Table of Contents
This chapter describes VSAM data set management concepts including the VSAM data format, VSAM, data set type, secondary index and sphere.
In the 1970s, IBM developed a new access method and related utility programs that integrate three data set structures (sequential, indexed, and direct-access). This new access method is associated with the virtual storage operating system used at the time, OS/VS1 and OS/VS2, and is called virtual storage access method (VSAM).
VSAM is used to store and search data. VSAM uses the GET/PUT interface to transmit data between disk devices and application programs. All VSAM data sets must be registered to the catalog and cannot be saved on tape device columns.
OpenFrame supports TSAM as a counterpart of VSAM. TSAM uses database as its low-level storage. A separate TSAM communication protocol used between TSAM clients and the storage server eliminates SQL overhead. In addition, an optimized communication protocol used for batch jobs enhances performance.
All data in a VSAM data set are arranged in logical records. Logical records are user records transmitted to the user through the VSAM interface.
A VSAM data set stores logical records differently than a non-VSAM data set. VSAM stores records in a control interval. A control interval is a continuous region of the disk device where data records and record control information are stored. When reading a VSAM record, the entire control interval of the respective record is read into the VSAM I/O buffer in memory.
Control Interval
The sizes of control intervals can differ between different VSAM data sets, but the sizes of CIs within a single data set are the same. Using the access method services command, DEFINE, the size of the VSAM data set can be defined.
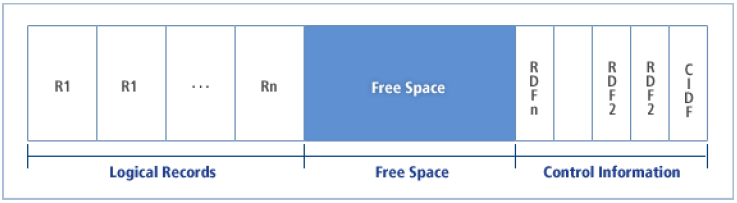
A control interval is composed of the following:
-
Logical records
-
Free space
-
Control information
Control information is composed of a single control interval definition field (CIDF) and one or more record definition fields (RDFs). A CIDF has four bytes. It stores the size and position of the free space. RDFs are three bytes that store each record's size information.
The following table describes common terms related to the control interval:
| Term | Description |
|---|---|
Group of continuous control intervals of a VSAM data set. The number of control intervals in a control area is determined by VSAM. One or more control areas comprise the VSAM data set. | |
Moving half of existing records in a control interval to another so that new records can be added to the current control interval. Splitting occurs when a record has to be added to a control interval that has not enough space. | |
Records bigger than the control interval size. When defining a VSAM data set, they use the SPANNED parameter to indicate that a record spans multiple control intervals. If record sizes change frequently or the average record size is bigger than the control interval size, use spanned records to save disk space. | |
One of individual units that comprise a VSAM data set. A component can be either data component or index component. KSDS and VRDS have data components and index components. ESDS and RRDS have only data components. | |
Any VSAM data set. A cluster consists of up to two related components. For KSDS, one cluster consists of a data component and an index component. RRDS and ESDS data sets are clusters without an index component, and their cluster name is used to process them for consistency. |
In OpenFrame, the related database involves only the base architecture technologies that do not involve control intervals and control areas.
The following table lists TSAM database components used to support VSAM data sets:
| Mainframe VSAM | OpenFrame TSAM | Description |
|---|---|---|
Storage Volume | Table Space | Table space mapping by volumes |
Cluster | Table | One table for each cluster |
Record | ROW | Mapping of one record to one row |
VSAM stores and processes data records in the order of the index and record number or relative address. It can also perform sequential and direct processing of fixed-length and variable-length records.
VSAM constructs data sets using the following four methods:
| Type | Description |
|---|---|
Data set by key sequence | |
Data set by input sequence | |
Data set by record number RRDS records fall under the following two categories on record lengths:
| |
Linear data set. TSAM does not support LDS. LDS is handled as a flat data set (FDS) in Hitachi mainframes. |
Key-sequenced data set (KSDS) records are stored in the data set in the order of record keys.
KSDS keys refer to a specific field of a record and have the following characteristics:
-
All key lengths and positions are the same.
-
Two or more records having the same key value cannot be stored.
-
Once stored, the key value cannot be changed.
KSDS supports both fixed and variable length records. When adding a new record, the record is positioned in ascending order.
To manage KSDS efficiently, VSAM creates a data component that stores the actual data and an index component that allows rapid access to the records in the order of the key values.
As with non-VSAM data sets, entry-sequenced data set (ESDS) stores records in the order of input. Any new records are added to the end of the data set.
Once stored in an ESDS, the records cannot be deleted. You can only make a logical deletion in an application by marking the record with a delete flag.
Also, records stored in an ESDS can be updated but their length cannot be modified. If absolutely needed, you must make a logical deletion and add a new record with a desired length to the end of the data set. For an application that may require frequent length changes, it is recommended to use KSDS instead.
An ESDS does not have an index component, but you can use an alternate index. For more information about an alternate index, refer to "3.5. Alternate Index and Sphere".
Relative record data set (RRDS) is used to store fixed-length records in numbered slots. Each record has a number, and the record is saved in the slot with a matching number. Multiple fixed-length slots are created for one data block of the RRDS.
To calculate the size of a data block, multiply the given record length by the number of records in the block and sum it with overhead size. If data block size is not calculated in this way, the data block may contain unusable space. However, such space does not cause a significant issue because it does not exceed the given record length.
Because an RRDS stores fixed-length records, you can figure out the location of a specific record through a simple calculation with the record number, which facilitates access to data records. However, given that the record lengths are fixed and records are identified with their numbers, this method may not be suitable for an application domain. Therefore, it is recommended to use this method only when you are handling a limited number of objects.
VRDS is an RRDS data set that can store variable-length records. From the user's perspective, a VRDS is the same as an RRDS because for both data sets, you provide the same parameters and use the same access method. However, from the VSAM's perspective, an VRDS is rather similar to KSDS because both use an index component and a data component.
An index component is used for a VRDS because of the variable length of a record, which makes it difficult to locate the record when requested. The difference between the VRDS and the KSDS is that the index component of a KSDS record takes the key region of the record while the index component of a VRDS record takes a user-defined record number. For both the VRDS and the KSDS, the index component begins on the same RBA.
Note
VRDS is not supported because OpenFrame processes both fixed-length and variable-length records only with RRDS.
A VSAM data set can be created by specifying a cluster name and a component name.
If the cluster name is specified without the component name, it is created according to component naming rules.
The following are three component naming rules:
-
When the last name segment of the cluster is "CLUSTER"
-
The last name segment of a data component is set to "DATA".
-
The last name segment of an index component is set to "INDEX".
The following is an example of data component and index component names created for a cluster named TMAX.TEST.KSDS01.CLUSTER:
Cluster name: TMAX.TEST.KSDS01.CLUSTER Data component: TMAX.TEST.KSDS01.DATA Index component: TMAX.TEST.KSDS01.INDEX
-
-
When the name of a cluster is 38 characters long or shorter.
-
A data component is appended with ".DATA".
-
An index component is appended with ".INDEX".
The following is an example of data component and index component names created for a cluster named TMAX.TEST.KSDS01.INFO.
Cluster name: TMAX.TEST.KSDS01.INFO Data component: TMAX.TEST.KSDS01.INFO.DATA Index component: TMAX.TEST.KSDS01.INFO.INDEX
-
-
When the name of a cluster is 39 characters long or longer.
-
A data component is appended with ".D".
-
An index component is appended with ".I".
The following is an example of data component and index component names created for a cluster named TMAX.TEST.KSDS01.RESOURCE.FROM.REGION01.
Cluster name: TMAX.TEST.KSDS01.RESOURCE.FROM.REGION01 Data component: TMAX.TEST.KSDS01.RESOURCE.FROM.REGION01.D Index component: TMAX.TEST.KSDS01.RESOURCE.FROM.REGION01.I
Note
When a cluster name is 43 or 44 characters long, the component name is set to 45 or 46 characters long by the third component naming rule, which exceeds the maximum length of a data set name. To avoid the maximum length error, when the cluster name is specified without the component name, a VSAM data set name must be no longer than 42 characters.
-
This section describes the concept of the alternate index and sphere.
By using the access method services, you can define the alternate index (AIX) of KSDS or the ESDS (base cluster). The alternate index supports key fields, other than the primary key, to access the base cluster.
By using the alternate index, you can manage multiple copies of the same data set for different application programs more easily.
Any part of the base cluster can be the key of an alternate index. It is possible to make multiple alternate indexes using the same part of the base record as an alternate key for all the indexes, but such functionality is not supported by OpenFrame.
In practice, the alternate key is an independent KSDS data set composed of index components and data components. The alternate index record contains the alternate key and pointer to the base cluster's data. In OpenFrame, a database index instead of an independent KSDS is created to the base cluster table.
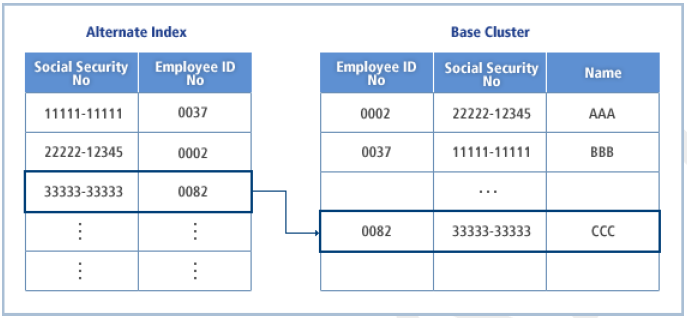
Alternate Index Access Path
Before processing KSDS or ESDS using an alternate index, the access path must first be defined (not required in OpenFrame). The access path is the catalog entry used when processing a base cluster using an alternate index.
An access path can be defined by using the IDCAMS (JSCVSUT/KQCAMS) DEFINE PATH command. Each alternate index must have at least one or more access paths defined so that the base cluster can be processed with an alternate index. Conceptually, the access path can be viewed as a pair of a base cluster and an alternate index.
When application programs use the access path for processing, the base cluster and alternate index data set open together. The group of a base cluster and all of its related alternate indexes is called a sphere.
A sphere is composed of a base cluster and its associated alternate indexes. An alternate index for a base cluster is a KSDS data set cluster composed of records with an alternate key and multiple primary keys.
When applying the sphere concept, an additional access method is added to the data set acting as the base. An access method, not in the same category as the sequential access method or direct access method, is created from a key that is not the base data set's primary key. This means that there exists multiple access paths to data.
COBOL application programs use data sets with the ALTERNATE KEY statement. The VSAM access method provides a sequential or direct access method using multiple alternate keys for KSDS or ESDS. These types of access methods are called 'access methods by access path'.
The VSAM data set can be defined with access method services commands.
The following describes how to manage VSAM data sets:
-
All data sets must be registered in the catalog. To use a new catalog, a new catalog must be created with the access method services DEFINE USERCATALOG command.
-
The VSAM data set can also be defined in a catalog using the access method services DEFINE CLUSTER command. OpenFrame does not support creating a VSAM data set with JCL (DISP=NEW).
-
Load data into the VSAM data set using the access method services REPRO command or a user written program.
-
It is recommended to use the alternate index in combination with the base cluster and the access method services DEFINE ALTERNATEINDEX, DEFINE PATH, and BLDINDEX commands.
To verify the results of tasks after completing the previous steps, use the access method services LISTCAT or PRINT command. The LISTCAT or PRINT command is commonly used to identify and correct VSAM data set related problems.
Cluster Concept
For the KSDS, a cluster is a group of data and index components. A cluster allows the data and index components to be handled as a single component. In a fixed-length RRDS or ESDS, a data component without an index component is still identified as a cluster and is given a cluster name for consistency with other data sets.
Defining VSAM Data Sets
A VSAM data set can be defined using the DEFINE CLUSTER command of the access method services.
When a cluster is defined, the following catalog entries are created.
-
A cluster entry that allows a cluster to be used as a single component
-
A data entry that specifies the data component of the cluster
-
A KSDS data set, an index entry that specifies the index component of the cluster
All attributes of a cluster are written to the catalog. The catalog must be supplied with all the information necessary to perform I/O on records or manage a data set.
When defining a VSAM data set using the access method services, the following parameters can be specified.
| Parameter | Description |
|---|---|
VSAM data set type.
| |
Average or maximum data record length. For fixed-length records, the average record length is equal to the maximum record length. | |
Position and length of the key of a KSDS record. | |
Name of the catalog the cluster is to be defined in. | |
Volume serial to allocate to the cluster. | |
RECORDS|KILOBYTES|MEGABYTES| | Disk space size of the cluster. |
Size of the control interval to be used in VSAM. Not supported in OpenFrame. | |
Option to store a record across multiple control intervals. Not supported in OpenFrame. |
Loading VSAM Data Sets
If a VSAM data set is defined, you can load records from a source data set to the VSAM data set. The records in the data source must be arranged in a specific order to be loaded into the VSAM data set of a particular type. The following describes the VSAM data set types and corresponding source data set order.
-
Data records to be stored in an ESDS data set
There is no required order. Records are loaded sequentially.
-
Data records to be stored in a KSDS data set
Records must be ordered in ascending order with no duplicate keys.
-
Data records to be stored in an RRDS data set
Records must also be ordered in ascending order. If they are loaded sequentially, they are assigned with a relative record number in sequence.
You can load data sets in the following two ways:
-
Using REPRO
You can use the access method services REPRO command, which extracts records from a sequential data set or a VSAM data set to load them into any VSAM data set.
-
Writing a program
You can write a program to load records into a KSDS data set. Before loading them, first arrange the records in the key order and then load them in order.
Defining Alternate Indexes
An alternate index is a type of KDSD data set in which indexes are arranged in the order of the alternate keys of associated base records. An alternate index can be used to find records in the data component of a cluster.
An alternate index may define a KSDS cluster or an ESDS cluster. The steps for building an alternate index are as follows:
-
Use the DEFINE CLUSTER command to define a base cluster.
-
Use the REPRO command or write a program to load the base cluster.
-
Use the DEFINE ALTERNATEINDEX command to define an alternate index.
-
Use the DEFINE PATH command to link the alternate index to the base cluster.
-
Use the BLDINDEX command to build the alternate index.
Note
In OpenFrame, it is not required to define PATH to link alternate indexes to the base cluster and building alternate indexes with BLDINDEX.
To describe an alternate index, VSAM uses the following three catalog entries:
-
An alternate index entry that describes the alternate index as a KSDS data set
-
A data entry that describes the data component of the alternate index
-
An index entry that describes the index component of the alternate index
When defining an alternate index that does not have unique keys, the record size must be defined as large as possible to be able to process all non-unique keys. Primary key values of all records having the same alternate key are saved in a single alternate index record.
Managing Alternate Indexes
Because VSAM assumes that the alternate index is synchronized with the base cluster, VSAM does not check their synchronization status every time a data set is opened.
If you specified the UPGRADE property when defining an alternate index, and if its associated base cluster is changed, you need to change the alternate index too. As a result, when the base cluster is opened in output mode, all associated alternate indexes are automatically opened.
OpenFrame creates alternate indexes by creating database indexes on the base cluster table, which has basically the same effect as the UPGRADE attribute even if OpenFrame does not support the UPGRADE/NOUPGRADE attributes.
Defining Access Paths
After defining an alternate index with the DEFINE PATH command, you must link the alternate index to the base cluster. A pair of a base cluster and an alternate index is called an access path. If you want to use an access path to access a data set, you must specify the access path name for the DSNAME parameter in JCL. An access path refers to the combined pair of a base cluster and an alternate index. When accessing a data set using the access path, the access path name for JCL's DSNAME parameter must be specified.
When an access path is used to access a data set, both the alternate index and the base cluster are opened at once. The base cluster's data is read or written by using the alternate index key.
Listing Catalog Entries
After you define a VSAM data set, you can use the access method services LISTCAT command to query a part or all of the entries registered in a catalog.
The LISTCAT command displays the following information registered in a catalog:
-
Properties of all objects including the SMS property
-
Dates of creation and expiration
-
Data set structure
-
Statistics on data set usage
-
Volume information and space allocation information
Copying Data Sets
You may want to make a copy of a data set or combine two data sets into one for many reasons such as testing a data set or making backup files before an update. In such cases, you can use the access method services REPRO command to copy the data sets.
The REPRO command can be used in the following cases:
-
Creating a new VSAM data set
-
Creating a new sequential data set
-
Converting a sequential data set into a VSAM data set
-
Converting a VSAM data set into a sequential data set
-
Performing REORGANIZE automatically
-
Copying individual members of a PDS or a partitioned data set extended (PDSE)
When copying to a KSDS data set, data records of the input data set must be sorted in ascending order without any duplicate keys.
When a VSAM data set is being copied sequentially, the following reorganization is automatically performed:
-
Relocation of logical records in physical order
-
Redistribution of a data set's internal free space
-
Reconstruction of the VSAM index component
Displaying Data Set
When there is a problem while using a data set, you can use the access method services PRINT command to print a part or all of the records.
The PRINT command prints not the control fields managed by the system but the content of logical records. Each printed record is identified by the following information:
-
RBA for ESDS data sets
-
Key value (KEY) for KSDS data sets
-
Record number (RRN) for RRDS data sets
Deleting Data Sets
You can use the access method services DELETE command to delete a data set or a catalog. The DELETE command removes the data set from the volume on which the data set resides and removes the data set entry from the catalog.
Browsing
The following interfaces are supported for browsing:
| Interface | Description |
|---|---|
Starts browsing in the same way as TSAM reads random records. Only initializes the browser's pointer without reading records. | |
Reads records sequentially from the starting position defined by the START_BR interface. | |
Reads data sets in reverse order. | |
Changes the current browsing pointer when browsing begins. You can also change the browsing pointer simply by changing the RIDFLD parameters of the READ_NEXT or READ_PREV interfaces. |
Transaction
Transaction is a logical unit of work representing one or more sets of jobs that are required to be processed at once.
The following interfaces are supported for transaction: