Table of Contents
- 4.1. Overview
- 4.2. Function List
- 4.2.1. ABS
- 4.2.2. ACOS
- 4.2.3. ADD_MONTHS
- 4.2.4. AGGR_CONCAT
- 4.2.5. APPENDCHILDXML
- 4.2.6. ASCII
- 4.2.7. ASCIISTR
- 4.2.8. ASIN
- 4.2.9. ATAN
- 4.2.10. ATAN2
- 4.2.11. AVG
- 4.2.12. BITAND
- 4.2.13. CAST
- 4.2.14. CEIL
- 4.2.15. CHARTOROWID
- 4.2.16. CHR
- 4.2.17. COALESCE
- 4.2.18. COMPOSE
- 4.2.19. CONCAT
- 4.2.20. CONVERT
- 4.2.21. CORR
- 4.2.22. COS
- 4.2.23. COSH
- 4.2.24. COUNT
- 4.2.25. COVAR_POP
- 4.2.26. COVAR_SAMP
- 4.2.27. CUME_DIST
- 4.2.28. CURRENT_DATE
- 4.2.29. CURRENT_TIME
- 4.2.30. CURRENT_TIMESTAMP
- 4.2.31. DBTIMEZONE
- 4.2.32. DECODE
- 4.2.33. DECOMPOSE
- 4.2.34. DELETEXML
- 4.2.35. DENSE_RANK
- 4.2.36. DUMP
- 4.2.37. EMPTY_BLOB
- 4.2.38. EMPTY_CLOB
- 4.2.39. EXISTSNODE
- 4.2.40. EXP
- 4.2.41. EXTRACT
- 4.2.42. EXTRACT(XML)
- 4.2.43. EXTRACTVALUE
- 4.2.44. FIRST
- 4.2.45. FIRST_VALUE
- 4.2.46. FLOOR
- 4.2.47. FROM_TZ
- 4.2.48. GETBLOBVAL
- 4.2.49. GETCLOBVAL
- 4.2.50. GETROOTELEMENT
- 4.2.51. GETSTRINGVAL
- 4.2.52. GREATEST
- 4.2.53. GROUPING
- 4.2.54. GROUPING_ID
- 4.2.55. GROUP_ID
- 4.2.56. HEXTORAW
- 4.2.57. INET_ATON
- 4.2.58. INET_NTOA
- 4.2.59. INITCAP
- 4.2.60. INSERTCHILDXML
- 4.2.61. INSERTCHILDXMLAFTER
- 4.2.62. INSERTCHILDXMLBEFORE
- 4.2.63. INSERTXMLAFTER
- 4.2.64. INSERTXMLBEFORE
- 4.2.65. INSTR
- 4.2.66. ISFRAGMENT
- 4.2.67. KURT
- 4.2.68. LAG
- 4.2.69. LAST_DAY
- 4.2.70. LAST
- 4.2.71. LAST_VALUE
- 4.2.72. LEAD
- 4.2.73. LEAST
- 4.2.74. LENGTH
- 4.2.75. LISTAGG
- 4.2.76. LN
- 4.2.77. LNNVL
- 4.2.78. LOCALTIMESTAMP
- 4.2.79. LOG
- 4.2.80. LOWER
- 4.2.81. LPAD
- 4.2.82. LTRIM
- 4.2.83. MAX
- 4.2.84. MEDIAN
- 4.2.85. MIN
- 4.2.86. MOD
- 4.2.87. MONTHS_BETWEEN
- 4.2.88. NANVL
- 4.2.89. NEW_TIME
- 4.2.90. NEXT_DAY
- 4.2.91. NLSSORT
- 4.2.92. NLS_CHARSET_ID
- 4.2.93. NLS_INITCAP
- 4.2.94. NLS_LOWER
- 4.2.95. NLS_UPPER
- 4.2.96. NTILE
- 4.2.97. NULLIF
- 4.2.98. NUMTODSINTERVAL
- 4.2.99. NUMTOYMINTERVAL
- 4.2.100. NVL
- 4.2.101. NVL2
- 4.2.102. ORA_HASH
- 4.2.103. OVERLAPS
- 4.2.104. PERCENT_RANK
- 4.2.105. PERCENTILE_CONT
- 4.2.106. PERCENTILE_DISC
- 4.2.107. POWER
- 4.2.108. RANK
- 4.2.109. REGR_SLOPE
- 4.2.110. REGR_INTERCEPT
- 4.2.111. REGR_COUNT
- 4.2.112. REGR_R2
- 4.2.113. REGR_AVGX
- 4.2.114. REGR_AVGY
- 4.2.115. REGR_SXX
- 4.2.116. REGR_SXY
- 4.2.117. REGR_SYY
- 4.2.118. RATIO_TO_REPORT
- 4.2.119. RAWTOHEX
- 4.2.120. REGEXP_COUNT
- 4.2.121. REGEXP_INSTR
- 4.2.122. REGEXP_REPLACE
- 4.2.123. REGEXP_SUBSTR
- 4.2.124. REMAINDER
- 4.2.125. REPLACE
- 4.2.126. REVERSE
- 4.2.127. ROUND(number)
- 4.2.128. ROUND(date)
- 4.2.129. ROWIDTOCHAR
- 4.2.130. ROW_NUMBER
- 4.2.131. RPAD
- 4.2.132. RTRIM
- 4.2.133. SESSIONTIMEZONE
- 4.2.134. SIGN
- 4.2.135. SIN
- 4.2.136. SINH
- 4.2.137. SKEW
- 4.2.138. SQRT
- 4.2.139. STDDEV
- 4.2.140. STDDEV_POP
- 4.2.141. STDDEV_SAMP
- 4.2.142. SUBSTR
- 4.2.143. SUM
- 4.2.144. SYS_CONNECT_BY_PATH
- 4.2.145. SYS_CONTEXT
- 4.2.146. SYS_EXTRACT_UTC
- 4.2.147. SYS_GUID
- 4.2.148. SYSDATE
- 4.2.149. SYSTIME
- 4.2.150. SYSTIMESTAMP
- 4.2.151. TAN
- 4.2.152. TANH
- 4.2.153. TIMESTAMP_TO_TSN
- 4.2.154. TO_BINARY_DOUBLE
- 4.2.155. TO_BINARY_FLOAT
- 4.2.156. TO_CHAR(character)
- 4.2.157. TO_CHAR(datetime)
- 4.2.158. TO_CHAR(number)
- 4.2.159. TO_CLOB
- 4.2.160. TO_DATE
- 4.2.161. TO_DSINTERVAL
- 4.2.162. TO_LOB
- 4.2.163. TO_MULTI_BYTE
- 4.2.164. TO_NCHAR
- 4.2.165. TO_NUMBER
- 4.2.166. TO_SINGLE_BYTE
- 4.2.167. TO_TIME
- 4.2.168. TO_TIMESTAMP
- 4.2.169. TO_TIMESTAMP_TZ
- 4.2.170. TO_YMINTERVAL
- 4.2.171. TRANSLATE
- 4.2.172. TRIM
- 4.2.173. TRUNC(number)
- 4.2.174. TRUNC(date)
- 4.2.175. TSN_TO_TIMESTAMP
- 4.2.176. TZ_OFFSET
- 4.2.177. TZ_SHIFT
- 4.2.178. UID
- 4.2.179. UNISTR
- 4.2.180. UPDATEXML
- 4.2.181. UPPER
- 4.2.182. USER
- 4.2.183. USERENV
- 4.2.184. VAR_POP
- 4.2.185. VAR_SAMP
- 4.2.186. VARIANCE
- 4.2.187. VSIZE
- 4.2.188. XMLAGG
- 4.2.189. XMLCAST
- 4.2.190. XMLCDATA
- 4.2.191. XMLCOLATTVAL
- 4.2.192. XMLCOMMENT
- 4.2.193. XMLCONCAT
- 4.2.194. XMLELEMENT
- 4.2.195. XMLEXISTS
- 4.2.196. XMLFOREST
- 4.2.197. XMLPARSE
- 4.2.198. XMLPI
- 4.2.199. XMLQUERY
- 4.2.200. XMLROOT
- 4.2.201. XMLSERIALIZE
- 4.2.202. XMLTABLE
- 4.2.203. XMLTRANSFORM
This chapter describes the embedded functions provided by Tibero.
Tiberoprovides various built-in functions. Some of the functions are defined in the SQL standard, and other functions are additionally provided by Tibero. Tibero's functions can be divided into two types: single row functions and aggregate functions.
Most functions have one or more parameters although some functions have no parameters. Each parameter has a specific data type. If an argument's data type is different from the type declared in a function, it will be converted as described in “3.3.1. Expression Conversion”. If the argument cannot be converted, an error will occur. In addition, if an argument exceeds a defined range, an error will occur.
All functions return a value. Most single-row functions return NULL if they receive NULL as an argument with the exception of a few functions such as CONCAT, NVL, and REPLACE.
When saving a function's return value in a column, note the allowed range of the value.
-
If a function's return value is a NUMBER, it should be within the precision and scale of the column.
-
If a function's return value is a CHAR, it should be within the maximum length of the column.
-
If a function's return value is a VARCHAR, it should be within the maximum length of the column.
Single row functions take column values as arguments from a single row. These kinds of functions can take both actual input data and column values as arguments.
Single row functions can be included in any expression in SQL statements.
Aggregate functions take column values as arguments from one or more rows. These kinds of functions can take both actual input data and column values as arguments.
Aggregate functions can only be included in the SELECT, GROUP BY, and HAVING clauses in SELECT statements.
Examples of aggregate functions provided by Tibero include: AVG, COUNT, MAX, MIN, and SUM. These functions can calculate average value, row count, maximum value, minimum value, and sum for each given column, respectively. If a function receives actual data as an argument, it just returns the received data.
SELECT Clauses
An aggregate function can be nested only once in the SELECT clause in a SELECT statement. Functions cannot be nested in other clauses.
The following aggregate function returns an error:
COUNT(SUM(AVG(SALARY)))
For a nested function, the inner aggregate function is evaluated first, and then the outer function is evaluated for the values returned by the inner function. For example, for SUM(AVG(SALARY)), the average value of the SALARY column is calculated first, and then a sum of all the average values is calculated and returned.
Any expression except a conditional expression can be located inside parentheses. In the SELECT clause in a SELECT statement, an aggregate function can include another aggregate function.
The following aggregate function is valid:
SUM(AVG(SALARY) * COUNT(EMPNO) + 1.10)
The COUNT function can include an asterisk (*) inside parentheses. In this case, the total number of rows, not a specific column, is returned.
If a SELECT statement that includes an aggregate function is evaluated for a table that has no rows, no resulting row will be returned. However, if a SELECT clause includes the COUNT(*) function, one row that has a 0 for the column value will be returned.
GROUP BY Clauses
Aggregate functions are usually used with a GROUP BY clause in a SELECT statement. An aggregate function returns one value for each set of rows grouped by the GROUP BY clause. If a SELECT statement does not include a GROUP BY clause, the entire table is regarded as a single group.
The following SELECT statement includes a GROUP BY clause.
SELECT AVG(SALARY) FROM EMP GROUP BY DEPTNO;
In the above statement, all rows in the EMP table are grouped by their DEPTNO column value, and then the average for the SALARY column for the employees in each group is calculated.
HAVING Clauses
A HAVING clause in a SELECT statement includes conditions for groups. It can also include aggregate functions for columns, including those in SELECT or GROUP BY clauses.
The following SELECT statement includes a HAVING clause:
SELECT AVG(SALARY) FROM EMP GROUP BY DEPTNO HAVING COUNT(EMPNO) >= 3;
The above statement calculates the average SALARY column values for departments that have three or more employees.
The reserved words DISTINCT and ALL can precede a parameter of an aggregate function. These reserved words define how to handle duplicate column values; DISTINCT removes duplicate column values, and ALL allows them.
For example, if four rows in a group have values of 20,000, 20,000, 20,000, and 40,000 for the SALARY column, the result of AVG(DISTINCT SALARY) will be 30,000 and the result of AVG(ALL SALARY) will be 25,000. If neither DISTINCT or ALL is specified, the default value is ALL.
The following table lists the aggregate functions provided by Tibero.
| Aggregate Function | Description |
|---|---|
| AVG | Finds the average value of expr of all rows in a group. |
| CORR | Finds the correlation coefficient of expr1 and expr2, which are given as parameters. |
| COUNT | Counts the number of rows returned by a query. |
| COVAR_POP | Calculates the population covariance of expr1 and expr2. |
| COVAR_SAMP | Calculates the sample covariance of expr1 and expr2. |
| DENSE_RANK | Returns the rank of each row in a group after the rows have been sorted by each group. |
| FIRST | Picks the first row after sorting, applies the row to the specified aggregate function, and returns the result. |
| LAST | Picks the last row after sorting, applies the row to the specified aggregate function, and returns the result. |
| MAX | Finds the maximum expr value of all rows in a group. |
| MIN | Finds the minimum expr value of all rows in a group. |
| PERCENT_RANK | Finds the position of the value given as a parameter in a group. |
| PERCENTILE_CONT | An inverse distribution function that calculates the value that corresponds to the percentile rank given as a parameter by the continuous distribution model. |
| PERCENTILE_DISC | An inverse distribution function that assumes a discrete distribution model. It can be used as an analytic function. |
| RANK | Returns the rank of each row in a group after sorting rows by group. |
| Calculates the linear equation that best fits the set of numeric data pairs. | |
| STDDEV | Returns the standard deviation of expr. |
| STDDEV_POP | Returns the population standard deviation of expr. |
| STDDEV_SAMP | Returns the accumulated sample standard deviation of expr. |
| SUM | Finds the sum of expr values of all rows in a group. |
| VARIANCE | Returns the variance of expr. |
| VAR_POP | Returns the population variance of expr. |
| VAR_SAMP | Returns the sample variance of expr. |
| XMLAGG | Receives XML parts, collects them to make a XML document, and returns the document. |
Analytic functions are used to calculate an aggregate value for a specific row group, similar to aggregate functions. They are different from aggregate functions in that all rows in a single row group do not share a single aggregate value. Each row has an aggregate value for its own row group because row groups are specified for each row. In an analytic function, the row group is called a window and is defined in analytic_clause. The window range can be defined by the number of physical rows or a calculated value.
Analytic functions are handled last, after everything except for ORDER BY clauses in a query block. The WHERE, GROUP BY, and HAVING clauses are all evaluated before analytic functions. Therefore, analytic functions can be located only in SELECT or ORDER BY clauses.
analytic_function
An analytic function consists of three parts: analytic_function, argument, and analytic_clause.
A detailed description of analytic_function is as follows:

analytic_clause
A function can be used as an analytic function using "OVER analytic_clause". Analytic functions are handled after all other clauses except for ORDER BY clauses in a query block. To select only a part of the results from an analytic function, wrap the query that performed the analytic function with a view and apply a WHERE clause to the view. Analytic functions cannot be used in analytic_clause. However, analytic functions can be used in a subquery.
A detailed description of analytic_clause follows:
-
Syntax
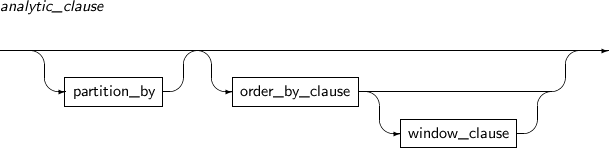
-
Component
Component Description partition_by Partitions the result set of the current query block before calculating an analytic function. order_by_clause Specifies how to sort rows within one partition divided by partition_by. window_clause Can be specified only when the order_by_clause of an analytic function is specified.
partition_by
This clause divides the result set of a current query block based on expr before calculating an analytic function. If this clause is not specified, the analytic function treats the entire query result as a single group.
Several analytic functions can be specified in a SELECT or an ORDER BY clause in one query block. Each analytic function can have a different PARTITION BY key.
A detailed description of partition_by follows:
-
Syntax

-
Component
Component Description expr An expression that consists of constants, columns, and non-analytic functions.
order_by_clause
This clause specifies how to sort rows within a partition divided by partition_by. Several key values can be specified to sort rows.
For the order_by_clause used in analytic functions, location constants such as ORDER BY 1 cannot be used. SIBLINGS and column aliases of a SELECT list also cannot be used. Apart from these differences, the usage is the same as standard ORDER BY clauses.
The order_by_clause used in an analytic function only determines the order of rows in a partition, and does not determine the order of rows in the final result set of the query block. To do so, a separate ORDER BY clause for the query block should also be present.
A detailed description of order_by_clause follows:
-
Syntax
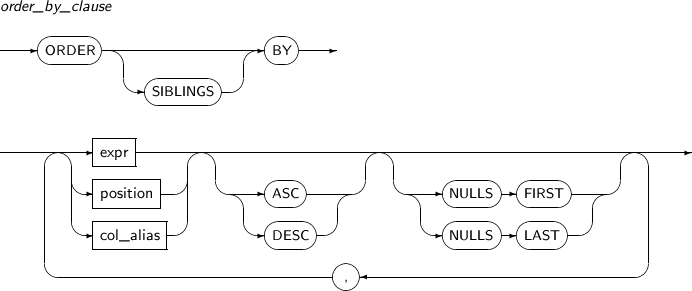
-
Component
Component Description SIBLINGS Used for a query in which hierarchical_query_clause is specified.
order_by_clause determines the sorting order in a sibling node of a hierarchical query.
Cannot be used in an analytic function.
expr Expression used as a sorting key. position Specifies the position of expr specified in select_list.
Cannot be used in an analytic function.
ASC Specifies the sorting order.
Sorts in ascending order.
DESC Specifies the sorting order.
Sorts in descending order.
NULLS FIRST Specifies the sorting order of NULL.
Used as the default for ascending order sort.
NULLS LAST Specifies the sorting order of NULL.
Used as the default for descending order sort.
window_clause
Some analytic functions can have a window_clause. window_clause cannot be specified without also specifying an order_by_clause. If window_clause is not specified, then the keywords RANGE, BETWEEN, UNBOUNDED, PRECEDING, and CURRENT ROW are set to the default window.
A detailed description of window_clause follows:
-
Syntax

-
Component
Component Description ROWS
Sets a window type to ROW. An analytic function operates on the rows of a window defined by the current row. It defines a windows in physical row units.
If a window is specified with ROWS, an analytic function returns different rows even if the result of order_by_clause is the same.
RANGE Sets a window type to RANGE. RANGE defines a window by specifying
a logical offset based on the current row.
Unlike ROW, the returned rows of the window specified with RANGE are always the same.
When RANGE is specified, only one key can be specified in order_by_clause.
If a window is specified with RANGE, an analytic function always returns the same rows if the result of order_by_clause is the same. The example in “4.2.143. SUM” shows this behavior.
BETWEEN ... AND Indicates the start point and the end point of a window. The start point is the row specified before AND, and the end point is the row specified after AND.
If only one point is specified without specifying BETWEEN ... AND, that point becomes the start point and the current row becomes the end point.
The following table shows whether each analytic function provided by Tibero uses window_clause.
| Analytic Function | Uses window_clause |
|---|---|
| AVG | Yes |
| CORR | Yes |
| COUNT | Yes |
| COVAR_POP | Yes |
| COVAR_SAMP | Yes |
| DENSE_RANK | No |
| FIRST | No |
| FIRST_VALUE | Yes |
| LAG | No |
| LAST | No |
| LAST_VALUE | Yes |
| LEAD | No |
| MAX | Yes |
| MIN | Yes |
| NTILE | No |
| PERCENT_RANK | No |
| PERCENTILE_CONT | No |
| PERCENTILE_DISC | No |
| RANK | No |
| RATIO_TO_REPORT | No |
| Yes | |
| ROW_NUMBER | No |
| STDDEV | Yes |
| STDDEV_POP | Yes |
| STDDEV_SAMP | Yes |
| SUM | Yes |
| VARIANCE | Yes |
| VAR_POP | Yes |
| VAR_SAMP | Yes |
window_value
A detailed description of window_value follows:
-
Syntax

-
Component
Component Description UNBOUNDED PRECEDING Specifies the first row of a partition as the start point. The first row cannot be used as the end point. UNBOUNDED FOLLOWING Specifies the last row of a partition as the end point. The last row cannot be used as the start point. CURRENT ROW The current row can be used as the start or end point. If ROW or RANGE is specified, the current row or the calculated row from the current row is specified. If the current row is specified as the start point, "expr PRECEDING" cannot be used as the end point, and if it is specified as the end point, "expr FOLLOWING" cannot be used as the start point. expr PRECEDING If "expr PRECEDING" is specified at the end point, the start point should always be "expr PRECEDING". expr FOLLOWING If "expr FOLLOWING" is specified at the start point, the end point should always be "expr FOLLOWING". expr differs according to its window type as follows:
-
When the window type is ROW,
-
expr specifies a physical offset. This is a positive number or an expression whose result is a positive number.
-
The row of the start point must be located before the row of the end point.
-
-
When a window type is RANGE,
-
expr specifies a logical offset. This is an interval literal or an expression whose result is a non-negative number. For information about an interval literal, refer to “2.3. Literals”.
-
Numeric values can be used for expr only when the expr in order_by_clause is a NUMBER or DATE.
-
Interval values can be used for expr only when the expr in order_by_clause is a DATE.
-
-
The following describes the built-in functions provided by Tibero.
ABS returns the absolute value of num.
A detailed description of the ABS function is as follows:
-
Syntax
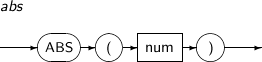
-
Component
Component Description num An expression that returns either a numeric type or a compatible type. -
Example
The following example shows how to use the ABS function.
SQL> SELECT ABS(15.5), ABS(-25.5) FROM DUAL; ABS(15.5) ABS(-25.5) ---------- ---------- 15.5 25.5 1 row selected.
ACOS returns the arc cosine of num. This function returns a NUMBER with a value between 0 and pi, in radians.
A detailed description of the ACOS function is as follows:
-
Syntax
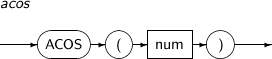
-
Component
Component Description num Should be between -1 and 1.
Should be a NUMBER or a type that can be converted to the NUMBER type.
The return value is a radian between 0 and pi.
If the type of num is BINARY FLOAT, it returns BINARY DOUBLE type. Otherwise, it returns the same type as num.
-
Example
The following example shows how to use the ACOS function.
SQL> SELECT ACOS(.4) FROM DUAL; ACOS(.4) ---------- 1.15927948 1 row selected.
ADD_MONTHS returns date plus integer months.
A detailed description of the ADD_MONTHS function is as follows:
-
Syntax

-
Component
Component Description date An expression that returns a DATE. integer A type that can hold integers. -
Example
The following example shows how to use the ADD_MONTHS function.
SQL> SELECT ADD_MONTHS (DATE'2006-01-01', 1) FROM DUAL; ADD_MONTHS(DATE'2006-01-01',1) -------------------------------- 2006/02/01 1 row selected.
AGGR_CONCAT concatenates strings from every row with separator between them and returns a single string. Rows that return NULL are excluded from the result.
A detailed description of the AGGR_CONCAT function is as follows:
-
Syntax

-
Component
Component Description set_quantifier Specifies whether to allow duplicate rows in the result. One of the following can be specified:
-
DISTINCT, UNIQUE: Removes duplicate rows.
-
ALL: Includes all rows. This is the default value.
expr An expression that returns a string or a compatible type. separator A character literal that will be concatenated to expr. order_by_clause Specifies how to sort strings that will be concatenated.
For detailed information, see order_by_clause in “4.1.3. Analytic Functions”.
-
-
Example
The following example shows how to use the AGGR_CONCAT function.
SQL> SELECT AGGR_CONCAT(NAME, ',') AS "EMPLOYEE" FROM EMP GROUP BY DEPT_ID; EMPLOYEE --------------------------------------------------------------------- Johnny Depp,Brad Pitt,Bruce Willis Will Smith,Nicolas Cage Jason Statham Angelina Jolie 4 rows selected.
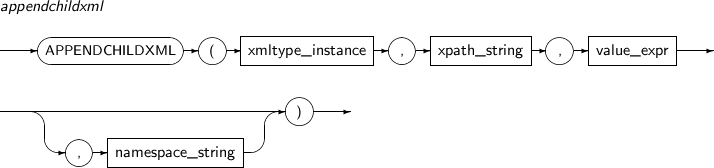
APPENDCHILDXML appends a user-input xml value to a node specified with an XPath expression xpath_string. The node is inserted after existing nodes.
A detailed description of the APPENDCHILDXML function is as follows:
-
Syntax
-
Component
Component Description xmltype_instance An expression that returns an XMLType instance. xpath_string An XPath expression that specifies the location where one or more child nodes are inserted. value_expr Specifies one or more XMLType child nodes to be inserted. This must be a value that can be converted to a string. namespace_string Provides namespace information for xpath_string. It must be a VARCHAR. -
Example
The following example shows how to use the APPENDCHILDXML function.
... INFO column '<dept><id>1</id><id>2</id></dept>' ... SQL> UPDATE EMP SET INFO = APPENDCHILDXML(INFO, '/dept', XMLTYPE('<id>3</id>')); SQL> SELECT INFO FROM EMP; EMP ------------------------------------------- <dept><id>1</id><id>2</id><id>3</id></dept>
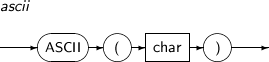
ASCII returns the decimal value in the database character set for the first character of char. If the current database's character set is 7-bit ASCII or EBCDIC, this function returns an ASCII value or an EBCDIC value, respectively.
A detailed description of the ASCII function is as follows:
-
Syntax
-
Component
Component Description char Can be a CHAR, VARCHAR, NCHAR, or NVARCHAR.
Cannot be a CLOB. However, this function can be called with a CLOB by using a type conversion function.
-
Example
The following example shows how to use the ASCII function.
SQL> SELECT ASCII('ABC') CODE FROM DUAL; CODE ---------- 65 1 row selected.
ASCIISTR returns an ASCII string using the database character set for str. Non-ASCII characters are converted to the form of "\xxxx", where xxxx is a UTF-16 code.
A detailed description of the ASCIISTR function is as follows:
-
Syntax

-
Component
Component Description str An expression that returns a string. -
Example
The following example shows how to use the ASCII function. The database's character set is 'MSWIN949'.
SQL> SELECT ASCIISTR('AÄB') FROM DUAL; ASCIISTR('AÄB') ------------------ A\00C4B 1 row selected.
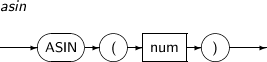
ASIN returns the arcsine of num. This function returns a NUMBER between -pi/2 and pi/2, in radians.
A detailed description of the ASIN function is as follows:
-
Syntax
-
Component
Component Description num Should be between -1 and 1.
Should be a NUMBER or a compatible type.
The return value is a radian between -pi/2 and pi/2.
If the type of num is BINARY FLOAT, it returns BINARY DOUBLE type. Otherwise, it returns the same type as num.
-
Example
The following example shows how to use the ASIN function.
SQL> SELECT ASIN(.4) FROM DUAL; ASIN(.4) ---------- .411516846 1 row selected.
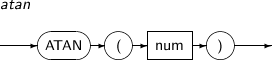
ATAN returns the arctangent of a num. This function returns a NUMBER between -pi/2 and pi/2, in radians.
A detailed description of the ATAN function is as follows:
-
Syntax
-
Component
Component Description num1, num2 Any real number. The return value is a radian between -pi/2 and pi/2, and it is a NUMBER or a compatible type.
If the type of num is BINARY FLOAT, it returns BINARY DOUBLE type. Otherwise, it returns the same type as num.
-
Example
The following example shows how to use the ATAN function.
SQL> SELECT ATAN(.4) FROM DUAL; ATAN(.4) ---------- .380506377 1 row selected.
ATAN2 returns the arctangent of num1 and num2. ATAN2(num1, num2) is the same as ATAN(num1/num2). The return value of this function is a NUMBER between -pi/2 and pi/2, in radians.
A detailed description of the ATAN2 function is as follows:
-
Syntax

-
Component
Component Description n, m Any real number. The return value is a radian between -pi/2 and pi/2, and it is a NUMBER or a compatible type.
If the type of num1 or num2 is BINARY FLOAT or BINARY DOUBLE, a BINARY DOUBLE type is returned. Otherwise, a NUMBER type is returned.
-
Example
The following example shows how to use the ATAN2 function.
SQL> SELECT ATAN2(.3, .4) ATAN2 FROM DUAL; ATAN2 ---------- .643501109 1 row selected.
AVG returns the average value of expr for all rows in a group. This function can be used as an analytic function.
A detailed description of the AVG function is as follows:
-
Syntax


-
Component
Component Description analytic_clause This function can be used as an analytic function using "OVER analytic_clause".
For detailed information, see analytic_clause in “4.1.3. Analytic Functions”.
expr An expression. See “3.3. Expressions”. ALL If this keyword is specified in front of expr, duplicate values of expr are not removed and the average value of all values is calculated. This is the default keyword. DISTINCT If this keyword is specified in front of expr, duplicate values of expr are removed and then the average value is calculated.
When specifying DISTINCT, only the query_partion_clause of the analytic_clause can be specified. The order_by_clause cannot be specified, so the window_clause also cannot be specified.
UNIQUE The same as DISTINCT. -
Example
The following example shows how to use the AVG function.
SQL> SELECT AVG(SALARY) AVG FROM EMP GROUP BY DEPTNO; AVG ---------- 3255 1 row selected. -
Example (Analytic Function)
The following example shows how to use the AVG function as an analytic function.
SQL> SELECT ID, HIREDATE, SALARY, AVG(SALARY) OVER (ORDER BY HIREDATE ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS AAVG FROM EMP; ID HIREDATE SALARY AAVG ---------- ---------- ---------- ---------- 1 1987/01/06 20000 17500 5 1991/05/16 15000 14333.3333 4 1999/11/25 8000 9333.33333 2 2001/06/07 5000 6333.33333 8 2003/03/26 6000 6666.66667 6 2003/08/15 9000 6333.33333 7 2004/02/08 4000 6666.66667 3 2005/09/23 7000 5500 8 rows selected.
BITAND returns the bitwise AND of expr1 and expr2.
A detailed description of the BITAND function is as follows:
-
Syntax
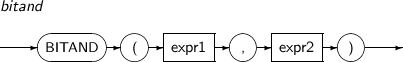
-
Component
Component Description expr1, expr2 Expressions that return integers. -
Example
The following example shows how to use the BITAND function.
SQL> SELECT BITAND(3, 1), BITAND(4, 1) FROM DUAL; BITAND(3,1) BITAND(4,1) ----------- ----------- 1 0 1 row selected.
CAST converts a value from one data type to another data type.
A detailed description of the CAST function is as follows:
-
Syntax

-
Component
Component Syntax expr An expression that returns a specific data type. typename The name of the data type to which expr should be converted. -
Example
The following example shows how to use the CAST function.
SQL> SELECT CAST('1974-06-23' AS TIMESTAMP) TS FROM DUAL; TS -------------------------- 1974/06/23 00:00:00.000000 1 row selected.
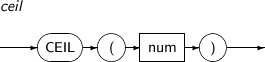
CEIL returns the smallest integer greater than or equal to num.
A detailed description of the CEIL function is as follows:
-
Syntax
-
Component
Component Description num An expression that returns a real number. num is a NUMBER or a compatible type. The return value is the same type as num. -
Example
The following example shows how to use the CEIL function.
SQL> SELECT CEIL(15.5), CEIL(-15.5), CEIL(25.0) FROM DUAL; CEIL(15.5) CEIL(-15.5) CEIL(25.0) ---------- ----------- ---------- 16 -15 25 1 row selected.
CHARTOROWID converts a CHAR, VARCHAR, NCHAR, or NVARCHAR to a ROWID.
A detailed description of the CHARTOROWID function is as follows:
-
Syntax

-
Component
Component Description str A value to be converted to the ROWID type. -
Example
The following example shows how to use the CHARTOROWID function.
SQL> SELECT DEPT_ID FROM EMP WHERE ROWID = CHARTOROWID('AAAAUcAAAAAAAxPAAA'); DEPT_ID ------- 5 1 row selected.
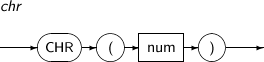
CHR returns the character that corresponds to num.
A detailed description of the CHR function is as follows:
-
Syntax
-
Component
Component Description num An expression that returns an integer. -
Example
The following example shows how to use the CHR function.
SQL> SELECT CHR(68) || CHR(66) RSLT FROM DUAL; RSLT ---- DB 1 row selected.
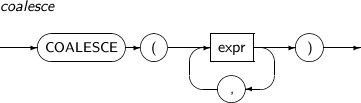
COALESCE returns the first non-NULL expr. If every occurrence of expr is NULL, NULL is returned.
A detailed description of the COALESCE function is as follows:
-
Syntax
-
Component
Component Description expr All occurrences of expr should be of the same type or a compatible type. -
Example
The following example shows how to use the COALESCE function.
SQL> SELECT COALESCE(NULL, 'A', 'B') FROM DUAL; COALESCE(NULL, 'A', 'B') ------------------------ A 1 row selected.
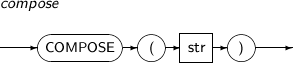
COMPOSE converts str to a UNICODE string in Normalization Form C (NFC).
A detailed description of the COMPOSE function is as follows:
-
Syntax
-
Component
Component Description str An expression that returns a string. -
Example
The following example shows how to use the COMPOSE function.
SQL> SELECT COMPOSE('o' || UNISTR('\0308')) FROM DUAL; COMPOSE('O'||UNISTR('\0308')) -------------------------------------------------------------------------------- 1 row selected.
CONCAT returns str1 concatenated with str2. The result is the same as using the concatenation operation (||). If one of the arguments is NULL, the result is not NULL.
A detailed description of the CONCAT function is as follows:
-
Syntax
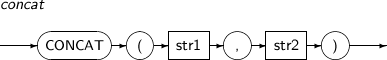
-
Component
Component Description str1, str2 Expressions that return a string. -
Example
The following example shows how to use the CONCAT function.
SQL> SELECT CONCAT('ABC', 'DEF') FROM DUAL; CONCAT('ABC', 'DEF') -------------------- ABCDEF 1 row selected.
CONVERT converts str to a string of another character set. If there is no corresponding character, "?" is returned.
A detailed description of the CONVERT function is as follows:
-
Syntax
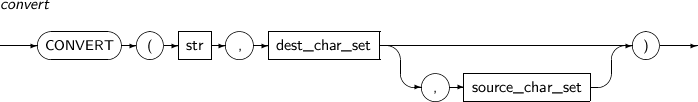
-
Component
Component Description str An expression that returns a string. dest_char_set Specifies the character set name to which str is converted.
-
The database character set name can be used.
-
Character sets besides ISO2022-KR and US8ICL can be used.
source_char_set Specifies the character set name for str. The default value is the character set name of the database.
- The default value is the character set name of the database.
-
-
Example
The following example shows how to use the CONVERT function.
SQL> SELECT CONVERT('AÄÄB', 'US7ASCII', 'MSWIN949') FROM DUAL; CONVERT('AÄÄB','US7ASCII','MSWIN949') --------------------------------------- A??B 1 row selected.
CORR computes the coefficient of correlation of expr1 and expr2. This function can be used as an analytic function.
This function takes arguments of any numeric or compatible type. If the argument is a numeric type, this function returns a value that is the same type as the argument. Otherwise, it returns the type the argument was converted to.
In Tibero, the coefficient of correlation is computed with the following formula:
COVAR_POP(expr1, expr2) / (STDDEV_POP(expr1) * STDDEV_POP(expr2))
A detailed description of the CORR function is as follows:
-
Syntax

-
Component
Component Description expr1, expr2 Expressions that return a numeric value. OVER analytic_clause This function can be used as an analytic function using "OVER analytic_clause".
For detailed information, see analytic_clause in “4.1.3. Analytic Functions”.
-
Example
The following example shows how to use the CORR function.
SQL> SELECT CORR(AGE, SAL) FROM EMP; CORR(AGE,SAL) ------------- -.21144410174 1 row selected.
-
Example (Analytic Function)
The following example shows how to use the CORR function as an analytic function.
SQL> SELECT DEPTNO, EMPNO, CORR(SAL, AGE) OVER (PARTITION BY DEPTNO) AS CORR FROM EMP; DEPTNO EMPNO CORR ---------- ---------- ---------- 10 7934 -.93645032 10 7839 -.93645032 10 7782 -.93645032 20 7566 .567780056 20 7788 .567780056 20 7876 .567780056 20 7902 .567780056 20 7369 .567780056 30 7654 -.33417865 30 7698 -.33417865 30 7521 -.33417865 30 7499 -.33417865 30 7844 -.33417865 30 7900 -.33417865 14 rows selected.
COS returns the cosine of num.
A detailed description of the COS function is as follows:
-
Syntax

-
Component
Component Description num An expression that returns a real number, in radians. Should be a NUMBER or a compatible type. If the type of num is BINARY FLOAT, it returns BINARY DOUBLE type. Otherwise, it returns the same type as num. -
Example
The following example shows how to use the COS function.
SQL> SELECT COS(360 * 3.14159265359/180) FROM DUAL; COS(360 * 3.14159265359/180) ---------------------------- 1 1 row selected.
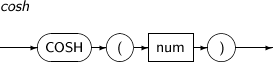
COSH returns the hyperbolic cosine of num.
A detailed description of the COSH function is as follows:
-
Syntax
-
Component
Component Description num An expression that returns a real number, in radians. Should be a NUMBER or a compatible type. If the type of num is BINARY FLOAT, it returns BINARY DOUBLE type. Otherwise, it returns the same type as num. -
Example
The following example shows how to use the COSH function.
SQL> SELECT COSH(0) FROM DUAL; COSH(0) ---------- 1 1 row selected.
COUNT returns the number of rows returned by a query. It always returns a number and never returns NULL. This function can be used as an analytic function.
A detailed description of the COUNT function is as follows:
-
Syntax
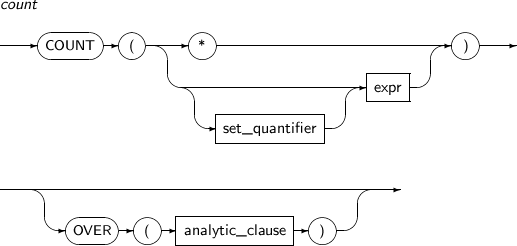
-
Component
Component Description set_quantifier Specifies whether duplicate rows are counted. One of the following can be set:
-
DISTINCT, UNIQUE: Remove duplicate rows.
-
ALL: includes all rows. This is the default value.
* If an asterisk (*) is specified, all rows including duplicates and NULLs are counted. expr If expr is specified, this function counts rows where expr evaluates to not NULL.
Specifying DISTINCT makes this function count only non-duplicate rows returned as the result of expr.
analytic_clause This function can be used as an analytic function using "OVER analytic_clause".
For detailed information, see analytic_clause in “4.1.3. Analytic Functions”.
-
-
Example
The following example shows how to use the COUNT function.
SQL> SELECT COUNT (*) FROM EMP; COUNT(*) ---------- 9 1 row selected. -
Example (Analytic Function)
The following example shows how to use the COUNT function as an analytic function.
SQL> SELECT NAME, SALARY, COUNT(*) OVER (ORDER BY SALARY RANGE BETWEEN 1000 PRECEDING AND 1000 FOLLOWING) AS W_COUNT FROM EMP; NAME SALARY W_COUNT -------------------- ---------- ---------- Paul 2000 4 Tom 2500 5 Jill 3000 6 Susan 3000 6 Matt 3200 5 Coon 4000 5 Josh 4500 2 Cathy 6000 2 Brad 6200 2 9 rows selected.
COVAR_POP computes the population covariance of expr1 and expr2. This function can be used as an analytic function.
This function takes arguments of any numeric type or a compatible type, and returns a NUMBER.
In Tibero, the population covariance is computed with the following formula:
(SUM(expr1 * expr2) - SUM(expr2) * SUM(expr1) / n) / n
In the above formula, n is the number of rows where both expr1 and expr2 are non-NULL.
A detailed description of the COVAR_POP function is as follows:
-
Syntax

-
Component
Component Description expr1, expr2 Expressions that return a numeric value. OVER analytic_clause This function can be used as an analytic function using "OVER analytic_clause".
For detailed information, see analytic_clause in “4.1.3. Analytic Functions”.
-
Example
The following example shows how to use the COVAR_POP function.
SQL> SELECT COVAR_POP(AGE, SAL) AS COVAR_POP FROM EMP; COVAR_POP ---------- -642.09184 1 row selected.
-
Example (Analytic Function)
The following example shows how to use the COVAR_POP function as an analytic function.
SQL> SELECT DEPTNO, EMPNO, COVAR_POP(AGE, SAL) OVER (PARTITION BY DEPTNO) AS COVAR_POP FROM EMP; DEPTNO EMPNO COVAR_POP ---------- ---------- ---------- 10 7934 -4777.7778 10 7839 -4777.7778 10 7782 -4777.7778 20 7566 1470 20 7788 1470 20 7876 1470 20 7902 1470 20 7369 1470 30 7654 -480.55556 30 7698 -480.55556 30 7521 -480.55556 30 7499 -480.55556 30 7844 -480.55556 30 7900 -480.55556 14 rows selected.
COVAR_SAMP computes the sample covariance of expr1 and expr2. This function can be used as an analytic function.
This function takes arguments of any numeric type or a compatible type, and returns a NUMBER.
In Tibero, the sample covariance is computed with the following formula:
(SUM(expr1 * expr2) - SUM(expr1) * SUM(expr2) / n) / (n-1)
In the above formula, n is the number of rows where both expr1 and expr2 are non-NULL.
A detailed description of the COVAR_SAMP function is as follows:
-
Syntax

-
Component
Component Description expr1, expr2 Expressions that return a numeric value. OVER analytic_clause This function can be used as an analytic function using "OVER analytic_clause".
For detailed information, see analytic_clause in “4.1.3. Analytic Functions”.
-
Example
The following example shows how to use the COVAR_SAMP function.
SQL> SELECT COVAR_SAMP(AGE, SAL) AS COVAR_SAMP FROM EMP; COVAR_SAMP ---------- -691.48352 1 row selected.
-
Example (Analytic Function)
The following example shows how to use the COVAR_SAMP function as an analytic function.
SQL> SELECT DEPTNO, EMPNO, COVAR_SAMP(AGE, SAL) OVER (PARTITION BY DEPTNO) AS COVAR_SAMP FROM EMP; DEPTNO EMPNO COVAR_SAMP ---------- ---------- ---------- 10 7934 -7166.6667 10 7839 -7166.6667 10 7782 -7166.6667 20 7566 1837.5 20 7788 1837.5 20 7876 1837.5 20 7902 1837.5 20 7369 1837.5 30 7654 -576.66667 30 7698 -576.66667 30 7521 -576.66667 30 7499 -576.66667 30 7844 -576.66667 30 7900 -576.66667 14 rows selected.
CUME_DIST computes the cumulative distribution of a value in a group of values. The return value is a NUMBER greater than 0 and less than or equal to 1.
The cumulative distribution is calculated in the following way. The rows in a group are sorted based on order_by_clause. Then, the position where the row corresponding to the given argument belongs is calculated. Finally, that position is divided by the number of rows.
A detailed description of the CUME_DIST function is as follows:
-
Syntax

-
Component
Component Description expr Should be a constant value in a group and correspond to an expression in order_by_clause. order_by_clause Specifies how to sort rows in a single partition.
For detailed information, see order_by_clause in “4.1.3. Analytic Functions”.
-
Example
The following example shows how to use the CUME_DIST function.
SQL> SELECT CUME_DIST(1000, '1981/01/01') WITHIN GROUP (ORDER BY SAL, HIREDATE) AS "CUME_DIST" FROM EMP; CUME_DIST ---------- .2 1 row selected.
CURRENT_DATE returns the current date based on the current session's time zone and the Gregorian calendar.
A detailed description of the CURRENT_DATE function is as follows:
-
Syntax

-
Example
The following example shows how to use the CURRENT_DATE function.
SQL> SELECT CURRENT_DATE FROM DUAL; CURRENT_DATE ----------------------------------------------------- 2005/12/04 1 row selected.
CURRENT_TIME returns the current time based on the current session's time zone.
A detailed description of the CURRENT_TIME function is as follows:
-
Syntax

-
Example
The following example shows how to use the CURRENT_TIME function.
SQL> SELECT CURRENT_TIME FROM DUAL; CURRENT_TIME -------------------------------- 20:23:18.383578 1 row selected.
CURRENT_TIMESTAMP returns the current date and time based on the current session's time zone. The return value is a TIMESTAMP WITH TIME ZONE.
A detailed description of the CURRENT_TIMESTAMP function is as follows:
-
Syntax
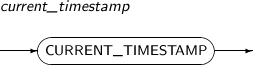
-
Example
The following example shows how to use the CURRENT_TIMESTAMP function.
SQL> SELECT CURRENT_TIMESTAMP FROM DUAL; CURRENT_TIMESTAMP --------------------------------------------- 2005/12/04 20:22:26.391220 Asia/Seoul 1 row selected.
DBTIMEZONE returns information about the database time zone in the form of an offset ([+|-]TZH:TZM) or a time zone region name (TZR). In Tibero, UTC is always returned.
A detailed description of the DBTIMEZONE function is as follows:
-
Syntax
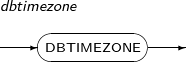
-
Example
The following example shows how to use the DBTIMEZONE function.
SQL> SELECT DBTIMEZONE FROM DUAL; DBTIMEZONE ------------------------------------- UTC 1 row selected.
DECODE compares expr to each value of search. If expr is the same as search, this function returns result. This function takes arguments of both numeric and character data types. There can be up to 255 arguments among expr, search, result, and default.
A detailed description of the DECODE function is as follows:
-
Syntax

-
Component
Component Description expr Should be the same data type or a compatible type as search. search Compared with expr.
search should be the same data type as the first search argument or a compatible type.
result Return value when matched with search.
All result arguments should either be the same type as the first result argument or a compatible type.
default If expr does not match any value of search, default will be returned.
If default is not specified, NULL will be returned.
default should be the same data type as the first result argument or a compatible type.
-
Example
The following example shows how to use the DECODE function.
SQL> SELECT DECODE('1', 1, 'Male', 2, 'Female') FROM DUAL; DECODE('1',1,'MALE',2,'FEMALE') ------------------------------- Male 1 row selected.
DECOMPOSE decomposes a Unicode string str and returns the decomposed string.
A detailed description of the DECOMPOSE function is as follows:
-
Syntax

-
Component
Component Description str An expression that returns a string. CANONICAL If CANONICAL is specified, this function performs canonical decomposition, which allows recomposition of the original string. COMPATIBILITY If COMPATIBILITY is specified, this function performs decomposition in compatibility mode. In this mode, recomposition is not possible. -
Example
The following example shows how to use the DECOMPOSE function.
SQL> SELECT DECOMPOSE('Chteaux') FROM DUAL; DECOMPOSE('Chteaux') ------------------------------------------------------------- Cha^teaux 1 row selected.
DELETEXML removes one or more nodes specified with an XPath expression from XML.
A detailed description of the DELETEXML function is as follows:
-
Syntax
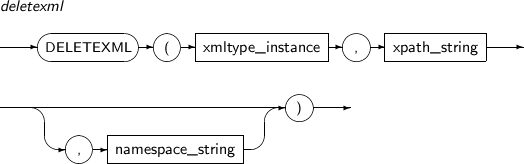
-
Component
Component Description xmltype_instance An XMLType instance. xpath_string Specifies the location of an XML element to be deleted with the XPath expression. namespace_string Provides namespace information for xpath_string. This must be a VARCHAR. -
Example
The following example shows how to use the DELETEXML function.
SQL> UPDATE warehouses SET warehouse_spec = DELETEXML(warehouse_spec, '/Warehouse/Building/Owner') WHERE warehouse_id = 2; SQL> SELECT warehouse_id, warehouse_spec FROM warehouses WHERE warehouse_id in (2,3); ID WAREHOUSE_SPEC ---------- ----------------------------------- 2 <Warehouse> <Building>Rented</Building> <Area>50000</Area> <Docks>1</Docks> <DockType>Side load</DockType> <WaterAccess>Y</WaterAccess> <RailAccess>N</RailAccess> <Parking>Lot</Parking> <VClearance>12 ft</VClearance> </Warehouse> 3 <Warehouse> <Building>Rented <Owner>Grandco</Owner> <Owner>ThirdOwner</Owner> <Owner>LesserCo</Owner> </Building> <Area>85700</Area> <DockType/> <WaterAccess>N</WaterAccess> <RailAccess>N</RailAccess> <Parking>Street</Parking> <VClearance>11.5 ft</VClearance> </Warehouse>
DENSE_RANK sorts grouped rows and returns the rank of each row in a group. This function can be used as an analytic function.
The returned ranks have the following characteristics:
-
The data type is a NUMBER.
-
The ranks are consecutive integers starting from 1.
-
The maximum rank is the number of unique values in the group of rows.
-
When there is a duplicate value, the next rank value is equal to the previous value plus one.
-
Rows with duplicate values have the same rank.
Depending on how this function is used, the calculation method is different:
A detailed description of the DENSE_RANK function is as follows:
-
Syntax


-
Component
-
dense_rank_aggregation
Component Description expr An expression. order_by_clause Specifies how to sort rows in a single partition.
For detailed information, see order_by_clause in “4.1.3. Analytic Functions”.
-
dense_rank_analytic
Component Description partition_by Partitions the result set of the current query block based on expr.
For detailed information, see partition_by in “4.1.3. Analytic Functions”.
order_by_clause Specifies how to sort rows in a single partition.
For detailed information, see order_by_clause in “4.1.3. Analytic Functions”.
-
-
Example
The following example shows how to use the DENSE_RANK function.
SQL> SELECT DEPTNO, DENSE_RANK(3000) WITHIN GROUP (ORDER BY SAL) AS DENSE_RANK FROM EMP GROUP BY DEPTNO; DEPTNO DENSE_RANK ---------- ---------- 10 3 20 4 30 6 3 rows selected. -
Example (Analytic Function)
The following example shows how to use the DENSE_RANK function as an analytic function.
SQL> SELECT NAME, DEPTID, SALARY, DENSE_RANK() OVER (PARTITION BY DEPTID ORDER BY SALARY) FROM EMP; NAME DEPTID SALARY DENSE_RANK -------------------- ---------- ---------- ---------- Paul 1 3000 1 Angela 1 3000 1 Nick 1 3200 2 Scott 1 4000 3 James 1 4000 3 John 1 4500 4 Joe 2 4000 1 Brad 2 4200 2 Daniel 2 5000 3 Tom 2 5000 3 Kathy 2 5000 3 Bree 2 6000 4 12 rows selected.
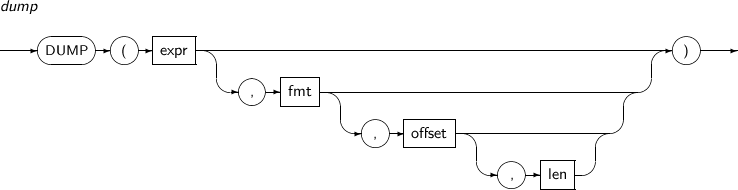
DUMP returns the internal representation information for expr. This function returns a VARCHAR2 that contains the length and a byte stream. This function does not support LONG, CLOB, or BLOB.
A detailed description of the DUMP function is as follows:
-
Syntax
-
Component
Component Description expr An expression. fmt Specifies the format of a byte stream. The default value is 10.
The following notations are available:
-
8: Octal notation
-
10: Decimal notation (The default value)
-
16: Hexadecimal notation
-
17: String expression
offset Specifies the start offset. len Specifies the length of a byte stream to be returned.
If expr is NULL, NULL is returned.
-
-
Example
The following example shows how to use the DUMP function.
SQL> SELECT DUMP(100) FROM DUAL; DUMP(100) ---------------- Len=2: 302,201 1 row selected.
EMPTY_BLOB returns an empty LOB locator to initialize BLOB columns.
A detailed description of the EMPTY_BLOB function is as follows:
-
Syntax
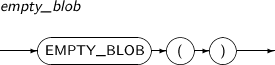
-
Example
The following example shows how to use the EMPTY_BLOB function.
SQL> UPDATE EMP SET PHOTO = EMPTY_BLOB();
EMPTY_CLOB returns an empty LOB locator to initialize CLOB columns.
A detailed description of the EMPTY_CLOB function is as follows:
-
Syntax

-
Example
The following example shows how to use the EMPTY_CLOB function.
SQL> UPDATE NOVEL SET CONTENTS = EMPTY_CLOB();
EXISTSNODE checks whether a node exists at an XPath in an XML document. It returns a NUMBER with a value of 1 if the node exists or 0 if it does not exist.
A detailed description of the EXISTSNODE function is as follows:
-
Syntax
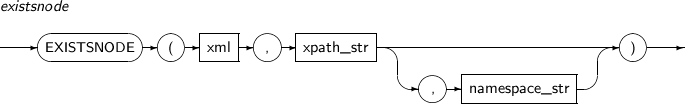
-
Component
Component Description xml XML document to be queried. The document is an XMLtype. xpath_str An XPath string to query. The maximum length is 4,000 characters. namespace_str Optional parameter to specify a namespace for the XML document.
This is a VARCHAR.
-
Example
The following example shows how to use the EXISTSNODE function.
SQL> SELECT EXTRACT(employee_xmldoc, '/employee/department/dname') dname FROM employee_xml WHERE EXISTSNODE(employee_xmldoc, '/employee/department/dname') = 1; dname --------------------- <dname>DB Lab</dname> 1 row selected.
EXP computes e (= 2.7182818284…), the base of the natural log, raised to the power of num.
A detailed description of the EXP function is as follows:
-
Syntax

-
Component
Component Description num An expression that returns a numeric value. Should be a NUMBER or a compatible type. If the type of num is BINARY FLOAT, it returns BINARY DOUBLE type. Otherwise, it returns the same type as num.
-
Example
The following example shows how to use the EXP function.
SQL> SELECT EXP(2.0) FROM DUAL; EXP(2.0) ---------- 7.3890561 1 row selected.
EXTRACT extracts a specific value from datetime or interval values. The return value is in the Gregorian calendar. The desired value to extract must be in the source expression.
A detailed description of the EXTRACT function is as follows:
-
Syntax

-
Component
Component Description YEAR A data type that holds years. MONTH A data type that holds months. DAY A data type that holds dates. HOUR A data type that holds hours. MINUTE A data type that holds minutes. SECOND A data type that holds seconds. TIMEZONE_HOUR A data type that holds time zone offset hours. TIMEZONE_MINUTE A data type that holds time zone offset minutes. TIMEZONE_REGION A data type that holds time zone region names. TIMEZONE_ABBR A data type that holds abbreviations for time zone daylight saving time.
-
Example
The following example shows how to use the EXTRACT function.
SQL> SELECT EXTRACT (MONTH FROM DATE'1996-04-01') FROM DUAL; EXTRACT(MONTHFROMDATE'1996-04-01') ---------------------------------- 4 1 row selected.
EXTRACT(XML) returns an XML node corresponding to an XPath in an XML document.
A detailed description of the EXTRACT(XML) function is as follows:
-
Syntax

-
Component
Component Description xml An XML document to be queried. This is an XMLType. xpath_str An XPath string to query. The maximum length is 4,000 characters. namespace_str An optional parameter to specify a namespace for the XML document.
This is a VARCHAR.
-
Example
The following example shows how to use the EXTRACT(XML) function.
SQL> SELECT EXTRACT(employee_xmldoc, '/employee/department/dname') dname FROM employee_xml; dname --------------------- <dname>DB Lab</dname> 1 row selected.
EXTRACTVALUE returns a VARCHAR corresponding to an XPath in an XML document.
A detailed description of the EXTRACTVALUE function is as follows:
-
Syntax

-
Component
Component Description xml An XML document of the XMLType to be queried. xpath_str An XPath string to query. The maximum length is 4,000 characters. namespace_str Optional parameter to specify a namespace for the XML document.
It is a VARCHAR.
-
Example
The following example shows how to use the EXTRACTVALUE function.
SQL> SELECT EXTRACTVALUE(employee_xmldoc, '/employee/department/dname') dname FROM employee_xml; dname ------ DB Lab 1 row selected.
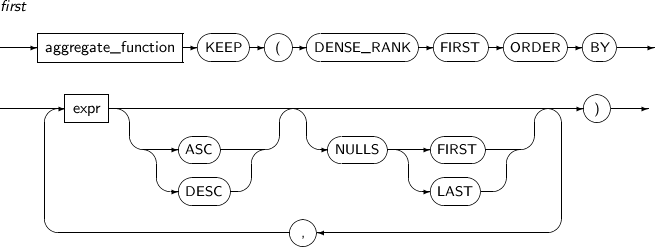
FIRST extracts the first row among sorted rows, applies a specified aggregate function to the row, and then returns it. Currently, it cannot be used as an analytic function.
A detailed description of the FIRST function is as follows:
-
Syntax
-
Component
Component Description aggregate_function The following aggregate functions can be used: AVG, COUNT, MIN, MAX, SUM, STDDEV, and VARIANCE. expr An expression.
-
Example
The following example shows how to use the FIRST function.
SQL> SELECT MIN(COMM) KEEP (DENSE_RANK FIRST ORDER BY SAL), MAX(COMM) KEEP (DENSE_RANK FIRST ORDER BY SAL) FROM EMP WHERE JOB = 'SALESMAN'; MIN(COMM)KEEP(DENSE_RANKFIRSTORDERBYSAL) MAX(COMM)KEEP(DENSE_RANKFIRSTORDERBYSAL) ---------------------------------------- ---------------------------------------- 500 1400 1 row selected.
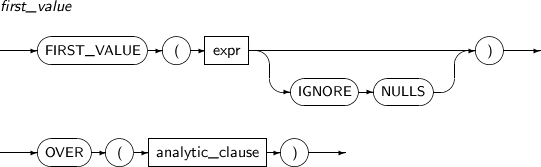
FIRST_VALUE is an analytic function that returns the first row value among sorted rows. If IGNORE NULLS is specified, this function returns the first row that is not NULL. If every row is NULL, NULL is returned.
A detailed description of the FIRST_VALUE function is as follows:
-
Syntax
-
Component
Component Description expr An expression.
-
Example
The following example shows how to use the FIRST_VALUE function.
SELECT DEPTNO, ENAME, SAL, FIRST_VALUE(ENAME) OVER (PARTITION BY DEPTNO ORDER BY SAL ASC ROWS UNBOUNDED PRECEDING) AS LOWEST_SAL FROM EMP; DEPTNO ENAME SAL LOWEST_SAL ---------- ---------- ---------- ---------- 10 MILLER 1300 MILLER 10 CLARK 2450 MILLER 10 KING 5000 MILLER 20 SMITH 800 SMITH 20 ADAMS 1100 SMITH 20 JONES 2975 SMITH 20 SCOTT 3000 SMITH 20 FORD 3000 SMITH 30 JAMES 950 JAMES 30 WARD 1250 JAMES 30 MARTIN 1250 JAMES 30 TURNER 1500 JAMES 30 ALLEN 1600 JAMES 30 BLAKE 2850 JAMES 14 rows selected.
FLOOR returns the largest integer less than or equal to num.
A detailed description of the FLOOR function is as follows:
-
Syntax
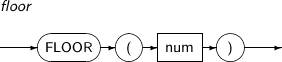
-
Component
Component Description num An expression that returns a numeric value.
-
Example
The following example shows how to use the FLOOR function.
SQL> SELECT FLOOR(15.5), FLOOR(-15.5), FLOOR(25.0) FROM DUAL; FLOOR(15.5) FLOOR(-15.5) FLOOR(25.0) ----------- ------------ ----------- 15 -16 25 1 row selected.
FROM_TZ converts a given TIMESTAMP, timestamp_value, and time zone, timezone_value, to a TIMESTAMP WITH TIME ZONE.
A detailed description of the FROM_TZ function is as follows:
-
Syntax

-
Component
Component Description timestamp_value An expression that returns a time value. timezone_value An expression that returns a time zone region name or an offset.
-
Example
The following example shows how to use the FROM_TZ function.
SQL> SELECT FROM_TZ(TIMESTAMP '2002/01/24 08:48:53', '8:00') FROM DUAL; FROM_TZ(TIMESTAMP'2002/01/2408:48:53','8:00') --------------------------------------------- 2002/01/24 08:48:53.000000 +08:00 1 row selected.
GETBLOBVAL returns a given XML type as a BLOB.
A detailed description of the GETBLOBVAL function is as follows:
-
Syntax

-
Component
Component Description xml XML type to convert to BLOB.
csid ID of the characterset used for the conversion.
-
Example
The following example shows how to use the GETBLOBVAL function.
SQL> SELECT GETBLOBVAL(XMLTYPE('<a>1</a>'), NLS_CHARSET_ID('MSWIN949')) FROM DUAL; GETBLOBVAL(XMLTYPE('<A>1</A>'),NLS_CHARSET_ID('MSWIN949')) -------------------------------------------------------------------------------- 3C613E313C2F613E 1 row selected.
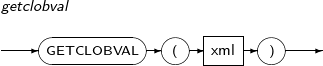
GETCLOBVAL returns a given XML type as a CLOB.
A detailed description of the GETCLOBVAL is as follows:
-
Syntax
-
Component
Component Description xml XML type to convert to CLOB.
-
Example
The following example shows how to use the GETCLOBVAL function.
SQL> SELECT GETCLOBVAL(XMLTYPE('<a>1</a>')) FROM DUAL; GETCLOBVAL(XMLTYPE('<A>1</A>')) -------------------------------------------------------------------------------- <a>1</a> 1 row selected.
GETROOTELEMENT returns the root element of an XML type instance as VARCHAR type.
A detailed description of the GETROOTELEMENT is as follows:
-
Syntax

-
Component
Component Description xml XML type instance.
-
Example
The following example shows how to use the GETROOTELEMENT function.
SQL> SELECT GETROOTELEMENT(XMLTYPE('<a>1</a>')) FROM DUAL; GETROOTELEMENT(XMLTYPE('<A>1</A>')) -------------------------------------------------------------------------------- a 1 row selected.
GETSTRINGVAL returns an XML type as VARCHAR type.
A detailed description of the GETSTRINGVAL is as follows:
-
Syntax

-
Component
Component Description xml VARCHAR 타입으로 변환하고자 하는 XML 타입 객체이다.
-
Example
The following example shows how to use the GETSTRINGVAL function.
SQL> SELECT GETSTRINGVAL(XMLTYPE('<a>1</a>')) FROM DUAL; GETSTRINGVAL(XMLTYPE('<A>1</A>')) -------------------------------------------------------------------------------- <a>1</a> 1 row selected.
GREATEST returns the greatest value in expr.
A detailed description of the GREATEST function is as follows:
-
Syntax
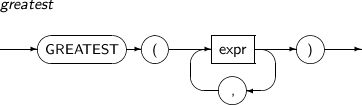
-
Component
Component Description expr An expression. The return value is the same as the first value of expr.
All occurrences of expr should be the same type or a compatible type with the first expr argument.
If any expr is NULL, this function returns NULL.
-
Example
The following example shows how to use the GREATEST function.
SQL> SELECT GREATEST(1, 3, 2) FROM DUAL; GREATEST(1,3,2) --------------- 3 1 row selected.
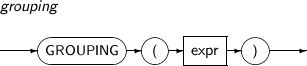
GROUPING distinguishes between superaggregate rows and regular grouped rows. ROLLUP and CUBE create superaggregate rows where the set of all values is represented as NULL. Using the GROUPING function can distinguish a NULL used to represent all values in a superaggregate row from a NULL in a regular row. If the value of an expression is NULL, this function returns 1. Otherwise, it returns 0. The return value is a NUMBER.
A detailed description of the GROUPING function is as follows:
-
Syntax
-
Component
Component Description expr Must match one of the expressions in a GROUP BY clause.
-
Example
The following example shows how to use the GROUPING function.
SQL> SELECT DECODE(GROUPING(DNO),1,'ALL',DNO) AS DNO, DECODE(GROUPING(JOB),1,'ALL',JOB) AS JOB, SUM(PAY) AS PAY FROM PERSONNEL GROUP BY CUBE(DNO, JOB) ORDER BY DNO, JOB; DNO JOB PAY ---------- -------------------- ---------- 10 ANALYST 5950 10 MANAGER 1000 10 PRESIDENT 7000 10 ALL 13950 20 CLERK 4000 20 MANAGER 3974 20 ALL 7974 30 MANAGER 3550 30 SALESMAN 4250 30 ALL 7800 ALL ANALYST 5950 ALL CLERK 4000 ALL MANAGER 8524 ALL PRESIDENT 7000 ALL SALESMAN 4250 ALL ALL 29724 16 rows selected.
GROUPING_ID returns a number corresponding to the GROUPING bit vector of a row.
Using the GROUPING_ID function is the same as using multiple GROUPING functions and concatenating the functions' results into a bit vector. By using the GROUPING_ID function, a row filtering condition is expressed more simply by avoiding multiple GROUPING functions. Row filtering using GROUPING_ID can be easily processed with a condition such as GROUPING_ID = n.
The GROUPING_ID function can be used only in a SELECT statement that contains a GROUPING function, ROLLUP, or CUBE. If a query uses GROUP BY multiple times, GROUPING functions should be used multiple times to determine the GROUP BY level of a specific row, which generates a complex SQL statement. In this case, the GROUPING_ID function is particularly useful.
A detailed description of the GROUPING_ID function is as follows:
-
Syntax

-
Component
Component Description expr Must match one of the expressions in a GROUP By clause.
-
Example
The following example shows how to use the GROUPING_ID function.
SQL> SELECT DECODE(GROUPING(DNO),1,'ALL',DNO) AS DNO, DECODE(GROUPING(JOB),1,'ALL',JOB) AS JOB, GROUPING(DNO) AS GD, GROUPING(JOB) AS GJ, GROUPING_ID(DNO, JOB) AS DJ, GROUPING_ID(DNO, JOB) AS JD, SUM(PAY) AS PAY FROM PERSONNEL GROUP BY CUBE(DNO, JOB) ORDER BY DNO, JOB; DNO JOB GD GJ DJ JD PAY ---------- -------------------- ---- ---- ---- ---- ---------- 10 ANALYST 0 0 0 0 5950 10 MANAGER 0 0 0 0 1000 10 PRESIDENT 0 0 0 0 7000 10 ALL 0 1 1 2 13950 20 CLERK 0 0 0 0 4000 20 MANAGER 0 0 0 0 3974 20 ALL 0 1 1 2 7974 30 MANAGER 0 0 0 0 3550 30 SALESMAN 0 0 0 0 4250 30 ALL 0 1 1 2 7800 ALL ANALYST 1 0 2 1 5950 ALL CLERK 1 0 2 1 4000 ALL MANAGER 1 0 2 1 8524 ALL PRESIDENT 1 0 2 1 7000 ALL SALESMAN 1 0 2 1 4250 ALL ALL 1 1 3 3 29724 16 rows selected.
GROUP_ID distinguishes duplicate groups in a result of GROUP BY. This function is useful for filtering out duplicate groups from a query result. It returns a NUMBER to identify duplicate row groups. This function can only be used in a SELECT statement that contains a GROUP BY clause.
A detailed description of the GROUP_ID function is as follows:
-
Syntax
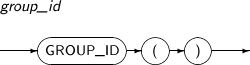
-
Example
The following example shows how to use the GROUP_ID function.
SQL> SELECT depart_num, group_id() FROM employees GROUP BY depart_num; DEPART_NUM GROUP_ID() ------------- ---------- 10 1 20 0 30 0 3 rows selected.
HEXTORAW returns a RAW corresponding to a hexadecimal format string, str.
A detailed description of the HEXTORAW function is as follows:
-
Syntax
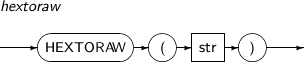
-
Component
Component Description str An expression that returns a hexadecimal format string.
-
Example
The following example creates a table containing a RAW column and inserts a hexadecimal value into the column by using the HEXTORAW function.
SQL> SELECT HEXTORAW(UTL_RAW.CAST_TO_RAW('DB')) COL FROM DUAL; COL ------------------------- 4442 1 row selected.
INET_ATON takes a network address expr and returns a numeric value corresponding to the address. Both 4 and 8 byte addresses are available.
To save a value returned by the INET_ATON function, use UNSIGNED INT. If SIGNED INT is used, the value is not saved correctly if the first octet of the address is greater than 127.
A detailed description of the INET_ATON function is as follows:
-
Syntax

-
Component
Component Description expr A string that contains a network address.
-
Example
The following example shows how to use the INET_ATON function.
SQL> SELECT INET_ATON('123.255.0.1') FROM DUAL; INET_ATON('123.255.0.1') ------------------------ 2080309249 1 row selected.
INET_NTOA takes a network address expr and returns a string value corresponding to the address.
A detailed description of the INET_NTOA function is as follows:
-
Syntax

-
Component
Component Description expr A numeric value that contains a network address.
-
Example
The following example shows how to use the INET_NTOA function.
SQL> SELECT INET_NTOA(2080309249) FROM DUAL; INET_NTOA(2080309249) -------------------------------------------------------------------- 123.255.0.1 1 row selected.
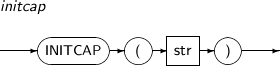
INITCAP returns str with the first letter of each word in uppercase and every other letter in lowercase.
A detailed description of the INITCAP function is as follows:
-
Syntax
-
Component
Component Description str An expression that returns a string. -
Example
The following example shows how to use the INITCAP function.
SQL> SELECT INITCAP('tiBero') FROM DUAL; INITCAP('TIBERO') ----------------- Tibero 1 row selected.
INSERTCHILDXML inserts a user-input XML value into a child node of the node specified by the XPath expression xpath_string. Compare this function with the INSERTXMLBEFORE function.
A detailed description of the INSERTCHILDXML function is as follows:
-
Syntax
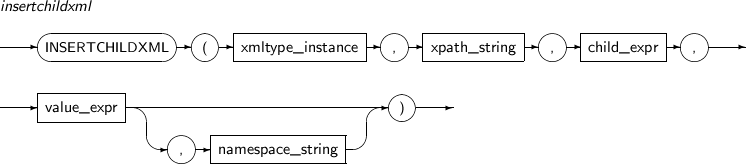
-
Component
Component Description XMLType_instance An expression that returns an XMLType instance. XPath_string An XPath expression that specifies the location into which one or more child nodes are inserted. child_expr An expression that represents the properties or elements of a child node to be inserted. value_expr An expression that represents one or more XMLType child nodes to be inserted. This expression must be a value that can be converted to a string. namespace_string Provides namespace information for xpath_string. This must be a VARCHAR. -
Example
The following example shows how to use the INSERTCHILDXML function.
... INFO column '<dept>research</dept>' ... SQL> UPDATE EMP SET INFO = INSERTCHILDXML(INFO, '/dept', 'id', XMLTYPE('<id>1</id>')); SQL> SELECT INFO FROM EMP; EMP ------------------------------------------- <dept>research<id>1</id></dept>
INSERTCHILDXMLAFTER inserts a user-input XML value to a node specified by the XPath expression xpath_string. The node is inserted after any existing child nodes.
A detailed description of the INSERTCHILDXMLAFTER function is as follows:
-
Syntax

-
Component
Component Description xmltype_instance An expression that returns an XMLType instance. xpath_string An XPath expression that specifies the location into which one or more child nodes are inserted. child_expr An expression that represents the properties or elements of a child node to be inserted. value_expr An expression that represents one or more XMLType child nodes to be inserted. This expression must be a value that can be converted to a string. namespace_string Provides namespace information for xpath_string. This must be a VARCHAR. -
Example
The following example shows how to use the INSERTCHILDXMLAFTER function.
... INFO column '<dept><id>1</id></dept>' ... SQL> UPDATE EMP SET INFO = INSERTCHILDXMLAFTER(INFO, '/dept', 'id[1]', XMLTYPE('<id>2</id>')); SQL> SELECT INFO FROM EMP; EMP ------------------------------------------- <dept><id>1</id><id>2</id></dept>
INSERTCHILDXMLBEFORE inserts a user-input XML value to a node specified by the XPath expression xpath_string. The node is inserted before any existing child nodes.
A detailed description of the INSERTCHILDXMLBEFORE function is as follows:
-
Syntax
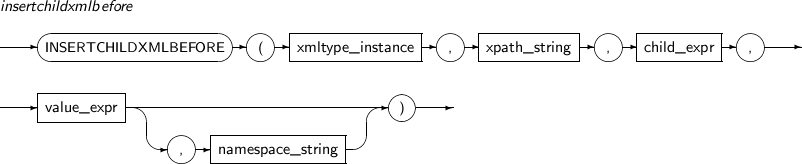
-
Component
Component Description xmltype_instance An expression that returns an XMLType instance. xpath_string An XPath expression that specifies the location into which one or more child nodes are inserted. child_expr An expression that represents the properties or elements of a child node to be inserted. value_expr An expression that represents one or more XMLType child nodes to be inserted. This expression must be a value that can be converted to a string. namespace_string Provides namespace information for xpath_string. This must be a VARCHAR. -
Example
The following example shows how to use the INSERTCHILDXMLBEFORE function.
... INFO column '<dept><id>1</id></dept>' ... SQL> UPDATE EMP SET INFO = INSERTCHILDXMLBEFORE(INFO, '/dept', 'id[1]', XMLTYPE('<id>2</id>')); SQL> SELECT INFO FROM EMP; EMP ------------------------------------------- <dept><id>2</id><id>1</id></dept>
INSERTXMLAFTER inserts a user-input XML value to a node specified by the XPath expression xpath_string. The node is inserted after any existing nodes.
A detailed description of the INSERTXMLAFTER function is as follows:
-
Syntax
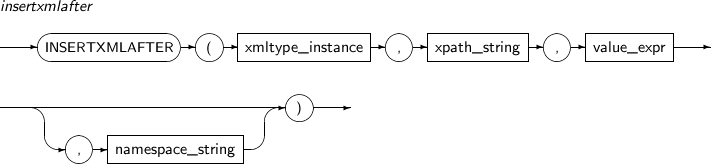
-
Component
Component Description xmltype_instance An expression that returns an XMLType instance. xpath_string An XPath expression that specifies the location into which one or more child nodes are inserted. value_expr An expression that represents one or more XMLType child nodes to be inserted. This expression must be a value that can be converted to a string. namespace_string Provides namespace information for xpath_string. This must be a VARCHAR. -
Example
The following example shows how to use the INSERTXMLAFTER function.
... INFO column '<dept>research</dept>' ... SQL> UPDATE EMP SET INFO = INSERTXMLAFTER(INFO, '/dept', XMLTYPE('<dept>sales</dept>')); SQL> SELECT INFO FROM EMP; EMP ------------------------------------------- <dept>research</dept> <dept>sales</dept>
INSERTXMLBEFORE inserts a user-input XML value to a node specified by the XPath expression xpath_string. The node is inserted before any existing nodes.
A detailed description of the INSERTXMLBEFORE function is as follows:
-
Syntax

-
Component
Component Description xmltype_instance An expression that returns an XMLType instance. xpath_string An XPath expression that specifies the location into which one or more child nodes are inserted. value_expr An expression that represents one or more XMLType child nodes to be inserted. This expression must be a value that can be converted to a string. namespace_string Provides namespace information for xpath_string. This must be a VARCHAR. -
Example
The following example shows how to use the INSERTXMLBEFORE function.
... INFO column '<dept>research</dept>' ... SQL> UPDATE EMP SET INFO = INSERTXMLBEFORE(INFO, '/dept', XMLTYPE('<dept>sales</dept>')); SQL> SELECT INFO FROM EMP; EMP ------------------------------------------- <dept>sales</dept> <dept>research</dept>
INSTR searches for substr in str, and returns the position.
Alternatively, INSTRB computes the position in bytes rather than in characters, and returns the position.
A detailed description of the INSTR and INSTRB functions follows:
-
Syntax

-
Component
Component Description str, substr Expressions that return a string.
If substr is not found in str, this function returns 0.
The first character in a string has a position of 1.
position An expression that returns a nonzero integer.
If this is specified, the search begins from the given position in str.
If this is a negative value, the search begins from the end of str.
Defaults to 1.
occurrence An expression that returns a nonzero integer.
If this is specified, the function will return the position of the nth occurrence of substr in str.
This must be a positive integer. Defaults to 1.
-
Example
The following example shows how to use the INSTR function.
SQL> select isfragment(XMLTYPE('<a><b>1</b></a>')) from dual; ISFRAGMENT(XMLTYPE('<A><B>1</B></A>')) -------------------------------------- 0 1 row selected. SQL> select isfragment(XMLCONCAT(XMLTYPE('<a>1</a>'), XMLTYPE('<b>2</b>'))) from dual; ISFRAGMENT(XMLCONCAT(XMLTYPE('<A>1</A>'),XMLTYPE('<B>2</B>'))) -------------------------------------------------------------- 1 1 row selected.
ISFRAGMENT returns 1 if xmltype_instance is a fragment, but it returns 0 if it is a well-formed document.
A detailed description of the ISFRAGMENT function is as follows:
-
Syntax

-
Component
Component Description xmltype_instance XML document to be queried. This is an XML type. -
Example
The following example shows how to use the ISFRAGMENT function.
SQL> select isfragment(XMLTYPE('<a><b>1</b></a>')) from dual; ISFRAGMENT(XMLTYPE('<A><B>1</B></A>')) -------------------------------------- 0 1 row selected. SQL> select isfragment(XMLCONCAT(XMLTYPE('<a>1</a>'), XMLTYPE('<b>2</b>'))) from dual; ISFRAGMENT(XMLCONCAT(XMLTYPE('<A>1</A>'),XMLTYPE('<B>2</B>'))) -------------------------------------------------------------- 1 1 row selected.
KURT computes the kurtosis of expr. The return value is of a numeric type or a converted numeric data type.
A detailed description of the KURT function is as follows:
-
Syntax
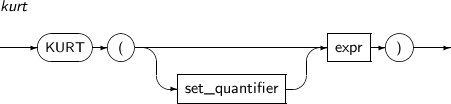
-
Component
Component Description set_quantifier Specifies whether to allow duplicate rows of a query result. The value is one of the following:
-
DISTINCT, UNIQUE: Removes duplicate rows.
-
ALL: Includes all rows. This is the default value.
expr An expression that is of a numeric data type or a compatible type. -
-
Example
The following example shows how to use the KURT function.
SQL> SELECT KURT(SAL) FROM EMP; KURT(SAL) ---------- 1.31945327 1 row selected.
LAG is an analytic function that enables access to more than one row of a table at the same time without a self join. This function provides access to a row that is offset rows before the current position.
A detailed description of the LAG function is as follows:
-
Syntax

-
Component
Component Description expr Cannot contain a nested analytic function.
offset The number of rows before the current row to access. Defaults to 1. default If offset is beyond the scope of the window, default is returned.
If default is not set, NULL is returned.
partition_by Partitions the result set of the current query block based on expr.
For detailed information, see partition_by in “4.1.3. Analytic Functions”.
order_by_clause Specifies how to sort rows in a single divided partition.
For detailed information, see order_by_clause in “4.1.3. Analytic Functions”.
-
Example
The following example shows how to use the LAG function.
SQL> SELECT NAME, DEPTID, SALARY, LAG (SALARY, 2, 0) OVER (PARTITION BY DEPTID ORDER BY SALARY) PSAL FROM EMP; NAME DEPTID SALARY PSAL -------------------- ---------- ---------- ---------- Paul 1 3000 0 Angela 1 3000 0 Nick 1 3200 3000 Scott 1 4000 3000 James 1 4000 3200 John 1 4500 4000 Joe 2 4000 0 Brad 2 4200 0 Daniel 2 5000 4000 Tom 2 5000 4200 Kathy 2 5000 5000 Bree 2 6000 5000 12 rows selected.
LAST_DAY returns the date of the last day of the month which contains date.
A detailed description of the LAST_DAY function is as follows:
-
Syntax
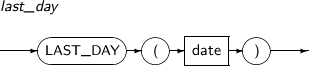
-
Component
Component Description date An expression that returns a date. -
Example
The following example shows how to use the LAST_DAY function.
SQL> SELECT LAST_DAY('2005/06/22') FROM DUAL; LAST_DAY('2005/06/22') ----------------------------------------------------------------- 2005-06-30 1 row selected.
LAST extracts the last row among sorted rows, applies a specified aggregate function to the row, and then returns it. Currently, it cannot be used as an analytic function.
A detailed description of the LAST function is as follows:
-
Syntax
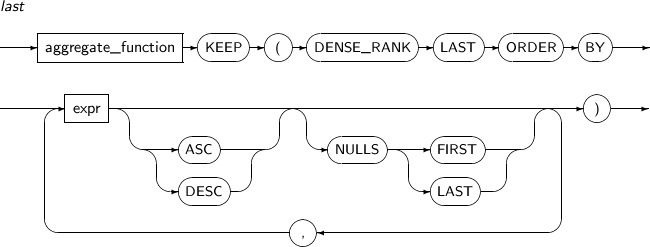
-
Component
Component Description aggregate_function The following aggregate functions can be used: AVG, COUNT, MIN, MAX, SUM, STDDEV, and VARIANCE. expr An expression.
-
Example
The following example shows how to use the LAST function.
SQL> SELECT DEPTNO, MIN(HIREDATE) KEEP (DENSE_RANK LAST ORDER BY SAL) MIN_HIREDATE, MAX(HIREDATE) KEEP (DENSE_RANK LAST ORDER BY SAL) MAX_HIREDATE FROM EMP GROUP BY DEPTNO; DEPTNO MIN_HIREDATE MAX_HIREDATE ---------- -------------------------------- -------------------------------- 10 1981/11/17 1981/11/17 20 1981/12/03 1987/04/19 30 1981/05/01 1981/05/01 3 rows selected.
LAST_VALUE returns the last row value among sorted rows as an analytic function. If IGNORE NULLS is specified, this function returns the last row that is not NULL. If every row is NULL, NULL is returned.
A detailed description of the LAST_VALUE function is as follows:
-
Syntax
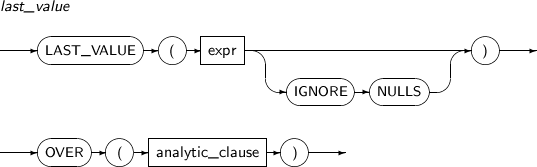
-
Component
Component Description expr An expression.
-
Example
The following example shows how to use the LAST_VALUE function.
SELECT DEPTNO, ENAME, LAST_VALUE(ENAME) OVER (PARTITION BY DEPTNO ORDER BY HIREDATE ASC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS NEW_EMP FROM EMP; DEPTNO ENAME NEW_EMP ---------- ---------- ---------- 10 CLARK MILLER 10 KING MILLER 10 MILLER MILLER 20 SMITH ADAMS 20 JONES ADAMS 20 FORD ADAMS 20 SCOTT ADAMS 20 ADAMS ADAMS 30 ALLEN JAMES 30 WARD JAMES 30 BLAKE JAMES 30 TURNER JAMES 30 MARTIN JAMES 30 JAMES JAMES 14 rows selected.
LEAD is an analytic function that enables access to more than one row of a table at the same time without a self join. This function provides access to a row that is offset rows after the current position.
A detailed description of the LEAD function is as follows:
-
Syntax

-
Component
Component Description expr Cannot contain a nested analytic function.
offset The number of rows after the current row to access. Defaults to 1. default If offset is beyond the scope of the window, default is returned.
If default is not set, NULL is returned.
partition_by Partitions the result set of the current query block based on expr.
For detailed information, see partition_by in “4.1.3. Analytic Functions”.
order_by_clause Specifies how to sort rows in a single divided partition.
For detailed information, see order_by_clause in “4.1.3. Analytic Functions”.
-
Example
The following example shows how to use the LEAD function.
SQL> SELECT NAME, DEPTID, SALARY, LEAD (SALARY, 2, 0) OVER (PARTITION BY DEPTID ORDER BY SALARY) PSAL FROM EMP; NAME DEPTID SALARY PSAL -------------------- ---------- ---------- ---------- Paul 1 3000 3200 Angela 1 3000 4000 Nick 1 3200 4000 Scott 1 4000 4500 James 1 4000 0 John 1 4500 0 Joe 2 4000 5000 Brad 2 4200 5000 Daniel 2 5000 5000 Tom 2 5000 6000 Kathy 2 5000 0 Bree 2 6000 0 12 rows selected.
LEAST returns the smallest value among expr.
A detailed description of the LEAST function is as follows:
-
Syntax
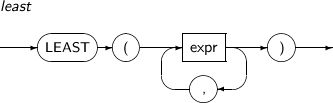
-
Component
Component Description expr An expression.
Each expr must be of a compatible type with the first parameter.
If any expr value is NULL, NULL is returned.
-
Example
The following example shows how to use the LEAST function.
SQL> SELECT LEAST(1, 3, 2) FROM DUAL; LEAST(1,3,2) ------------ 1 1 row selected.
LENGTH returns the length of a given string.
Alternatively, LENGTHB returns the length in bytes rather than in characters.
A detailed description of the LENGTH and LENGTHB functions follows:
-
Syntax

-
Component
Component Description str An expression that returns a string. -
Example
The following example shows how to use the LENGTH function.
SQL> SELECT LENGTH('ABCDEFG') FROM DUAL; LENGTH('ABCDEFG') ----------------- 7 1 row selected.
LISTAGG functions the same as “4.2.4. AGGR_CONCAT”. This was added for Oracle compatibility.
LISTAGG differs from AGGR_CONCAT:
-
Set_quantifier cannot be used.
-
Separator can be omitted, and the default value is null.
-
Order_by_clause is defined after WITHIN GROUP, and it cannot be omitted.
A detailed description of the LISTAGG functions follows:
-
Syntax

-
Components
Component Description expr Expression that returns a string or a string-compatible type. separator Character literal that is concatenated to expr. order_by_clause Sort method for strings that will be concatenated.
For more information, see order_by_clause in “4.1.3. Analytic Functions”.
-
Example
The following example shows how to use the LISTAGG function.
SQL> SELECT LISTAGG(ENAME, ',') WITHin GROUP (ORDER BY EMPNO) AS "EMPLOYEE" 2 FROM EMP 3 GROUP BY DEPTNO; EMPLOYEE -------------------------------------------------------------------------------- CLARK,KING,MILLER SMITH,JONES,SCOTT,ADAMS,FORD ALLEN,WARD,MARTIN,BLAKE,TURNER,JAMES 3 rows selected.
LN computes the natural logarithm of num.
A detailed description of the LN function is as follows:
-
Syntax
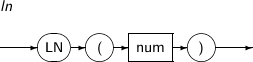
-
Component
Component Description num An expression that returns a real number greater than 0. Should be a NUMBER or a compatible type. If the type of num is BINARY FLOAT, it returns BINARY DOUBLE type. Otherwise, it returns the same numeric type as that of num. -
Example
The following example shows how to use the LN function.
SQL> SELECT TO_CHAR(LN(2.7182818284),'99') FROM DUAL; TO_CHAR(LN(2.7182818284),'99') ------------------------------ 1 1 row selected.
LNNVL returns TRUE if condition is FALSE or UNKNOWN, and returns FALSE if condition is TRUE. In practice, this function is rarely used directly, but may be added by the query optimizer.
A detailed description of the LNNVL function is as follows:
-
Syntax

-
Component
Component Description condition An expression. For detailed information on conditions, see “3.4. Conditional Expressions”. -
Example
The following example shows how to use the LNNVL function.
SQL> SELECT 1 FROM DUAL WHERE LNNVL (1 = 2); 1 ---------- 1 1 row selected.
LOCALTIMESTAMP returns the current date and time as a TIMESTAMP.
A detailed description of the LOCALTIMESTAMP function is as follows:
-
Syntax

-
Example
The following example shows how to use the LOCALTIMESTAMP function.
SQL> SELECT LOCALTIMESTAMP FROM DUAL; LOCALTIMESTAMP ------------------------------------- 2011/04/14 16:55:23.375613 1 row selected.
LOG computes the logarithm of num2 to base num1.
A detailed description of the LOG function is as follows:
-
Syntax

-
Component
Component Description num1, num2 Expressions that return a real number greater than 0. num1 must not be 1.
num1 and num2 are NUMBER or a compatible type.
If num1 or num2 is BINARY_FLOAT or BINARY_DOUBLE, it returns a BINARY_DOUBLE type. Otherwise it returns a NUMBER type.
-
Example
The following example shows how to use the LOG function.
SQL> SELECT LOG(2, 8) FROM DUAL; LOG(2,8) ---------- 3 1 row selected.
LOWER returns str with all letters in lowercase.
A detailed description of the LOWER function is as follows:
-
Syntax
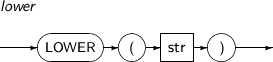
-
Component
Component Description str An expression that returns a string. -
Example
The following example shows how to use the LOWER function.
SQL> SELECT LOWER('ABCDEFG123') FROM DUAL; LOWER('ABCDEFG123') ------------------- abcdefg123 1 row selected.
LPAD pads the left side of expr1 with expr2 resulting in a new string with a maximum length of num.
In most character sets, the number of characters of a string to be returned is the same as the length. However, in the case of multibyte character sets such as Korean, the number of characters and the length can differ from each other.
A detailed description of the LPAD function is as follows:
-
Syntax

-
Component
Component Description expr1 An expression that returns a string, CLOB, or BLOB.
If expr1 is longer than num, this function returns the first num characters of expr1.
expr2 An expression that returns a string, CLOB, or BLOB.
If expr2 is not specified, blank spaces are used.
num An expression that returns a numeric value.
The length of the returned string.
-
Example
The following example shows how to use the LPAD function.
SQL> SELECT LPAD('LPAD', 10, '-=') FROM DUAL; LPAD('LPAD',10,'-=') -------------------- -=-=-=LPAD 1 row selected.
LTRIM removes any character included in char_set from the left end of str.
A detailed description of the LTRIM function is as follows:
-
Syntax
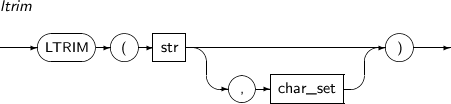
-
Component
Component Description str An expression that returns a string. char_set An expression that returns a string.
If not specified, the default value is a blank space.
-
Example
The following example shows how to use the LTRIM function.
SQL> SELECT LTRIM(' ABCDE') FROM DUAL; LTRIM('ABCDE') -------------- ABCDE 1 row selected. SQL> SELECT LTRIM('XYXABCDEXYX', 'XY') FROM DUAL; LTRIM('XYXABCDEXYX','XY') ------------------------- ABCDEXYX 1 row selected.
MAX returns the maximum value of expr for all rows in a group. This function can be used as an analytic function.
When this function is used as an analytic function, if DISTINCT is specified, only query_partiton_clause can be specified in analytic_clause, and order_by_clause cannot be specified.
A detailed description of the MAX function is as follows:
-
Syntax

-
Component
Component Description set_quantifier Specifies whether to allow duplicate rows. One of the following can be set:
-
DISTINCT, UNIQUE: Remove duplicate rows.
-
ALL: includes all rows. This is the default value.
expr An expression.
If DISTINCT is specified before expr, duplicate expr values are removed before calculating a maximum value.
analytic_clause This function can be used as an analytic function using "OVER analytic_clause".
For detailed information, see analytic_clause in “4.1.3. Analytic Functions”.
-
-
Example
The following example shows how to use the MAX function.
SQL> SELECT DEPTID, MAX(SALARY) FROM EMP2 GROUP BY DEPTID; DEPTID MAX(SALARY) ---------- ----------- 1 4500 2 6000 2 rows selected. -
Example (Analytic Function)
The following example shows how to use the MAX function as an analytic function.
SQL> SELECT NAME, DEPTID, SALARY, MAX(SALARY) OVER (PARTITION BY DEPTID) AS MSAL FROM EMP2; NAME DEPTID SALARY MSAL -------------------- ---------- ---------- ---------- Paul 1 3000 4500 Nick 1 3200 4500 Scott 1 4000 4500 John 1 4500 4500 Bree 2 6000 6000 Daniel 2 5000 6000 Joe 2 4000 6000 Brad 2 4200 6000 8 rows selected.
MEDIAN returns the median value of a group specified by expr. This function can be used as an analytic function. NULL values are ignored during the calculation.
The calculation method and result are the same as those of the PERCENTILE_CONT function with the argument 0.5.
A detailed description of the MEDIAN function is as follows:
-
Syntax

-
Component
Component Description expr An expression that returns a numeric value. analytic_clause This function can be used as an analytic function using "OVER analytic_clause".
For detailed information, see analytic_clause in “4.1.3. Analytic Functions”.
-
Example
The following example shows how to use the MEDIAN function.
SQL> SELECT DEPTNO, MEDIAN(SAL) FROM EMP AS MEDIAN GROUP BY DEPTNO; DEPTNO MEDIAN(SAL) ---------- ----------- 10 2450 20 2975 30 1375 3 rows selected. -
Example (Analytic Function)
The following example shows how to use the MEDIAN function as an analytic function.
SQL> SELECT DEPTNO, EMPNO, MEDIAN(SAL) OVER (PARTITION BY DEPTNO) AS MEDIAN FROM EMP; DEPTNO EMPNO MEDIAN ---------- ---------- ---------- 10 7934 2450 10 7782 2450 10 7839 2450 20 7369 2975 20 7876 2975 20 7566 2975 20 7788 2975 20 7902 2975 30 7900 1375 30 7521 1375 30 7654 1375 30 7844 1375 30 7499 1375 30 7698 1375 14 rows selected.
MIN returns the minimum value of expr for all rows in a group. This function can be used as an analytic function.
When this function is used as an analytic function, if DISTINCT is specified, only query_partiton_clause can be specified in analytic_clause, and order_by_clause cannot be specified.
A detailed description of the MIN function is as follows:
-
Syntax

-
Component
Component Description set_quantifier Specifies whether to allow duplicate rows. One of the following can be set:
-
DISTINCT, UNIQUE: Remove duplicate rows.
-
ALL: includes all rows. This is the default value.
expr An expression.
If DISTINCT is specified before expr, duplicate expr values are removed before calculating a minimum value.
analytic_clause This function can be used as an analytic function using "OVER analytic_clause".
For detailed information, see analytic_clause in “4.1.3. Analytic Functions”.
-
-
Example
The following example shows how to use the MIN function.
SQL> SELECT DEPTID, MIN(SALARY) FROM EMP2 GROUP BY DEPTID; DEPTID MIN(SALARY) ---------- ---------- 1 3000 2 4000 2 rows selected. -
Example (Analytic Function)
The following example shows how to use the MIN function as an analytic function.
SQL> SELECT NAME, DEPTID, SALARY, MIN(SALARY) OVER (PARTITION BY DEPTID) AS MSAL FROM EMP2; NAME DEPTID SALARY MSAL -------------------- ---------- ---------- ---------- Paul 1 3000 3000 Nick 1 3200 3000 Scott 1 4000 3000 John 1 4500 3000 Bree 2 6000 4000 Daniel 2 5000 4000 Joe 2 4000 4000 Brad 2 4200 4000 8 rows selected.
MOD returns the remainder of num1 divided by num2. This function returns a different result than the classic modulus function if one of the two numbers is a negative number.
The MOD function can be defined as follows:
MOD(num1, num2) = SIGN(num1) * MOD1(ABS(num1), ABS(num2))
In the above formula, MOD1 is the classic modulus function. When both num1 and num2 are positive, the function returns the same result as the MOD1 function. The SIGN function returns +1 when num1 is positive or -1 when it is negative. The ABS function returns the absolute values of num1 and num2.
A detailed description of the MOD function is as follows:
-
Syntax

-
Component
Component Description num1, num2 Expressions that return a numeric value.
Should be a NUMBER or a compatible type.
If the types of num1 and num2 do not match, the type with the higher priority is used for both components. The return value is also set to this type.
-
Example
The following example shows how to use the MOD function.
SQL> SELECT MOD(13, 5), MOD(13, -5), MOD(-13, 5), MOD(-13, -5) FROM DUAL; MOD(13,5) MOD(13,-5) MOD(-13,5) MOD(-13,-5) ---------- ---------- ---------- ---------- 3 3 -3 -3 1 row selected.
MONTHS_BETWEEN returns the number of months between date1 and date2. The fractional portion of the result is based on a 31-day month.
A detailed description of the MONTHS_BETWEEN function is as follows:
-
Syntax

-
Component
Component Description date1, date2 Expressions that return a date. -
Example
The following example shows how to use the MONTHS_BETWEEN function.
SQL> SELECT MONTHS_BETWEEN(LAST_DAY('2005/06/22'), '2005/06/22') FROM DUAL; MONTHS_BETWEEN(LAST_DAY('2005/06/22'),'2005/06/22') --------------------------------------------------- .258064516129032 1 row selected.
NANVL returns num1 if num1 is not NaN (Not A Number), but NANVL returns num2 if num1 is NaN.
A detailed description of the NANVL function is as follows:
-
Syntax
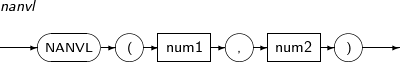
-
Component
Component Description num1, num2 Expression that return a numeric value.
Should be a NUMBER or a compatible type.
If the types of num1 and num2 do not match, the type with the higher priority is used for both components. The return value is also set to this type.
-
Example
The following example shows how to use the NANVL function.
SQL> SELECT NAME, INC_PCT FROM SALARY; NAME INC_PCT -------------------- ---------- Smith 1.34E+001 Jane NaN 2 rows selected. SQL> SELECT NAME, NANVL(INC_PCT, 0) INC_PCT FROM SALARY; NAME INC_PCT -------------------- ---------- Smith 1.34E+001 Jane 0 2 rows selected.
NEW_TIME returns a date and time in timezone2 converted from a date and time in timezone1.
A detailed description of the NEW_TIME function is as follows:
-
Syntax

-
Component
Component Description date An expression that return a date timezone1, timezone2 Expressions that return a time zone value. The following timezones can be used:
- AST, ADT: Atlantic Standard or Daylight Time
- BST, BDT: Bering Standard or Daylight Time
- CST, CDT: Central Standard or Daylight Time
- EST, EDT: Eastern Standard or Daylight Time
- GMT: Greenwich Mean Time
- HST, HDT: Alaska-Hawaii Standard or Daylight Time
- MST, MDT: Mountain Standard or Daylight Time
- NST: Newfoundland Standard Time
- PST, PDT: Pacific Standard or Daylight Time
- YST, YDT: Yukon Standard or Daylight Time
-
Example
The following example shows how to use the NEW_TIME function.
SQL> SELECT NEW_TIME(TO_DATE('1982/12/13 15:28:00', 'YYYY/MM/DD HH24:MI:SS'), 'EST', 'YST') NEW_TIME FROM DUAL; NEW_TIME -------------------------------- 1982/12/13 11:28:00 1 row selected.
NEXT_DAY returns the date of the next day of the week specified by str that occurs after date.
A detailed description of the NEXT_DAY function is as follows:
-
Syntax

-
Component
Component Description date An expression that returns a date. str A string that indicates a day of the week. -
Example
The following example shows how to use the NEXT_DAY function.
SQL> SELECT NEXT_DAY('2005/06/22', 'MONDAY') FROM DUAL; NEXT_DAY('2005/06/22','MONDAY') -------------------------------- 2005/06/27 1 row selected.
NLSSORT returns a string of bytes that can be used to sort str.
A detailed description of the NLSSORT function is as follows:
-
Syntax

-
Component
Component Description str A string value to be sorted.
This argument can be a CHAR, VARCHAR, NCHAR, and NVARCHAR.
nls_param Defines a character set used to sort str.
This argument can be a CHAR, VARCHAR, NCHAR, and NVARCHAR.
It can be defined in the form of 'NLS_SORT=sort'. If it is not specified, a value defined in a session is used.
-
Example
The following example shows how to use the NLSSORT function.
SQL> CREATE TABLE T (NAME VARCHAR(10)); SQL> INSERT INTO T VALUES('jclee'); SQL> INSERT INTO T VALUES(' voir'); SQL> SELECT NAME FROM T ORDER BY NLSSORT(NAME, 'NLS_SORT=german'); NAME ---------- voir jclee 2 rows selected.
NLS_CHARSET_ID returns the ID of the characterset specified by the characterset name argument.
A detailed description of the NLS_CHARSET_ID is as follows:
-
Syntax
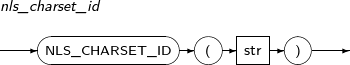
-
Component
Component Description str ID of the characterset specified by the characterset name argument.
Can be of CHAR, VARCHAR, NCHAR, or NVARCHAR type.
-
Example
The following example shows how to use the NLS_CHARSET_ID function.
SQL> SELECT NLS_CHARSET_ID('MSWIN949') FROM DUAL; NLS_CHARSET_ID('MSWIN949') -------------------------- 2 1 row selected.
NLS_INITCAP returns str with the first letter of each word in uppercase and all other letters in lowercase.
A detailed description of the NLS_INITCAP function is as follows:
-
Syntax

-
Component
Component Description str A string value to be converted.
This argument can be a CHAR, VARCHAR, NCHAR, and NVARCHAR.
The return value has the same data type as str.
nls_param Defines the character set used to convert str.
This argument can be a CHAR, VARCHAR, NCHAR, and NVARCHAR.
It can be defined in the form of 'NLS_SORT=sort'. If it is not specified, a value defined in a session is used.
-
Example
The following example shows how to use the NLS_INITCAP function.
SQL> SELECT NLS_INITCAP('ijland','NLS_SORT=XDutch') "NLS_INITCAP" FROM DUAL; NLS_INITCAP ----------- IJland 1 row selected.
NLS_LOWER returns str with all letters in lowercase.
A detailed description of the NLS_LOWER function is as follows:
-
Syntax

-
Component
Component Description str A string value to be converted.
-
This argument can be a CHAR, VARCHAR, NCHAR, and NVARCHAR.
nls_param Defines a character set used to convert str.
-
This argument can be a CHAR, VARCHAR, NCHAR, and NVARCHAR.
-
It can be defined in the form of 'NLS_SORT=sort'. If it is not specified, a value defined in a session is used.
-
-
Example
The following example shows how to use the NLS_LOWER function.
SQL> SELECT NLS_LOWER('GROBE','NLS_SORT=XGerman') "NLS_LOWER" FROM DUAL; NLS_LOWER -------- grobe 1 row selected.
NLS_UPPER returns str with all letters in uppercase.
A detailed description of the NLS_UPPER function is as follows:
-
Syntax

-
Component
Component Description str A string value to be converted.
-
This argument can be a CHAR, VARCHAR, NCHAR, and NVARCHAR.
nls_param Defines a character set used to convert str.
-
This argument can be a CHAR, VARCHAR, NCHAR, and NVARCHAR
-
It can be defined in the form of 'NLS_SORT=sort'. If it is not specified, a value defined in a session is used.
-
-
Example
The following example shows how to use the NLS_UPPER function.
SQL> SELECT NLS_UPPER('große','NLS_SORT=XGerman') "NLS_UPPER" FROM DUAL; NLS_UPPER --------- GROSSE 1 row selected.
NTILE is an analytic function that divides sorted columns into a number of buckets indicated by expr and assigns a bucket number to each.
A detailed description of the NTILE function is as follows:
-
Syntax

-
Component
Component Description expr If this value is not an integer, it will be truncated to an integer.
Cannot contain a nested analytic function.
-
Example
The following example shows how to use the NTILE function.
SQL> SELECT NTILE(5) OVER (ORDER BY SAL) AS NTILE FROM EMP; NTILE ---------- 1 1 1 2 2 2 3 3 3 4 4 4 5 5 14 rows selected.
NULLIF returns NULL if expr1 and expr2 are equal. It returns expr1 if they are not equal.
A detailed description of the NULLIF function is as follows:
-
Syntax

-
Component
Component Description expr1 An expression that cannot be NULL. expr2 An expression. -
Example
The following example shows how to use the NULLIF function.
SQL> SELECT NVL (NULLIF ('A', 'A'), 'Same') FROM DUAL; NVL(NULLIF('A','A'),'SAME') --------------------------- Same 1 row selected.
NUMTODSINTERVAL returns a date-time interval type value converted from expr.
A detailed description of the NUMTODSINTERVAL function is as follows:
-
Syntax

-
Component
Component Description expr A value to be converted.
interval_unit Specifies the unit of expr.
One of the following can be used: DAY, HOUR, MINUTE, or SECOND.
-
Example
The following example shows how to use the NUMTODSINTERVAL function.
SQL> SELECT NUMTODSINTERVAL (10, 'DAY') "NUMTODSINTERVAL" FROM DUAL; NUMTODSINTERVAL ----------------------------- +000000010 00:00:00.000000000 1 row selected.
NUMTOYMINTERVAL returns a year-month interval type value converted from expr.
A detailed description of the NUMTOYMINTERVAL function is as follows:
-
Syntax

-
Component
Component Description expr A value to be converted.
interval_unit Specifies the unit of expr.
Either YEAR or MONTH can be used.
-
Example
The following example shows how to use the NUMTOYMINTERVAL function.
SQL> SELECT NUMTOYMINTERVAL (10, 'YEAR') "NUMTOYMINTERVAL" FROM DUAL; NUMTOYMINTERVAL --------------- +000000010-00 1 row selected.
NVL returns expr1 if the expression value is not NULL, or expr2 if the first expression value is NULL.
A detailed description of the NVL function is as follows:
-
Syntax
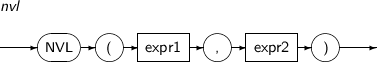
-
Component
Component Description expr1, expr2 Expressions. -
Example
The following example shows how to use the NVL function.
SQL> SELECT NAME, ID, NVL(TO_CHAR(MGRID, '99'), 'N/A') MID FROM EMP3; NAME ID MID -------------------- ---------- --- Paul 1 N/A John 2 1 Linda 3 1 Lucas 4 N/A Kathy 5 4 5 rows selected.
NVL2 returns expr2 if expr1 is not NULL, or expr3 if expr1 is NULL.
A detailed description of the NVL2 function is as follows:
-
Syntax
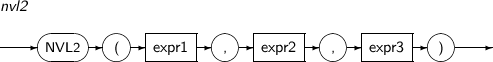
-
Component
Component Description expr1 An expression. expr2 An expression.
The return type of this function depends on the data type of expr2.
expr3 An expression.
The data type of expr3 is implicitly converted to the data type of expr2.
-
Example
The following example shows how to use the NVL2 function.
SQL> SELECT NVL2(DUMMY, 'NOT NULL', 'NULL') FROM DUAL; NVL2(DUMMY, 'NOT NULL', 'NULL') ------------------------------- NOT NULL 1 row selected.
ORA_HASH returns the hash value of expr.
A detailed description of the ORA_HASH function is as follows:
-
Syntax
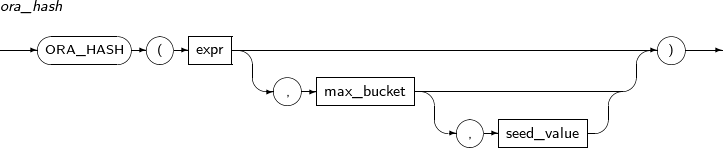
-
Component
Component Description expr An expression that represents data for which a hash value is computed. All types except for LONG and LOB can be used. max_bucket A numeric expression that indicates the maximum bucket size. A value between 0 and 4294967295 can be used. Defaults to 4294967295. seed_value A numeric expression that allows the function to produce different results for the same data. A value between 0 and 4294967295 can be used. Defaults to 0. -
Example
The following example shows how to use the ORA_HASH function.
SQL> SELECT ORA_HASH(512, 10, 5) FROM DUAL; ORA_HASH(512,10,5) ------------------ 4 1 row selected.
OVERLAPS returns TRUE if two given time intervals overlap with one another or FALSE if they do not overlap. The time intervals are specified with two pairs of start and end points. interval can alternatively be specified for end points.
A detailed description of the OVERLAPS function is as follows:
-
Syntax
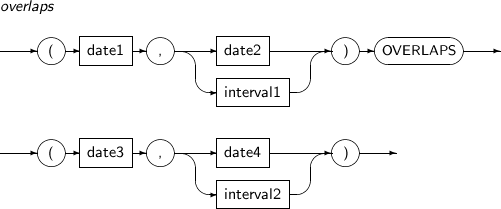
-
Component
Component Description date1, date3 Indicate the start date. The values are either a DATE or TIMESTAMP. date2, date4 Indicate the end date. The values are either a DATE or TIMESTAMP. interval1, interval2 Interval literals that indicate an interval of dates. -
Example
The following example shows how to use the OVERLAPS function.
SQL> SELECT 1 FROM DUAL WHERE (DATE'1999-01-01', DATE'2000-01-01') OVERLAPS (DATE'1999-03-01', INTERVAL '1' YEAR); 1 ---------- 1 1 row selected.
PERCENT_RANK returns the rank of expr as a NUMBER between 0 and 1. This function can be used as an analytic function.
Depending on how this function is used, the calculation method is different as follows:
| Function | Description |
|---|---|
| Aggregate Function | Computes the rank of a virtual row that consists of parameter values, subtracts 1 from the rank, and divides this by the number of rows in a group. Parameter values should have constant values in a group and correspond to the expression in the ORDER BY clause. |
| Analytic Function | Computes the rank of a virtual row that consists of parameter values, subtracts 1 from the rank, and divides this by the number of rows in a group minus 1. |
A detailed description of the PERCENT_RANK function is as follows:
-
Syntax
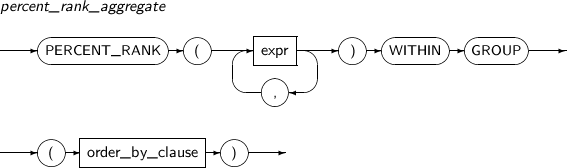

-
Component
Component Description expr An expression that returns a numeric value. partition_by Partitions the result set of the current query block based on expr.
For detailed information, see partition_by in “4.1.3. Analytic Functions”.
order_by_clause Specifies how to sort rows in a single divided partition.
For detailed information, see order_by_clause in “4.1.3. Analytic Functions”.
-
Example
The following example shows how to use the PERCENT_RANK function.
SQL> SELECT PERCENT_RANK(1000) WITHIN GROUP (ORDER BY SAL) AS PERCENT_RANK FROM EMP; PERCENT_RANK ------------ .14285714286 1 row selected. -
Example (Analytic Function)
The following example shows how to use the PERCENT_RANK function as an analytic function.
SQL> SELECT PERCENT_RANK() OVER (PARTITION BY DEPTNO ORDER BY SAL) AS PERCENT_RANK FROM EMP; PERCENT_RANK ------------ 0 .5 1 0 .25 .5 .75 .75 0 .2 .2 .6 .8 1 14 rows selected.
PERCENTILE_CONT is an inverse distribution function that calculates a value that corresponds to a percentile value given as an argument in a continuous distribution mode. NULL values are ignored during the calculation. This function can be used as an analytic function.
The expression value of an argument is a percentile value between 0 and 1 in a group. The expression value of an ORDER BY clause must be a numeric type or a DATE.
This function computes a result according to linear interpolation after sorting rows with a sorting specification. For this, RN, CRN, and FRN are calculated as follows:
RN=(1+(P*(N-1))) CRN=CEILING(RN) FRN=FLOOR(RN)
| Classification | Description |
|---|---|
| P | A percentile value given as an argument. |
| N | The number of rows that are not NULL in a group. |
If CRN and FRN are equal, the final result is the value of an expression at the RNth row. If not, the result is calculated as follows:
(CRN-RN) * (value of expr at FRN) + (RN-FRN) * (value of expr at CRN)
A detailed description of the PERCENTILE_CONT function is as follows:
-
Syntax
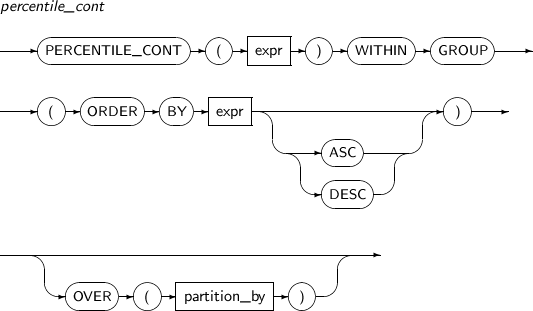
-
Component
Component Description expr An expression that returns a numeric value. ASC
DESC
-
ORDER BY ASC sorts the result in ascending order. (Default value)
-
ORDER BY DESC sorts the result in descending order.
partition_by Partitions the result set of the current query block based on expr.
For detailed information, see partition_by in “4.1.3. Analytic Functions”.
-
-
Example
The following example shows how to use the PERCENTILE_CONT function.
SQL> SELECT DEPTNO, PERCENTILE_CONT(0.35) WITHIN GROUP (ORDER BY SAL) FROM EMP GROUP BY DEPTNO; DEPTNO PERCENTILE_CONT(0.35)WITHINGRO ---------- ------------------------------- 10 2105 20 1850 30 1250 3 rows selected. -
Example (Analytic Function)
The following example shows how to use the PERCENTILE_CONT function as an analytic function.
SQL> SELECT DEPTNO, EMPNO, PERCENTILE_CONT(0.35) WITHIN GROUP (ORDER BY SAL) OVER (PARTITION BY DEPTNO) FROM EMP; DEPTNO EMPNO PERCENTILE_CONT(0.35)WITHINGRO ---------- ---------- ------------------------------- 10 7934 2105 10 7782 2105 10 7839 2105 20 7369 1850 20 7876 1850 20 7566 1850 20 7788 1850 20 7902 1850 30 7900 1250 30 7521 1250 30 7654 1250 30 7844 1250 30 7499 1250 30 7698 1250 14 rows selected.
PERCENTILE_DISC is an inverse distribution function that assumes a discrete distribution. NULL values are ignored during the calculation. This function can be used as an analytic function.
An argument's expression value must be a percentile value and a constant value between 0 and 1. The value must be a type that can be sorted with an ORDER BY clause.
This function calculates RN with the following formula. The result is the expression value at the row corresponding to CRN.
RN=N*P CRN=CEILING(RN)
A detailed description of the PERCENTILE_DISC function is as follows:
-
Syntax
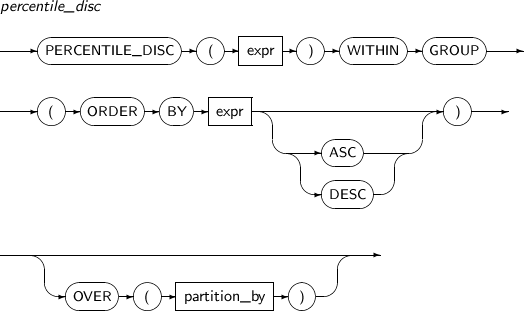
-
Component
Component Description expr An expression that returns a numeric value. ASC
DESC
ORDER BY ASC sorts the result in ascending order. ASC is the default value.
ORDER BY DESC sorts the result in descending order.
partition_by Partitions the result set of the current query block based on expr.
For detailed information, see partition_by in “4.1.3. Analytic Functions”.
-
Example
The following example shows how to use the PERCENTILE_DISC function.
SQL> SELECT DEPTNO, PERCENTILE_DISC(0.15) WITHIN GROUP (ORDER BY SAL) AS PERCENTILE_DISC FROM EMP GROUP BY DEPTNO; DEPTNO PERCENTILE_DISC ---------- --------------- 10 1300 20 800 30 950 3 rows selected. -
Example (Analytic Function)
The following example shows how to use the PERCENTILE_DISC function as an analytic function.
SQL> SELECT DEPTNO, PERCENTILE_DISC(0.15) WITHIN GROUP (ORDER BY SAL) OVER (PARTITION BY DEPTNO) AS PERCENTILE_DISC FROM EMP; DEPTNO PERCENTILE_DISC ---------- --------------- 10 1300 10 1300 10 1300 20 800 20 800 20 800 20 800 20 800 30 950 30 950 30 950 30 950 30 950 30 950 14 rows selected.
POWER returns num1 raised to the power of num2 (num1num2).
A detailed description of the POWER function is as follows:
-
Syntax

-
Component
Component Description num1, num2 Expressions that return a numeric value.
If num1 is negative, num2 must be an integer.
Should be a NUMBER or a compatible type.
If the type of num1 or num2 is BINARY FLOAT or BINARY_DOUBLE, it returns BINARY DOUBLE type. Otherwise, it returns NUMBER type.
-
Example
The following example shows how to use the POWER function.
SQL> SELECT POWER(2, 3) FROM DUAL; POWER(2,3) ---------- 8 1 row selected.
RANK returns the rank of each row in a group after the rows are sorted by group. This function can be used as an analytic function.
Ranks are NUMBERs. Rows that have equal values receive the same rank, and the rank value is increased by one for each row. Therefore, the ranks may be nonconsecutive numbers.
Depending on how this function is used, the calculation method is different as follows:
| Function | Description |
|---|---|
| Aggregate Function | Computes ranks of virtual rows that match the given arguments. Arguments should have a constant value for each group and correspond with an expression in order_by_clause. |
| Analytic Function | Returns the rank of each row in a group. Each row's rank depends on the sorting method in the expr in order_by_clause. |
A detailed description of the RANK function is as follows:
-
Syntax


-
Component
Component Description expr An expression that returns a numeric value. ASC
DESC
-
ORDER BY ASC sorts the result in ascending order. (Default value)
-
ORDER BY DESC sorts the result in descending order.
partition_by Partitions the result set of the current query block based on expr.
For detailed information, see partition_by in “4.1.3. Analytic Functions”.
-
-
Example
The following example shows how to use the RANK function.
SQL> SELECT DEPTNO, RANK(3000) WITHIN GROUP (ORDER BY SAL) AS RANK FROM EMP GROUP BY DEPTNO; DEPTNO RANK ---------- ---------- 10 3 20 4 30 7 3 rows selected. -
Example (Analytic Function)
The following example shows how to use the RANK function as an analytic function.
SQL> SELECT NAME, DEPTID, SALARY, RANK() OVER (PARTITION BY DEPTID ORDER BY SALARY) FROM EMP; NAME DEPTID SALARY RANK()OVER -------------------- ---------- ---------- ---------- Paul 1 3000 1 Angela 1 3000 1 Nick 1 3200 3 Scott 1 4000 4 James 1 4000 4 John 1 4500 6 Joe 2 4000 1 Brad 2 4200 2 Daniel 2 5000 3 Tom 2 5000 3 Kathy 2 5000 3 Bree 2 6000 6 12 rows selected.
REGR_SLOPE calculates the linear equation that best fits the set of numeric data pairs. It is used as both aggregate and analytic function, and takes numeric or compatible type arguments. If either a dependent argument (expr1) or an independent argument (expr2) is NULL, that argument is ignored during the calculation. If all rows are NULL, NULL is returned.
This function calculates and returns the slope of a regression line, which is the result of "COVAR_POP(expr1, expr2) / VAR_POP(expr2)". If the result of VAR_POP is 0, the final result is NULL.
COVAR_POP(expr1, expr2) / VAR_POP(expr2)
If the result of VAR_POP is 0, the final result is null.
A detailed description of the REGR_SLOPE function is as follows:
-
Syntax
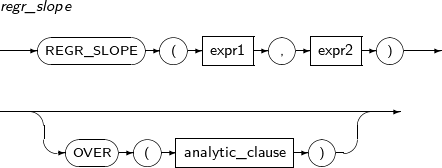
-
Components
Component Description expr1 An expression that returns a numeric value. This is the dependent variable. expr2 An expression that returns a numeric value. This is the independent variable. -
Example
The following example shows how to use the REGR_SLOPE function.
SQL> SELECT * FROM XY; X Y ---------- ---------- 1 1 2 3 2 rows selected. SQL> SELECT REGR_SLOPE(Y,X) FROM XY; REGR_SLOPE(Y,X) --------------- 2 1 row selected. SQL> SELECT REGR_SLOPE(X,Y) FROM XY; REGR_SLOPE(X,Y) --------------- .5 1 row selected.
REGR_INTERCEPT calculates the linear equation that best fits the set of numeric data pairs. It is used as both aggregate and analytic function, and takes numeric or compatible type arguments. If either a dependent argument (expr1) or an independent argument (expr2) is NULL, that argument is ignored during the calculation. If all rows are NULL, NULL is returned.
This function calculates and returns the y-intercept of the regression line, which is the result of "AVG(expr1) - REGR_SLOPE(expr1, expr2) × AVG(expr2)". If the result of REGR_SLOPE is NULL, the final result is also NULL.
AVG(exr1) - REGR_SLOPE(expr1, expr2) × AVG(expr2)
If the result of VAR_POP is 0, the final result is null.
A detailed description of the REGR_INTERCEPT function is as follows:
-
Syntax
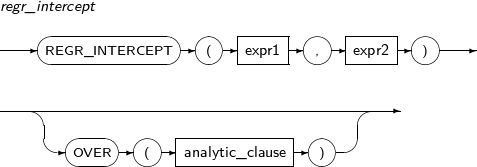
-
Component
Component Description expr1 An expression that returns a numeric value. This is the dependent variable. expr2 An expression that returns a numeric value. This is the independent variable. -
Example
The following example shows how to use the REGR_INTERCEPT function.
SQL> SELECT * FROM XY; X Y ---------- ---------- 1 1 2 3 2 rows selected. SQL> SELECT REGR_INTERCEPT(Y,X) FROM XY; REGR_INTERCEPT(Y,X) ------------------- -1 1 row selected.
REGR_COUNT calculates the linear equation that best fits the set of numeric data pairs. It is used as both aggregate and analytic function, and takes numeric or compatible type arguments. If either a dependent argument (expr1) or an independent argument (expr2) is NULL, that argument is ignored during the calculation. If all rows are NULL, NULL is returned.
This function returns the number of non-null number pairs (expr1, expr2). It is used to configure the regression line.
A detailed description of the REGR_COUNT function is as follows:
-
Syntax
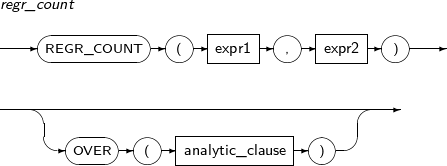
-
Component
Component Description expr1 An expression that returns a numeric value. This is the dependent variable. expr2 An expression that returns a numeric value. This is the independent variable. -
Example
The following example shows how to use the REGR_COUNT function.
SQL> SELECT * FROM XY; X Y ---------- ---------- 1 1 2 3 2 rows selected. SQL> SELECT REGR_COUNT(Y,X) FROM XY; REGR_COUNT(Y,X) --------------- 2 1 row selected.
REGR_R2 calculates the linear equation that best fits the set of numeric data pairs. It is used as both aggregate and analytic function, and takes numeric or compatible type arguments. If either a dependent argument (expr1) or an independent argument (expr2) is NULL, that argument is ignored during the calculation. If all rows are NULL, NULL is returned.
This function calculates the coefficient of determination (R-squared or how well a regression is fitted) for the regression line. The VAR_POP(expr1) and VAR_POP(expr2) values determine the return value.
-
If VAR_POP(expr2) = 0, returns NULL.
-
If VAR_POP(expr1) = 0 and VAR_POP(expr2) > 0, returns 1.
-
If VAR_POP(expr1) > 0 and VAR_POP(expr2) > 0, returns POWER(CORR(expr1, expr2), 2)
A detailed description of the REGR_R2 function is as follows:
-
Syntax

-
Components
Component Description expr1 An expression that returns a numeric value. This is the dependent variable. expr2 An expression that returns a numeric value. This is the independent variable. -
Example
The following example shows how to use the REGR_R2 function.
SQL> SELECT * FROM XY; X Y ---------- ---------- 1 1 2 3 2 rows selected. SQL> SELECT REGR_R2(Y,X) FROM XY; REGR_R2(Y,X) ------------ 1 1 row selected.
REGR_AVGX calculates the linear equation that best fits the set of numeric data pairs. It is used as both aggregate and analytic function, and takes numeric or compatible type arguments. If either a dependent argument (expr1) or an independent argument (expr2) is NULL, that argument is ignored during the calculation. If all rows are NULL, NULL is returned.
This function calculates the average value of the independent variable (expr2). "AVG(expr2)" is calculated after null pairs are eliminated.
A detailed description of the REGR_AVGX function is as follows:
-
Syntax

-
Component
Component Description expr1 An expression that returns a numeric value. This is the dependent variable. expr2 An expression that returns a numeric value. This is the independent variable. -
Example
The following example shows how to use the REGR_AVGX function.
SQL> SELECT * FROM XY; X Y ---------- ---------- 1 1 2 3 2 rows selected. SQL> SELECT REGR_AVGX(Y,X) FROM XY; REGR_AVGX(Y,X) -------------- 1.5 1 row selected.
REGR_AVGY calculates the linear equation that best fits the set of numeric data pairs. It is used as both aggregate and analytic function, and takes numeric or compatible type arguments. If either a dependent argument (expr1) or an independent argument (expr2) is NULL, that argument is ignored during the calculation. If all rows are NULL, NULL is returned.
This function calculates the average value of the independent variable (expr1). "AVG(expr1)" is calculated after null pairs are eliminated.
A detailed description of the REGR_AVGY function is as follows:
-
Syntax
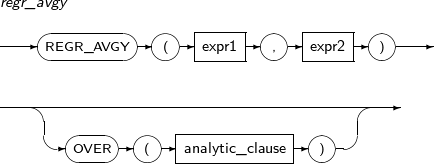
-
Component
Component Description expr1 An expression that returns a numeric value. This is the dependent variable. expr2 An expression that returns a numeric value. This is the independent variable. -
Example
The following example shows how to use the REGR_AVGY function.
SQL> SELECT * FROM XY; X Y ---------- ---------- 1 1 2 3 2 rows selected. SQL> SELECT REGR_AVGY(Y,X) FROM XY; REGR_AVGY(Y,X) -------------- 2 1 row selected.
REGR_SXX calculates the linear equation that best fits the set of numeric data pairs. It is used as both aggregate and analytic function, and takes numeric or compatible type arguments. If either a dependent argument (expr1) or an independent argument (expr2) is NULL, that argument is ignored during the calculation. If all rows are NULL, NULL is returned.
This function calculates and returns the statistics for data diagnostics used in regression analysis.
REGR_COUNT(expr1, expr2) × VAR_POP(expr2)
A detailed description of the REGR_SXX function is as follows:
-
Syntax

-
Components
Component Description expr1 An expression that returns a numeric value. This is the dependent variable. expr2 An expression that returns a numeric value. This is the independent variable. -
Example
The following example shows how to use the REGR_SXX function.
SQL> SELECT * FROM XY; X Y ---------- ---------- 1 1 2 3 2 rows selected. SQL> SELECT REGR_SXX(Y,X) FROM XY; REGR_SXX(Y,X) ------------- .5 1 row selected.
REGR_SXY calculates the linear equation that best fits the set of numeric data pairs. It is used as both aggregate and analytic function, and takes numeric or compatible type arguments. If either a dependent argument (expr1) or an independent argument (expr2) is NULL, that argument is ignored during the calculation. If all rows are NULL, NULL is returned.
This auxiliary function calculates and returns the statistics for data diagnostics used in regression analysis.
REGR_COUNT(expr1, expr2) × VAR_POP(expr1)
A detailed description of the REGR_SXY function is as follows:
-
Syntax
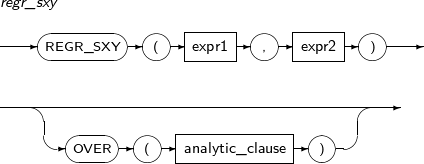
-
Components
Component Description expr1 An expression that returns a numeric value. This is the dependent variable. expr2 An expression that returns a numeric value. This is the independent variable. -
Example
The following example shows how to use the REGR_SXY function.
SQL> SELECT * FROM XY; X Y ---------- ---------- 1 1 2 3 2 rows selected. SQL> SELECT REGR_SYY(Y,X) FROM XY; REGR_SYY(Y,X) ------------- 2 1 row selected.
REGR_SYY calculates the linear equation that best fits the set of numeric data pairs. It is used as both aggregate and analytic function, and takes numeric or compatible type arguments. If either a dependent argument (expr1) or an independent argument (expr2) is NULL, that argument is ignored during the calculation. If all rows are NULL, NULL is returned.
This auxiliary function calculates and returns the statistics for data diagnostics used in regression analysis.
REGR_COUNT(expr1, expr2) × VAR_POP(expr1)
A detailed description of the REGR_SYY function is as follows:
-
Syntax
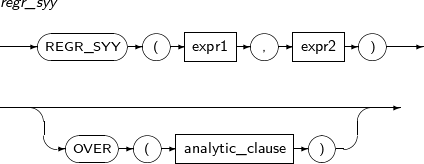
-
Components
Component Description expr1 An expression that returns a numeric value. This is the dependent variable. expr2 An expression that returns a numeric value. This is the independent variable. -
Example
The following example shows how to use the REGR_SYY function.
SQL> SELECT * FROM XY; X Y ---------- ---------- 1 1 2 3 2 rows selected. SQL> SELECT REGR_SXY(Y,X) FROM XY; REGR_SXY(Y,X) ------------- 1 1 row selected.
RATIO_TO_REPORT is an analytic function that computes the ratio of a value to the sum of a set of values. If expr is NULL, the return value of this function is also NULL.
The set of values is determined by partition_by. If partition_by is not specified, this function computes over every row returned by the query.
A detailed description of the RATIO_TO_REPORT function is as follows:
-
Syntax

-
Component
Component Description expr An expression that returns a numeric value.
Cannot contain a nested analytic function. However, this can contain other embedded functions.
partition_by Partitions the result set of the current query block based on expr.
For detailed information, see partition_by in “4.1.3. Analytic Functions”.
-
Example
The following example shows how to use the RATIO_TO_REPORT function.
SQL> SELECT TYPE, AMOUNT, RATIO_TO_REPORT(AMOUNT) OVER () RATIO FROM ASSETS; TYPE AMOUNT RATIO -------------------- ---------- ---------- funds 200 .1 stock 500 .25 real_estate 1000 .5 cash 300 .15 4 rows selected.
RAWTOHEX converts raw to a hexadecimal VARCHAR2.
A detailed description of the RAWTOHEX function is as follows:
-
Syntax
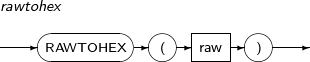
-
Component
Component Description raw An expression that returns a string. CLOB, BLOB, LONG, LONG RAW, XMLTYPE, and GEOMETRY types cannot be used.
-
Example
The following example shows how to use the RAWTOHEX function.
SQL> SELECT RAWTOHEX('AB') FROM DUAL; RAWTOHEX('AB') -------------- 4142 1 row selected.
REGEXP_COUNT returns how many times a regular expression pattern is repeated in source_str.
A detailed description of the REGEXP_COUNT function is as follows:
-
Syntax
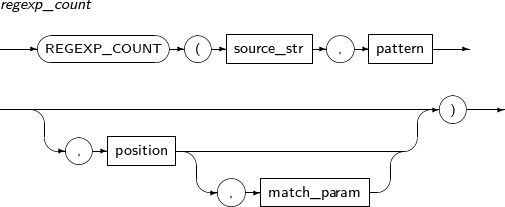
-
Component
Component Description source_str An expression that returns a string.
This argument can be a CHAR, VARCHAR2, NCHAR, and NVARCHAR2.
pattern An expression that returns a string written with a regular expression.
This argument can be a CHAR, VARCHAR2, NCHAR, and NVARCHAR2. If the type is different from that of source_str, it is converted to the type of source_str.
position An expression that returns a numeric value and indicates the initial position to begin matching from. Defaults to 1.
match_param An expression that returns a string. This parameter specifies option for matching the pattern.
The following values are available. Multiple values can be specified.
-
'i': Case-insensitive.
-
''c': Case-sensitive.
-
'n': Indicates that a period can function as a newline character.
-
'm': Treats the input string as a multiple line input.
-
'x': Ignores whitespace characters.
If contradictory values are used together, only the last value is used. For example, if 'ic' is specified, only 'c' is used.
-
-
Example
The following example shows how to use the REGEXP_COUNT function.
SQL> SELECT REGEXP_COUNT('abcabcabc','abc', 2) FROM DUAL; REGEXP_COUNT('ABCABCABC','ABC',2) --------------------------------- 2 1 row selected.
REGEXP_INSTR returns the position where a regular expression pattern exists in source_str. If pattern does not exist in source_str, 0 is returned.
A detailed description of the REGEXP_INSTR function is as follows:
-
Syntax
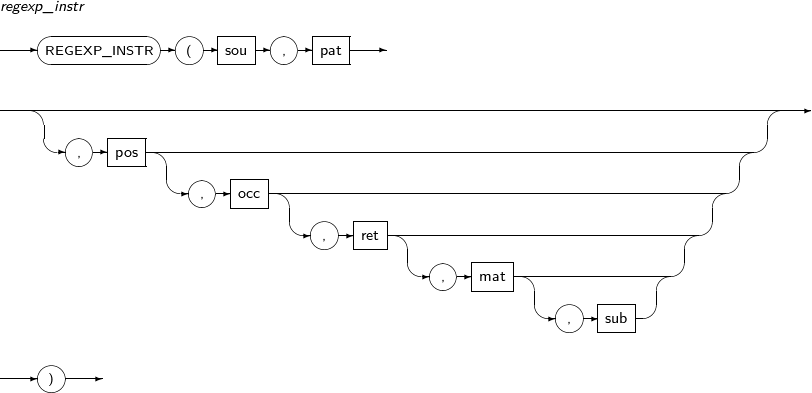
-
Component
Component Description sou
(source_str)
An expression that returns a string.
This argument can be a CHAR, VARCHAR2, NCHAR, or NVARCHAR2.
pat
(pattern)
An expression that returns a string that contains a regular expression.
This argument can be a CHAR, VARCHAR2, NCHAR, or NVARCHAR2. If the type is different from that of source_str, it is converted to the type of source_str.
pos
(position)
An expression that returns a numeric value that indicates the initial position to begin matching from. Defaults to 1.
occ
(occurrence)
An expression that returns a numeric value. If specified, the function will return the nth occurrence of the matched pattern. Defaults to 1.
ret
(return_option)
An expression that returns a numeric value.
-
0: Returns the position of the first character of the pattern. This is the default value.
-
1: Returns the position of the character following the pattern.
mat
(match_param)
An expression that returns a string. This parameter specifies option for matching the pattern. The available values and their characteristics are the same as the REGEXP_COUNT function. sub
(sub_expr)
An expression that returns a numeric value between 0 and 9. Defaults to 0.
This specifies which fragment of a pattern to use. Fragments are enclosed in parentheses and are numbered from left to right.
For example, the regular expression "(tibero(is(an)(rdbms)))" contains four groups: "tiberoisanrdbms" numbered as 1, "isanrdbms" as 2, "an" as 3, and "rdbms" as 4.
-
-
Example
The following example shows how to use the REGEXP_INSTR function.
SQL> SELECT REGEXP_INSTR('abcabcabc','abc', 2) FROM DUAL; REGEXP_INSTR('ABCABCABC','ABC',2) --------------------------------- 4 1 row selected.
REGEXP_REPLACE searches source_str and replaces an occurrence of the regular expression pattern with replace_str.
A detailed description of the REGEXP_REPLACE function is as follows:
-
Syntax
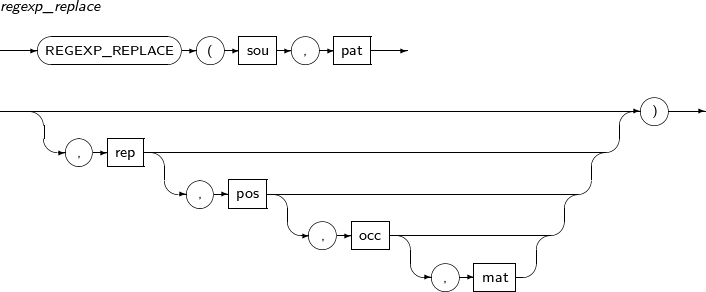
-
Component
Component Description sou
(source_str)
An expression that returns a string.
This argument can be a CHAR, VARCHAR2, NCHAR, or NVARCHAR2.
pat
(pattern)
An expression that returns a string that contains a regular expression.
This argument can be a CHAR, VARCHAR2, NCHAR, or NVARCHAR2. If the type is different from that of source_str, it is converted to the type of source_str.
rep
(replace_str)
An expression that returns a string.
This argument can be a CHAR, VARCHAR2, NCHAR, or NVARCHAR2. If the type is different from that of source_str, it is converted to the type of source_str.
pos
(position)
An expression that returns a numeric value that indicates the initial position to begin matching from. Defaults to 1.
occ
(occurrence)
An expression that returns a numeric value. If specified, the function will return the nth occurrence of pattern. Defaults to 1.
mat
(match_param)
An expression that returns a string. This parameter specifies options for matching the pattern. The available values and their characteristics are the same as the REGEXP_COUNT function. -
Example
The following example shows how to use the REGEXP_REPLACE function.
SQL> SELECT REGEXP_REPLACE('aaaaaaa','([[:alpha:]])', 'x') FROM DUAL; REGEXP_REPLACE('AAAAAAA','([[:ALPHA:]])','X') --------------------------------------------- xxxxxxx 1 row selected.
REGEXP_SUBSTR returns a string found by searching source_str for the regular expression pattern.
A detailed description of the REGEXP_SUBSTR function is as follows:
-
Syntax
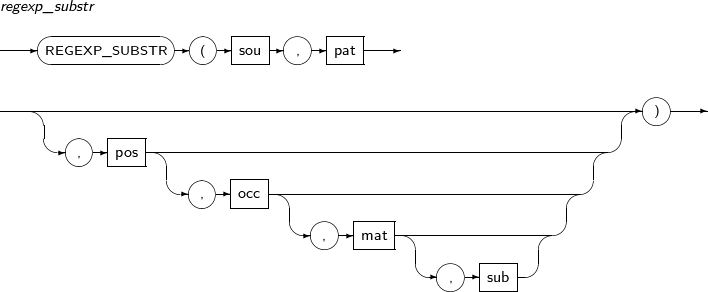
-
Component
Component Description source_str An expression that returns a string.
This argument can be a CHAR, VARCHAR2, NCHAR, or NVARCHAR2.
pattern An expression that returns a string that contains a regular expression.
This argument can be a CHAR, VARCHAR2, NCHAR, or NVARCHAR2. If the type is different from that of source_str, it is converted to the type of source_str.
position An expression that returns a numeric value that indicates the initial position to begin matching from. Defaults to 1. occurrence An expression that returns a numeric value. If specified, the function will return the nth occurrence of pattern. Defaults to 1. match_param An expression that returns a string. This parameter specifies option for matching the pattern. The available values and their characteristics are the same as the REGEXP_COUNT function. sub_expr An expression that returns a numeric value between 0 and 9. Defaults to 0. This has the same characteristics as the REGEXP_INSTR function.
-
Example
The following example shows how to use the REGEXP_SUBSTR function.
SQL> SELECT REGEXP_SUBSTR('123456','3.*5', 1) FROM DUAL; REGEXP_SUBSTR('123456','3.*5',1) -------------------------------- 345 1 row selected.
REMAINDER returns the remainder after dividing num1 by num2.
A detailed description of the REMAINDER function is as follows:
-
Syntax
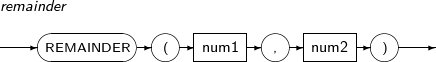
-
Component
Component Description num1, num2 num1 and num2 must be a numeric value or a type that can be converted to a numeric valie. If the types of num1 and num2 do not match, the type with the higher priority is used for both components. The return value is also set to this type.
-
Example
The following example shows how to use the REMAINDER function.
SQL> SELECT REMAINDER(3, 2), REMAINDER(7F, 3), REMAINDER(5.5D, 1.3F) FROM DUAL; REMAINDER(3,2) REMAINDER(7F,3) REMAINDER(5.5D,1.4F) -------------- --------------- -------------------- -1 1.0E+000 3.0E-001 1 rows selected.
REPLACE searches str and replaces substr with replace_str.
A detailed description of the REPLACE function is as follows:
-
Syntax

-
Component
Component Description str An expression that returns a string. substr An expression that returns a string.
If this is NULL, str is used.
replace_str An expression that returns a string.
If this is NULL or not specified, every instance of substr in str is removed.
-
Example
The following example shows how to use the REPLACE function.
SQL> SELECT REPLACE('ABCDEFG', 'CD') FROM DUAL; REPLACE('ABCDEFG','CD') ----------------------- ABEFG 1 row selected. SQL> SELECT REPLACE('ABCDEFG', 'CD', 'XY') FROM DUAL; REPLACE('ABCDEFG','CD','XY') ---------------------------- ABXYEFG 1 row selected.
REVERSE returns the reverse of str.
A detailed description of the REVERSE function is as follows:
-
Syntax
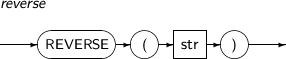
-
Component
Component Description str An expression that returns a string. -
Example
The following example shows how to use the REVERSE function.
SQL> SELECT REVERSE('TIBERO') FROM DUAL; REVERSE('TIBERO') ----------------- OREBIT 1 row selected.
ROUND(number) returns num1 rounded to an amount of decimal places equal to num2.
A detailed description of the ROUND(number) function is as follows:
-
Syntax
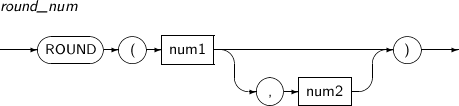
-
Component
Component Description num1 An expression that returns a numeric value. num2 An expression that returns a numeric value.
Must be an integer.
If this is 0 or not specified, num1 will be rounded to 0 places.
If this is a negative integer, num1 will be rounded off to the left of the decimal point.
-
Example
The following example shows how to use the ROUND(number) function.
SQL> SELECT ROUND(345.678), ROUND(345.678, 2), ROUND(345.678, -1) FROM DUAL; ROUND(345.678) ROUND(345.678,2) ROUND(345.678,-1) -------------- ---------------- ----------------- 346 345.68 350 1 row selected.
ROUND(date) returns date rounded to the unit specified in format.
A detailed description of the ROUND(date) function is as follows:
-
Syntax
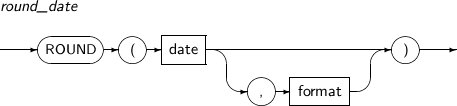
-
Component
Component Description date An expression that returns a date. format A string that represents a format model that specifies a rounding off unit.
If this is not specified, the date is rounded to the nearest day using the "DD" format string.
format can be of a format like 'YEAR', 'MONTH', 'DAY', etc.
Format strings that can be specified in the ROUND(date) function are as follows:
Format String Description CC, SCC The last 2 digits of a 4-digit year are truncated and then 1 year is added 1. (e.g., xx01) IYYY, IYY, IY, I An ISO year is rounded up or down on July 1. SYYYY, YYYY, YYY, YY, Y, YEAR, SYEAR A year is rounded up or down based on July 1. Q A quarter is rounded up or down on the 16th day of the second month. MONTH, MON, MM, RM A month is rounded up or down on the 16th day. WW A week is rounded up or down where week 1 starts on the first day of the year (January 1). IW A week is rounded up or down on the same day of the week as the first day of the ISO year. W A week is rounded up or down on the same day of the week as the first day of the month. DDD, DD, J A day is rounded up or down after 12 p.m. DAY, DY, D A week is rounded up or down to the nearest Sunday based on Wednesday at 12 p.m. HH24, HH12, HH An hour is rounded up or down based on minutes. MI A minute is rounded up or down based on seconds. -
Example
The following example shows how to use the ROUND(date) function.
SQL> SELECT ROUND(TO_DATE('2005/06/22'), 'YEAR') AS TO_DATE FROM DUAL; TO_DATE -------------------------------- 2005/01/01 1 row selected. SQL> SELECT TO_CHAR(ROUND(TO_DATE('1998/6/20', 'YYYY/MM/DD'), 'CC'), 'YYYY/MM/DD') AS TO_DATE FROM DUAL; TO_DATE ---------- 2001/01/01 1 row selected. SQL> SELECT TO_CHAR(ROUND(TO_DATE('-3741/01/02', 'SYYYY/MM/DD'), 'CC'), 'SYYYY/MM/DD') AS TO_DATE FROM DUAL; TO_DATE ----------- -3700/01/01 1 row selected. SQL> SELECT TO_CHAR(ROUND(TO_DATE('2005/01/26 12:30:14', 'YYYY/MM/DD HH24:MI:SS'), 'DY'), 'YYYY/MM/DD') AS TO_DATE FROM DUAL; TO_DATE ---------- 2005/01/30 1 row selected. SQL> SELECT ROUND(TO_DATE('2005/01/26 12:30:14', 'YYYY/MM/DD HH24:MI:SS')) AS TO_DATE FROM DUAL; TO_DATE -------------------------------- 2005/01/27 1 row selected.
ROWIDTOCHAR returns a VARCHAR converted from a ROWID, rowid.
A detailed description of the ROWIDTOCHAR function is as follows:
-
Syntax

-
Component
Component Description rowid A value to be converted to a VARCHAR. -
Example
The following example shows how to use the ROWIDTOCHAR function.
SQL> SELECT LAST_NAME FROM EMP WHERE ROWIDTOCHAR(ROWID) LIKE "%AAAF%'; LAST_NAME ---------- King 1 row selected.
ROW_NUMBER is an analytic function that assigns a unique consecutive number, starting from 1, to each row to which it is applied (each row in a partition or each row returned by a query), in the order specified in order_by_clause.
This function enables top-N, bottom-N, and inner-N reporting. To get consistent results, a query must guarantee a constant sort order.
A detailed description of the ROW_NUMBER function is as follows:
-
Syntax

-
Component
Component Description partition_by Partitions the result set of the current query block based on expr.
For detailed information, see partition_by in “4.1.3. Analytic Functions”.
order_by_clause Specifies how to sort rows in a single divided partition.
For detailed information, see order_by_clause in “4.1.3. Analytic Functions”.
-
Example
The following example shows how to use the ROW_NUMBER function.
SQL> SELECT JOB_ID, LAST_NAME, SALARY FROM ( SELECT JOB_ID, LAST_NAME, SALARY, ROW_NUMBER() OVER (PARTITION BY JOB_ID ORDER BY SALARY) RN FROM EMPLOYEES_DEMO ) WHERE RN <= 1; JOB_ID LAST_NAME SALARY ---------- ------------------------- ---------- AD_PRES King 24000 AD_VP Kochhar 17000 IT_PROG Ernst 6000 3 rows selected.
RPAD pads the right side of expr1 with expr2 resulting in a new string with a maximum length of num.
In most character sets, the number of characters of a string to be returned is the same as the length. However, in the case of multibyte character sets such as Korean, the number and the length can differ from each another.
A detailed description of the RPAD function is as follows:
-
Syntax

-
Component
Component Description expr1 An expression that returns a string, CLOB, or BLOB.
If expr1 is longer than num, this function returns the first num characters of expr1.
expr2 An expression that returns a string, CLOB, or BLOB.
If this is not specified, blank spaces are used.
num An expression that returns a numeric value.
The length of the returned string.
-
Example
The following example shows how to use the RPAD function.
SQL> SELECT RPAD('RPAD', 10, '-=') FROM DUAL; RPAD('RPAD',10,'-=') -------------------- RPAD-=-=-= 1 row selected.
RTRIM removes any character included in char_set from the right end of str.
A detailed description of the RTRIM function is as follows:
-
Syntax
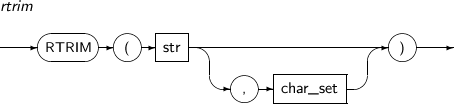
-
Component
Component Description str An expression that returns a string. char_set An expression that returns a string.
If this is not specified, the default value is a blank space.
-
Example
The following example shows how to use the RTRIM function.
SQL> SELECT RTRIM('ABCDE ') FROM DUAL; RTRIM('ABCDE') -------------- ABCDE 1 row selected. SQL> SELECT RTRIM('XYXABCDEXYX', 'XY') FROM DUAL; RTRIM('XYXABCDEXYX','XY') ------------------------- XYXABCDE 1 row selected.
SESSIONTIMEZONE returns the time zone of the current session.
A detailed description of the SESSIONTIMEZONE follows:
-
Syntax

-
Example
The following example shows how to use the SESSIONTIMEZONE function.
SQL> SELECT SESSIONTIMEZONE FROM DUAL; SESSIONTIMEZONE ------------------------- Asia/Seoul 1 row selected.
SIGN returns -1, 0, or +1 when num is negative, 0, or positive, respectively.
A detailed description of the SIGN function is as follows:
-
Syntax
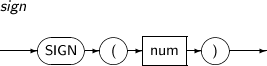
-
Component
Component Description num Expression that returns a numeric value.
Should be a NUMBER or a compatible type. The return type is a NUMBER.
If num is a NUMBER, the return values are shown below.
-
Less than 0: -1
-
0: 0
-
Greater than 0: 1
If num is a BINARY_FLOAT or BINARY_DOUBLE, the return values are shown below.
-
Less than 0: -1
-
Greater than or equal to 0, or NaN: 1
-
-
Example
The following example shows how to use the SIGN function.
SQL> SELECT SIGN(-10), SIGN(0), SIGN(15.5) FROM DUAL; SIGN(-10) SIGN(0) SIGN(15.5) ---------- ---------- ---------- -1 0 1 1 row selected.
SIN computes the sine of num.
A detailed description of the SIN function is as follows:
-
Syntax

-
Component
Component Description num An expression that returns a real number, in radians.
Should be a NUMBER or a compatible type. The return type is NUMBER.
If num is a BINARY FLOAT, it returns a BINARY DOUBLE. Otherwise, it returns the same type as num.
-
Example
The following example shows how to use the SIN function.
SQL> SELECT SIN(3.141592654 / 2.0) FROM DUAL; SIN(3.141592654/2.0) -------------------- 1 1 row selected.
SINH computes the hyperbolic sine of num.
A detailed description of the SINH function is as follows:
-
Syntax

-
Component
Component Description num An expression that returns a real number, in radians.
Should be a NUMBER or a compatible type.
If num is a BINARY FLOAT, it returns a BINARY DOUBLE. Otherwise, it returns the same type as num.
-
Example
The following example shows how to use the SINH function.
SQL> SELECT SINH(1) FROM DUAL; SINH(1) ---------- 1.17520119 1 row selected.
SKEW returns the skewness of expr.
This function takes any numeric data type and some non-numeric data types that can be implicitly converted to a numeric data type as an argument. This function returns a value of the numeric data type of the given parameter or the converted numeric data type.
A detailed description of the SKEW function is as follows:
-
Syntax

-
Component
Component Description set_quantifier Specifies whether to allow duplicate rows. One of the following can be set:
- DISTINCT, UNIQUE: Remove duplicate rows.
- ALL: includes all rows. This is the default value.
expr An expression to be calculated. -
Example
The following example shows how to use the SKEW function.
SQL> SELECT SKEW(SAL) FROM EMP; SKEW(SAL) ---------- 1.17469474 1 row selected.
SQRT computes the square root of num.
A detailed description of the SQRT function is as follows:
-
Syntax
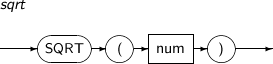
-
Component
Component Description num If num is a NUMBER, num cannot be a negative value. The return value is the same type as num.
If num is a BINARY_FLOAT or BINARY_DOUBLE, the return values are shown below.
-
num is greater than or equal to 0: A real number
-
num is less than 0: NaN
-
-
Example
The following example shows how to use the SQRT function.
SQL> SELECT SQRT(2.0) FROM DUAL; SQRT(2.0) ---------- 1.41421356 1 row selected.
STDDEV returns the sample standard deviation of expr. This function can be used as an analytic function. In Tibero, the sample standard deviation is calculated as the square root of the result of the VARIANCE aggregate function.
This function takes all numeric data types and some non-numeric data types that can be implicitly converted to a numeric data type as an argument. STDDEV returns a value of the numeric data type of the given parameter or the converted numeric data type.
The difference between STDDEV and STDDEV_SAMP is that STDDEV returns 0 if the input data is a single row while STDDEV_SAMP returns NULL.
A detailed description of the STDDEV function is as follows:
-
Syntax

-
Component
Component Description expr An expression that returns a numeric value. analytic_clause This function can be used as an analytic function using "OVER analytic_clause".
For detailed information, see analytic_clause in “4.1.3. Analytic Functions”.
-
Example
The following example shows how to use the STDDEV function.
SQL> SELECT STDDEV(AGE) FROM EMP_AGE; STDDEV(AGE) ----------- 3.034981237 1 row selected.
-
Example (Analytic Function)
The following example shows how to use the STDDEV function as an analytic function.
SQL> SELECT DEPTNO, EMPNO, STDDEV(SAL) OVER (PARTITION BY DEPTNO) AS STDDEV FROM EMP; DEPTNO EMPNO STDDEV ---------- ---------- ---------- 10 7934 1893.62967 10 7839 1893.62967 10 7782 1893.62967 20 7566 1123.3321 20 7788 1123.3321 20 7876 1123.3321 20 7902 1123.3321 20 7369 1123.3321 30 7654 668.331255 30 7698 668.331255 30 7521 668.331255 30 7499 668.331255 30 7844 668.331255 30 7900 668.331255 14 rows selected.
STDDEV_POP returns the population standard deviation of expr. This function can be used as an analytic function. InTibero, the population standard deviation is calculated as the square root of the result of the VARIANCE_POP aggregate function. This function returns a value of the numeric data type of the given parameter or the converted numeric data type.
A detailed description of the STDDEV_POP function is as follows:
-
Syntax

-
Component
Component Description expr An expression that returns a numeric data type or a compatible type. analytic_clause This function can be used as an analytic function using "OVER analytic_clause".
For detailed information, see analytic_clause in “4.1.3. Analytic Functions”.
-
Example
The following example shows how to use the STDDEV_POP function.
SQL> SELECT STDDEV_POP(AGE) FROM EMP_AGE; STDDEV_POP(AGE) --------------- 2.8792360097776 1 row selected.
-
Example (Analytic Function)
The following example shows how to use the STDDEV_POP function as an analytic function.
SQL> SELECT DEPTNO, EMPNO, STDDEV_POP(SAL) OVER (PARTITION BY DEPTNO) AS STDDEV_POP FROM EMP; DEPTNO EMPNO STDDEV_POP ---------- ---------- ---------- 10 7934 1546.14215 10 7839 1546.14215 10 7782 1546.14215 20 7566 1004.73877 20 7788 1004.73877 20 7876 1004.73877 20 7902 1004.73877 20 7369 1004.73877 30 7654 610.100174 30 7698 610.100174 30 7521 610.100174 30 7499 610.100174 30 7844 610.100174 30 7900 610.100174 14 rows selected.
STDDEV_SAMP returns the cumulative sample standard deviation of expr. This function can be used as an analytic function. In Tibero, the cumulative sample standard deviation is calculated as the square root of the result of the VARIANCE_SAMP aggregate function. This function returns a value of the numeric data type of the given parameter or the converted numeric data type.
A detailed description of the STDDEV_SAMP function is as follows:
-
Syntax

-
Component
Component Description expr An expression that returns a numeric data type or a compatible type. analytic_clause This function can be used as an analytic function using "OVER analytic_clause".
For detailed information, see analytic_clause in “4.1.3. Analytic Functions”.
-
Example
The following example shows how to use the STDDEV_SAMP function.
SQL> SELECT STDDEV_SAMP(AGE) FROM EMP_AGE; STDDEV_SAMP(AGE) ---------------- 3.03498123735734 1 row selected.
-
Example (Analytic Function)
The following example shows how to use the STDDEV_SAMP function as an analytic function.
SQL> SELECT DEPTNO, EMPNO, STDDEV_SAMP(SAL) OVER (PARTITION BY DEPTNO) AS STDDEV_SAMP FROM EMP; DEPTNO EMPNO STDDEV_SAMP ---------- ---------- ----------- 10 7782 1893.62967 10 7839 1893.62967 10 7934 1893.62967 20 7566 1123.3321 20 7902 1123.3321 20 7876 1123.3321 20 7369 1123.3321 20 7788 1123.3321 30 7521 668.331255 30 7844 668.331255 30 7499 668.331255 30 7900 668.331255 30 7698 668.331255 30 7654 668.331255 14 rows selected.
SUBSTR returns length characters of str beginning at position.
Alternatively, SUBSTRB uses bytes instead of characters to determine length.
A detailed description of the SUBSTR function is as follows:
-
Syntax

-
Component
Component Description str An expression that returns a string.
position An expression that returns an integer.
The first character in a string has a position of 1.
If this value is 0, it is treated as if it were 1. If it is less than 0, the function counts in reverse from the end of the string.
length An expression that returns an integer.
If this is not specified, SUBSTR returns the remainder of the string after position. If it is less than 1, NULL is returned.
-
Example
The following example shows how to use the SUBSTRB function.
SQL> SELECT SUBSTR('ABCDEFG', 3), SUBSTR('ABCDEFG', 3, 2) FROM DUAL; SUBSTR('ABCDEFG',3) SUBSTR('ABCDEFG',3,2) ------------------- --------------------- CDEFG CD 1 row selected. SQL> SELECT SUBSTR('ABCDEFG', -3), SUBSTR('ABCDEFG', -3, 2) FROM DUAL; SUBSTR('ABCDEFG',-3) SUBSTR('ABCDEFG',-3,2) -------------------- ---------------------- EFG EF 1 row selected.
SUM returns the sum of expr values for all rows in a group. This function can be used as an analytic function.
If DISTINCT is specified when this function is used as an analytic function, only query_partition_clause can be specified in analytic_clause, and order_by_clause cannot be specified.
A detailed description of the SUM function is as follows:
-
Syntax

-
Component
Component Description set_quantifier Specifies whether to allow duplicate rows. One of the following can be set:
-
DISTINCT, UNIQUE: Remove duplicate rows.
-
ALL: includes all rows. This is the default value.
expr An expression.
If DISTINCT is specified before expr, duplicate expr values are removed before computing a maximum value.
analytic_clause This function can be used as an analytic function using "OVER analytic_clause".
For detailed information, see analytic_clause in “4.1.3. Analytic Functions”.
-
-
Example
The following example shows how to use the SUM function.
SQL> SELECT DEPTID, SUM(SALARY) FROM EMP2 GROUP BY DEPTID; DEPTID SUM(SALARY) ---------- ---------- 1 14700 2 19200 2 rows selected. -
Example (Analytic Function)
The following example shows how to use the SUM function as an analytic function.
SQL> SELECT NAME, DEPTID, SALARY, SUM(SALARY) OVER (PARTITION BY DEPTID) FROM EMP2; NAME DEPTID SALARY SUM(SALARY) -------------------- ---------- ---------- ---------- Paul 1 3000 14700 Nick 1 3200 14700 Scott 1 4000 14700 John 1 4500 14700 Bree 2 6000 19200 Daniel 2 5000 19200 Joe 2 4000 19200 Brad 2 4200 19200 8 rows selected. SQL> SELECT NAME, SALARY, SUM(SALARY) OVER (ORDER BY SALARY RANGE UNBOUNDED PRECEDING) FROM EMP3; NAME SALARY SUM(SALARY) -------------------- ---------- ---------- Paul 3000 3000 Nick 3200 9400 Scott 3200 9400 John 3500 12900 Bree 4000 16900 Daniel 4500 25900 Joe 4500 25900 7 rows selected.
SYS_CONNECT_BY_PATH returns the path of expr from root to node. This function is valid only in hierarchical queries. Each column value in the returned path is separated by char.
A detailed description of the SYS_CONNECT_BY_PATH function is as follows:
-
Syntax

-
Component
Component Description expr, char One of the following types: CHAR, VARCHAR2, NCHAR, or NVARCHAR2.
The returned string is a VARCHAR2 and is in the same character set as expr.
-
Example
The following example shows how to use the SYS_CONNECT_BY_PATH function.
SQL> SELECT ENAME, CONNECT_BY_ROOT ENAME MANAGER, SYS_CONNECT_BY_PATH(ENAME, '-') PATH FROM EMP2 WHERE LEVEL > 1 CONNECT BY PRIOR EMPNO = MGRNO START WITH ENAME = 'Clark'; ENAME MANAGER PATH --------------- --------------- ----------------------- Martin Clark -Clark-Martin James Clark -Clark-Martin-James Alicia Clark -Clark-Martin-Alicia Ramesh Clark -Clark-Ramesh Allen Clark -Clark-Ramesh-Allen JohnClark Clark -Ramesh-John Ward Clark -Clark-Ramesh-John-Ward 7 rows selected.
SYS_CONTEXT returns the argument value associated with the context namespace. The context namespace and argument can be defined as a string or an expression. This function returns a VARCHAR. In Tibero, the default context namespace is USERENV. A user can create a context namespace using the CREATE CONTEXT DDL statement. The return value of SYS_CONTEXT for each parameter of the namespace can be specified using the procedure DBMS_SESSION.SET_CONTEXT.
A detailed description of the SYS_CONTEXT function is as follows:
-
Syntax

-
Component
Component Description namespace A value to define the context. param A parameter name associated with the context namespace. -
Example
The following example shows how to use the SYS_CONTEXT function.
SQL> SELECT SYS_CONTEXT('USERENV', 'TID') "TID" FROM DUAL; TID --- 1 1 row selected.The following example illustrates how the SYS_CONTEXT function displays the result when the attr0 parameter of the ctx0 namespace is configured through the specified package.
SQL> SELECT SYS_CONTEXT('ctx0', 'attr0') "ATTR0" FROM DUAL; ATTR0 ----- val0 1 row selected. -
USERENV parameters
Parameter Description CLIENT_IDENTIFIER Returns the client identifier defined in the DBMS_SESSION.SET_IDENTIFIER procedure. CURRENT_SCHEMA Returns the name of the currently active schema. This value can be changed by the ALTER SESSION SET CURRENT_SCHEMA statement. CURRENT_SCHEMAID Returns the identification number of the currently active schema. DB_NAME Returns the database name defined in the DB_NAME initialization parameter. HOST Returns the name of the device in which the client is running. INSTANCE_NAME Returns the current instance name. INSTANCE Returns the current instance identification number. IP_ADDR[ESS] Returns the client IP address. LANG Returns the abbreviation of the 'LANGUAGE' parameter. LANGUAGE Returns the database character set name. MODULE Returns the module name defined by the DBMS_APPLICATION_INFO.SET_MODULE procedure. NETWORK_PROTOCOL Returns the network protocol name for two-way communication. OS_USER Returns the OS user name of the client process. SCHEMA Returns the access schema name of the client. SCHEMAID Returns the access user identification number. SERVER_ADDRESS Returns the IP address of the device in which the current instance is running. SERVER_HOST Returns the name of the device in which the current instance is running. SESSION_USER Returns the access user name of the client. SESSIONID Returns the session monitoring identification number. TERMINAL Returns the OS identifier of the client. TID Returns the identification number of the current session.
SYS_EXTRACT_UTC converts a datetime value that includes time zone information to UTC (Coordinated Universal Time).
A detailed description of the SYS_EXTRACT_UTC function is as follows:
-
Syntax

-
Component
Component Description datetime_with_timezone An expression that returns a datetime value that includes time zone information. -
Example
The following example shows how to use the SYS_EXTRACT_UTC function.
SQL> SELECT SYS_EXTRACT_UTC(TIMESTAMP '1994/07/23 21:13:08 -8:00') FROM DUAL; SYS_EXTRACT_UTC(TIMESTAMP'1994/07/2321:13:08-8:00') --------------------------------------------------- 1994/07/24 05:13:08.000000 1 row selected.
SYS_GUID returns a globally unique value. The return value is a 16 byte RAW type that consists of a thread number, a host name, a connection time, and a sequence number.
A detailed description of the SYS_GUID function is as follows:
-
Syntax
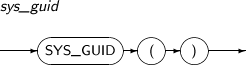
-
Example
The following example shows how to use the SYS_GUID function.
SQL> SELECT SYS_GUID() "SYS_GUID" FROM DUAL; SYS_GUID -------------------------------- 120000000080087893B1484201000000 1 row selected.
SYSDATE returns the current date and time as a DATE. This function takes no arguments and does not use parentheses.
A detailed description of the SYSDATE function is as follows:
-
Syntax

-
Example
The following example shows how to use the SYSDATE function.
SQL> SELECT SYSDATE FROM DUAL; SYSDATE ---------- 2009-12-03 1 row selected.
SYSTIME returns the current time as a TIME. This function takes no arguments and does not use parentheses.
A detailed description of the SYSTIME function is as follows:
-
Syntax

-
Example
The following example shows how to use the SYSTIME function.
SQL> SELECT SYSTIME FROM DUAL; SYSTIME --------------- 13:42:05.455775 1 row selected.
SYSTIMESTAMP returns the current date and time as a TIMESTAMP WITH TIME ZONE. This function takes no arguments and does not use parentheses.
A detailed description of the SYSTIMESTAMP function is as follows:
-
Syntax

-
Example
The following example shows how to use the SYSTIMESTAMP function.
SQL> SELECT SYSTIMESTAMP FROM DUAL; SYSTIMESTAMP ----------------------------------------- 2009/12/03 13:42:45.816763 Asia/Seoul 1 row selected.
TAN computes the tangent of num.
A detailed description of the TAN function is as follows:
-
Syntax
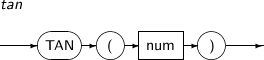
-
Component
Component Description num An expression that returns a real number, in radians.
Should be a NUMBER or a compatible type. The return type is NUMBER.
If num is a BINARY FLOAT, it returns a BINARY DOUBLE. Otherwise, it returns the same type as num.
-
Example
The following example shows how to use the TAN function.
SQL> SELECT TAN(3.141592654 * 45.0 / 180.0) FROM DUAL; TAN(3.141592654*45.0/180.0) --------------------------- 1 1 row selected.
TANH computes the hyperbolic tangent of num.
A detailed description of the TANH function is as follows:
-
Syntax
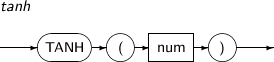
-
Component
Component Description num An expression that returns a real number, in radians.
Should be a NUMBER or a compatible type. The return type is NUMBER.
If num is a BINARY FLOAT, it returns a BINARY DOUBLE. Otherwise, it returns the same type as num.
-
Example
The following example shows how to use the TANH function.
SQL> SELECT TANH(1) FROM DUAL; TANH(1) ---------- .761594156 1 row selected.
TIMESTAMP_TO_TSN returns a TSN value closest to the given time value.
A detailed description of the TIMESTAMP_TO_TSN function is as follows:
-
Syntax
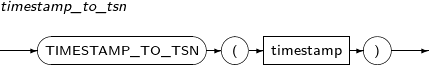
-
Component
Component Description timestamp Expression that returns a time value. -
Example
The following example shows how to use the TIMESTAMP_TO_TSN function.
SQL> SELECT TIMESTAMP_TO_TSN(SYSTIMESTAMP) FROM DUAL; TIMESTAMP_TO_TSN(SYSTIMESTAMP) ------------------------------ 382716 1 row selected.
TO_BINARY_DOUBLE converts expr to a BINARY_DOUBLE according to the specified format.
A detailed description of the TO_BINARY_DOUBLE function is as follows:
-
Syntax

-
Component
Component Description expr Expression that returns a string or number.
Supports the following special strings. It is not case-sensitive.
-
'INF' is converted to positive infinity.
-
'-INF' is converted to negative infinity.
-
'NaN' is converted to NaN (Not A Number).
Floating-point number format elements (f, F, d, D) cannot be used.
format NUMBER type string.
If this is not specified, expr is converted into the default format.
Format is applicable when expr is a string.
-
-
Example
The following example shows how to use the TO_BINARY_DOUBLE function.
SQL> SELECT TO_BINARY_DOUBLE(3.141592), TO_BINARY_DOUBLE('+inf') FROM DUAL; TO_BINARY_DOUBLE(3.141592) TO_BINARY_DOUBLE('+INF') -------------------------- ------------------------ 3.142E+000 Inf 1 row selected.
TO_BINARY_FLOAT A detailed description of the TO_BINARY_FLOAT function is as follows:
A detailed description of the TO_BINARY_FLOAT function is as follows:
-
Syntax

-
Component
Component Description expr Expression that returns a string or number.
Supports the following special strings. It is not case-sensitive.
-
'INF' is converted to positive infinity.
-
'-INF' is converted to negative infinity.
-
'NaN' is converted to NaN (Not A Number).
Floating-point number format elements (f, F, d, D) cannot be used.
format NUMBER type string.
If this is not specified, expr is converted into the default format.
Format is applicable when expr is a string.
-
-
Example
The following example shows how to use the TO_BINARY_FLOAT function.
SQL> SELECT TO_BINARY_FLOAT(3.141592), TO_BINARY_FLOAT('-inf') FROM DUAL; TO_BINARY_FLOAT(3.141592) TO_BINARY_FLOAT('-INF') ------------------------- ----------------------- 3.142E+000 -Inf 1 row selected.
TO_CHAR(character) converts clob to a string that uses the database character set.
A detailed description of the TO_CHAR(character) function is as follows:
-
Syntax
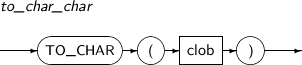
-
Component
Component Description clob A CLOB to be converted to a string. -
Example
The following example shows how to use the TO_CHAR(character) function.
SQL> SELECT TO_CHAR(contents) FROM BOOK;
TO_CHAR(datetime) converts date to a string based on the format string format.
A detailed description of the TO_CHAR(datetime) function is as follows:
-
Syntax

-
Component
Component Description date An expression that returns a datetime type value. format A datetime type format string.
If this is not specified, date will be converted to a string using the default format.
For detailed information on datetime format strings, see “2.4.2. Datetime Types”.
-
Example
The following example shows how to use the TO_CHAR(datetime) function.
SQL> SELECT TO_CHAR(SYSDATE) FROM DUAL; TO_CHAR(SYSDATE) -------------------------------- 2006/12/06 1 row selected. SQL> SELECT TO_CHAR(SYSDATE, 'DD/MM/YY DY') FROM DUAL; TO_CHAR(SYSDATE,'DD/MM/YYDY') ----------------------------- 06/12/06 WED 1 row selected.
TO_CHAR(number) converts a NUMBER num to a string based on the format format.
A detailed description of the TO_CHAR(number) function is as follows:
-
Syntax
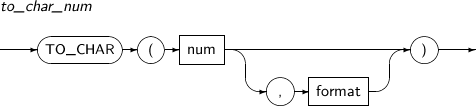
-
Component
Component Description num An expression that returns a NUMBER. format A NUMBER format string.
If this is not specified, all valid numbers in num will be converted to a string using the default format.
For detailed information on NUMBER format strings, see “2.4.1. NUMBER Types”.
-
Example
The following example shows how to use the TO_CHAR(number) function.
SQL> SELECT TO_CHAR(MIN(SALARY)) FROM EMP; TO_CHAR(MIN(SALARY)) -------------------- 3000 1 row selected. SQL> SELECT TO_CHAR(MIN(SALARY), '$99,999,99') FROM EMP; TO_CHAR(MIN(SAL),'$99,999,99') ------------------------------ $30,00 1 row selected.
TO_CLOB converts lob_column or char to a CLOB.
A detailed description of the TO_CLOB function is as follows:
-
Syntax
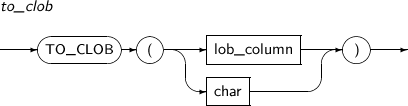
-
Component
Component Description lob_column A CHAR, VARCHAR, or CLOB column. char An expression that returns a string. -
Example
The following example shows how to use the TO_CLOB function.
SQL> SELECT TO_CLOB('tibero') FROM DUAL; TO_CLOB('TIBERO') ----------------- tibero 1 row selected.
TO_DATE converts str to a DATE based on the format format.
A detailed description of the TO_DATE function is as follows:
-
Syntax

-
Component
Component Description str An expression that returns a string. format A datetime type format string.
If this is not specified, str will be converted using the default format.
-
Example
The following example shows how to use the TO_DATE function.
SQL> SELECT TO_DATE('25/12/2004', 'DD/MM/YYYY') FROM DUAL; TO_DATE('25/12/2004','DD/MM/YYYY') ---------------------------------- 2004/12/25 1 row selected.
TO_DSINTERVAL converts a CHAR, VARCHAR2, NCHAR, or NVARCHAR2, char, to an INTERVAL DAY TO SECOND.
A detailed description of the TO_DSINTERVAL function is as follows:
-
Syntax

-
Component
Component Description days An integer between 0 and 999,999,999. hours An integer between 0 and 23 minutes, seconds An integer between 0 and 59. frac_secs An integer between 0 and 999,999,999. -
Example
The following example computers the date 50 days prior to March 20, 2008 using the TO_DSINTERVAL function.
SQL> SELECT DATE '2008-03-20' - TO_DSINTERVAL('50 00:00:00') BEFORE FROM DUAL; BEFORE ---------------------- 2008-01-30 1 row selected.
TO_LOB converts a LONG or LONG RAW column long_column to a CLOB or BLOB, respectively. Only a LONG or LONG RAW type column can be a parameter. It can only be used in a subquery of an INSERT statement or a subquery of an UPDATE statement that updates the column value.
A detailed description of the TO_LOB function is as follows:
-
Syntax
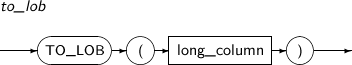
-
Component
Component Description long_column A LONG OR LONG_RAW column. -
Example
The following example shows how to use the TO_LOB function.
SQL> CREATE TABLE LONG_TABLE (ID NUMBER, LONG_COL LONG); Table 'LONG_TABLE' created. SQL> INSERT INTO LONG_TABLE VALUES (1, 'first'); 1 row inserted. SQL> CREATE TABLE CLOB_TABLE AS 2 SELECT ID, TO_LOB(LONG_COL) CLOB_COL FROM LONG_TABLE; Table 'CLOB_TABLE' created. SQL> SELECT * FROM CLOB_TABLE; ID CLOB_COL ---------- ---------- 1 first 1 row selected. SQL> INSERT INTO LONG_TABLE VALUES (2, 'second'); 1 row inserted. SQL> INSERT INTO LONG_TABLE VALUES (3, 'third'); 1 row inserted. SQL> INSERT INTO CLOB_TABLE 2 SELECT ID, TO_LOB(LONG_COL) FROM LONG_TABLE WHERE ID = 2; 1 row inserted. SQL> SELECT * FROM CLOB_TABLE; ID CLOB_COL ---------- ---------- 1 first 2 second 2 rows selected. SQL> UPDATE CLOB_TABLE 2 SET CLOB_COL = (SELECT TO_LOB(LONG_COL) FROM LONG_TABLE WHERE ID = 3) 3 WHERE ID = 2; 1 row updated. SQL> SELECT * FROM CLOB_TABLE; ID CLOB_COL ---------- ---------- 1 first 2 third 2 rows selected.
TO_MULTI_BYTE converts str to multibyte characters. The argument can be a VARCHAR, CHAR, NCHAR, or NVARCHAR. The return value type is the same as the argument type.
A detailed description of the TO_MULTI_BYTE function is as follows:
-
Syntax
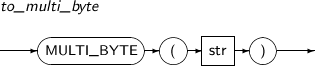
-
Component
Component Description str A value to be converted to multibyte characters. -
Example
The following example shows how to use the TO_MULTI_BYTE function.
SQL> SELECT DUMP(TO_MULTI_BYTE('A')) "TO_MULTI_BYTE" FROM DUAL; TO_MULTI_BYTE -------------- Len=2: 163,193 1 row selected.
TO_NCHAR converts str to a value of the national character set. The argument can be a CHAR, VARCHAR, CLOB, or NCLOB.
A detailed description of the TO_NCHAR function is as follows:
-
Syntax

-
Component
Component Description str A value to be converted to the national character set. -
Example
The following example shows how to use the TO_NCHAR function.
SQL> SELECT TO_NCHAR(LAST_NAME) "LAST_NAME" FROM EMP WHERE EMP_ID = 5; LAST_NAME --------- Braun 1 row selected.
TO_NUMBER converts str to a NUMBER based on the format format.
A detailed description of the TO_NUMBER function is as follows:
-
Syntax
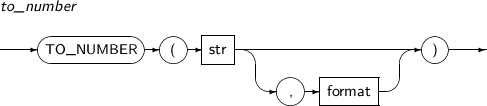
-
Component
Component Description str An expression that returns a string. format A NUMBER format string.
If this is not specified, str is converted using the default format.
-
Example
The following example shows how to use the TO_NUMBER function.
SQL> SELECT TO_NUMBER('$35,000.00', '$99,999.99') FROM DUAL; TO_NUMBER('$35,000.00','$99,999.99') ------------------------------------ 35000 1 row selected.
TO_SINGLE_BYTE converts str to single-byte characters. The argument can be a VARCHAR, CHAR, NCHAR, or NVARCHAR. The return value type is the same as the argument type.
A detailed description of the TO_SINGLE_BYTE function is as follows:
-
Syntax

-
Component
Component Description str A value to be converted to single-byte characters. -
Example
The following example shows how to use the TO_SINGLE_BYTE function.
SQL> SELECT DUMP(TO_SINGLE_BYTE(TO_MULTI_BYTE('A'))) "TO_SINGLE_BYTE" FROM DUAL; TO_SINGLE_BYTE -------------------------------------------------------------------------------- Len=1: 65 1 row selected.
TO_TIME converts str to a TIME based on the format string format.
A detailed description of the TO_TIME function is as follows:
-
Syntax
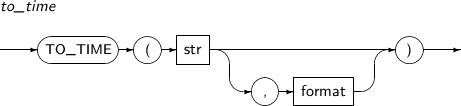
-
Component
Component Description str An expression that returns a string. format A datetime format string.
If this is not specified, str will be converted using the default format.
-
Example
The following example shows how to use the TO_TIME function.
SQL> SELECT TO_TIME ('12:07:15.50', 'HH24:MI:SS.FF') FROM DUAL; TO_TIME('12:07:15.50','HH24:MI:SS.FF') -------------------------------------- 12:07:15.500000000 1 row selected.
TO_TIMESTAMP converts str to a TIMESTAMP based on the format string format.
A detailed description of the TO_TIMESTAMP function is as follows:
-
Syntax
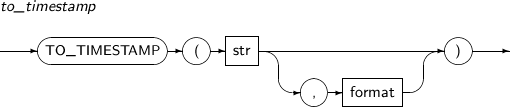
-
Component
Component Description str An expression that returns a string. format A datetime format string.
If this is not specified, str will be converted using the default format.
-
Example
The following example shows how to use the TO_TIMESTAMP function.
SQL> SELECT TO_TIMESTAMP('2009/05/21 12:07:15.50','yyyy-mm-dd HH24:MI:SS.FF') FROM DUAL; TO_TIMESTAMP('2009/05/2112:07:15.50','YYYY-MM-DDHH24:MI:SS.FF') ----------------------------------------------------------------- 2009/05/21 12:07:15.500000 1 row selected.
TO_TIMESTAMP_TZ converts str to the TIMESTAMP WITH TIME ZONE type according to the specified format.
A detailed description of the TO_TIMESTAMP_TZ function is as follows:
-
Syntax

-
Component
Component Description str An expression that returns a string.
If the string does not include time zone information, the default time zone of the session will be used.
format A datetime format string.
If this is not specified, str will be converted using the default format.
-
Example
The following example shows how to use the TO_TIMESTAMP_TZ function.
SQL> SELECT TO_TIMESTAMP_TZ('1998/09/27 22:05:21.089','YYYY-MM-DD HH24:MI:SS.FF') FROM DUAL; TO_TIMESTAMP_TZ('1998/09/2722:05:21.089','YYYY-MM-DDHH24:MI:SS.FF') ------------------------------------------------------------------ 1998/09/27 22:05:21.089000 Asia/Seoul 1 row selected. SQL> SELECT TO_TIMESTAMP_TZ('2015-10-3 2:17:09.0 +03:00', 'YYYY-MM-DD HH24:MI:SS.FF TZH:TZM') FROM DUAL; TO_TIMESTAMP_TZ('2015-10-32:17:09.0+03:00','YYYY-MM-DDHH24:MI:SS.FFTZH:TZM') ------------------------------------------------------------------------------- 2015/10/03 02:17:09.000000 +03:00 1 row selected.
TO_YMINTERVAL converts a string in the CHAR, VARCHAR2, NCHAR, or NVARCHAR2 type to the INTERVAL YEAR TO MONTH type.
A detailed description of the TO_YMINTERVAL function is as follows:
-
Syntax
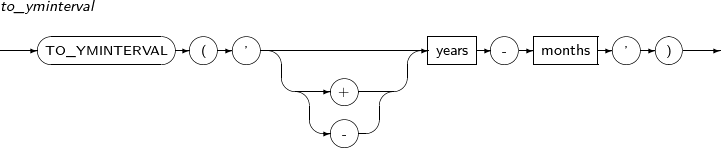
-
Component
Component Description years An integer between 0 and 999,999,999.
months An integer between 0 and 11.
-
Example
The following example illustrates how to use TO_YMINTERVAL to find the date 2 years and 7 months after March 20, 2008.
SQL> SELECT DATE '2008-03-20' + TO_YMINTERVAL('2-7') AFTER FROM DUAL; AFTER ---------------------- 2010-10-20 1 row selected.
TRANSLATE returns a string where each character in from_str has been replaced with the corresponding character in str.
A detailed description of the TRANSLATE function is as follows:
-
Syntax

-
Component
Component Description str An expression that returns a string. from_str An expression that returns a string.
When from_str is longer than to_str, some characters in from_str have no corresponding characters in to_str. In this case, the characters are removed from str.
to_str An expression that returns a string. -
Example
The following example shows how to use the TRANSLATE function.
SQL> SELECT TRANSLATE('ABCXYDEFZ', 'ABCDE', '12345') FROM DUAL; TRANSLATE('ABCXYDEFZ','ABCDE','12345') -------------------------------------- 123XY45FZ 1 row selected. SQL> SELECT TRANSLATE('ABCXYDEFZ', 'ABCDE', '123') FROM DUAL; TRANSLATE('ABCXYDEFZ','ABCDE','123') ------------------------------------ 123XYFZ 1 row selected.
TRIM removes all occurrences of trim_character from the beginning and the end of str.
A detailed description of the TRIM function is as follows:
-
Syntax

-
Component
Component Description str An expression that returns a string. LEADING If LEADING is specified before trim_character, trim_character is only removed from the beginning of str. TRAILING If TRAILING is specified before trim_character, trim_character is only removed from the end of str. BOTH If BOTH or nothing is specified before trim_character, trim_character is removed from the beginning and end of str. trim_character A single-length character.
If this is not specified, blank spaces are removed.
-
Example
The following example shows how to use the TRIM function.
SQL> SELECT TRIM(' ABCDE '), LENGTH(TRIM(' ABCDE ')) FROM DUAL; TRIM('ABCDE') LENGTH(TRIM('ABCDE')) ------------- --------------------- ABCDE 5 1 row selected. SQL> SELECT TRIM(LEADING 'X' FROM 'XXYXABCDEXYXX') FROM DUAL; TRIM(LEADING'X'FROM'XXYXABCDEXYXX') ----------------------------------- YXABCDEXYXX 1 row selected. SQL> SELECT TRIM(TRAILING 'X' FROM 'XXYXABCDEXYXX') FROM DUAL; TRIM(TRAILING'X'FROM'XXYXABCDEXYXX') ------------------------------------ XXYXABCDEXY 1 row selected. SQL> SELECT TRIM('X' FROM 'XXYXABCDEXYXX') FROM DUAL; TRIM('X'FROM'XXYXABCDEXYXX') ---------------------------- YXABCDEXYs 1 row selected.
TRUNC(number) returns num1 truncated to num2 decimal places.
A detailed description of the TRUNC(number) function is as follows:
-
Syntax
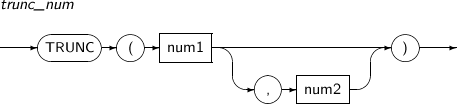
-
Component
Component Description num1, num2 An expression that returns an integer value.
Num1 and num2 must be a numeric type or one that can be converted into a numeric type.
Num2 must be a positive number. If num2 is not specified or is 0, num1 is truncated to 0 decimal places.
If num2 is negative, num1 is truncated to num2 digits to the left of the decimal point.
-
Example
The following example shows how to use the TRUNC(number) function.
SQL> SELECT TRUNC(345.678), TRUNC(345.678, 2), TRUNC(345.678, -1) FROM DUAL; TRUNC(345.678) TRUNC(345.678,2) TRUNC(345.678,-1) -------------- ---------------- ----------------- 345 345.67 340 1 row selected.
TRUNC(date) returns date truncated based on the format string format.
Note
The format string that can be specified in format of the TRUNC(date) function is the same as that of the ROUND(date) function.
A detailed description of the TRUNC(date) function is as follows:
-
Syntax
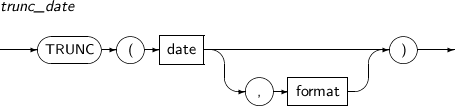
-
Component
Component Description date An expression that returns a date. format A format string that specifies the unit of truncation.
If this is not specified, date is truncated to the nearest date using the "DD" type string.
"YEAR", "MONTH", "DAY" and other formats can be used.
-
Example
The following example shows how to use the TRUNC(date) function.
SQL> SELECT TRUNC(TO_DATE('2005/06/22', 'YYYY/MM/DD'), 'YEAR') FROM DUAL; TRUNC(TO_DATE('2005/06/22','YYYY/MM/DD'),'YEAR') ----------------------------------------------------------------- 2005-01-01 1 row selected. SQL> SELECT TO_CHAR(TRUNC(TO_DATE( '1998/6/20', 'YYYY/MM/DD'), 'CC'), 'YYYY/MM/DD') FROM DUAL; TO_CHAR(TRUNC(TO_DATE('1998/6/20','YYYY/MM/DD'),'CC'),'YYYY/MM/DD') ------------------------------------------------------------------- 1901/01/01 1 row selected. SQL> SELECT TO_CHAR(TRUNC(TO_DATE('-3741/01/02', 'SYYYY/MM/DD'), 'CC'), 'SYYYY/MM/DD') FROM DUAL; TO_CHAR(TRUNC(TO_DATE('-3741/01/02','SYYYY/MM/DD'),'CC'),'SYYYY/MM/DD') ----------------------------------------------------------------------- -3800/01/01 1 row selected. SQL> SELECT TO_CHAR(TRUNC(TO_DATE( '2005/01/26 12:30:14', 'YYYY/MM/DD HH24:MI:SS'), 'DY'), 'YYYY/MM/DD') FROM DUAL; TO_CHAR(TRUNC(TO_DATE('2005/01/2612:30:14','YYYY/MM/DDHH24:MI:SS'),'DY'),'YYYY/M -------------------------------------------------------------------------------- 2005/01/23 1 row selected. SQL> SELECT TRUNC(TO_DATE( '2005/01/26 12:30:14', 'YYYY/MM/DD HH24:MI:SS')) FROM DUAL; TRUNC(TO_DATE('2005/01/2612:30:14','YYYY/MM/DDHH24:MI:SS')) ----------------------------------------------------------------- 2005-01-26 1 row selected.
TSN_TO_TIMESTAMP returns a time value closest to the specified TSN.
A detailed description of the TSN_TO_TIMESTAMP function is as follows:
-
Syntax

-
Component
Component Description num Expression that returns a number. -
Example
The following example shows how to use the TSN_TO_TIMESTAMP function.
SQL> SELECT TSN_TO_TIMESTAMP(527720) FROM DUAL; TSN_TO_TIMESTAMP(527720) ----------------------------------------------------------------- 2014/11/27 09:34:01.708203000 1 row selected.
TZ_OFFSET returns the time zone offset type value corresponding to an argument.
A detailed description of the TZ_OFFSET function is as follows:
-
Syntax

-
Component
Component Description timezone_name A string that represents a time zone region name. [+|-]hh:mi A string that represents a time zone offset value. SESSIONTIMEZONE A string that represents the time zone value of the current session. -
Example
The following example shows how to use the TZ_OFFSET function.
SQL> SELECT TZ_OFFSET('-5:00') FROM DUAL; TZ_OFFSET('-5:00') ------------------------------ -05:00 1 row selected.
TZ_SHIFT converts the given time zone to the specified time zone.
A detailed description of the TZ_SHIFT function is as follows:
-
Syntax
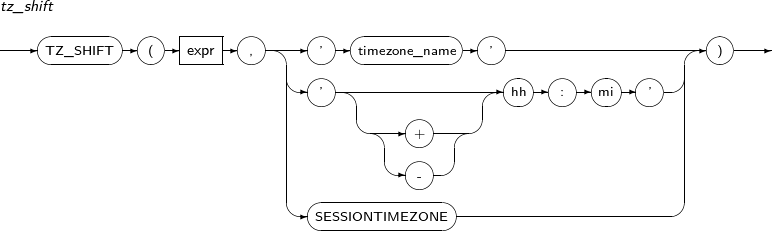
-
Component
Component Description expr An expression that returns the time value, including the time zone information. timezone_name A string that returns the time zone name. [+|-]hh:mi A string that returns the time zone offset value. SESSIONTIMEZONE A function that returns the time zone of the current session. -
Example
The following example illustrates how to use the TZ_SHIFT function.
SQL> SELECT TZ_SHIFT(FROM_TZ(TIMESTAMP '2002-09-08 21:00:00', '00:00'), '+09:00') SEOUL FROM DUAL; SEOUL --------------------------------- 2002/09/09 06:00:00.000000 +09:00 1 row selected.
UID returns the ID of the user who created the current session. The user ID is the only integer that identifies the user in Tibero. This function takes no parameters and does not use parentheses.
A detailed description of the UID function is as follows:
-
Syntax
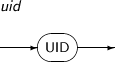
-
Example
The following example shows how to use the UID function.
SQL> SELECT UID FROM DUAL; UID ---------- 7171 1 row selected.
UNISTR takes a UNICODE string and returns a string encoded with an international character set. The UNICODE string has the form "\xxxx" where xxxx is the hexadecimal value of a character in the UCS-2 encoding format.
A detailed description of the UNISTR function is as follows:
-
Syntax
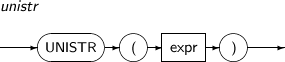
-
Component
Component Description expr An expression that returns a string. -
Example
The following example shows how to use the UNISTR function.
SQL> SELECT UNISTR('\00E5\00F1\00F6') FROM DUAL; UNISTR('\00E5\00F1\00F6') ------------------------- 1 row selected.
UPDATEXML takes an XPath expression and an XMLType instance pair as an argument and returns the updated XMLType instance. Each xpath_string in the XMLType instance is replaced by a value in value_expr. Actual XML column values are not changed, and the changed XMLType instance is returned. If there is no node corresponding to xpath_string, the original XMLType instance is returned.
A detailed description of the UPDATEXML function is as follows:
-
Syntax
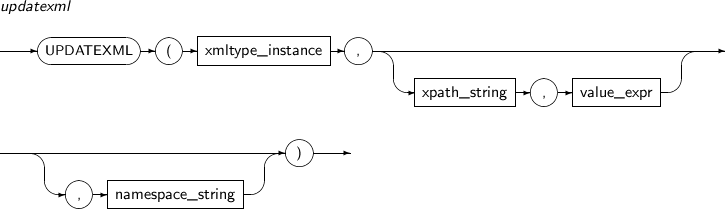
-
Component
Component Description xmltype_instance An XMLType instance. xpath_string Child nodes of the location to be updated by the Xpath expression are updated. value_expr New values of child nodes to be updated. namespace_string Provides namespace information for xpath_string. It must be a VARCHAR. -
Example
The following example shows how to use the UPDATEXML function.
SQL> SELECT warehouse_name, EXTRACT(warehouse_spec, '/Warehouse/Docks') "Number of Docks" FROM warehouses WHERE warehouse_name = 'San Francisco'; WAREHOUSE_NAME Number of Docks -------------------- -------------------- San Francisco <Docks>1</Docks> SQL> UPDATE warehouses SET warehouse_spec = UPDATEXML(warehouse_spec, '/Warehouse/Docks/text()',4) WHERE warehouse_name = 'San Francisco'; 1 row updated. SQL>SELECT warehouse_name, EXTRACT(warehouse_spec, '/Warehouse/Docks') "Number of Docks" FROM warehouses WHERE warehouse_name = 'San Francisco'; WAREHOUSE_NAME Number of Docks -------------------- -------------------- San Francisco <Docks>4</Docks>
UPPER returns str with all letters in uppercase.
A detailed description of the UPPER function is as follows:
-
Syntax
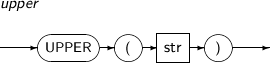
-
Component
Component Description str An expression that returns a string. -
Example
The following example shows how to use the UPPER function.
SQL> SELECT UPPER('ABCdefg123') FROM DUAL; UPPER('ABCDEFG123') ------------------- ABCDEFG123 1 row selected.
USER returns the name of the user who created the current session. This function takes no parameters and does not use parentheses.
-
Syntax

-
Example
The following example shows how to use the USER function.
SQL> SELECT USER FROM DUAL; USER ------------------------------ JOE 1 row selected.
USERENV shows information about the current session. This function currently only shows the thread ID of the current session.
Note
For more information about the parameters provided by the USERENV function, refer to “4.2.145. SYS_CONTEXT”.
A detailed description of the USERENV function is as follows:
-
Syntax
-
Component
Component Description str An expression that returns a string. -
Example
The following example shows how to use the USERENV function.
SQL> SELECT USERENV('TID') FROM DUAL; USERENV('TID') ---------------------------------------------------------------- 7 1 row selected.
VAR_POP returns the population variance of expr. This function ignores NULL values and returns a numeric or converted numeric data type of a given parameter. If this function is applied to an empty set, it returns NULL.
The population variance is calculated with the following formula:
(SUM(expr2) - SUM(expr)2 / COUNT(expr)) / COUNT(expr)
A detailed description of the VAR_POP function is as follows:
-
Syntax

-
Component
Component Description expr An expression that returns a numeric data type or a compatible type. analytic_clause This function can be used as an analytic function using "OVER analytic_clause".
For detailed information, see analytic_clause in “4.1.3. Analytic Functions”.
-
Example
The following example shows how to use the VAR_POP function.
SQL> SELECT VAR_POP(AGE) FROM EMP_AGE; VAR_POP(AGE) ------------ 8.29 1 row selected. -
Example (Analytic Function)
The following example shows how to use the VAR_POP function as an analytic function.
SQL> SELECT DEPTNO, EMPNO, VAR_POP(SAL) OVER (PARTITION BY DEPTNO) AS VAR_POP FROM EMP; DEPTNO EMPNO VAR_POP ---------- ---------- ---------- 10 7934 2390555.56 10 7839 2390555.56 10 7782 2390555.56 20 7566 1009500 20 7788 1009500 20 7876 1009500 20 7902 1009500 20 7369 1009500 30 7654 372222.222 30 7698 372222.222 30 7521 372222.222 30 7499 372222.222 30 7844 372222.222 30 7900 372222.222 14 rows selected.
VAR_SAMP returns the sample variance of expr. This function ignores NULL values and returns a numeric or converted numeric data type of a given parameter. If this function is applied to an empty set, it returns NULL.
The sample variance is calculated with the following formula:
(SUM(expr2) - SUM(expr)2 / COUNT(expr)) / (COUNT(expr) - 1)
A detailed description of the VAR_SAMP function is as follows:
-
Syntax

-
Component
Component Description expr An expression that returns a numeric data type or a compatible type. analytic_clause This function can be used as an analytic function using "OVER analytic_clause".
For detailed information, see analytic_clause in “4.1.3. Analytic Functions”.
-
Example
The following example shows how to use the VAR_SAMP function.
SQL> SELECT VAR_SAMP(AGE) FROM EMP_AGE; VAR_SAMP(AGE) ------------- 9.21111111111 1 row selected.
-
Example (Analytic Function)
The following example shows how to use the VAR_SAMP function as an analytic function.
SQL> SELECT DEPTNO, EMPNO, VAR_SAMP(SAL) OVER (PARTITION BY DEPTNO) AS VAR_SAMP FROM EMP; DEPTNO EMPNO VAR_SAMP ---------- ---------- ---------- 10 7934 3585833.33 10 7839 3585833.33 10 7782 3585833.33 20 7566 1261875 20 7788 1261875 20 7876 1261875 20 7902 1261875 20 7369 1261875 30 7654 446666.667 30 7698 446666.667 30 7521 446666.667 30 7499 446666.667 30 7844 446666.667 30 7900 446666.667 14 rows selected.
VARIANCE returns the variance of expr. This function can be used as an analytic function. It returns a numeric or converted numeric data type of a given parameter. If this function is applied to an empty set, it returns NULL.
In Tibero, the variance is computed as follows:
-
If the number of rows of expr is 1, 0 is returned.
-
If the number of rows of expr is greater than 1, the return value of the VAR_SAMP function is returned.
A detailed description of the VARIANCE function is as follows:
-
Syntax

-
Component
Component Description expr An expression that returns a numeric data type or a compatible type. analytic_clause This function can be used as an analytic function using "OVER analytic_clause".
For detailed information, see analytic_clause in “4.1.3. Analytic Functions”.
-
Example
The following example shows how to use the VARIANCE function.
SQL> SELECT VARIANCE(AGE) FROM EMP_AGE; VARIANCE(AGE) ------------- 9.21111111111 1 row selected.
-
Example (Analytic Function)
The following example shows how to use the VARIANCE function as an analytic function.
SQL> SELECT DEPTNO, EMPNO, VARIANCE(SAL) OVER (PARTITION BY DEPTNO) AS VARIANCE FROM EMP; DEPTNO EMPNO VARIANCE ---------- ---------- ----------- 10 7934 3585833.333 10 7839 3585833.333 10 7782 3585833.333 20 7566 1261875 20 7788 1261875 20 7876 1261875 20 7902 1261875 20 7369 1261875 30 7654 446666.6667 30 7698 446666.6667 30 7521 446666.6667 30 7499 446666.6667 30 7844 446666.6667 30 7900 446666.6667 14 rows selected.
VSIZE returns the number of bytes used internally to represent expr.
A detailed description of the VSIZE function is as follows:
-
Syntax
-
Component
Component Description expr An expression.
If this is NULL, this function returns NULL.
-
Example
The following example shows how to use the VSIZE function.
SQL> SELECT VSIZE(SYSDATE) FROM DUAL; VSIZE(SYSDATE) -------------- 8 1 row selected.
XMLAGG is an aggregate function that aggregates XML fragments and returns an XML document. Any arguments that return NULL are excluded from the result.
A detailed description of the XMLAGG function is as follows:
-
Syntax

-
Component
Component Description xml_expr An expression that returns an XML statement. order_by_clause Specifies how to sort rows in a single partition.
For detailed information, see order_by_clause in “4.1.3. Analytic Functions”.
-
Example
The following example shows how to use the XMLAGG function.
SQL> SELECT XMLELEMENT("EMPLOYEE", XMLAGG(XMLELEMENT("NAME",NAME)), XMLELEMENT("AGE",AGE)) AS "EMPLOYEE" FROM EMP_AGE GROUP BY AGE; EMPLOYEE --------------------------------------------------------------------- <EMPLOYEE><NAME>Jim Clark</NAME><NAME>John Ronaldo</NAME><NAME>Choi S efo</NAME><NAME>Titicaca Eboue</NAME><AGE>27</AGE></EMPLOYEE> <EMPLOYEE><NAME>Mirko Fedor</NAME><NAME>Doug Bush</NAME><AGE>28</AGE> </EMPLOYEE> <EMPLOYEE><NAME>Razor Ramon</NAME><AGE>34</AGE></EMPLOYEE> <EMPLOYEE><NAME>Mike Thai</NAME><NAME>Ryu Hayabusa</NAME><NAME>Sebast ian Panucci</NAME><AGE>31</AGE></EMPLOYEE> 4 rows selected.
XMLCAST converts the type of expr to the SQL data type specified by typename.
A detailed description of the XMLCAST function is as follows:
-
Syntax

-
Component
Component Description expr An expression that returns an XML string. typename Specifies an SQL data type to be returned. -
Example
The following example shows how to use the XMLCAST function.
SQL> SELECT XMLCAST( XMLQUERY('/BOOK' PASSING C1 RETURNING CONTENT) AS VARCHAR(100)) CAST_VALUE FROM XMLTBL; CAST_VALUE -------------------------------------------------------------------------------- Introduction to TIBERO Tibero team 1 row selected.
XMLCDATA generates an XML CDATA section. The result is used as the body of the generated XML CDATA section, <![CDATA[string]]>.
A detailed description of the XMLCDATA function is as follows:
-
Syntax
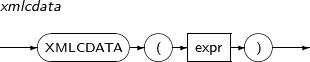
-
Component
Component Description expr String of the XML CDATA section.
If expr is null, the function returns null.
-
Example
The following example shows how to use the XMLCDATA function.
SQL> SELECT XMLCDATA('Tibero') AS "XMLCDATA" FROM DUAL; XMLCDATA ---------------------------------------------------------------------- <!CDATA[Tibero]]> 1 row selected.
XMLCOLATTVAL converts each parameter into an XML node with a name of "column" and an attribute of "name" and then expands the resulting XML.
A detailed description of the XMLCOLATTVAL function is as follows:
-
Syntax

-
Component
Component Description expr If expr is a column, the AS clause can be omitted. Tibero
If expr is NULL, no attribute is generated for the expression.
alias, EVALNAME expr Specifies an alias of expr using the AS clause.
The alias or expr must be a string with a maximum length of 4,000 characters.
-
Example
The following example shows how to use the XMLCOLATTVAL function.
SQL> SELECT XMLCOLATTVAL(LOC) AS "Locations" FROM DEPT; Locations ---------------------------------------------------------------------- <column name="LOC">NEW YORK</column> <column name="LOC">DALLAS</column> 2 rows selected.
XMLCOMMENT generates an XML comment using the result of expr and returns an XML type value in the format of "<!--string-->".
A detailed description of the XMLCOMMENT function is as follows:
-
Syntax

-
Component
Component Description expr A string that becomes the contents of an XML comment.
If this is NULL, the function returns NULL.
-
Example
The following example shows how to use the XMLCOMMENT function.
SQL> SELECT XMLCOMMENT('Tibero') AS "XMLCOMMENT" FROM DUAL; XMLCOMMENT ---------------------------------------------------------------------- <!--Tibero--> 1 row selected.
XMLCONCAT concatenates and then returns each XMLType expr. If an occurrence of expr is NULL, it is ignored. If all occurrences of expr are NULL, NULL is returned.
A detailed description of the XMLCONCAT function is as follows:
-
Syntax

-
Component
Component Description expr An expression that returns an XMLType instance. -
Example
The following example shows how to use the XMLCONCAT function.
SQL> SELECT XMLCONCAT(XMLTYPE('<Tibero>TIBERO</Tibero>'), XMLTYPE('<Tibero></Tibero>')) AS "XMLCONCAT" FROM DUAL; XMLCONCAT -------------------------------------------------------------- <Tibero>TIBERO</Tibero><Tibero></Tibero> 1 row selected.
XMLELEMENT takes an element name, an optional attribute set, and the contents of the element. In general, this function is nested to create a nested XML document.
A detailed description of the XMLELEMENT function is as follows:
-
Syntax
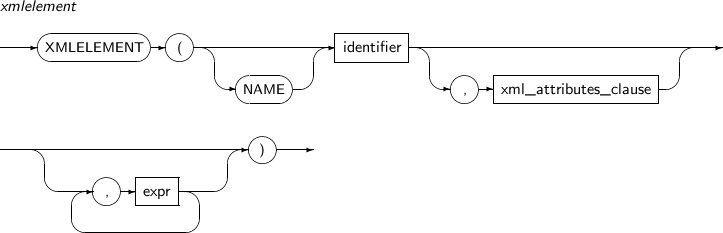
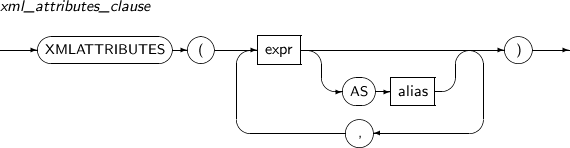
-
Component
-
xmlelement
Component Description identifier Must be specified because this value is used as an enclosing tag for XML.
Can be up to 4,000 characters and does not have to be a column name or column reference. It cannot be an expression or NULL.
The object in the element contents must be specified after the XMLATTRIBUTES reserved word.
xml_attributes_clause Syntax for representing an attribute of XML.
expr An expression that consists of element contents. -
xml_attributes_clause
Component Description expr If this is a column, "AS" can be omitted. Tibero uses a column name as an element name.
If this is NULL, no element is created for that value expression.
The value expression is the expr for XMLELEMENT.
alias The size of alias can be up to 4,000 characters when an alias for expr is specified with an AS clause.
-
-
Example
The following example shows how to use the XMLELEMENT function.
SQL> SELECT XMLELEMENT("DEPT", XMLELEMENT("DNAME",DNAME), XMLELEMENT("LOCATION",LOC)) AS "DEPT" FROM DEPT; DEPT --------------------------------------------------------------------- <DEPT><DNAME>ACCOUNTING</DNAME><LOCATION>NEW YORK</LOCATION></DEPT> <DEPT><DNAME>RESEARCH</DNAME><LOCATION>DALLAS</LOCATION></DEPT> <DEPT><DNAME>SALES</DNAME><LOCATION>CHICAGO</LOCATION></DEPT> <DEPT><DNAME>OPERATIONS</DNAME><LOCATION>BOSTON</LOCATION></DEPT> 4 rows selected.
XMLEXISTS checks whether a given XQuery expression returns a nonempty result. If the result is nonempty, it returns TRUE. Otherwise, it returns FALSE. This function is not supported in Linux IA64, HP PA-RISC, and Windows.
A detailed description of the XMLEXISTS function is as follows:
-
Syntax
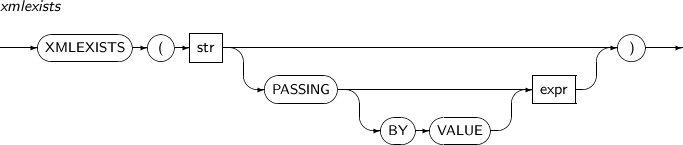
-
Component
Component Description str An XQuery string used to query an XML document.
expr An expression that has an XMLType result.
If the result is not an XMLType, an error occurs.
-
Example
The following example shows how to use the XMLEXISTS function.
SQL> SELECT OBJECT_VALUE AS "DEPT" FROM DEPT_XMLTABLE WHERE XMLEXISTS('/DEPT[DNAME="ACCOUNTING"]' PASSING OBJECT_VALUE); DEPT ---------------------------------------------------------------------- <DEPT><DNAME>ACCOUNTING</DNAME><LOC>NEW YORK</LOC></DEPT> 1 row selected.
XMLFOREST converts each argument to XML, and then aggregates and returns the converted arguments.
A detailed description of the XMLFOREST function is as follows:
-
Syntax

-
Component
Component Description expr If this is a column, "AS" can be omitted. Tibero uses a column name as an element name.
If this is NULL, no element is created for that value expression.
alias This can be up to 4,000 characters when an alias for expr is specified with an AS clause.
-
Example
The following example shows how to use the XMLFOREST function.
SQL> SELECT XMLELEMENT("DEPT", XMLFOREST(DNAME,LOC)) AS "DEPT" FROM DEPT; DEPT ---------------------------------------------------------------------- <DEPT><DNAME>ACCOUNTING</DNAME><LOC>NEW YORK</LOC></DEPT> <DEPT><DNAME>RESEARCH</DNAME><LOC>DALLAS</LOC></DEPT> <DEPT><DNAME>SALES</DNAME><LOC>CHICAGO</LOC></DEPT> <DEPT><DNAME>OPERATIONS</DNAME><LOC>BOSTON</LOC></DEPT> 4 rows selected.
XMLPARSE generates an XML type value from expr.
A detailed description of the XMLPARSE function is as follows:
-
Syntax

-
Component
Component Description DOCUMENT The result of expr must be a singly rooted XML document.
CONTENT The result of expr must be an XML value. expr The result of expr must be a string type. WELLFORMED If CONTENT is specified, a database does not internally perform WELLFORMED CHECK. -
Example
The following example shows how to use the XMLPARSE function.
SQL> SELECT XMLPARSE(CONTENT 'ABC<NAME>Park</NAME><ID>123</ID>' WELLFORMED) AS PO FROM DUAL; PO ---------------------------------------------------------------------- ABC<NAME>Park</NAME><ID>123</ID> 1 row selected.
XMLPI generates an XML processing instruction in an XML document and returns a XMP type value.
A detailed description of the XMLPI function is as follows:
-
Syntax

-
Component
Component Description identifier A string for a name of a processing instruction syntax in an XML document.
Cannot include reserved words that XML uses internally, a question mark (?), or a greater than sign (>).
expr Has a string as a result. If this is omitted, the string is considered to be of zero length. -
Example
The following example shows how to use the XMLPI function.
SQL> SELECT XMLPI(NAME "RDBMS", 'Tibero') AS XMLPI FROM DUAL; XMLPI --------------------------------------------- <?RDBMS Tibero?> 1 row selected.
XMLQUERY queries XML data using a specified XML query and returns an XML type.
A detailed description of the XMLQUERY function is as follows:
-
Syntax


-
Component
Component Description str An XQuery string to query to an XML document.
Can be up to 4,000 characters.
expr An expression that returns an XML document to be queried.
Must be of the XML type.
-
Example
The following example shows how to use the XMLQUERY function.
SQL> SELECT XMLQUERY('1, 2, 5' RETURNING CONTENT) AS XMLQRY FROM DUAL; XMLQRY --------------------------------------------- 1 2 5
XMLROOT generates the declaratives of an XML document. It returns an XML statement in a format of <?xml version="version" [standalone="{yes|no}"]?>.
A detailed description of the XMLROOT function is as follows:
-
Syntax
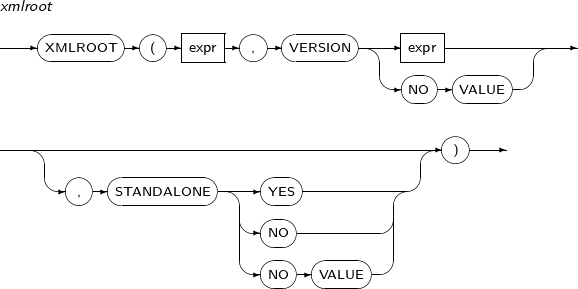
-
Component
Component Description expr Expression that returns an XML statement.
If the result of the expression is not an XML statement, an error occurs.
VERSION Expression that returns a string.
If 'NO VALUE' is specified, "1.0" is used by default.
STANDALONE If the STANDALONE clause is omitted or 'NO VALUE' is used, then the standalone property is absent from the value returned by the function. -
Example
A detailed description of the XMLROOT function is as follows:
SQL> SELECT XMLROOT(XMLTYPE('<id>31679</id>'), VERSION '1.0', STANDALONE YES) AS "XMLDecl" FROM DUAL; XMLDecl ---------------------------------------------------------------------- <?xml version="1.0" standalone="yes"?><id>31679</id> 1 rows selected.
XMLSERIALIZE generates a string or a LOB from expr.
A detailed description of the XMLSERIALIZE function is as follows:
-
Syntax

-
Component
Component Description DOCUMENT The result of expr must be a singly rooted XML document.
CONTENT The result of expr must be an XML value. expr An expression that returns an XML document. datatype Specifies the result type as either VARCHAR2 or CLOB. Defaults to CLOB. -
Example
The following example shows how to use the XMLSERIALIZE function.
SQL> SELECT XMLROOT(XMLTYPE('<id>31679</id>'), VERSION '1.0', STANDALONE YES) AS "XMLDecl" FROM DUAL; XMLDecl ---------------------------------------------------------------------- <?xml version="1.0" standalone="yes"?><id>31679</id> 1 rows selected.
XMLTABLE returns the result of an XML query to an XML document in the form of a table. Each column value is specified with XPath in the resulting XML of the XML query. The return value is converted to a specified data type.
A detailed description of the XMLTABLE function is as follows:
-
Syntax


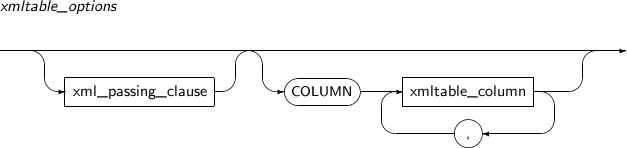

-
Component
Component Description xquery_str An XML query to query to an XML document. It can be up to 4,000 characters.
str in xmlnamespace_clause Can specify a namespace for an XML query. It can be omitted if it is not necessary.
expr in xml_passing_clause An XML document to query an XML query.
datatype in xmltable_column Specifies the data type of a result column.
str in xmltable_column Specifies the name of a result column. It can be up to 4,000 characters.
expr in xmltable_column The default value if there is no value for a corresponding XPath. If this is omitted, the default value is NULL.
-
Example
The following example shows how to use the XMLTABLE function.
SQL> SELECT warehouse_name warehouse, warehouse2."Water", warehouse2."Rail" FROM warehouses, XMLTABLE('/Warehouse' PASSING warehouses.warehouse_spec COLUMNS "Water" varchar2(6) PATH '/Warehouse/WaterAccess', "Rail" varchar2(6) PATH '/Warehouse/RailAccess') warehouse2; WAREHOUSE Water Rail ----------------------------------- ------ ------ Southlake, Texas Y N San Francisco Y N New Jersey N N Seattle, Washington N Y 4 rows selected.
XMLTRANSFORM transforms an xmltype_instance into an expression that is defined in xslt_document. The parameter specified in xslt_document can be entered through param_map.
However, this function does not support Windows (64-bit) and HP UX/PA-RISC.
A detailed description of the XMLTRANSFORM function is as follows:
-
Syntax
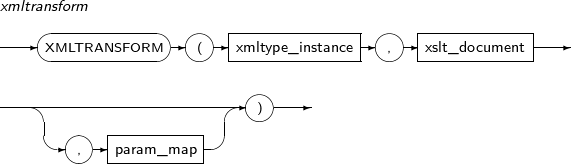
-
Component
Component Description xmltype_instance XML document to be queried. This is an XMLType. xslt_document XSLT document that expresses the transformation format. This is an XMLType. param_map Parameter defined in the XSLT document.
String in the format of name1=value1 name2=value2 ....
-
Example
The following example shows how to use the TRANSFORM function.
SQL> select XMLTRANSFORM(XMLTYPE('<root/>'), XMLTYPE('<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:fo="http://www.w3.org/1999/XSL/Format" exclude-result-prefixes="fo"> <xsl:output method="xml"/><xsl:param name="par1"/> <xsl:param name="par2"/><xsl:template match="/"> <output><param1><xsl:value-of select="$par1"/></param1> <param2><xsl:value-of select="$par2"/></param2></output> </xsl:template></xsl:stylesheet>'), 'par1="a" par2="b"') as result from dual; RESULT -------------------------------------------------------------------------------- <output><param1>a</param1><param2>b</param2></output> 1 row selected.