에 맞는 로우를 출력하고, B의 로우 중에 조인 조건에 맞는 A의 로우가 없는 경우에도 그 로우를 모두 출력한다.
-
B의 로우 중 조인 조건을 만족하는 A의 로우가 없는 로우에 대해서는 조인의 출력에서 A 컬럼이 필요한 부분에 모두 NULL을 출력한다.
-
오른쪽 외부 조인을 SQL 문장에 명시하려면 RIGHT [OUTER] JOIN을 FROM 절에 명시하거나, WHERE 절의 조인 조건에 있는 A의 모든 컬럼에 외부 조인 연산자 '(+)'를 명시한다.
-
-
완전 외부 조인(full outer join)
-
테이블 A와 B를 조인하는 경우 조인 조건에 맞는 로우를 출력하고, A의 로우 중에 조인 조건에 맞는 B 의 로우가 없는 경우에도 그 로우를 모두 출력하고, B의 로우 중에 조인 조건에 맞는 A의 로우가 없는 경우에도 그 로우를 모두 출력한다.
-
A의 로우 중 조인 조건을 만족하는 B의 로우가 없는 로우에 대해서는 조인의 출력에서 B 컬럼이 필요한 부분에 모두 NULL을 출력한다. B의 로우 중 조인 조건을 만족하는 A의 로우가 없는 로우에 대해서는 조인의 출력에서 A 컬럼이 필요한 부분에 모두 NULL을 출력한다.
-
완전 외부 조인을 SQL 문장에 명시하려면 FULL [OUTER] JOIN을 FROM 절에 명시한다.
-
여러 테이블 간의 외부 조인을 수행하는 질의에서 하나의 테이블은 오직 다른 하나의 테이블에 대해서만 NULL을 제공하는 테이블의 역할을 할 수 있다. 따라서, 테이블 A와 B에 대한 조건과 테이블 B와 C에 대한 조건에서 모두 B의 컬럼 쪽에 (+) 연산자를 적용할 수는 없다.
외부 조인 연산자 (+)에는 FROM 절에 외부 조인을 명시할 경우에 다음과 같은 규칙과 제약 조건이 있다.
-
FROM 절에 조인이 있는 질의 블록에는 외부 조인을 사용할 수 없다.
-
(+) 연산자는 WHERE 절에만 올 수 있고, 테이블이나 뷰의 컬럼에만 적용할 수 있다.
-
테이블 A와 B의 조인 조건이 여러 개 있을 경우에는 '(+)' 연산자를 모든 조건에 사용해야 한다. 그렇지 않은 경우에는 아무런 경고나 에러 메시지 없이 일반 조인과 같이 취급한다.
-
(+) 연산자를 외부 테이블과 내부 테이블에 모두 사용할 경우에는 일반 조인과 같이 취급한다.
-
(+) 연산자는 컬럼에만 적용될 수 있고, 일반 연산식에는 적용될 수 없다. 단, 연산식 내의 컬럼에 '(+)' 연산자를 적용할 수는 있다.
-
(+) 연산자를 포함하는 조건은 WHERE 절의 다른 조건과 OR 연산자를 통해 묶일 수 없다.
-
(+) 연산자가 적용된 컬럼을 IN 연산자를 이용해 비교하는 조건을 사용할 수 없다.
-
(+) 연산자가 적용된 컬럼을 부질의의 결과와 비교할 수 없다.
-
테이블 A와 B의 외부 조인의 조건 중에 B의 컬럼을 상수와 비교하는 조건이 있다면, '(+)' 연산자를 B의 컬럼에 적용해야 한다. 그렇지 않으면, 일반 조인과 같이 취급한다.
안티 조인(Anti Join)은 프리디키트의 오른쪽 부분에 해당하는 로우가 없는 왼쪽 부분의 프리디키트에 해당하는 로우를 반환한다. 즉 프리디키트의 오른쪽 부분을 NOT IN의 부질의로 실행했을 때 일치하지 않는 로우를 반환한다.
질의를 사용해서 어떤 문제를 해결하고자 할 때 단계를 나누어서 수행하면 좀 더 쉽게 문제를 풀 수 있는 경우가 있다.
예를 들어 Peter라는 사람이 속해있는 부서에서 일하는 사람 모두를 구하고자 할 때 먼저 Peter의 부서를 구하는 질의를 작성한 다음, 그 질의의 결과를 이용해 최종 답을 얻는 형태로 단계를 나눈 질의를 생각해 볼 수 있다. 이처럼 하나의 질의가 내부에 또 다른 질의를 포함하고 있을 경우 이 내부에 포함된 질의를 부질의(Subquery)라고 한다.
부질의는 질의가 사용된 위치에 따라 다음과 같이 두 가지 형태로 나눌 수 있다.
| 부질의 종류 | 설명 |
|---|---|
| 인라인 뷰 | 부질의가 부모 질의의 FROM 절에서 사용되었을 경우 이런 부질의를 보통 인라인(Inline) 뷰라고 부른다. |
| 중첩된 부질의 | 부 질의가 부모 질의의 SELECT 리스트 또는 WHERE 절 등에서 사용되었을 경우 이런 부질의를 중첩된(Nested) 부질의 또는 부질의라고 부른다. |
부질의는 다음과 같은 경우에 종종 사용된다.
-
INSERT 문을 통해 삽입할 로우의 값을 결정할 때
-
CREATE TABLE을 통해 테이블을 생성함과 동시에 테이블의 내용을 채울 때
-
CREATE VIEW 문을 통해 뷰가 질의하는 로우의 집합을 정의할 때
-
UPDATE 문에서 UPDATE할 값을 결정할 때
-
SELECT, UPDATE, DELETE 문에서 WHERE 절, HAVING 절, START WITH 절과 같은 조건을 명시할 때
-
테이블처럼 사용하고 싶은 로우의 집합을 정의할 때(SELECT의 FROM 절 또는 INSERT, UPDATE, DELETE에서 테이블을 명시할 수 있는 자리에 사용할 수 있다.)
참고
부질의는 내부에 다른 부질의를 포함할 수 있으며, Tibero에서는 부질의가 다른 부질의를 포함할 수 있는 단계에 대해 제한을 두지 않는다.
다음은 부질의와 컬럼 참조에 대한 설명이다.
부질의의 컬럼을 참조할 때의 규칙은 다음과 같다.
-
서로 관련된 부질의 내에서 부모 질의의 FROM 절의 테이블의 컬럼을 참조할 때 자신의 FROM 절의 테이블의 컬럼과 동일한 이름을 가지고 있는 컬럼을 참조하고자 하는 경우에는 컬럼 이름 앞에 부모 질의의 테이블 이름을 붙여 주어야 한다.
-
부모 질의의 컬럼을 참조할 때 위로 올라가는 단계에 대한 제한은 없다. 서로 관련된 부질의는 부모 질의의 각각의 로우를 처리할 때 매번 일일이 별도로 수행된다.
-
컬럼 이름에 대한 모호함이 발생하지 않는 한, 부질의에서 명시하는 (테이블 이름을 앞에 붙이지 않은) 컬럼 이름은 자신의 FROM 절의 테이블에서부터 시작해서 자신의 부모, 부모의 부모 순으로 컬럼 이름을 찾아본다.
서로 관련된 부질의는 하위 단계에서 구하고자 하는 값이 상위 단계의 각각의 로우에 따라 별도로 결정되어야 하는 경우에 사용된다.
다음과 같은 경우를 가정해 보자.
-
자신의 부서의 평균 연봉보다 많은 연봉을 받는 사원의 리스트를 구하는 질의가 있다.
-
이때, 하위 단계에서 계산하고자 하는 값은 각 사원에 대해서 그 사원이 근무하고 있는 부서의 평균 연봉이 된다.
-
또한, 상위 단계에서는 하위 단계에서 구한 평균 연봉을 현재 사원의 연봉과 비교하게 된다.
이러한 경우 평균 연봉을 각 사원에 대해 매번 구해야 하므로 이럴 경우 서로 관련된 부질의를 구사해서 문제를 해결할 수 있다.
다음은 스칼라(scalar) 부질의에 대한 설명이다. 자세한 내용은 “3.3.6. 부질의 연산식”을 참고한다.
집합 연산자는 두 개의 질의를 하나로 결합하는 데 사용된다. 집합 연산자에 의해 결합된 질의의 select_list에 명시된 연산식의 개수는 동일해야 하고 대응되는 연산식은 같은 데이터 타입 그룹에 속해야 한다.
다음은 집합 연산자의 우선순위에 대한 설명이다.
| 우선순위 | 집합 연산자 | 설명 |
|---|---|---|
| 1 | INTERSECT | 두 개의 질의 결과 양쪽 모두에 존재하는 로우를 결과로 반환한다. (A ∩ B) |
| 2 | UNION | 두 개의 질의의 결과에서 중복된 로우를 제거한 후 결과를 반환한다. (A ∪ B) |
| UNION ALL | 두 개의 질의의 결과에서 중복된 로우를 제거시키지 않고 모든 결과를 반환한다. (A + B) | |
| MINUS | 앞의 질의 결과에서 뒤의 질의 결과를 뺀 결과를 반환한다. (A - B) | |
| EXCEPT | MINUS 집합 연산자와 동일하게 동작한다. (A - B) |
두 개 이상의 질의가 집합 연산자에 의해 결합되면, 다음과 같은 규칙이 적용된다.
-
왼쪽에서 오른쪽 순서로 질의를 수행한다.
-
괄호를 사용하여 쿼리의 수행 순서를 조정할 수 있다.
집합 연산자는 다음과 같은 제약조건이 있다.
-
select_list가 BLOB, CLOB 타입의 연산식을 가질 경우 집합 연산자를 사용할 수 없다.
-
UNION, INTERSECT, MINUS, EXCEPT 연산자의 경우 LONG 타입의 컬럼이 허용되지 않는다.
-
먼저 명시된 질의의 select_list에 나오는 연산식에 별칭이 명시되어야만 order_by_clause에서 참조할 수 있다.
-
for_update_clause를 명시할 수 없다.
대응되는 연산식이 동일한 데이터 타입의 그룹이 아니면 암시적인 형 변환은 허용되지 않으며, 동일한 데이터 타입의 그룹이면 다음과 같은 형 변환이 일어난다.
-
데이터 타입의 그룹이 숫자이면, 결과는 NUMBER 타입이다.
-
데이터 타입의 그룹이 문자이면, 다음의 규칙에 의해 결과의 데이터 타입이 결정된다.
-
양쪽이 CHAR 타입이면, 결과는 CHAR 타입이다.
-
하나 또는 양쪽 모두 VARCHAR2 타입이면, 결과는 VARCHAR2 타입이다.
-
계층 질의(Hierarchical Query)란 테이블에 포함된 로우 사이에 상하 계층 관계가 성립된 경우 그 상관 관계에 따라 로우를 출력하는 질의이다.
하나의 대상 테이블에 계층 관계는 하나 이상 정의할 수 있으며, 계층 질의는 하나의 테이블 또는 조인된 둘 이상의 테이블에 대해서도 가능하다.
계층 질의를 위하여 SELECT 문장 내에 START WITH … CONNECT BY 절을 이용한다.
-
START WITH 절과 CONNECT BY 절에는 하나의 조건식이 포함되며, 단순 조건식 또는 복합 조건식일 수 있다. 자세한 내용은 “3.4. 조건식”을 참고한다.
PRIOR
CONNECT BY 절에는 다른 조건식에서는 포함되지 않는 특별한 연산자가 사용되는데, 로우 간의 상하 관계를 나타내기 위한 PRIOR 연산자이다.
PRIOR 연산자가 포함된 조건식은 다음과 같은 형식을 갖는다.
PRIOR expr = expr expr = PRIOR expr
PRIOR 쪽의 연산식의 결과 값을 갖는 로우가 반대 쪽의 연산식의 결과 값을 갖는 로우의 부모가 된다.
예를 들어 두 개의 컬럼 EMPNO와 MGRNO를 포함하는 테이블 EMP에 대하여 다음의 조건식을 이용하여 계층 질의를 수행한다면, 특정 (부모) 로우의 EMPNO 컬럼 값과 같은 MGRNO 컬럼 값을 갖는 모든 로우는, EMPNO 컬럼 값을 갖는 로우의 자식 로우가 된다.
PRIOR EMPNO = MGRNO
다음의 테이블 EMP2 내의 로우 중에서 EMPNO 컬럼 값이 27인 (부모) 로우에 대하여 EMPNO 컬럼 값이 35, 42인 로우가 자식 로우가 된다. 두 컬럼 모두 MGRNO 컬럼 값이 27이기 때문이다.
EMPNO ENAME ADDR SALARY MGRNO
---------- ------------ ---------------- ---------- ----------
35 John Houston 30000 27
54 Alicia Castle 25000 24
27 Ramesh Humble 38000 12
69 James Houston 35000 24
42 Allen Brooklyn 29000 27
87 Ward Humble 28500 35
24 Martin Spring 30000 12
12 Clark Palo Alto 45000 5
CONNECT BY 절의 조건식은 여러 단순 조건식이 연결된 복합 조건식이 될 수 있다. 하지만, PRIOR 연산자를 포함한 단순 조건식은 반드시 하나만 포함되어야 하며, 0개 또는 2개 이상이 포함된 경우에는 에러를 반환한다. CONNECT BY 절의 조건식은 부질의를 포함할 수 없다.
CONNECT_BY_ROOT
계층 질의에서만 사용되는 또 다른 특수 연산자로 CONNECT_BY_ROOT 연산자가 있다.
CONNECT_BY_ROOT 연산자를 사용하면 데이터베이스는 루트 로우의 데이터를 이용하여 컬럼 값을 반환한다.
다음은 CONNECT_BY_ROOT 연산자를 사용한 예이다.
SQL> SELECT ENAME, CONNECT_BY_ROOT ENAME MANAGER,
SYS_CONNECT_BY_PATH(ENAME, '-') PATH
FROM EMP2
WHERE LEVEL > 1
CONNECT BY PRIOR EMPNO = MGRNO
START WITH ENAME = 'Clark';
ENAME MANAGER PATH
--------------- --------------- -----------------------
Martin Clark -Clark-Martin
James Clark -Clark-Martin-James
Alicia Clark -Clark-Martin-Alicia
Ramesh Clark -Clark-Ramesh
Allen Clark -Clark-Ramesh-Allen
JohnClark Clark -Ramesh-John
Ward Clark -Clark-Ramesh-John-Ward
7 rows selected.
-
CONNECT BY 절
CONNECT BY 절의 조건식에는 등호 이외에 다른 비교 연산자를 사용할 수 있다. 하지만, 이때 상하 관계가 순환적으로 정의될 수 있으며 무한 루프에 빠질 수 있다. 이러한 경우 Tibero에서는 에러를 반환하고 실행을 중지한다.
-
START WITH 절
START WITH 절은 계층 관계를 검색하기 위한 루트 로우에 대한 조건식을 포함한다. 조건식에 따라 0개 이상의 루트 로우로부터 시작될 수 있다. 만약 START WITH 절이 생략되면 대상 테이블 내의 모든 로우를 루트 로우로 하여 계층 관계를 검색한다.
-
CONNECT BY 절과 WHERE 절의 혼합
하나의 SELECT 문 내에 CONNECT BY 절과 WHERE 절이 함께 사용된 경우 CONNECT BY 절의 조건식을 먼저 적용한다. 만약 SELECT 문이 조인 연산을 수행하며 WHERE 절 내에 조인 조건이 포함되어 있다면, 조인 조건만 먼저 적용하여 조인을 수행한 후에 CONNECT BY 절의 조건식과 WHERE 절 내의 나머지 조건식을 차례로 적용한다.
WHERE 절 내의 조건식은 CONNECT BY 절의 조건식에 의하여 로우 간에 상하 관계가 정해진 후에 적용되므로, 특정 로우가 WHERE 절에 의하여 제거되더라도 그 로우의 하부 로우도 최종 결과에 포함될 수 있다.
-
ORDER SIBLINGS BY 절
계층 질의에 대해 일반적인 ORDER BY를 사용할 경우 상하 관계를 무시하고 정렬이 된다. 그러나 ORDER SIBLINGS BY 절을 사용할 경우엔 계층간의 상하 관계를 유지한 상태에서 같은 레벨에 있는 로우 들에 대해서만 정렬을 하므로 원하는 결과를 얻을 수 있다.
계층 질의는 재귀적(Recursive)으로 실행된다.
먼저 하나의 루트 로우에 대해 모든 자식 로우를 검색한다. 그 다음 각 자식 로우의 자식 로우를 다시 검색한다. 이러한 방법으로 다시는 자식 로우가 발견되지 않을 때까지 계속 진행한다. 만약 무한 루프가 되면 에러를 반환한다.
계층 질의의 결과를 출력하는 순서는 깊이 우선(Depth-First) 순서를 따른다.
다음의 그림은 테이블 EMP2의 계층 질의 결과로 구성된 계층 관계의 한 예이며, 원 안의 값은 EMPNO 컬럼의 값이다. 이때, 로우의 출력 순서는 12, 27, 35, 87, 42, 24, 54, 69이다.
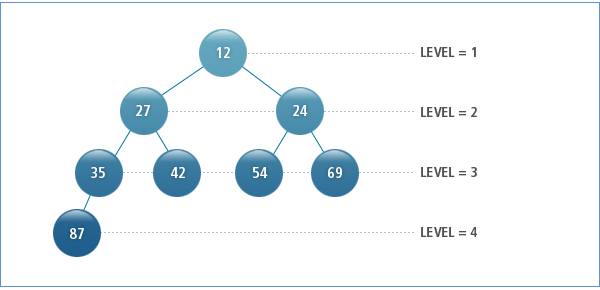
계층 트리의 각 로우는 레벨 값을 갖는다. 루트 로우의 레벨 값은 1이며 자식 로우로 내려가면서 1씩 증가한다. 따라서, 위의 [그림 5.1]에서 EMPNO = 12인 로우는 레벨이 1이며, EMPNO = 27, 24인 로우는 레벨이 2, EMPNO = 35, 42, 54, 69인 로우는 레벨이 3, EMPNO = 87인 로우는 레벨이 4다.
레벨 값은 의사 컬럼인 LEVEL 컬럼의 값으로 출력할 수 있다.
다음은 START WITH 절을 이용하지 않고 계층 질의를 실행하는 SELECT 문의 예이다. 본 예제에서는 모든 로우를 루트 로우로 하여 하부 로우를 출력한다.
SQL> SELECT EMPNO, ENAME, ADDR, MGRNO
FROM EMP2
CONNECT BY PRIOR EMPNO = MGRNO;
EMPNO ENAME ADDR MGRNO
---------- ------------ ---------------- ----------
12 Clark Palo Alto 5
27 Ramesh Humble 12
35 John Houston 27
87 Ward Humble 35
42 Allen Brooklyn 27
24 Martin Spring 12
54 Alicia Castle 24
69 James Houston 24
27 Ramesh Humble 12
35 John Houston 27
87 Ward Humble 35
42 Allen Brooklyn 27
24 Martin Spring 12
54 Alicia Castle 24
69 James Houston 24
54 Alicia Castle 24
69 James Houston 24
35 John Houston 27
87 Ward Humble 35
42 Allen Brooklyn 27
87 Ward Humble 35
21 rows selected.
다음은 START WITH 절을 이용하여 계층 질의를 실행하는 SELECT 문의 예이다. 본 예제에서는 EMPNO = 12인 조건식을 만족하는 하나의 루트 로우에 대해서만 하부 로우를 검색한다.
SQL> SELECT EMPNO, ENAME, ADDR, MGRNO
FROM EMP2
START WITH EMPNO = 12
CONNECT BY PRIOR EMPNO = MGRNO;
EMPNO ENAME ADDR MGRNO
---------- ------------ ---------------- ----------
12 Clark Palo Alto 5
27 Ramesh Humble 12
35 John Houston 27
87 Ward Humble 35
42 Allen Brooklyn 27
24 Martin Spring 12
54 Alicia Castle 24
69 James Houston 24
8 rows selected.
다음은 WHERE 절을 포함하여 계층 질의를 실행하는 SELECT 문의 예이다. 본 예제에서는 EMPNO = 27인 로우가 WHERE 절 때문에 제거되었으나, 그 하부 로우는 모두 그대로 출력된다.
SQL> SELECT EMPNO, ENAME, ADDR, MGRNO
FROM EMP2
WHERE ENAME != ’Ramesh’
START WITH EMPNO = 12
CONNECT BY PRIOR EMPNO = MGRNO;
EMPNO ENAME ADDR MGRNO
---------- ------------ ---------------- ----------
12 Clark Palo Alto 5
35 John Houston 27
87 Ward Humble 35
42 Allen Brooklyn 27
24 Martin Spring 12
54 Alicia Castle 24
69 James Houston 24
7 rows selected.
다음은 LEVEL 컬럼을 포함하여 계층 질의를 실행하는 SELECT 문의 예이다.
SQL> SELECT EMPNO, ENAME, ADDR, MGRNO, LEVEL
FROM EMP2
START WITH EMPNO = 12
CONNECT BY PRIOR EMPNO = MGRNO;
EMPNO ENAME ADDR MGRNO LEVEL
---------- ------------ ---------------- ---------- ----------
12 Clark Palo Alto 5 1
27 Ramesh Humble 12 2
35 John Houston 27 3
87 Ward Humble 35 4
42 Allen Brooklyn 27 3
24 Martin Spring 12 2
54 Alicia Castle 24 3
69 James Houston 24 3
8 rows selected.
병렬 질의란 하나의 SQL 문장을 여러 워킹 스레드를 사용하여 처리하는 것을 말한다. 대용량 테이블을 스캔할 때 여러 워킹 스레드가 테이블의 영역을 나눠서 처리하면 워킹 스레드 하나를 사용했을 때보다 빠르게 작업을 실행할 수 있다.
병렬 질의는 OLTP(Online transaction processing) 환경 보다는 주로 데이터 웨어하우스(Data warehouse)와 같은 대용량 데이터를 다루는 환경에서 주로 사용된다.
다음은 병렬 질의를 사용하는 예이다.
SELECT /*+ PARALLEL (4) */ DEPTNO, AVG(SAL) FROM EMP GROUP BY DEPTNO;
위의 예에서처럼 병렬 질의를 사용하기 위해서는 PARALLEL 힌트를 사용하면 된다. 'PARALLEL (4)'라고 명시한 부분의 숫자 4는 병렬 질의 처리에서 사용할 워킹 스레드의 개수를 나타내며 보통 DOP(Degree of parallelism)라고 한다. 즉 4개의 워킹 스레드를 사용해 해당 질의를 처리하도록 지시한다.
이와 같이 병렬 질의 실행이 지시되면 Tibero 서버는 유휴 상태의 워킹 스레드를 사용자가 지정한 DOP 개수만큼 확보하려 할 것이다.
현재 사용할 수 있는 워킹 스레드가 힌트에 지정된 개수보다 부족하다면 확보할 수 있는 워킹 스레드만을 사용해 병렬 질의를 실행한다. 만약 유휴 상태의 워킹 스레드가 없어서, DOP가 1이 되면 병렬 질의는 진행되지 않으며, 일반 질의처럼 처리된다. 이러한 상황을 별도의 에러 메시지를 통해 알려주지는 않는다.
Tibero가 병렬 질의로 실행할 수 있는 연산은 다음과 같다.
-
TABLE FULL SCAN
-
INDEX FAST FULL SCAN
-
HASH JOIN
-
NESTED LOOP JOIN
-
MERGE JOIN
-
SET 연산
-
GROUP BY
-
ORDER BY
-
집계 함수
Tibero는 병렬 질의를 실행하기 위해 실행 계획을 생성한다.
다음은 병렬 질의를 실행하기 위해 실행 계획을 생성한 예이다.
SQL> SET AUTOT TRACE EXPLAIN SQL> SELECT EMPNO, ENAME, SAL FROM EMP ORDER BY SAL; SQL ID: 451 Plan Hash Value: 2848347407 Explain Plan -------------------------------------------------------------------------------- 1 ORDER BY (SORT) 2 TABLE ACCESS (FULL): EMP SQL> SELECT /*+ PARALLEL (4) */ EMPNO, ENAME, SAL FROM EMP ORDER BY SAL; SQL ID: 449 Plan Hash Value: 979088785 Explain Plan -------------------------------------------------------------------------------- 1 PE MANAGER 2 PE SEND QC (ORDER) 3 ORDER BY (SORT) 4 PE RECV 5 PE SEND (RANGE) 6 PE BLOCK ITERATOR 7 TABLE ACCESS (FULL): EMP
위의 예를 보면, PARALLEL 힌트를 사용한 병렬 질의의 실행 계획에 기존에는 없던 새로운 연산 노드가 추가가 된 것을 확인 할 수 있다. 이때 새로 추가된 노드는 병렬 질의 실행에 필요한 작업을 하게 된다.
PE RECV, PE SEND 노드가 추가된 경우에는 Tibero는 병렬 질의를 실행하기 위해 2-set 모델을 사용한다. 이 경우 실제 사용하는 워킹 스레드의 개수는 DOP의 2배가 되며 2개의 set 중에서 한 곳의 워킹 스레드는 consumer의 역할을, 다른 set의 워킹 스레드는 producer의 역할을 하게 된다. 이렇게 2-set 모델을 사용하는 이유는 두 연산 노드를 동시에 병렬로 실행하여 파이프라이닝(Pipelining) 효과를 보기 위해서이다.
듀얼 테이블(DUAL Table)은 VARCHAR(1) 타입의 하나의 컬럼 더미(Dummy)와 문자열 'X'를 포함하는 하나의 로우를 포함하는 테이블이다.
듀얼 테이블의 특성은 다음과 같다.
-
SYS 사용자뿐만 아니라 모든 사용자가 듀얼 테이블을 사용할 수 있다.
-
삽입, 삭제, 갱신 연산이 허용되지 않으며, 테이블 자체를 변경하거나 제거할 수 없다.
-
테이블의 내용과 상관없는 연산식의 계산에 사용할 수 있다.
-
하나의 로우만을 포함하기 때문에 항상 연산식의 결과는 하나다.
다음은 듀얼 테이블을 사용하는 예이다.
SQL> SELECT SIN(3.141592654 / 2.0) FROM DUAL;
SIN(3.141592654/2.0)
--------------------
1
1 row selected.