Table of Contents
SQL statements that are bound in one database instance are committed or rolled back together. SQL statements that are processed in different networked database instances in a transaction should also have a method to be committed or rolled back all at once.
Transactions that relate to multiple nodes or different kinds of databases are called a distributed transactions. In Tibero, distributed transaction processing is supported through XA and database links (DBLink).
Tibero complies with the X/Open XA standard for Distributed Transaction Processing (DTP). XA uses a two-phase commit (2PC) to handle distributed transactions.
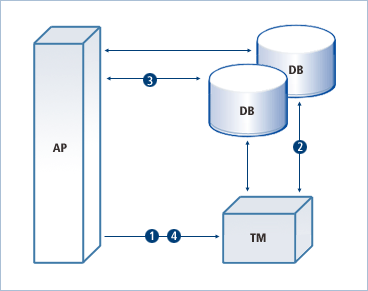
XA's operation is shown below:
-
Generally, XA is coordinated by a transaction manager (TM). First, an application informs the TM of a distributed transaction.
-
The TM receives a request from an application, finds out which DB nodes are participating in the transaction, and then informs the DB nodes that a distributed transaction will start.
When informing each database node of the start of the transaction, the TM creates a unique transaction ID (XID) and sends it to each DB. Then, each DB node starts processing distributed transactions with the XID.
-
The application sends SQL statements to each database in order to process necessary tasks.
DBs recognize the requests from the application as tasks related to the distributed transaction of the XID and execute the statements.
-
When all tasks have finished, the application informs the TM that the distributed transaction has ended.
The TM orders all database nodes that participated in the distributed transaction of the XID to commit or roll back at the same time. To avoid a situation where some databases are committed and others are rolled back, the TM uses a two-phase commit mechanism, whose explanation is explained below.
A two-phase commit mechanism is a protocol that guarantees successful modification of all databases in a distributed computing system. This mechanism enables all database nodes that participated in a distributed transaction to be committed or rolled back at the same time.
A two-phase commit mechanism is composed of two steps as follows:
-
First phase (or prepare phase)
The first phase is a preparation request step for the database node commit.
The process for the first phase is as follows:
-
The TM sends a 'prepare' message for the commit to each database node.
-
Each database which received this message prepares the commit.
The preparation tasks include locking the necessary resources and saving log files.
-
The databases inform the TM of the success of the commit preparation.
-
-
Second phase (or commit phase)
The TM waits until it receives messages from all database nodes that they have finished preparation.
Depending on which message is received, different steps are taken.
When the database receives the first prepare message of the two-phase commit mechanism, the database prepares for a commit by locking the resources of the relevant distributed transaction or saving logs. Sometimes, however, the database might not be able to receive the next commit or rollback message because of a network problem.
In this case, the database cannot decide whether the transaction is to be committed or rolled back. Therefore, the database should wait, with the prepared resource locked, until it receives the next message. This kind of transaction is called an in-doubt transaction.
Generally, when the network or TM problem is solved, the TM will send a commit or rollback message to the in-doubt transaction. However, if the resources locked by the in-doubt transaction needs to be unlocked quickly because the locks are delaying other operations, the DBA can manually commit or roll back the in-doubt transaction to unlock the resources.
This action is at the discretion of the DBA. If a later commit or rollback message from the TM differs from the DBA's decision, the entire distributed transaction may have a consistency problem as some transactions were committed while others were rolled back. Therefore, to maintain the consistency of a distributed transaction, it is best to wait for the next message from the TM.
If an in-doubt transaction must to be processed, solve the problem using the view DBA_2PC_PENDING.
DBA_2PC_PENDING is a view that shows the information of pending XA transaction branches.
Querying for XA transaction branches is shown below. In the example, the branch to be committed or rolled back with the XID and FAIL_TIME information is selected.
[Example 7.1] Looking up DBA_2PC_PENDING
SQL> SELECT LOCAL_TRAN_ID, XID, STATUS FROM DBA_2PC_PENDING;
LOCAL_TRAN_ID
-------------------------------------
XID
-------------------------------------
STATUS
---------------
2.16.18
1.1000.1000
PREPARED
1 selected.
The DBA can commit the desired XA transaction branch. Then, the resources that the branch had locked will be unlocked and the transaction will be committed.
SQL> commit force '2.16.18'; Commit succeeded.
The DBA can force a rollback with the following command:
SQL> rollback force '2.16.18'; Rollback succeeded.
Because the transaction was committed by the DBA instead of the TM, information about the corresponding XA transaction branch will remain.
The time when the commit was made by the DBA will be logged in FORCE_TIME as shown below:
SQL> SELECT LOCAL_TRAN_ID, XID, STATUS FROM DBA_2PC_PENDING;
LOCAL_TRAN_ID
-------------------------------------
XID
-------------------------------------
STATUS
---------------
1.1000.1000
FORCED_COMMIT
1 selected
Information about the XA transaction branch will be deleted when the TM judges that the information is no longer needed after using xa_forget.
The RM (Resource Manager) will not delete this information until it receives a request from the TM.
Database links provide a method to access data in a remote database as if it the data were in the local database. DBLinks enable not just easy access to and modification of remote database data but also easy processing of distributed transactions. Distributed transactions use a two-phase commit mechanism like XA in order to preserve the atomicity of transaction.
Creating and removing DBLinks is different depending on access privileges.
Public DBLinks
Public DBLinks can be used by the creator and other users.
To create a public DBLink, the user should have the privilege create public database link.
Creating a public DBLink is shown below:
create public database link public_tibero using 'remote_2';
In the example above, 'remote_2' in the using clause indicates the name of the database to connect to, which must be saved in the tbdsn.tbr file.
Removing a public DBLink is shown below. To remove a DBLink, the user should have the privilege drop public database link.
drop public database link public_tibero;
Private DBLinks
Only the user who created a private DBLink is allowed to use it.
To create a private DBLink, the user should have the privilege create database link.
Creating a private DBLink is shown below:
create database link remote_tibero using 'remote_1';
In the example above, 'remote_1' in the using clause creates a DBLink named 'remote_tibero'. Because the DBLink is a private DBLink, it can only be used by the user who created it.
Removing a private DBLink is shown below. Only the user who created the private DBLink can remove it.
drop database link remote_tibero;
There are two ways to specify the account for connecting to a remote database.
| Account | Description |
|---|---|
| Specified account | Access the remote database using a specified ID and password. An account with the specified ID and password must exist in the remote database. No matter which user uses the connection, the ID and password specified when creating the DBLink is used. |
| Current account | Access the remote database using the ID and password of the user that executed the current query. The same ID and password of the user that uses the DBLink must exist in the remote database. If no account is specified, the currently connected account is used by default. |
The account used to connect to the remote database should have the privilege to use CREATE SESSION. Because the local user can gain the authority of the account used to connect to the remote database through a DBLink, use caution when assigning privileges, especially to public DBLinks, because all local users have permissions in the remote database.
Creating a DBLink using a specified account is shown below:
create database link remote_tibero connect to user1
identified by 'password' using 'remote_1';
Creating a DBLink using the currently connected account is shown below:
create database link remote_tibero using 'remote_1';
When executing queries through a DBLink and the target of the DBLink is a DBMS other than Tibero, the DBLink can use a gateway for each DBMS.
Tibero server sends queries that target another DBMS to a gateway. The gateway connects to the remote DBMS, executes the queries received from the Tibero server, and sends the results to the Tibero server. To use the DBLink function of another DBMS, the DBMS's gateway binary and a configuration file are needed.
This section describes the types of gateways for each DBMS vendor and the cases of when the gateway and the Tibero are on the same machine and when they are not. Logging and the options provided by gateways are also described.
Gateways for Each DBMS Vendor
The following table shows the DBMS types and their gateway binary names which support DBLinks in Tibero .
| DBMS Vendor | Gateway Binary File | Programming Language | |
|---|---|---|---|
| Oracle | gw4orcl | C | Oracle 9i, 10g, 11g |
| DB2 | gw4db2 | C | DB2 V8, DB2 9, DB2 9.5 |
| MS-SQL SERVER | tbgateway.jar | Java | MS-SQL SERVER 2000, 2005, 2008 |
| Adaptive Server Enterprise(Sybase) | tbgateway.jar | Java | Sybase SQL Server 10.0.2 or later |
| GREENPLUM | tbgateway.jar | Java | GREENPLUM or PostgreSQL |
Because gateway binaries can be different for each DBMS version, using the appropriate gateway is recommended.
Note
DB2 gateway does not support the HP PA-RISC platform.
Create Gateway Processes
A general way to use a gateway. This method cannot be used in the Windows environment.
The gateway needs a DBMS-provided library. If the library can be used in the location where the Tibero server is installed, it is possible to execute the DBLink function on the same machine with the Tibero server by creating a gateway process. The created gateway process is terminated when the session that uses the DBLink is closed.
Specifying the tbdsn.tbr file to use a DBLink that connects to an Oracle server is shown below:
<tbdsn.tbr>
ora_dblink=(
(GATEWAY=(PROGRAM=gw4orcl)
(TARGET=orcl)
(TX_MODE=GLOBAL))
)
Specifying the tbdsn.tbr file to use a DBLink that connects to a DB2 server is shown below:
<tbdsn.tbr>
db2_dblink=(
(GATEWAY=(PROGRAM=gw4db2)
(TARGET=sample)
(TX_MODE=GLOBAL))
)
| Item | Description |
|---|---|
| PROGRAM | Absolute path to a gateway binary file. If the gateway binary file is in the $TB_HOME/client/bin directory, only the file name is needed. |
| TARGET | Contains different information depending on the DBMS.
|
| TX_MODE | Either a global transaction or a local transaction. Global transactions are handled with two-phase commit, and local transactions are not handled with two-phase commit. Options are:
|
| CONFIG | Absolute path to a gateway configuration file. |
Multithreaded Server Method
A user can start a gateway located on the same machine as Tibero server or on a remote machine with the multithreaded server method. Tibero server sessions communicate with the gateway via TCP/IP and connection information from the tbdsn.tbr file. When the gateway receives a request from a Tibero session, one of the working threads handles the request. In particular, the gateway that uses the Java programming language only supports the multithreaded server method.
The following example specifies the tbdsn.tbr file should to use DBLink to connect to an ORACLE server.
<tbdsn.tbr>
ora_link_remote=(
(GATEWAY=(LISTENER=(HOST=12.34.56.78)
(PORT=9999))
(TARGET=orcl)
(TX_MODE=GLOBAL))
)
The following example specifies the tbdsn.tbr file to use DBLink to connect to DB2 server.
<tbdsn.tbr>
db2_link_remote=(
(GATEWAY=(LISTENER=(HOST=12.34.56.78)
(PORT=9999))
(TARGET=sample)
(TX_MODE=GLOBAL))
)
The following example specifies the tbdsn.tbr file to use DBLink to connect to MS-SQL SERVER.
<tbdsn.tbr>
mssql_link_remote=(
(GATEWAY=(LISTENER=(HOST=12.34.56.78)
(PORT=9093))
(TARGET=12.34.56.87:1433:master)
(TX_MODE=LOCAL))
)
The following example specifies the tbdsn.tbr file to use DBLink to connect to Sybase ASE.
<tbdsn.tbr>
ase_link_remote=(
(GATEWAY=(LISTENER=(HOST=12.34.56.78)
(PORT=9093))
(TARGET=12.34.56.87:5000:master)
(TX_MODE=LOCAL))
)
The following example specifies the tbdsn.tbr file to use DBLink to connect to GREENPLUM.
<tbdsn.tbr>
gp_link_remote=(
(GATEWAY=(LISTENER=(HOST=12.34.56.78)
(PORT=9093))
(TARGET=12.34.56.87:5432:mydb)
(TX_MODE=LOCAL))
)
| Term | Description |
|---|---|
| LISTENER |
|
| TARGET | Contains different information for each DBMS as follows:
|
| TX_MODE | A global transaction or a local transaction. The values of TX_MODE are:
|
| BYTES_CHARSET | Ignores the ENCODING gateway initialization parameter and uses another character set for encoding. Only character sets supported by Tibero server can be used. |
If the character set of the TARGET server is EUCKR and the character set of the Tibero server is ASCII, characters excluded from the ASCII character set are displayed as '?' when executing a SELECT statement. However, if BYTES_CHARSET=EUCKR is set, characters are processed as EUCKR characters regardless of the gateway ENCODING or the Tibero server character set. Therefore, normal EUCKR characters are displayed when performing a SELECT statement.
To use a remote gateway, first start the gateway.
The following is the command used for starting an Oracle server gateway remotely.
$ gw4orcl
The following is the command used for starting an MS-SQL server gateway remotely.
$ tbgw
Gateway Related Directory Structure (ORACLE, DB2)
Gateways read configuration files and write log files using the environment variable TBGW_HOME.
If the TBGW_HOME variable is not specified, the default value is ${TB_HOME}/client/gateway. In Windows, the default value is %TB_HOME%\client\gateway.
The directory structure for configuration files and log files used by gateways is as follows:
$TBGW_HOME |--- DBMS Vendor Name |--- config | |--- tbgw.cfg |--- log |--- Gateway Log File
In the directory structure above, the root $TBGW_HOME is different depending on the system environment.
- DBMS vendor name/config
-
Contains a gateway configuration file named tbgw.cfg. If a user wants to change gateway-related settings, change values in this file.
- DBMS vendor name/log
-
Contains a gateway-related log file, which is created based on the corresponding DBMS vendor name.
-
The following table shows the logs files of each DBMS vendor.
DBMS Vendor Log File Name Log Name of the Listener Oraclegw4orcl.log gw4orcl_lsnr.log DB2gw4db2.log gw4db2_lsnr.log
Gateway Configuration (ORACLE, DB2)
Gateway-related settings can be changed by modifying values of initialization parameters in the tbgw.cfg file.
Modifying values of initialization parameters is shown below:
<tbgw.cfg>
LOG_DIR=${TBGW_HOME}/{DBMS vnedor name}/log
LOG_LVL=2
LISTENER_PORT=9999
MAX_LOG_SIZE=20k
FETCH_SIZE=32k
| Initialization Parameter | Description |
|---|---|
CHARACTER_SET | Character sets of the gateway. If unspecified, the value defined in the TB_NLS_LANG variable is used. (Default value: MSWIN949) |
FETCH_SIZE | Amount of data retrieved at one time when processing queries in the database. (Default value: 32 KB, maximum value: 64 KB) |
IGNORE_WARNING | Option to ignore a warning message that occurs in a remote database. (Default value: N) |
LOG_DIR | Path for gateway log files. ${TBGW_HOME}/{DBMS vendor name}/log |
LOG_LVL | Log level to be saved in the log file. (Default value: 2) |
MAX_LOG_BACKUP_SIZE | Total aggregate size of backup log files when the log file backup function is used. (Default value: 0, unit: bytes)
|
MAX_LOG_SIZE | Maximum size of a log file. (Default value: 0, unit: bytes)
|
QUERY_WITH_UR | Applies only to the gateway for DB2. Option to add the WITH UR syntax to the query. (Default value: N) |
SKIP_CHAR_CONV | Applies only to the gateway for Oracle. (Default value: N)
|
The following table shows the options for using the gateway in listener mode.
| Option | Description |
|---|---|
LISTENER_PORT | Listener port number. (Default value: 9999) Specified port is opened. The (specified listener port + 1) port is opened for processing Statement Cancel. |
MIN_POOL_SIZE | Minimum number of sessions that can be concurrently connected to the database. (Default value: 10) |
MAX_POOL_SIZE | Maximum number of sessions that can be concurrently connected to the database. (Default value: 100, maximum value: 128) |
Gateway Related Structure (MS-SQL SERVER, Sybase ASE, GREENPLUM)
A user must copy the tbJavaGW.zip file in ${TB_HOME}/client/bin and decompress it. Since JDBC driver files (Sybase: jconn3.jar, MS-SQL: sqljdbc.jar, GREENPLUM: postgresql-8.4-701.jdbc3.jar) are not provided by default, the user must obtain the JDBC driver and copy it to the LIB directory. The JDBC driver can generally be downloaded from the DBMS vendor web site.
The following is the directory structure of the Java gate configuration and log files.
Installation Directory
|--- tbJavaGW
|--- tbgw
|--- jgw.cfg
|--- jgwlog.properties
|--- jgw_service.bat
|--- prunsrv.exe
|--- lib
| |--- tbgateway.jar
|--- commons-collections.jar
|--- commons-daemon-1.0.6.jar
|--- commons-pool.jar
|--- log4j-1.2.15.jar
|--- jconn3.jar
|--- sqljdbc.jar
|--- postgresql-8.4-701.jdbc3.jar
|--- log
| --- A gateway's log files
- tbJavaGW/tbgw
-
A script file for implementing a Java gateway.
- tbJavaGW/jgw.cfg
-
A gateway configuration file. A user needs to create this file to change settings related to a gateway and save the file in the appropriate folder.
- tbJavaGW/jgwlog.properties
-
A configuration file for logs. The size of a log file and a log level can be set. For the detailed format, see LOG4J.
- tbJavaGW/jgw_service.bat
-
A gateway can be registered as a Windows service. This is an executable file for registering/deleting a gateway as a Windows service. tbJavaGW/prunsrv.exe is required to execute this file.
- tbJavaGW/prunsrv.exe
-
An executable file for registering/deleting a gateway as a Windows service. This is required to execute the tbJavaGW/jgw_service.bat file.
This file is not provided by default and can be downloaded from the Apache Commons Daemon download page.
- tbJavaGW/lib
-
Contains a JAR file used by a Java gateway. The JDBC driver for a database is in this directory.
- tbJavaGW/log
-
Contains log files related to a gateway.
Gateway Configuration (MS-SQL SERVER, Sybase ASE, GREENPLUM)
Settings related to a gateway can be modified by specifying values for initialization parameters in jgw.cfg.
Specifying a gateway is shown below:
<jgw.cfg>
DATABASE=SQL_SERVER LISTENER_PORT=9093 INIT_POOL_SIZE=10 MAX_POOL_SIZE=1000 ENCODING=MSWIN949 MAX_LONGVARCHAR=4K MAX_LONGRAW=4K
| Initialization Parameter | Description |
|---|---|
DATABASE | Target database.
|
LISTENER_PORT | Listener's port number. Use this for general requests and use LISTENER_PORT+1 for control requests such as Statement cancel. (Default value: 9093) |
INIT_POOL_SIZE | Number of working threads created when a gateway starts. (Default value: 10) |
MAX_POOL_SIZE | Maximum number of working threads that can be created by a gateway.(Default value: 100) |
MAX_CURSOR_CACHE_SIZE | Maximum number of cursors that can be cached for each working thread. (Default value: 100) |
ENCODING | Encoding used to send strings to Tibero server's sessions. This must be identical to the character set of the Tibero server. One of the following can be specified: (Default value: MSWIN949)
|
MAX_LONGVARCHAR | Gateways do not support getting LONG and CLOB type data at intervals (deferred type), and instead read data all at once, like CHAR and VARCHAR data. This parameter specifies the maximum size of the data to be read. (Default value: 4 KB, maximum value: 32 KB) |
MAX_LONGRAW | Gateways do not support getting LONG RAW and BLOB type data at intervals (deferred type), and instead read data all at once, like RAW data. This parameter specifies the maximum size of the data to be read. The maximum 32 kilobytes. (Default value: 4 KB, maximum value: 32 KB) |
VALIDATION_QUERY | SQL to check for the validity of a connection to the target database from the gateway. If set, connection check is performed in the following cases:
|
VALIDATION_IDLE_TIME | Wait time before executing connection check after processing the last request. Unit is in milliseconds, and 0 indicates infinity. (Default value: 0, Min value: 60000) VALIDATION_QUERY item must be configured to use this setting. |
Java Binary Versions
The following command checks the gateway binary version.
$ gw4orcl -v tbGateway for oracle : Release 4 Trunk (Build 31190) Linux Tibero_Linux 2.6.22-16-generic #1 SMP Mon Nov 24 17:50:35 GMT 2008 x86_64 GNU/Linux version (little-endian)
The following database objects can be accessed through DBLink.
-
Tables (LOB columns cannot be accessed.)
-
Views
-
Sequences
To access LONG columns in Oracle tables through DBLink, they must be the last column. SQL statements that can use DBLink are SELECT, INSERT, UPDATE, and DELETE. However, SELECT statements cannot use the FOR UPDATE clause.
Global Consistency is guaranteed for distributed transactions which consist of homogeneous DBLinks. To provide global consistency, users need to synchronize the TSNs of databases that participate in the distributed transaction.
TSN synchronization is processed when messages are exchanged between databases. When committed, the commit TSN of all nodes must be synchronized.
Processing a transaction in the pending state is similar to that of XA.
This section describes the differences between DBLink and XA in terms of the two-phase commit mechanism.
Commit Point Sites
For distributed transactions that use DBLink, select a 'commit point site' among the nodes that are participating in the transaction.
The commit point site is selected when the two-phase commit
starts. Follow up the session tree and select the node that has the
largest commit point strength. Each database has a commit point
strength, and this value can be specified with the initialization
parameter COMMIT_POINT_STRENGTH.
The commit point site is not prepared in the two-phase commit's prepare phase. Instead, the commit point site is committed after all nodes are prepared. Afterward, all other nodes will process the commit phase.
DBLink uses this kind of modified two-phase commit because it needs to decrease the overhead that occurs when preserving global consistency. In order to preserve global consistency in DBLink, the commit TSN of all nodes should be the same. Select the largest TSN among the nodes that finished the prepare phase and then commit using the TSN from the commit phase.
The commit TSN is unknown before the commit phase. Therefore, if other transactions should be allowed to see the information that was modified in the transaction cannot be determined. If a transaction tries to access information that was modified by a prepared transaction, the following error will occur:
TBR-21019: lock held by in-doubt distributed transaction.
If the prepared state is changed to the pending state when using DBLink, it is impossible to access the relevant data, which causes a problem for the in-doubt transaction.
To reduce this kind of problem, one of the participating nodes in the transactions is set to skip the prepare phase. This allows the commit point site to access the data even if the transaction enters an in-doubt state. Therefore, when choosing the commit point strength for the database, make sure to assign a larger value if the database requires more data accessibility.
Tibero provides the static views below to support viewing DBLink data:
Note
For more details on static views, refer to Tibero Reference Guide.
V$DBLINK
The dynamic view V$DBLINK shows information about database links that are connected to a remote database in the current session.
If a user makes a query through a DBLink, a connection to the remote database is made and it remains even after the query or transaction finishes. This reduces the connection overhead needed to use the same DBLink later. The created connection remains until the session is terminated or until the connection is explicitly ended.
Querying connection data using V$DBLINK after executing a SELECT statement through a DBLink named remote_tibero is shown below:
SQL> select * from employee@remote_tibero; ID NAME --- --------- 1 KIM 2 LEE 3 HONG 3 rows selected. SQL> select * from V$DBLINK; DB_LINK OWNER_ID OPEN_CURSORS IN_TRANSACTION HETEROGENEOUS ------------- ---------- ------------ -------------- ------------- REMOTE_TIBERO 15 0 YES NO COMMIT_POINT_STRENGTH --------------------- 1 1 row selected.
The owner ID of remote_tibero is 15, there is no open cursor, and a transaction is active. It exists on the Tibero server, and the commit point strength of the remote database is 1.
Terminating a DBLink is shown below:
SQL> alter session close database link remote_tibero; TBR-12056: database link is in use. ... (1) ... SQL> commit; ... (2) ... Commit succeeded. SQL> alter session close database link remote_tibero; ... (3) ... Session altered. SQL> select * from V$DBLINK; ... (4) ... DB_LINK OWNER_ID OPEN_CURSORS IN_TRANSACTION HETEROGENEOUS -------------- ---------- ------------ -------------- ------------- COMMIT_POINT_STRENGTH --------------------- 0 row selected.
(1) The attempt to close the DBLink did not succeed because a transaction that uses the DBLink is currently active.
(2) Complete the transaction using the commit command.
(3) Try to close the DBLink again.
(4) The DBLink is terminated normally and no data is in the V$DBLINK view.