Table of Contents
This chapter describes parallel execution's basic concepts, operation principles, and execution methods.
Parallel execution (hereafter PE) divides a single task into several tasks and then executes the tasks at the same time. This can dramatically reduce the response time in a large capacity database that supports data warehousing (DW) and business information (BI). The performance of handling a batch in an online transaction processing (OLTP) system can also be improved.
Because PE improves database performance by maximizing system resource usage, performance improvements can be expected for the following tasks:
-
Partitioned index scans of large capacity tables
-
Queries such as joins for large capacity tables
-
Creating indexes for large capacity tables
-
Bulk inserts, updates, and deletions
-
Aggregations
Note that if PE is used inappropriately, important data handling can be delayed, or performance can be reduced due to resource depletion.
Performance can be improved with PE in the following kind of environment:
-
System-side parallel organization such as CPU and clustering
-
Sufficient input/output bandwidth
-
Low CPU usage (for example, when CPU usage is less than 30%)
-
Sufficient memory for input/output buffers and to execute sorting and hashing
The degree of parallelism (hereafter DOP) is used to determine how many system resources should be allocated to a single operation when handling it in parallel. It indicates the number of working threads (hereafter WTHR) that perform a single operation together.
Note
An operation is a task unit that is allocated to the WTHR in a single query such as order by or full table scan.
There are two types of PE: intra-operation PE, which simultaneously performs a single operation with several WTHR and inter-operation PE, which simultaneously performs several operations by connecting them with the pipe stream method.
Tibero performs intra-operation PE by allocating as many WTHRs as the DOP and performs inter-operation PE by organizing two sets of intra-operation PEs.
Query Coordinator (hereafter QC), which controls the PE process, uses as many as 2 X DOP WTHR for PE_SLAVE (Parallel Execution Slave). However, it does not support inter-operation PE where more than one operation is simultaneously performed.
A single DOP is used to perform PE in a single SQL statement. If there are multiple parallel hints in a query, or a parallel hint and a table that includes the parallel option exist in the query, the largest DOP is used for the query.
If the DOP is less than or equal to 0, 4 is used by default. The DOP can be specified in a parallel hint. For more information about using DOP, refer to Tibero SQL Reference Guide.
To determine the DOP, consider the following:
-
The number of CPUs in a system
-
The maximum number of processes and threads in a system
-
Table distribution, the number of disks that the table exists on
-
Data location and query type
-
The number of object partitions
If only one user uses PE, the DOP should use a range of values from 1 to 2 times the number of CPUs for CPU bound operations such as sorting. For I/O bound jobs such as table scanning, the DOP should use a range of values from 1 - 2 times the number of disks. Performance is improved when considering the query type and system environment for PE.
When a parallel operation is performed during query execution in Tibero, QC requests as many WTHRs as the calculated DOP and receives the available WTHRs as PE_SLAVEs.
QC receives as many WTHRs as the value of DOP and organizes the PE_SLAVE set as in the following example. For other queries, QC receives an amount of WTHRs equal to two times the value of DOP and creates two PE_SLAVE sets. If there are insufficient WTHRs to perform the query with the DOP specified by a user, the DOP is redefined with the available WTHRs.
SELECT * FROM table1;
For example, if DOP is determined to be 4 and is specified in a hint, 2* DOP WTHRs are necessary. If there are only 5 WTHRs, PE is performed after redefining DOP to 2 and receiving 4 WTHRs. If only one WTHR is available, jobs are performed sequentially even though the plan was parallel.
PE_SLAVEs are returned as available WTHRs after the query is performed. The resources are available for the next query.
If a query that includes a table that has a parallel hint or parallel option is performed in Tibero, a parallel plan is made.
A parallel plan is executed with the following procedure:
-
The WTHR that executes the SQL acts as the QC.
-
If there is a parallel operator, the QC receives as many WTHRs as are needed according to the DOP using PE_SLAVE.
-
If there are insufficient WTHRs to use PE, the user is notified and the query is performed sequentially.
-
The QC controls PE_SLAVE to perform operations based on a 2-set structure in sequence.
-
After a query is performed, the QC sends the query result collected from PE_SLAVE to the user and returns PE_SLAVE as available WTHRs.
An execution plan made by QC is shared with all PE_SLAVEs in PE. The QC controls PE_SLAVEs with messages so that each PE_SLAVE executes a particular part of the execution plan.
PE supports intra-parallelism, which performs an execution plan by dividing it into as many PE_SLAVEs as the value of DOP. The set of PE_SLAVEs that perform an operation is called a PE_SLAVE set.
PE supports a maximum of 2 PE_SLAVE sets for inter-parallelism that simultaneously performs two operations from the execution plan.
A PE_SLAVE set that performs simultaneously is divided into a producer set and a consumer set.
The following figure explains the 2-set structure of producer sets and consumer sets:
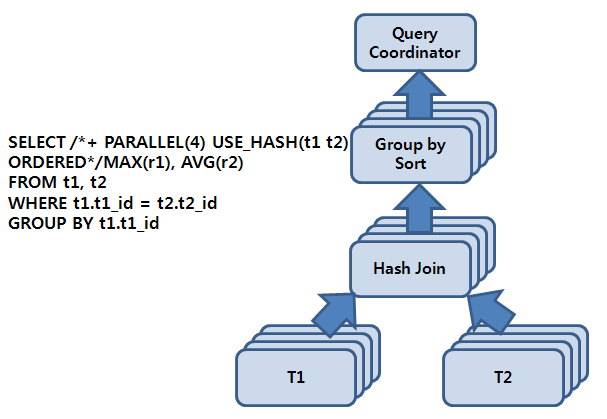
In the query in [Figure 13.1], the PE execution plan uses the parallel hint for the DOP, and each operation is divided into 4 (the determined value for DOP) task units. One PE_SLAVE set is organized with 4 PE_SLAVEs because PE uses 4 threads, and a total of 8 (= 2 x 4) PE_SLAVEs are allocated to form the 2-set structure of the producer set and the consumer set.
If the allocated PE_SLAVE sets are called set1 and set2, each set is converted to a producer set (Tibero Producer Set, hereafter TPS) and consumer set (Tibero Consumer Set, hereafter TCS) according to its role, and then the execution plan is performed. TCS waits for TPS to scan table T1 and provide a row so that it can perform a hash join, and TPS starts table scanning. Afterward, the PE execution plan is performed.
As a TPS, set1 scans T1. As a TCS, set2 organizes a hash table for a row from set1. After set1 completes scanning T1, it scans T2 and gives a row to set2 at the same time. After set1 completes scanning T2, it is converted to a TCS and then performs sort group by. set2 is converted to a TPS and then gives the result of the hash join to set1. Finally, set1 is converted to a TPS and sends the result of sort group by to QC.
This demonstrates the basic operation principles that intra-operation parallelism and intra-operation parallelism are simultaneously performed with the 2-set structure.
A TPS enables a TCS to handle the next operation by providing the result of an operation to the TCS. Tibero provides the following 5 methods to help a TPS distribute results: hash, range, broadcast, round-robin, and send idxm. Hash, range, and broadcast are the most common methods.
| Distribution Method | Description |
|---|---|
| hash | Used when a TCS assumes control of hash-based operations such as hash join and hash group by. The consumer thread that receives a corresponding row is based on the hash value of the send key. |
| range | Used when TCS assumes control of sort-based operations such as order by and sort group by. The consumer thread that receives a corresponding row is determined according to the range of the send key. |
| broadcast | Used when TCS assumes control of a join that forces a broadcast using a nested loop join or pq_distribute hint. For more information, refer to “13.4.1. Parallel Queries”. The row is sent to all consumer threads. |
| round-robin | Used when the consumer that sends a row is executed with the round-robin method. |
| send idxm | Used when Parallel DML sends a row for indexes and reference constraints. |
This section explains the range method with an example and the figure [Figure 13.2].
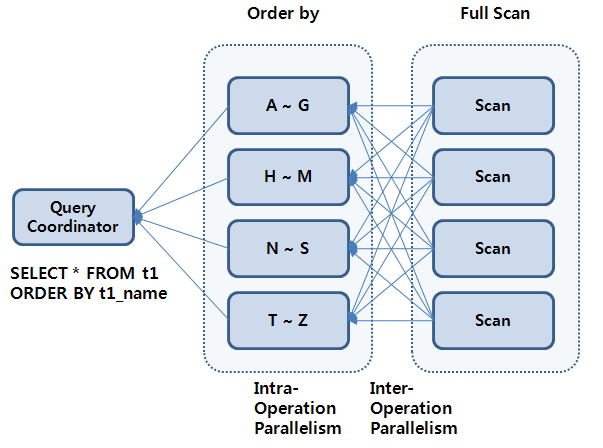
If two sets of TPS and TCS work together using inter-operation parallelism in the PE execution plan where the determined DOP is 4, a total of 8 PE_SLAVEs participate in the PE.
One PE_SLAVE set becomes a TPS and scans the table. The other set, specified as a TCS, performs order by on a row. Four PE_SLAVEs decide the range for the sort key as A - G, H - M, N - S, and T - Z and sort each range. To accomplish this, the TPS transfers each row to the corresponding PE_SLAVE with the range method.
After a TCS completes sorting, it changes to a TPS and sends the sort result to QC in the range order set by the PE_SLAVE. The final process result is created in this way.
Tibero provides the following parallel operations:
-
Access methods
Table scans and index fast full scans
-
Join methods
Nested loops, sort merges, and hash joins
-
DDL
CREATE TABLE AS SELECT, CREATE INDEX, REBUILD INDEX, and REBUILD INDEX PARTITION
-
DML
INSERT AS SELECT, UPDATE, DELETE
-
Other operations
GROUP BY, ORDER BY, SELECT DISTINCT, UNION, UNION ALL, and aggregations
If a parallel hint is used or a query is performed for a table that has a parallel option, a parallel plan is made in Tibero. PE is only performed according to the parallel plan if there are enough WTHRs,
SQL> select /*+ parallel (3) */ * from t1; SQL> create table t1 (a number, b number) parallel 3; SQL> select * from t1;
Autotrace (explain plan)
A parallel plan can be viewed using autotrace (explain plan) in Parallel Query.
SQL> set autot on
select * from t1;
Explain Plan
--------------------------------------------------------------------------------
1 PE MANAGER
2 PE SEND QC (RANDOM)
3 PE BLOCK ITERATOR
4 TABLE ACCESS (FULL): T1
In the execution plan above, the gap between PE SEND and PE RECV (or leaf node) can be seen as a PE_SLAVE. PE SEND at the top of the PE_SLAVE distributes rows to a TCS if it is a TPS.
| Item | Description |
|---|---|
| PES (Parallel Execution Set) | The unit used to perform one PE_SLAVE set in a parallel plan.. |
| producer slave | Producer set's PE_SLAVE |
| consumer slave | Consumer set's PE_SLAVE |
There is a table scan (or index fast full scan) operation that creates a row or PE RECV at the bottom of the PE_SLAVE. PE RECV receives rows distributed by TPS when a PE_SLAVE is a TCS.
The following is an example:
SQL> select /*+ parallel (3) use_hash(t2) ordered */ * from t1, t2 where t1.a=t2.c; Explain Plan -------------------------------------------------------------------------------- 1 PE MANAGER 2 PE SEND QC (RANDOM) 3 HASH JOIN (BUFFERED 4 PE RECV 5 PE SEND (HASH) 6 PE BLOCK ITERATOR 7 TABLE ACCESS (FULL): T1 8 PE RECV 9 PE SEND (HASH) 10 PE BLOCK ITERATOR 11 TABLE ACCESS (FULL): T2
| Item | Description |
|---|---|
| PE MANAGER | Operation that starts PE and coordinates the PE_SLAVE set. This is the division between serial execution and parallel execution. Starting with the next operation, operations are performed in parallel. |
| PE SEND | Operation in which the producer slave distributes rows. The distribution methods among PE_SLAVEs are as follows: hash, range, broadcast, round-robin, and send idxm. For more information, refer to “13.3.2. Distributing a TPS”. The following methods can be used to send rows from PE_SLAVE to QC: |
| PE RECV | Operation that receives rows that were distributed by a producer slave in a consumer slave through PE SEND |
| PE BLOCK ITERATOR | Operation that requests and receives a granule, which is used for table scans and index scans. A granule is the unit size of a task allocated to PE_SLAVE when PE is performed. The size influences the performance of PE. |
| PE IDXM | Operation to manage index and reference constraints in Parallel DML. |
Nested Loops
Making a parallel plan for a nested loop is different from plans for other joins because a nested loop repeatedly performs a join on a right-side child. To decrease the load while joins are being performed, this method combines the PES of the right-side child and the PES for the nested loop join. The left-side child uses the broadcast method as part of the parallel plan.
SQL> SELECT /*+parallel(3) use_nl(t1 t2) ordered*/ *
FROM t1, t2
WHERE a < c;
Explain Plan
--------------------------------------------------------------------------------
1 PE MANAGER
2 PE SEND QC (RANDOM)
3 NESTED LOOPS
4 BUFF
5 PE RECV
6 PE SEND (BROADCAST)
7 PE BLOCK ITERATOR
8 TABLE ACCESS (FULL): T1
9 PE BLOCK ITERATOR
10 TABLE ACCESS (FULL): T2
In general, a parallel plan is made by including the slave that joins the child on the right side. However, PE performance can be improved by selecting which side of a child should be joined using the pq_distribute hint.
SQL> SELECT /*+parallel(3) pq_distribute(t2 broadcast none) use_nl(t2) ordered*/ *
FROM t1, t2
WHERE a=c;
Explain Plan
--------------------------------------------------------------------------------
1 PE MANAGER
2 PE SEND QC (RANDOM)
3 NESTED LOOPS
4 BUFF
5 PE RECV
6 PE SEND (BROADCAST)
7 PE BLOCK ITERATOR
8 TABLE ACCESS (FULL): T1
9 PE BLOCK ITERATOR
10 TABLE ACCESS (FULL): T2
SQL> SELECT /*+parallel(3) pq_distribute (t2 none broadcast) use_nl(t2) ordered*/ *
FROM t1, t2
WHERE a=c;
Explain Plan
--------------------------------------------------------------------------------
1 PE MANAGER
2 PE SEND QC (RANDOM)
3 NESTED LOOPS
4 PE BLOCK ITERATOR
5 TABLE ACCESS (FULL): T1
6 TABLE ACCESS (FULL): T2
Constraints
The following operations are not performed in parallel:
-
Operations that create a rownum
-
group by clauses that include cube or rollup
-
Operations that include an analysis function
-
top-N order by clauses
The following is an example:
SQL> SELECT * FROM (select * from t1 order by t1.a) WHERE rownum < 5; -
Table scans on a temporary table
-
Scans on a dynamic performance view
-
Scans on an external table
-
Operations that use DBLink:
-
index range scans, index full scans, index skip scans, and index unique scans
-
connect by statements
-
Tibero can perform "create table ... as select," "create index," and "rebuild index" in parallel.
"create table ... as select" can be used to create a summary table in a decision support application. If the insert part and parallel part are handled in parallel, DDL can be executed more quickly.
Parallel DDL can be used by specifying the parallel option in a DDL statement. For more information about syntax related to DDL, refer to Tibero SQL Reference Guide.
Tibero supports parallel DML for the insert, update, and delete statement, but not for the "insert into ... values ..." statement.
Parallel DML can be effectively used for batch jobs that need to insert, update, or delete a large volume of data. It is not useful for tasks with only a few transactions.
Enable Parallel DML
DML can be performed in parallel when Parallel DML is enabled via 'alter session enable parallel dml' and a hint is used after an insert, update, or delete statement. If parallel DML is not enabled, it is not performed in parallel even if a hint is specified in a DML statement. If parallel DML is disabled, parallel DML is not processed.
Parallel DML can perform DOP + 1 transactions, and commit is executed with two-phase commit. Rollback is performed in parallel because DML is organized with several transactions.
Because parallel DML is processed with several transactions, the corresponding table cannot be viewed from the same session with the select statement before commit. A table modified with Parallel DML can be viewed after commit.
SQL> alter session enable parallel dml; SQL> insert /*+ parallel (3) */ into PE_test3 select * from PE_test3; 10001 rows created. SQL> select * from PE_test3; TBR-12066: Unable to read or modify an object after modifying it with PDML. SQL> insert /*+ parallel (3) */ into PE_test3 select * from PE_test3; TBR-12067: Unable to modify an object with PDML after modifying it.
Insert
DML can be performed more quickly by performing both insert and select statement that extract the rows to insert in parallel by using a parallel hint in the select subquery.
SQL> insert /*+ parallel (3) */ into PE_test3
select /*+ parallel (3) */ * from PE_test3;
10001 rows created.
Constraints
The following cannot be performed with parallel DML:
-
"insert into ... values ..." statements
-
DML with a return clause
-
Merge statements
-
If a table is modified with parallel DML, it cannot be accessed from the same session with DML or queries until the changes is committed.
-
DML for a table that has a trigger
-
DML for a table that has a LOB type column
-
DML that has a self reference or delete cascade constraints
-
DML for a table that has an index that is being online rebuilt
-
If there is a Standby server
The views for parallel execution provided by Tibero are shown below.
| View | Description |
|---|---|
| V$PE_SESSION | Query session server data. It displays information about sessions that execute in parallel in real time and displays the requested DOP and the actual DOP allowed for the operation. For additional information query the SID in V$SESSION. |
| V$PE_TQSTAT | Traffic data during parallel execution at the table queue level. Table queue is a pipeline between query servers or between a query server and a coordinator. This view shows the amount and the size of data sent to the consumer from each producer in order to confirm even distribution of loads. This view has a value when parallel execution is performed in the session, and it contains information about the last parallel execution of the session. |
| V$PE_PESSTAT | Time consumed by each step during parallel execution. A step is when a consumer becomes a new producer or a producer has sent data to a coordinator after the data transmission from a producer to consumer is complete. Checking the operation performed by each producer or consumer through this view is difficult. Instead, using the V$PE_PESPLAN view is recommended. Like the V$PE_TQSTAT view, both V$PE_PESSTAT and V$PE_PESPLAN contain information about the last parallel execution of the session. If the session has not performed any parallel executions, no data will exist. |
| V$PE_PESPLAN | Last parallel execution plan performed by the session and its execution time. It displays which executions were performed in parallel; how long it took to send data to the consumer; and the sample collection time when the producer sent data using the range method. |