내용 목차
본 장에서는 Tmax 사용에 참고가 되는 사항에 대해서 설명한다.
다음은 다수의CLH를 사용하는데 있어서의 스케줄링 특성에 대한 설명이다.
ASQCOUNT 는 엔진 전체에 걸친 값이 아니라 CLH 하나에 부여되는 값이다. 그래서 각 CLH마다 큐 상태를 보고 ASQCOUNT를 적용하여 부족한 서버를 부트한다.
예를 들면 ASQCOUNT=4로 설정하고, 한 노드에 현재 대기중인 요청이 5개라면, 현재 큐 크기가 5가 아니고, 각 CLH마다 svr 대기 큐를 가지고 있기 때문에 1번 CLH에 2개, 2번 CLH에 3개가 될 수 있는 상태에서는 ASQCOUNT에 못미치기 때문에 서버를 부트하지 않는다.
다수 CLH에서는 모든 CLH에서 동시에 같은 spr에 스케줄링할 수 있다. 최대한 방지하기 위해 다른 CLH의 상태도 검사하며 스케줄링하지만 요청이 많아지거나 동시에 요청이 있을 경우 발생할 수 있다. 이런 경우에는 늦게 요청된 spr의 소켓에 대기하며 tmadmin의 큐에서는 보여지지 않고 각 CLH의 st -p에 RUN 상태로 보여야 한다. 이런 상태에 있는 요청들은 CLH의 큐에 있는 것이나 마찬가지로 판단하여 svr에 실제 서비스 수행 전에 qtimeout을 체크하여 시간이 이미 지났다면 TPEQPURGE로 응답을 주고 있다.
참고
무조건 실행되게 하기 위해서는 SERVER 절의 CLOPT 항목에 [-B] 옵션을 추가한다.
본 절은 도메인 게이트웨이 간 ROUTING이 필요한 경우 도메인 게이트웨이 가용성을 위한 구성 방법을 설명한다.
*SVRGROUP ServerGroup Name [COUSIN = cousin-svg-name,cousin-gw-name,] [LOAD = numeric]
-
COUSIN = literal
-
범위: 7999 자 이내
-
서버 그룹/게이트웨이별로 서로 공유해야 할 프로세스가 있거나, 서버 그룹 / 게이트웨이간 ROUTING이 필요한 경우 서버 그룹/게이트웨이의 이름을 지정 한다. 4.0 SP1 버전부터 게이트웨이명을 지정할 수 있다.
-
-
LOAD = numeric
-
"3.2.3. SVRGROUP 절" LOAD 항목을 참고한다.
-
*GATEWAY
Gateway Name [LOAD = numeric]
-
LOAD = numeric
-
"3.2.3. SVRGROUP 절" LOAD 항목을 참고한다.
-
예제
다음과 같이 설정할 경우 svg1(tmaxh4), svg2(tmaxh2), gw1(tmaxh4), gw2(tmaxh2) 가 하나의 COUSIN 으로 묶이게 된다. LOAD 의 값이 모두 1 이므로 클라이언트에서 TOUPPER 서비스 호출하는 경우 각 svg1, svg2, gw1, gw2 가 1:1:1:1 로 서비스를 처리한다.
<domain1.m>
*DOMAIN
tmax1 SHMKEY = 78350, MINCLH = 2, MAXCLH = 3,
TPORTNO = 8350, BLOCKTIME = 10000,
MAXCPC = 100, MAXGW = 10, RACPORT = 3355
*NODE
tmaxh4 TMAXDIR = "/data1/tmaxqam/tmax",
tmaxh2 TMAXDIR = "/data1/tmaxqam/tmax",
*SVRGROUP
svg1 NODENAME = tmaxh4,
COUSIN = "svg2, gw1, gw2", LOAD = 1
svg2 NODENAME = tmaxh2, LOAD = 1
*SERVER
svr2 SVGNAME = svg1
*SERVICE
TOUPPER SVRNAME = svr2
*GATEWAY
#Gateway for domain 2
gw1 GWTYPE = TMAXNONTX,
PORTNO = 7510,
RGWADDR ="192.168.1.43",
RGWPORTNO = 8510,
NODENAME = tmaxh4,
CPC = 3, LOAD = 1
#Gateway for domain 3
gw2 GWTYPE = TMAXNONTX,
PORTNO = 7520,
RGWADDR ="192.168.1.48",
RGWPORTNO = 8520,
NODENAME = tmaxh2,
CPC = 3, LOAD = 1
<domain2.m>
*DOMAIN
tmax1 SHMKEY = 78500, MINCLH=2, MAXCLH=3,
TPORTNO=8590, BLOCKTIME=10000
*NODE
tmaxh4 TMAXDIR = "/EMC01/starbj81/tmax",
*SVRGROUP
svg1 NODENAME = "tmaxh4"
*SERVER
svr2 SVGNAME = svg1
*SERVICE
TOUPPER SVRNAME = svr2
*GATEWAY
gw1 GWTYPE = TMAXNONTX,
PORTNO = 8510,
RGWADDR="192.168.1.43",
RGWPORTNO = 7510,
NODENAME = tmaxh4,
CPC = 3
<domain3.m>
*DOMAIN
tmax1 SHMKEY = 78500, MINCLH=2, MAXCLH=3,
TPORTNO=8590
*NODE
tmaxh2 MAXDIR = "/data1/starbj81/tmax",
*SVRGROUP
svg2 ODENAME = "tmaxh2"
*SERVER
svr2 SVGNAME = svg2
*SERVICE
TOUPPER SVRNAME = svr2
*GATEWAY
gw2 GWTYPE = TMAXNONTX,
PORTNO = 8520,
RGWADDR="192.168.1.48",
RGWPORTNO = 7520,
NODENAME = tmaxh2,
CPC = 3
참고사항
Tmax v5.0 SP1까지는 게이트웨이가 속한 노드는 반드시 해당 노드의 일반 서버 그룹(보통 dummy 서버)도 등록되어 COUSIN으로 함께 묶여 있어야 한다. 위 예제 <domain1.m> 에서 gw1 은 tmaxh4 노드에 속해 있으며, gw2는 tmaxh2 노드에 속해 있다. 이 경우 tmaxh4와 tmaxh2의 일반 서버 그룹도 반드시 COUSIN 서버 그룹 내에 포함되어 있어야 한다.
그러나 Tmax v5.0 SP2에서는 위와 같은 불편함을 해결하여 게이트웨이가 속한 노드를 묶지 않고 해당 게이트웨이만 묶어 주어도 된다.
-
Tmax v5.0 SP2 이전 버전의 환경설정
*SVRGROUP svg1 NODENAME = tmaxh4, COUSIN = "svg2, gw1, gw2" svg2 NODENAME = tmaxh2 *GATEWAY gw1 NODENAME = tmaxh4 gw2 NODENAME = tmaxh2
-
Tmax v5.0 SP2 이후 버전의 환경설정
Tmax v5.0 SP1에서는 잘못된 설정이지만, Tmax v5.0 SP2에서는 올바른 설정이다.
*GATEWAY gw1 NODENAME = tmaxh4 COUSIN = "gw2" gw2 NODENAME = tmaxh2
참고
Tmax v5.0 SP1까지는 GATEWAY 절에 COUSIN 항목을 직접 설정할 수 없으며 일반 서버 그룹에만 COUSIN 항목의 설정이 가능하다.
하지만 Tmax v5.0 SP2 에서는 GATEWAY 절에서 COUSIN 설정이 가능하도록 기능이 추가되었으며 여전히 이전 환경설정 방법도 가능하다.
이러한 설정 방법은 TMAX, TMAXNONTX, JEUS, JEUS_ASYNC, TUXEDO, TUXEDO_ASYNC GWTYPE 에서 가능하다.
멀티 노드 환경에서 부하 분산에 대해 로컬 노드의 서버가 종료되었을 경우, CLH 에서 이를 판단하고 리모트 노드의 서버로 재스케줄한다. 따라서 에러 없이 클라이언트의 요청을 모두 처리할 수 있다. 리모트 노드의 특정 서버가 죽은 경우, 로컬 노드의 CLH는 리모트 노드에서의 해당 서버의 상태를 알지 못하기 때문에 리모트 노드로 해당 요청을 보내게 되어 클라이언트는 TPENOREADY 에러를 전달받는다.
이와 같은 문제를 해결하기 위해 지능형 라우팅 기능(IRT)이 도입되었다. 이 기능은 정적 부하 분산에 대한 리모트 서버의 상태를 관리하여, 처리할 수 있는 서버로 스케줄 하도록 재스케줄(IRT – Intelligent Routing) 된다. 따라서 리모트 노드의 프로세스가 비정상종료되어 서비스를 처리할 수 없게 되면, 처리할 수 있는 서버로 재스케줄된다.
참고
재스케줄되는 서버 그룹의 개수는 10개로 제한되어 있으며, TPENOTREADY 에러에 대해서만 재스케줄된다.
기존 도메인 게이트웨이는 리모트 노드/리모트 도메인의 상태를 체크하지 못하기 때문에 리모트 노드의 특정 서버 (Gateway 포함)에 장애가 난 경우 이에 대하여 감지하지 못하고 그대로 스케줄링되어 클라이언트에게 TPENOREADY 에러를 리턴하였다.
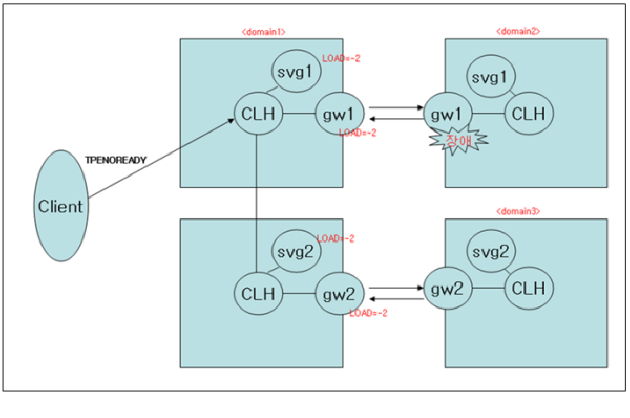
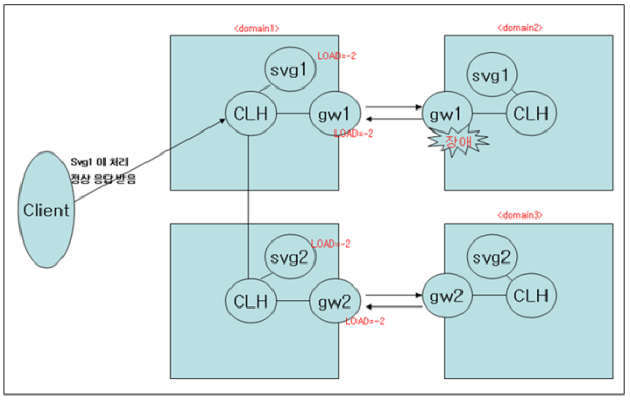
리모트 노드 / 도메인의 상태를 체크하여 리모트 게이트웨이 장애가 발생하였을 경우 남아 있는 다른 서버 그룹이 처리한다. 즉 svg1 이 대신 처리한다.
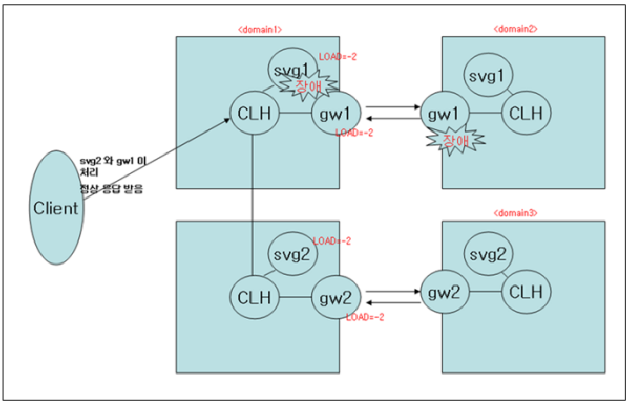
svg1 이 dummy 서버 그룹인 경우 혹은 게이트웨이간의 네트워크 장애가 발생했을 경우 리모트 노드인 svg2 와 gw2 가 각각 1:1 로 처리를 하게 된다.
Tmax에서의 FD(maximum user) 계산 방법은 버전별로 다르다. 각 버전별 FD값을 계산하는 공식은 다음과 같다.
-
Tmax v5.0 ~ Tmax v5.0 SP1 Fix#1 b.3.5
maximum user = max_fd - maxspr - maxcpc - maxtms - maxclh - Tmax 내부 FD(21) - [(nodecount(실제 활성화된 노드 개수) - 1(자신노드)) * maxclh * domain.cpc] -
Tmax v5.0 SP1 Fix#1 b.3.7 ~ Tmax v5.0 SP2
maximum user = max_fd - maxspr - maxcpc - maxtms - maxclh - Tmax 내부 FD(21) - [멀티 노드를 위한 CLH 간 연결FD(maxnode(default:32) * maxclh * domain.cpc * 2)]
'max_fd' 값은 Tmax 내에서 정의한 max_fd 값과 해당 시스템에서 정의된 값 중 작은 값이 적용되고, 'domain.cpc'는 tmadmin의 cfg -d에서 확인할 수 있는 cpc 값이다. 각 항목들의 값은 tmadmin의 cfg 명령어를 통해서 확인할 수 있다.
참고
Tmax v5.0 SP1 Fix#1 b.3.7 버전이 정식 릴리즈된 버전이며 테크넷에서 다운받을 수 있다.