Table of Contents
This chapter introduces the basic concepts, components, and program structure of tbCLI.
tbCLI is a Call Level Interface(CLI) provided by Tibero and works as an SQL interface between user application programs and Tibero. Users can use the tbCLI library to create a C or C++ application program which accesses Tibero.
tbCLI is developed based on ODBC (Open Database Connectivity) and X/Open Call Level Interface Standard. tbCLI satisfies all conditions of Level 2 of ODBC and most of conditions of Level 2 of ODBC 3.0. Therefore, the existing application programs written with ODBC or CLI can be easily migrated to the tbCLI environment.
tbCLI is especially useful in a client/server environment, as the following shows.
If a client application program calls a tbCLI API, the database system processes it and returns the result to the client. Interfaces like tbESQL can be used to process data, but through tbCLI, application programs and data can be manipulated in a more sophisticated way.
The tbCLI has the following features:
-
Precompiler is not required to create an executable file.
Like tbESQL, tbCLI combines advantages of general program languages and SQL statements. The tbCLI is closer to general programs than tbESQL.
-
Through tbCLI, modules can be managed efficiently, and readability is enhanced.
-
No need to bind an application package.
-
Statistics of the database can be used.
-
The tbCLI ensures stability of threads to enable multi-threaded application programs to be developed.
This section describes the basic components a user is required to know before creating or executing the tbCLI program.
Handle is a pointer for one of some major data structures managed by tbCLI. By using a handle, tbCLI can manage complicated data more easily.
The Internal data of a handle is automatically updated when a change occurs to the data structure. Therefore, an application program developer needs neither to know the details of the data structure, nor to access the internal data directly.
tbCLI uses four handles as follows.
-
Includes data about tbCLI program environment.
Includes data such as; the current environment state, a list of connection handles allocated to the environment, and error information for the environment.
-
Includes data about connections with data source.
Includes data such as; the current connection state, a list of statement handles allocated to the connection, and error information for the connection.
-
Includes data about an SQL statement that will be executed from the tbCLI program.
Includes data such as; the current statement state, a list of input parameters and output columns within the statement, and error information for the statement.
-
Includes data about each column or bound parameters of the result set related to a statement handle. Includes data such as; input parameters of an SQL statement and metadata for output columns.
In order to execute a database job from a tbCLI program, use the tbCLI functions. Most of tbCLI functions receive the target handle as an input parameter and have an SQLRETURN type return code.
The following is a prototype of the
SQLExecDirect function among tbCLI functions. The function can execute an
SQL statement directly.
SQLRETURN SQLExecDirect(SQLHSTMT StatementHandle, SQLCHAR *SQLString,
SQLINTEGER SQLStringSize);
tbCLI functions are provided by being divided into several groups by functions. For example, there are functions related to handle allocation and connection, functions related to SQL statement execution, functions related to SQL query results and research, functions related to descriptors, functions related to error information, and functions related to data source information.
Note
Refer to the “Chapter 3. tbCLI Functions” function for more information about tbCLI functions.
The tbCLI program gets the execution result by the code returned after executing a tbCLI function, but the user may require more information. In order to offer such information, tbCLI creates a diagnostic record.
Diagnostic record has not only the return code of the executed function but also a variety of information about the execution result.
Diagnostic record consists of two records as follows.
-
Consists of return code, row count, status record count, and executed command type.
Except in the case where the return code is SQL_INVALID_HANDLE, if a tbCLI function is executed, the header record is always created.
-
Status record includes information about warnings and errors.
Created when the return code is SQL_ERROR, SQL_SUCCESS_WITH_INFO, SQL_NO_DATA, SQL_NEED_DATA, or SQL_STILL_EXECUTING.
One of the most important fields of a status record is SQLSTATE. As standardization of error or warning code, the field values are defined by X/Open and ISP/IEC standards. Format is CCSSS, five-digit character string. CC refers to error class and SSS refers to sub class.
A Diagnostic record starts with one head record, and one or more status records are added.
In order to get a value from a diagnostic record, the
SQLGetDiagRec and
SQLGetDiagField functions are required. These two
functions only return the diagnostic record information included in the
handle given as a parameter.
A Diagnostic record is used and managed by an environment connection, statement, and descriptor handle.
Note
Refer to “Chapter 4. tbCLI Error Messages” for more information on error messages.
The tbCLI program is divided into as below.
-
Starting Setting
-
SQL Query Execution and Error Handling
-
Ending Setting
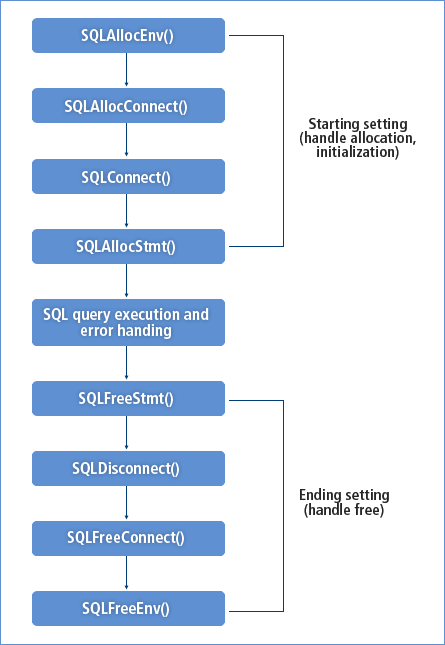
The tbCLI structure is described in detail in the following sections.
Before a tbCLI program is started, initialization settings should be set up. To set up initialization settings, the environment handle and the connection handle should be allocated, and a datasource should be connected. Here, a datasource refers to the whole composition of software and hardware of Tibero.
The following is an example of starting a tbCLI program.
[Example 1.1] Initialization Settings for tbCLI Program
SQLHENV h_env; SQLHDBC h_dbc; SQLRETURN rc = SQL_SUCCESS; ... rc = SQLAllocHandle(SQL_HANDLE_ENV, NULL, &h_env); ... (1) ... if (rc != SQL_SUCCESS) ... rc = SQLAllocHandle(SQL_HANDLE_DBC, h_env, &h_dbc); ... (2) ... if (rc != SQL_SUCCESS) ... rc = SQLConnect(h_dbc, (SQLCHAR *)ds_name, SQL_NTS, (SQLCHAR *)user, SQL_NTS, (SQLCHAR *)passwd, SQL_NTS); ... (3) ... if (rc != SQL_SUCCESS && rc != SQL_SUCCESS_WITH_INFO) ...
(1), (2) Allocate the environment handle and the connection handle for initialization settings.
(3) Connect to a datasource through
SQLConnect function.
In order to call this function, data source name (ds_name), user name (user), and password (passwd) should be also be sent, as parameters. Parameter length should also be set up. In [Example 1.1] above, the null-terminating string, SQL_NTS, is set up instead of length.
(4) If datasource is connected, tbCLI program must allocate at least one statement handle in order to execute an SQL statement.
SQLHSTMT h_stmt; ... rc = SQLAllocHandle(SQL_HANDLE_STMT, h_dbc, &h_stmt); ... (4) ... if (rc != SQL_SUCCESS) ...
There are two ways to execute an SQL statement.
Direct Execution
Executes an SQL statement at once by using the
SQLExecDirect function.
The following is an example of direct execution.
[Example 1.2] SQL query execution of tbCLI program - Direct execution
SQLCHAR *update = "UPDATE EMP SET SALARY = SALARY * 1.05 "
"WHERE DEPTNO = 5";
rc = SQLExecDirect(h_stmt, update, SQL_NTS);
if (rc != SQL_SUCCESS) ...
Prepared Execution
Executes through two steps by using the
SQLPrepare and SQLExecute
functions.
If most of the SQL statements include parameters, use the prepared
execution method. Call the SQLBindParameter
function between the SQLPrepare and
SQLExecute functions to set up the actual value of
a parameter.
The following is an example of executing an SQL statement which includes two input parameters.
[Example 1.3] SQL query execution of tbCLI program - Prepared execution
SQLCHAR *update = "UPDATE EMP SET SALARY = SALARY * ? "
"WHERE DEPTNO = ?";
double ratio = 0.0;
short deptno = 0;
...
rc = SQLPrepare(h_stmt, update, SQL_NTS); ... (1) ...
if (rc != SQL_SUCCESS) ...
rc = SQLBindParameter(h_stmt, 1, SQL_PARAM_INPUT, SQL_C_DOUBLE,
SQL_DOUBLE, 5, 2, &ratio, 0, NULL); ... (a) ...
if (rc != SQL_SUCCESS) ...
rc = SQLBindParameter(h_stmt, 2, SQL_PARAM_INPUT, SQL_C_SHORT,
SQL_SMALLINT, 0, 0, &deptno, 0, NULL); ... (b) ...
if (rc != SQL_SUCCESS) ...
ratio = 1.05;
deptno = 5;
SQLExecute(h_stmt); ... (2) ...
if (rc != SQL_SUCCESS) ...
In the example above, input parameters in the SQL statement are presented as a question mark (?). In order to mark the input parameter position, use 1 or a larger integer.
(1) Set up a pointer variable which contains each input parameter included in the prepared SQL statement. Set the input/output direction, C or C++ data type, SQL data type, precision, and scale for each input parameter ((a), (b)).
(2) Execute the SQL statement. If this statement is executed, the EMP table is updated by the configured input parameters.
Use the SQLRowCount function to check how
many rows are updated after executing the SQL statement.
The following shows how to use the function.
rc = SQLRowCount(h_stmt, &count);
The Return code of each function has information about the execution result, and therefore a user must check the return code after calling the function.
In order to terminate a tbCLI program, tasks that reverse the ones executed in “1.3.1. Initialization Settings” must be executed.
The following is an example of terminating a tbCLI program.
[Example 1.4] Termination Settings for tbCLI Program
rc = SQLDisconnect(h_dbc); ... (1) ... if (rc != SQL_SUCCESS) ... SQLFreeHandle(SQL_HANDLE_DBC, h_dbc); ... (2) ... SQLFreeHandle(SQL_HANDLE_ENV, h_env); ... (3) ...
(1) Disconnect the datasource.
(2), (3) Return the allocated connection handle and the environment handle to the system.