Table of Contents
This chapter describes the characteristics and types of non-VSAM data sets, such as record format, DCB structures, sequential data sets, distributed data sets, and generation data groups.
Non-VSAM data sets refer to all data sets used before the IBM mainframe introduced the VSAM data set. Therefore, all data sets that are not VSAM are called non-VSAM data sets.
In OpenFrame, a non-VSAM data set is provided for UNIX file systems, and access methods for the different types of data sets are listed as OpenFrame interfaces.
OpenFrame supports the following four types of record formats:
-
Fixed length (RECFM=F)
-
Variable length (RECFM=V)
-
Line sequential (RECFM=L)
-
Undefined (RECFM=U)
Variable and fixed length formats can perform block I/O by adding 'B' to the RECFM parameter. A data block refers to grouping multiple records into a single block on a disk volume before writing the data.
In OpenFrame, even if 'B' is not added to the RECFM parameter, when performing disk I/O, buffering is executed using the internal buffer.
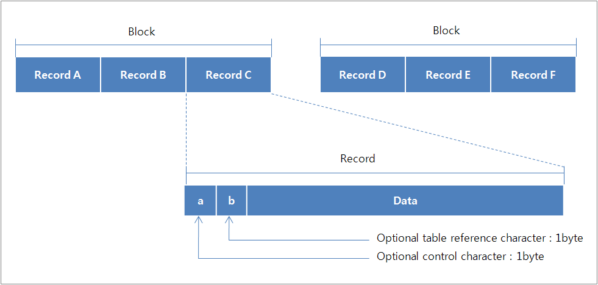
Fixed-Length Record
All records in the same data set have the same size and support block I/O (RECFM=FB). If not a block I/O, a single record is treated as a single block.
Each record is stored continuously without any distinctive record separators inside a block. When reading records sequentially from a block, it reads the record as much as its size each time.
An optional control character refers to a character that controls carriage return when outputting each record. An optional table reference character refers to a code used to select the font when outputting records.
Variable-Length Record
Variable-length records may each have a different length. In the case of a variable length record, a block I/O (RECFM=VB) and spanned format (RECGM=VS) can be used at the same time.
A spanned record is a record split into segments when the assigned block size is smaller than the record length. The segments are saved in the disk. When spanned format in OpenFrame supports I/Os without issue even when the logical record length is longer than the block size. This is possible not because the logical record is stored by segment, but because the block I/O method is different from that of mainframes.
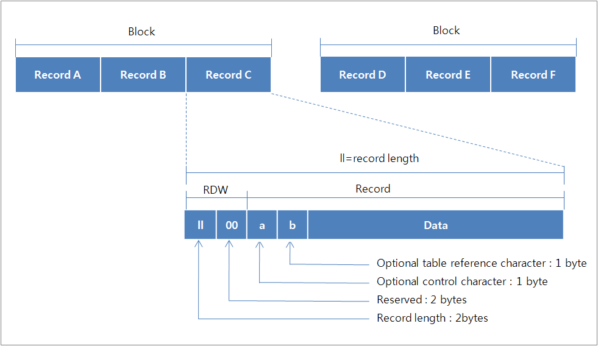
A variable length block is composed of a block descriptor word (BDW) and one or more logical records. The BDW is an additional four-byte field that describes the corresponding block. The BDW is not used in OpenFrame.
A variable length record is composed of a record descriptor word (RDW) and the record data. The RDW is an additional four-byte field used to describe the corresponding record. The first two bytes of an RDW stores the length of the logical record, including the RDW, and the third and fourth bytes are both set to 0.
Line Sequential Record Format
A line sequential record format refers to a record format that has the same structure as a UNIX text file. It does not support block I/O. Each record in a data set is separated with the line feed character. In-stream data set or SPOOL output data set used in OpenFrame batch operations use the line sequential record format.
Undefined-Length Record Format
An undefined length record format is a record format that performs I/O without a fixed format. In an undefined length record format, a single block is considered to be a single record.
Optional Control Characters
In JCL DD statements or DCB parameters, optional control characters can be included as part of the data set record. A single byte output control character located at the start of each record is responsible for carriage control when displaying the data set. This single byte is part of the record saved in a data set, but is not displayed as part of output. Inclusion of this control character is determined by the character 'M' or 'A' in the RECFM field of the data control block (DCB). 'M' means machine code, and 'A' means ANSI code.
In OpenFrame, the DCB for all data sets that are to be processed before applications open a data set needs to be prepared. Data control block is a structure that contains the proper processing information for a data set, and it is put together by extracting information from JCL DD statements or catalogs.
When running a typical JCL batch operation, control blocks for all data sets required by application programs are communicated to application programs after the system creates them internally from the JCL DD statements. However, in cases where a number of utilities using dynamic allocation, such as IDCAMS, the utilities themselves can create the data control blocks.
The following is data set information specified in the data control block:
| Item | Description |
|---|---|
Defines the maximum size of the data block for input and output. If not defined, 32 KB or 64 KB, depending on the device type, is used as the default block size. OpenFrame technically supports the block size parameter, but during actual disk I/O operations, buffering is performed to the extent of the buffer size specified in the ds subject, in the NVSM_BUFFUR_SIZE key of the DATASET_DEFAULT section in OpenFrame configuration. For more information about OpenFrame configuration, refer to OpenFrame Configuration Guide. | |
Defines the data set structure. The following types of data set structure can be defined:
| |
RECFM represents the record characteristic as the following:
RECFM uses FB or VB for block I/O and VS or VBS for spanned records. | |
LRECL defines the length of the data set record. For a variable length record format or undefined length record format, the maximum record length must be defined. |
This section describes the size allocation of a space in a non-VSAM data set.
Specifying the Primary and Secondary Spaces
Space allocation sizes are determined in the following order:
-
When the values set in AVGREC, AVGVAL, PRIMARY, and SECONDARY spaces of the dataclass are used
Primary Space = (PRIMARY * AVGVAL * AVGREC + 1023)/1024 Secondary Space = (SECONDARY * AVGVAL * AVGREC + 1023)/1024
Item Description PRIMARY
4096 (Default)
SECONDARY
0 (Default)
AVGVAL
CYL (768 KB), TRK (48 KB), or a value set in LRECL
-
When LIKE or DCB=(dsname) is specified in the JCL DD statement
The primary and secondary space values of the model data set is used.
-
When a SPACE parameter is specified in the JCL DD statement
The SPACE=(AVGVAL,PRIMARY,SECONDARY) parameter is set as follows:
Primary Space = (PRIMARY * AVGVAL * AVGREC + 1023)/1024 Secondary Space = (SECONDARY * AVGVAL * AVGREC + 1023)/1024
Item Description PRIMARY
4096 (Default)
SECONDARY
0 (Default)
AVGVAL
CYL (768 KB), TRK (48 KB), or a value set in LRECL
-
If the primary space has not been set by the methods in 1-3, the spaces are set as follows:
Primary Space = The maximum space value of the volume device (megabyte) Secondary Space = 0
Calculating maximum space using the primary and secondary units
Calculates the maximum size based on the specified primary and secondary space.
Data Set Size Limit = (Primary Space + Secondary Space * conf_extent_limit) * 1024
| Item | Description |
|---|---|
conf_extent_limit | NVSM_EXTENT_LIMIT value in the DATASET_DEFAULT section of the ds subject in OpenFrame Configuration. It indicates the maximum number of secondary extents. If not specified, it is set to 15 by default. If the DATASET_SIZE_LIMIT value specified in the DATASET_DEFAULT section of the ds subject is smaller than the data set size limit, then DATASET_SIZE_LIMIT value is used. Conversely, the data set size limit is used. |
Note
For more information about OpenFrame Configuration, refer to OpenFrame Configuration Guide.
A sequential data set is the most common data set in the OpenFrame system, and it refers to a data set that can process data in the order the records are stored. A sequential data set can be stored in a disk volume or a tape device volume.
Creating a Sequential Data Set
The following are the steps for creating a sequential data set with QSAM or BSAM access methods:
-
Define DSORG=PS for the DCB parameter.
-
Define the type of the data set in the DD statement.
-
Open the data set, use the PUT or WRITE API, and then close the data set.
Retrieving a Sequential Data Set
The following describes how to read a record from a sequential data set:
-
Define DSORG=PS for the DCB parameter.
-
Define the location of the data set in the DD statement.
-
Open the data set, use the GET or READ API, and then close the data set.
Sequentially Concatenated Data Sets
The OpenFrame system provides a method to link two or more data sets so that they can be searched consecutively as if they are a single data set. This is called sequential concatenation. Sequentially concatenated data sets cannot be read in reverse, and VSAM data sets do not support sequential concatenation.
The following example shows how to use many data sets sequentially concatenated with BSAM.
//INPUT DD *
... (instream data set)
// DD DSN=IGKANG.MAIN.DATA,DISP=SHR
// DD DSN=IGKANG.SUPL.DATA,UNIT=3390,DISP=OLD,
BLKSIZE=4096
Modifying Sequential Data Sets
The following are two ways to modify sequential data sets:
-
Updating records in place
To update an existing record, it must be read and processed first before being updated with new information. The following rules apply:
-
Existing records cannot be deleted.
-
Data set must exist on a disk volume.
-
-
Extending the data set
To add a new record at the end of a data set, you must define DISP=MOD in the DD statement and open the data set in the OUTPUT mode. Then, you can use the PUT or WRITE API. In a sequential data set, a new record is always added to the end of the data set. It is not possible to add a new record between records.
A partitioned data set (PDS) is composed of sequentially structured members and a directory parameter described for each member. It is stored only on disk volumes.
Each member has a unique name composed of eight characters at most, and each record of a member can be sequentially read and written.
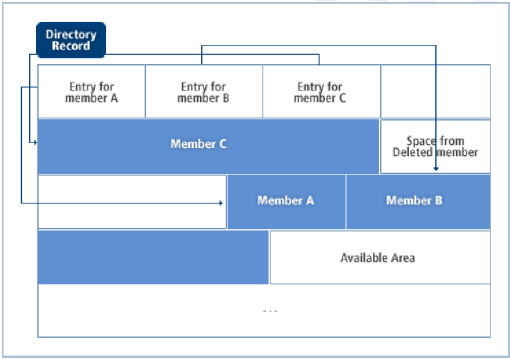
The advantage of a partitioned data set is that you can access each member without searching the entire data set. For example, take a program library. Each member of the PDS is an executable or a subroutine that can be individually executed. Depending on your need, you can add or delete each member.
OpenFrame maps the partitioned data set onto the UNIX file system's directory, and members are managed as individual files in the respective directories.
Creating a PDS
Using the BSAM, QSAM, or BPAM access method, you can create a partitioned data set or PDS member.
The following steps show how to create a data set and add a member:
-
Define DSORG=PS in the DCB parameter.
-
Specify that the data is to be stored as a new PDS member in the DD statement. That is, define DSNAME=<NAME> (member name) and DISP=NEW.
-
Open the data set, run the PUT or WRITE API, and then close it.
The following is an example of using JCL to create a partitioned data set.
//PDSDD DD ---,DSNAME=MASTFILE(MEMBERK),SPACE=(TRK,(100,5,7)), // DISP=(NEW,CATLG),DCB=(DSORG=PS,RECFM=FB,LRECL=80),---
By defining DSORG=PO instead of DSORG=PS and STOW API instead of PUT API or WRITE API in the previous example, you can use the BPAM access method to create a PDS.
To add a new member to an existing PDS, follow the aforementioned steps, but set DISP to MOD.
The following steps show how to add multiple members at once.
-
Define DSORG=PO for the DCB parameter.
-
Define the location of the entire PDS in the DD statement.
-
Open the data set, and add new members using the STOW API.
Processing a Member of a PDS
Because PDS members are equivalent to sequential data sets, you can perform I/Os on a PDS member as you would on a sequential data set. Also, you can use APIs provided in OpenFrame to manage directory entries or search members.
The BLDL API is used to search and read into memory all information related to the PDS directory parameter. The FIND API is used to move the record pointer to a designated location. The STOW API is used to add new members, delete existing members, and rename members. To use these APIs, DSORG=PO must be defined in the DCB parameter.
The following is a description of each API in the BPAM access method:
| API | Description |
|---|---|
Constructs, or builds, a directory entry list. Use the BLDL API to read the directory parameter related information from memory. This information is used for FIND API to access to the members of PDS. | |
Moves to the starting address of the member. Use the FIND API to move the record pointer to the start of a specific member. Input/output jobs that follow are performed from the location set by FIND. | |
Updates the directory. Add one or more members to the PDS. The STOW API can be used to add the directory parameter corresponding to the member to the PDS directory. To use the STOW API, DSORG=PO must be defined in the DCB parameter. |
Searching for a PDS member
To search for a specific member in a PDS, use BSAM or QSAM:
-
Define DSORG=PS for the DCB parameter.
-
Define the existing PDS member in the DD statement. That is, define DSNAME=name (member name) and either DISP=OLD, DISP=SHR, or DISP=MOD.
-
Open the data set, run the GET or READ API, and then close the data set.
The following is an example of a PDS member being processed with JCL.
//PDSDD DD ---,DSN=MASTFILE(MEMBERK), // DISP=SHR,DCB=(DSORG=PS),---
OpenFrame provides a way of cataloging a collection of successive, historically related data sets. A set of cataloged data sets is called a generation data group (GDG). Individual data sets contained in a GDG are called generation data sets (GDS) or generations.
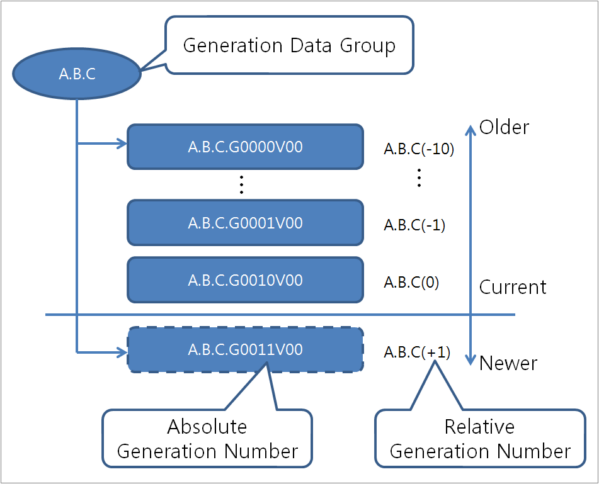
A generation data set can only be composed of sequential data sets. Partitioned data sets or VSAM data sets cannot form a generation data set.
Grouping related data sets together has the following benefits:
-
Data sets in the same group can be referenced using the same name.
-
The system can manage data set generation in sequential order.
-
A data set of an old generation is to be deleted from the system automatically.
A generation data set has an absolute name and a relative name that represents its age. A catalog management system only uses absolute generation names. Older data sets have smaller absolute numbers. For the relative name, the most recent data set is represented by (0), and the next recent data set is (-1). Relative names can also be used to catalog a new generation (+1).
A generation data group (GDG) BASE must be registered to the catalog before the generation data sets are cataloged. Each generation data group is represented by the cataloged GDG base category. You can use the GDG BASE by using the gdgcreate tool program.
Note
For more information about the gdgcreate program, refer to OpenFrame Tool Reference Guide.
An absolute generation number and version number are used to represent a specific generation of the GDG. The combination of an absolute generation number and version number is specified as GxxxxVyy, where 'xxxx' represents a four-digit generation number (0001 – 9999) and 'yy' represents a two-digit version number (00–99).
The following is an example of specifying a generation using its absolute generation number and version number.
Example) A.B.C.G0001V00
This represents a data set with a generation number of 1, in the generation data set group A.B.C., with a version number of 0.
Example) A.B.C.G0009V01
This represents a data set with a generation number of 9, in the generation data set group A.B.C., with a version number of 1.
The system automatically manages generation numbers. The maximum number of generations is decided by the limit defined in the GDG BASE. For example, GDG with the limit of 10 can have up to ten items managed by the GDG.
The version number allows data sets to process jobs without disturbing the generation management of GDG. For example, when an update of the second generation is needed in a GDG, that is managing three generations, the version of the G0002 can be changed from V00 to V01. In a generation, only one version is managed by the GDG.
When registering a generation data set to the catalog, you can use either the absolute name or relative name. After the generation has been registered, the generation number and version number of the generation are registered to a GDG entry. When registering a generation data set with a version number other than V00, you must specify both the absolute generation number and version number.
Instead of using an absolute generation and version number, a relative generation number can be used to specify a generation. To use the relative generation number, you must specify a number enclosed in parenthesis, such as in A.B.C(-1), A.B.C(+1), and A.B.C(0).
When a relative generation number is given, the system uses this number and the most recently registered absolute generation number to determine the desired absolute generation number. For example, if A.B.C.G0005V00 was the generation data set that was cataloged last in a previous job, when given A.B.C(+1) the system comes up with A.B.C.G0006V00 as the absolute generation number.
When cataloging or uncataloging a data set in a multi-step job, you can only use JCL, not IEHPROGM (JSGPROGM) or any other user programs. Data sets allocated during an IEHPROGM (JSGPROGM) program or user program execution are not reported to the data set allocation management system. Thus, in the subsequent step, the current state of the data set is lost and may cause a conflict or another problem.
When referencing the previously cataloged generation data set using a relative number, the relative number has the following meanings:
-
A.B.C (0) refers to the most recently registered entry
-
A.B.C (-1) refers to the previous entry of the most recently registered entry
When performing a cataloging job of a data set using JCL, all actual cataloging is performed when exiting the job step. However, the relative generation number is maintained until the end of an actual job. Therefore, the following situations may occur:
-
A relative generation number used in JCL always points to the same generation data set during batch jobs.
-
After cataloging the GDG for the generation data set, all relative generation numbers must be modified before performing a JCL submit. For example, before the step is restarted, A.B.C(+1) must be changed to A.B.C(0), A.B.C(0) to A.B.C(-1), and A.B.C(-1) to A.B.C(-2).
Non-VSAM data sets can be stored on a tape device volume. However, VSAM data sets cannot be stored.
A tape volume in OpenFrame does not use an actual physical tape device. The tape volume is virtual, and it can be located in DASD. It can be created by creating a volume on a tape device during a volume creation with volmgr. When defining a tape device, set the device type number to 3480.
volmgr define device -dn 0010 -dt 3480 -dg STAPE
Define the tape device's logical tape volume and the logical tape volume's physical tape volume.
volmgr define volume -v STAPE1 -dn 0010 volmgr define volume -v ST0001 -lv STAPE1 -t
One or more physical tape volumes in the logical tape volume can be created. The volumes can be switched if necessary.
volmgr update volume -v STAPE1 -pv ST0002
OpenFrame allows to access a tape volume by using a file sequence number.
To use the file sequence numbers, set the USE_TAPE_FILESEQ key in the DATASET_DEFAULT section of the ds subject to YES in OpenFrame configuration.
ofconfig update -n NODE1 -s ds -sec DATASET_DEFAULT -k USE_TAPE_FILESEQ -v YES
File sequence numbers can be used when accessing a data set with JCL. In XSP systems, a file sequence number is specified in FILE. In other systems, it is specified in LABEL of a DD statement.
File sequence numbers can be used to search for a data set in a tape volume. Incidentally, a data set name can be used to check the integrity with a data set at the position of the sequence number or to create a new data set.
If the number is omitted, a data set name is used to search for a data set in a tape volume. If a specified data set name does not exist, it is regarded that the file sequence number is 1.
Deleting a tape data set that does not use file sequence numbers is the same as deleting a data set in DASD. The following describes how to delete a data set that uses file sequence numbers.
When a new data set is created or a new record is written in an existing data set, data sets located after the data set are deleted. This is the same as in OpenFrame. At the point in time when OPEN is performed on a tape data set in OUTPU mode, all data sets located after the current data set are deleted. They are not deleted depending on the physical characteristics of the actual tape. If the data sets are registered in a catalog, the catalog remains.
Tape data sets cannot be deleted with DISP of JOB because mainframes do not allow to execute DELETE on tape data sets with DISP. In OpenFrame, DELETE can be specified for a data set, but it is internally changed to KEEP, which does not delete the data set. However, data sets can be deleted with the dsdelete tool. When deleting a data set by using the tool, all data sets located after the data set are deleted.
Consider the following when using a tape volume.
-
In OpenFrame, volume locks as well as data set locks are used to protect a tape volume when file sequence numbers are used. Therefore, one tape volume cannot be concurrently used by multiple JOBs. However, it cannot prevent that an application uses multiple data sets in one tape volume at the same time. Note that there may be a data set related issue in this case.
-
DCB handling
Use the DCB handling API with care when using file sequence numbers. When the numbers are used, DCB for tape data sets is created by assuming INPUT mode. There may be incorrect information about tape data sets to use in OUTPUT mode until they are open. Therefore, execute DCB information and Get attributes functions after executing OPEN on the tape data set.