Table of Contents
This chapter will briefly explain the major features, process structures, and directory structures of Tibero.
These days, corporate businesses are rapidly expanding amid increasing amounts of data and business environments. With the influx of new business environments, it has become a prerequisite for business success to provide more efficient and flexible data service, information processing, and data management techniques.
As an enterprise database management system, Tibero meets those needs by supporting the database infrastructure, a foundation for corporate businesses, with high performance, availability, and scalability.
Tibero adopted and implemented Tibero Thread Architecture as a unique technology to make up for the weak points of existing DBs. This enables cost-effective usage of system resources such as CPU and memory within limited server processes, by providing excellent performance, stability, and scalability, as well as an easy to use development environment and management tools.
Tibero has been developed to differentiate itself from other DBMSs in terms of large-scale user and data processing, improved stability, and enhanced compatibility.
In short,Tibero is a superior DB that provides the optimal environment for enterprises.
Tibero RDBMS, which manages massive data and ensures stable business continuity, provides the following key features required for the RDBMS environment:
-
Stores data in a different database instance. By using this function, a read or write operation can be performed for data in a remote database across a network.
Other vendors' RDBMS solutions can also be used for read and write operations.
-
This function copies all changed contents of the operating database to a standby database. This can be done by sending change logs through a network to a standby database, which then applies the changes to its data.
-
This function resolves the biggest issues for any enterprise DB, which are high availability and high performance. To achieve this, Tibero DB implements a technology called Tibero Active Cluster.
Database clustering allows multiple database instances to share a database with a shared disk. It is important that clustering maintain consistency among the instances' internal database caches. This is also implemented in Tibero Active Cluster. For more detailed information, see “Chapter 10. Tibero Active Cluster”.
-
Data volumes for businesses are continually rising. Because of this, it is necessary to have parallel processing technology which provides maximum usage of server resources for massive data processing.
To meet these needs, Tibero supports transaction parallel processing functions optimized for OLTP (Online Transaction Processing) and SQL parallel processing functions optimized for OLAP (Online Analytical Processing). This allows queries to complete more quickly.
-
The query optimizer decides the most efficient plan by considering various data handling methods based on statistics for the schema objects.
Query optimizer performs the following:
-
Creates various execution plans to handle given SQL statements.
-
Calculates each execution plan's cost by considering statistics for how much data is distributed, tables, indexes, and partitions as well as computer resources such as CPU and memory, where the cost is the relative time needed to perform a certain execution plan.
-
Selects the lowest cost execution plan.
Major features of the query optimizer are as follows:
-
Purpose of the query optimizer
The final purpose of the query optimizer can be changed. The following table shows two examples:
Classification Description Total handling time Query optimizer can reduce the time to retrieve all rows by using the hint ALL_ROWS. Initial response time Query optimizer can reduce the time to retrieve the first row by using the hint FIRST_ROWS. -
Query transformation
A query can be transformed to make a better execution plan. The following are examples of query transformation: merging views, unnesting subqueries, and using materialized views.
-
Determining a data access method
Retrieving data from a database can be performed through a variety of methods such as a full table scan, an index scan, or a rowid scan. Because each method has different benefits depending on the amount of data and the filtering type, the best data access method may vary.
-
Determining a join handling method
When joining data from multiple tables, the order in which to join the tables and a join method such as a nested loop join, merge join, and hash join should be determined. The order and method have a large effect on performance.
-
Cost estimation
Each execution plan's cost in each execution phase is estimated based on statistics such as predicate selectivity and the number of data rows.
-
Tibero guarantees reliable database transactions, which are logical sets of SQL statements, by supporting the following four properties:
-
Atomicity
Each transaction is all or nothing; all results of a transaction are applied or nothing is applied. To accomplish this, Tibero uses Undo data.
-
Consistency
Every transaction complies with rules defined in the database regardless of its result, and the database is always consistent. There are many reasons why a transaction could break a database's consistency. For example, an inconsistency occurs when a table and an index have different data. To prevent this, Tibero does not allow applying only a part of a transaction. That is, even if a table has been modified and a related index has not yet been modified, other transactions can only see the unmodified data. The other transactions think that there is consistency between the table and the index.
-
Isolation
A transaction is not interrupted by another transaction. When a transaction is handling data, other transactions wait to access the data and any operation in another transaction cannot use the data. However, an error does not occur. To accomplish this, Tibero uses two methods: multiversion concurrency control (MVCC) and row-level locking.
When reading data, MVCC can be used without interrupting other transactions. When modifying data, row level fine-grained lock controls can be used to minimize conflicts and to make a transaction wait. That is, concurrency is guaranteed by locking a row, which is the smallest data unit. Even if multiple rows are modified, Data Manipulation Language (DML) can still be executed despite a table lock. With these methods, Tibero provides high performance in an OLTP environment.
-
Durability
Once a transaction has been committed, it must be permanent even if there is a failure such as a loss of power or a breakdown. To accomplish this, Tibero uses Redo logs and write-ahead logging. When a transaction is committed, relevant Redo logs are written to disk to guarantee the transaction's durability. Before a block is loaded on a disk, the Redo logs are loaded first to guarantee that the database has consistency.
Tiberouses row level locking to guarantee fine-grained lock control. That is, it maximizes concurrency by locking a row, the smallest unit of data. Even if multiple rows are modified, concurrent DMLs can be performed because the table is not locked. Through this method, Tibero provides high performance in an OLTP environment.
Tibero has a multi-process and multi-thread based architecture, which allows access by a large amount of users.
The following figure shows the process structure of Tibero:
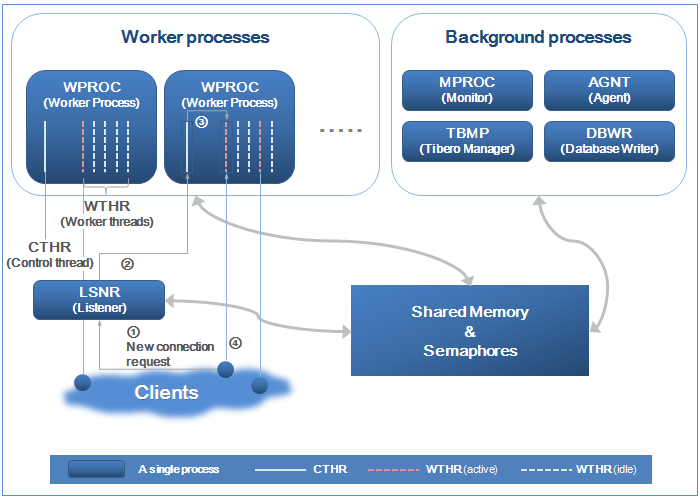
Tibero has the following three processes:
-
Listener
-
Worker process or foreground process
-
Background process
Listener receives requests for new connections from clients and assigns them to an available worker process. Listener plays an intermediate role between clients and worker process using an independent executable file, tblistener. Starting in Tibero 6, listeners are created by MPROC, and they are created again when they are forcibly terminated.
A new connection from a client is handled in the following way (refer to [Figure 1.1]):
-
Listener searches for a worker process that has an available worker thread and then sends the connection request to the worker process (①).
-
Because connection information is sent along with the request, the client starts operations as soon as it connects to the worker thread regardless of a server’s internal operation.
-
A control thread that receives a request from listener checks the status (②) of worker threads included in the same worker process and assigns an available worker thread (③) to the connection from the client.
-
The worker thread authenticates the client and starts a session (④).
A worker process communicates with client processes and handles user
requests. Tibero creates multiple working processes
when a server starts to support connections from multiple client
processes. The number of working processes can be adjusted with the
initialization parameter WTHR_PROC_CNT. This number
cannot be modified after Tibero RDBMS
starts. If the number of working threads increases, more CPU and memory
resources are used. Therefore, the proper number of working processes
should be specified based on the number of concurrent users and the
system environment. Starting in Tibero 6, worker processes are divided
into two groups based on their purpose. A background worker process
performs the batch jobs registered in an internal task or job scheduler,
while a foreground worker process performs online requests sent through
the listener. The groups can be adjusted using MAX_BG_SESSION_COUNT, an
initialization parameter.
Note
For more information on the initialization parameter, refer to "Tibero Reference Guide".
Tibero handles jobs using threads to efficiently use resources. One worker process consists of one control thread and multiple worker threads. A working process contains one control thread and ten worker threads by default.
The number of worker threads per process can be set using the
initialization parameter _WTHR_PER_PROC, and after
Tibero
begins, this number cannot be changed, like
WTHR_PROC_CNT. Therefore, the proper number of
worker processes should be set based on the number of concurrent users
and the system environment.
It is recommended to use the initialization parameter
MAX_SESSION_COUNT instead of
WTHR_PROC_CNT and
_WTHR_PER_PROC to specify the maximum number of
sessions provided by a server. The values of
WTHR_PROC_CNT and
_WTHR_PER_PROC are automatically set depending on
the value of MAX_SESSION_COUNT.
If WTHR_PROC_CNT and
_WTHR_PER_PROC are manually set, the value of
WTHR_PROC_CNT * _WTHR_PER_PROC
must be identical to MAX_SESSION_COUNT.
The value of MAX_BG_SESSION_COUNT must be
smaller than the value of MAX_SESSION_COUNT, and it
must be a multiple of _WTHR_PER_PROC .
A worker process performs the following jobs using the given control thread and worker threads.
Control Thread
Each worker process has one control thread, which plays the following roles:
-
Creates as many worker threads as specified in the initialization parameter when Tibero is started.
-
Allocates new client connection requests to an idle worker thread.
-
Checks signal processing.
-
Tibero 6 supports I/O multiplexing and performs the role of sending and receiving messages instead of worker threads.
Worker Thread
A worker thread communicates directly with a single client
process. It receives and handles messages from a client process and
returns the result. It handles most DBMS jobs such as SQL parsing and
optimization. Because a worker thread connects to a single client, the
number of clients that can simultaneously connect to Tibero RDBMS is
equal to WTHR_PROC_CNT multiplied by
_WTHR_PER_PROC. Because Tibero RDBMS
does not support session multiplexing, a single client connection
represents a single session. Therefore, the maximum number of sessions
is also equal to WTHR_PROC_CNT multiplied by
_WTHR_PER_PROC.
Even after a worker thread is disconnected from a client, it does not disappear. It is created when Tibero RDBMS starts and is removed when Tibero RDBMS terminates. This improves system performance as threads do not need to be created or removed even if connections to clients need to be made frequently.
However, a number of worker threads equal to the initialization parameter have to be created regardless of the number of clients. This unnecessarily uses OS resources, but is still practical for system operation because it takes few resources to maintain idle threads.
Caution
If too many worker threads attempt to handle jobs at the same time without consideration for the CPU and memory resources, system performance may suffer due to heavy loads. Therefore, to build a massive scale system, it is recommended to install middleware between Tibero and application programs using a three-tier structure.
Background processes are independent processes that primarily perform time-consuming disk operations at specified intervals or at the request of a worker thread or another background process.
The following are the processes that belong to the background process group:
-
Monitor Process is a single independent process. In previous versions of Tibero, it was named 'monitor thread'. It is the first process created after Listener when Tibero starts. It is the last process to finish when Tibero terminates.
The monitor thread creates other processes, including a listener when Tibero starts. It also periodically checks each process status and deadlocks.
-
Tibero Manager Process (TBMP)
Tibero Manager Process is used to manage the system. TBMP receives a manager's connection request and allocates a thread that is reserved for system management. TBMP basically performs the same role as a worker process but it directly handles the connection through a special port. Only the SYS account is allowed to connect to the special port.
-
Agent Process (AGNT)
Agent Process performs internal jobs for Tibero that are required for system maintenance. Until version 4SP1, this process stored sequence cache values to disk, but starting in Tibero 5, each worker thread stores them individually. The name "SEQW" was changed to "AGNT" starting in Tibero 6. For more details on how to use the sequence process, refer to “4.7.1. Creating, Changing, and Deleting Sequences”.
In Tibero 6, AGNT runs based on a multi-threaded structure, and threads are allocated per workload.
-
Database Write Process (DBWR)
Database Write Process is a collection of threads that record database updates on the disk. DBWR includes threads that periodically record user-changed blocks onto disk, threads for recording redo logs onto disk, and check point threads for managing the check point process of the database.
The following directory structure is created after installing Tibero.
$TB_HOME +- bin | +- client | | | +- bin | +- config | +- include | +- lib | +- ssl | | | | | +- certs | | +- misc | | +- private | +- epa | | | | | +- java | | | | | +- config | | +- lib | +- win32 | +- win64 | +- config | +- database | +- $TB_SID | | | +- psm | +- instance | | | +- $TB_SID | | | +- audit | +- log | | +- dbmslog | | +- lsnr | | +- tracelog | +- path | +- lib | +- license | | | +- oss_licenses | +- scripts +- pkg
The directories shown as $TB_SID in the previous directory structure is replaced by the server SID of the system environment.
The following are the native directories of Tibero.
- bin
-
This directory contains Tibero. The tbsvr and tblistener files are executables for creating the Tibero, and tbboot and tbdown are used to start up and shut down the Tibero.
The tbsvr and tblistener 'tbboot.
- client/bin
-
This directory contains the following Tibero (utilities).
For more information about the utilities, refer to "Tibero Utility Guide". For the tbpc utility, refer to "Tibero tbESQL/C Guide".
- client/config
-
This directory contains configuration file for executing a Tibero client program.
- client/include
-
This directory contains the header files for creating a Tibero
- client/lib
-
This directory contains the library files for creating a Tibero. For more information, refer to "Tibero Application Developer's Guide" and "Tibero tbESQL/C Guide".
- client/ssl
-
This directory contains certificate and key files for server security.
- client/epa
-
This directory contains configuration and log files related to external procedures. For more information, refer to "Tibero External Procedure Guide".
- client/win32
-
This directory contains the ODBC/OLE DB driver for 32-bit Windows.
- client/win64
-
This directory contains the ODBC/OLE DB driver for 64-bit Windows.
- config
-
This directory contains the environment configuration files for Tibero. The $TB_SID.tip file in this directory contains the environment settings for Tibero.
- database/$TB_SID
-
This directory and its subdirectories contain all database information unless it is configured separately. It includes the metadata and the following file types.
- database/$TB_SID/psm
-
This directory contains the tbPSM programs that are compiled in the compiled mode. Note that currently, Tibero For more information, refer to "Tibero tbPSM Guide".
- instance/$TB_SID/audit
-
This directory contains the audit files that records activities of database users using system privileges or schema object privileges.
- instance/$TB_SID/log
-
This directory contains the trace, DBMS, event, and listener log files of Tibero.
Trace, DBMS, event, and listener log files are accumulated with use and can grow up to the size of the directory. Old files must be deleted from the directory to not exceed the limit.
The following are the initialization parameters for a DBMS log file.
Initialization Parameter Description DBMS_LOG_FILE_SIZE Maximum DBMS log file size. DBMS_LOG_TOTAL_SIZE_LIMIT Maximum size of the directory where DBMS log files are saved. TRACE_LOG_FILE_SIZE Maximum trace log file size. TRACE_LOG_TOTAL_SIZE_LIMIT Maximum size of the directory where trace log files are saved. EVENT_TRACE_FILE_SIZE Maximum event log file size. EVENT_TRACE_TOTAL_SIZE_LIMIT Maximum size of the directory where event log files are saved. LSNR_LOG_FILE_SIZE Maximum listener file size. LSNR_LOG_TOTAL_SIZE_LIMIT Maximum size of the directory where listener log files are saved. - instance/$TB_SID/path
-
This directory contains the socket files used for interprocess communication in Tibero. The files in this directory must not be read or updated while Tibero is running.
- lib
-
This directory contains the spatial function library files for Tibero.
- license
-
This directory contains the Tibero(license.xml). This XML file can be opened using a text editor to check its contents.
- license/oss_licenses
-
This directory contains the open license terms that must be complied with when using Tibero.
- nls/zoneinfo
-
This directory contains the time zone information file for Tibero.
- scripts
-
This directory contains various SQL statements used when creating a database in Tibero. It also includes various view definitions that reflect the current state of Tibero.
- scripts/pkg
-
This directory contains the package creation statements for Tibero.