Table of Contents
This chapter describes about the SELECT statement in detail.
Searches for desired data from one or more table or views.
A detailed description of SELECT follows:
-
Syntax



-
Privileges
Users who have the SELECT ANY TABLE system privilege are allowed to search all tables and views.
To search a table, the table should be owned by the user, or the user should have the SELECT schema object privilege on the object.
To search the base table of a view, both of the following conditions should be satisfied:
-
The user should own the view, or have the SELECT schema object privilege on the view.
-
The user of the schema containing the view should own the base table of the view, or have the SELECT schema object privilege on the base table.
-
-
Components
-
select
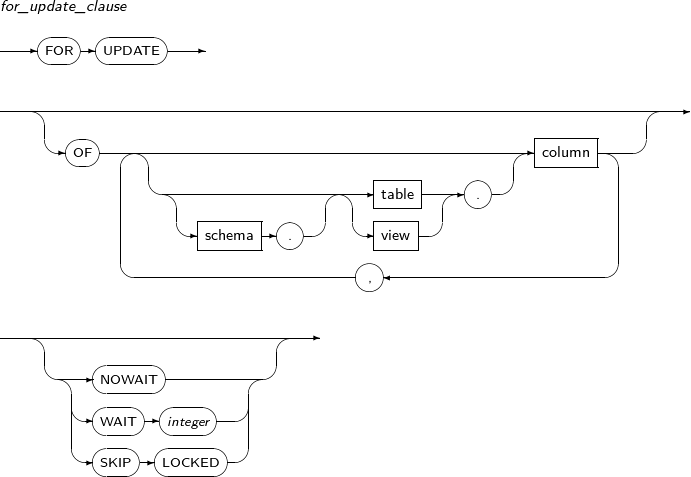
Component Description with_clause Defines subqueries and assigns names. subquery Specifies a query. for_update_clause Locks all returned rows in order to prevent other users from reading or updating them.
The rows remain locked until the current transaction is terminated. for_update_clause cannot be included in subqueries.
If a query joins two or more tables or views, for_update_clause locks all the selected tables and views.
for_update_clause cannot be included in a query whose result row cannot be determined to be a unique row in the base table.
It cannot be included in the following query statements:
-
A statement that contains DISTINCT in the SELECT clause.
-
A statement that contains set or back operations for two or more tables or views.
-
A statement that contains a GROUP BY clause, or that contains aggregate functions in the SELECT clause.
-
-
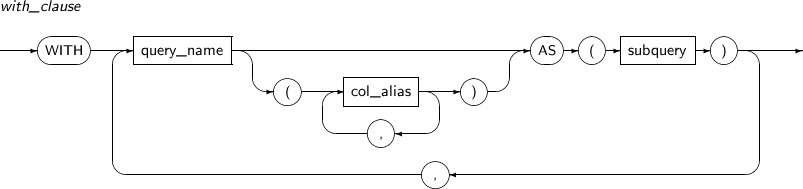
with_clause
Component Description query_name Name of a subquery.
Specify query_name for a subquery that is to be defined after the main query and the current subquery.
col_alias Provides an alias for a column name in the subquery. subquery Specifies a query. with_clause has the following restriction:
-
In a subquery defined as query_name, query_name cannot be referenced.
-
-
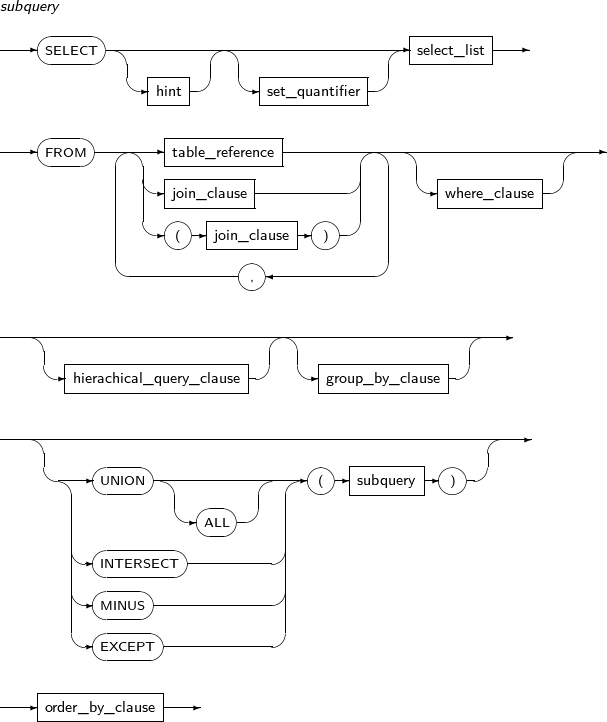
subquery
Component Description hint Uses hints. A hint gives instructions to the optimizer on how to perform a particular action, or modifies the execution plan of the optimizer. For details, see “2.8. Hints”. set_quantifier Specifies whether to allow duplicate rows in the result. One of the following can be specified:
-
DISTINCT, UNIQUE: Removes duplicate rows.
-
ALL: Selects all rows. The default value.
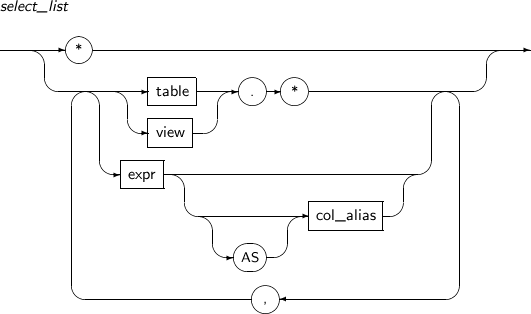
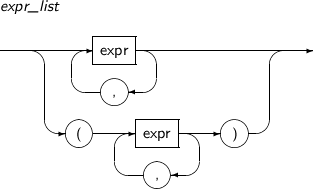
select_list Specifies expressions to be returned as a query result.
It has the following restrictions:
If group_by_clause is specified, select_list can only use a combination of the following expressions:
-
A constant
-
An aggregate function
-
An expression combined with expressions used in group_by_clause
If ROWID is selected in a join view, that of a key-preserved table that is specified at the end is selected. If there is no key-preserved table, it is impossible to select ROWID.
If two or more tables or views which contain columns with the same name are joined together, the column name should be specified with the table name or an alias to identify the column.
FROM Specifies one or more tables, views, or subqueries to query. table_reference Specifies tables, views or inline views for a query, and sets the join relationship. where_clause The WHERE clause searches only the rows which satisfy a conditional expression. If the WHERE clause is omitted, all rows of the query's target object are returned. For details about conditional expressions, refer to “3.4. Conditional Expressions”. hierarchical_query_clause Defines and searches a hierarchical relationship among rows in a table or joined tables.
This kind of query is called a hierarchical query, and it is performed using the START WITH … CONNECT BY clauses. The CONNECT BY clause contains the PRIOR operator which is not used in other conditional expressions. To perform a sort in a hierarchical query, use the ORDER SIBLINGS BY clause.
For more details about hierarchical queries, see “5.5. Hierarchical Queries”.
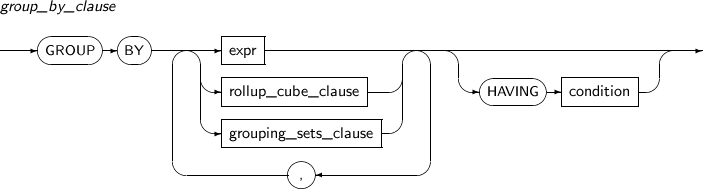
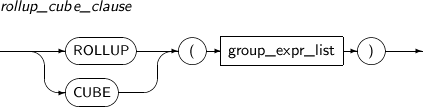
group_by_clause The GROUP BY clause groups returned rows. By using the CUBE or ROLLUP extensions, an upper group can be created with such row groups.
One or more expressions can be used for grouping, and the HAVING clause can be used to return a desired group.
A grouped result might not be sorted, so use the ORDER BY clause to sort the final result.
LOB columns and subqueries cannot be used in GROUP BY query expressions.
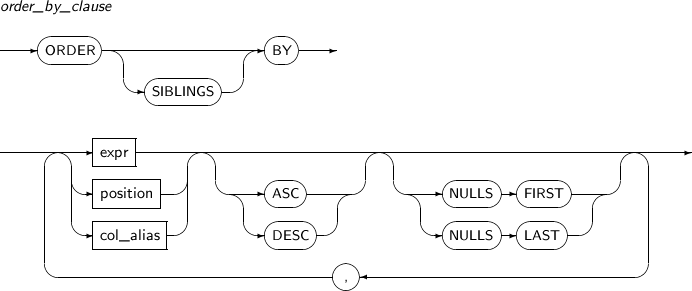
UNION (ALL) Creates a new result that removes duplicate rows from both query results. Specify ALL to indicate that duplicate rows should not be removed. INTERSECT Creates a new result with rows which are found in both query results. MINUS Creates a new result that removes rows from one result that also appear in a second result. EXCEPT Identical to MINUS. Creates a new result that removes rows from one result that also appear in a second result. order_by_clause The ORDER BY clause sorts and return rows from the search result.
Columns, column aliases, and expressions that contain column names may be used to specify the sorting order.
If several sort orders are specified, rows are sorted in the order that they appear in the statement. The standard sorting methods appear below.
order_by_clause has the following restrictions:
-
If DISTINCT is specified in select_list, only an expr used in select_list of order_by_clause can be used as a sorting key.
-
Cannot use LOB data type columns.
-
If group_by_clause is specified, only the four types of expr in the following table can be used in order_by_clause:
Count Available expr 1 Constants 2 Aggregate functions 3 Analytic functions 4 An expr used in group_by_clause.
-
-
select_list
-
table_reference
-
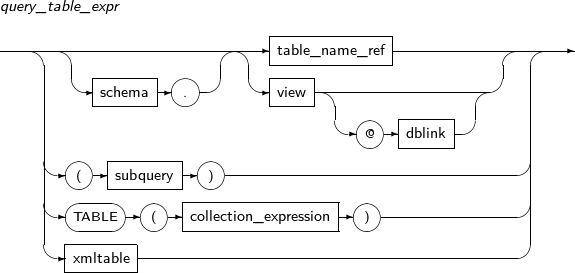
query_table_expr
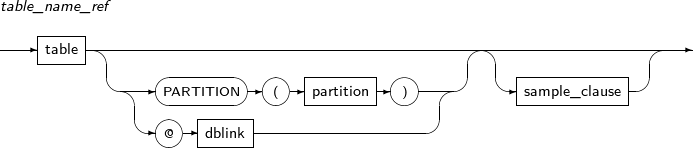
Component Description schema Specifies the schema for a table. If omitted, the schema of the current user will be used. table Specifies a table name. PARTITION (partition) Specifies the name of a particular partition. Reads from the specified partition instead of the entire table. dblink Specifies whole or part of a database link name. An at symbol (@) must prepend each database link name.
A database link has the following restrictions:
-
Tibero does not support querying a REF object from a remote table.
-
Tibero does not support querying ANYTYPE, ANYDATA, or ANYDATASET columns from a remote table.
view Specifies a view name. sample_clause Provides a random sample of data from the table. subquery Specifies a subquery. collection_expression Specifies a pipelined table function. The result of the function can be used as a table. For more details, refer to "Chapter 9. Pipelined Table Functions" in Tibero tbPSM Guide. xmltable Specifies the XMLTABLE function. -
-
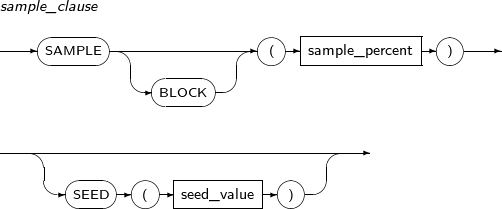
sample_clause
Component Description BLOCK If this keyword is specified, a data block is sampled. If not specified, a row is sampled. sample_percent Specifies a ratio of rows or blocks to be sampled. A number from .000001 to 100 can be specified. seed_value Selects the same sampling data in subsequent executions. If seed_value is not specified, different data is selected in subsequent executions. A number between 0 and 4294967295 can be specified. -
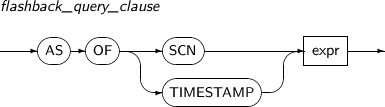
flashback_query_clause
Component Description expr Expression which indicates a previous event.
-
Can specify a certain point of time with SCN or TIMESTAMP.
-
If AS OF SCN is used, expr should be a NUMBER.
-
If AS OF TIMESTAMP is used, expr should be a TIMESTAMP.
flashback_query_clause has the following restrictions:
-
Columns and subqueries cannot be used in expr.
-
Cannot be used in a query_name which is used in table_reference to reference a subquery defined in with_clause.
-
-
pivot_clause
PIVOT converts table rows into columns. An aggregation function that belong to the same group is used to generate new column values. pivot_clause does not contain an explicit GROUP BY CLAUSE. Instead, query_table_expr, which is not defined in pivot_clause, performs implicit grouping.
Component Description aggregate_function Aggregation function that generates column values.
If an alias is specified, a new column name is created by adding an underscore '_' and the alias to the column created in pivot_in_clause.
pivot_for_clause Column to be pivoted. pivot_in_clause Value of the column to be pivoted.
Calculates a column value by creating the specified number of columns and applying the aggregation function to each column. A value that is not defined is not applied to the aggregation function.
If an alias is not used, the specified value is used as a column name.
-
unpivot_clause
UNPIVOT converts table columns into rows. The same column from all rows are collected and converted into a single row.
Component Description INCLUDE|EXCLUDE NULLS INCLUDE NULLS creates a row that includes null values.
EXCLUDE NULLS does not create a row with null values. By default, EXCLUDE NULLS is used.
column Name of each unpivoted query output column that holds measure values.
An output value that is the result of performing UNPIVOT is called a measure value. The datatypes of all values in a column must be in the same datatype group or compatible with the final result type.
pivot_for_clause Name of each output column that will hold descriptor values. The value specified in this column is used to describe measure values. unpivot_in_clause Column whose name becomes the values in the measure column.
If a literal is specified, it is used as the value of the descriptor value column. By default, a column name is used.
-
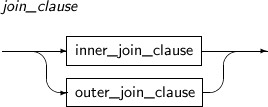
join_clause
-
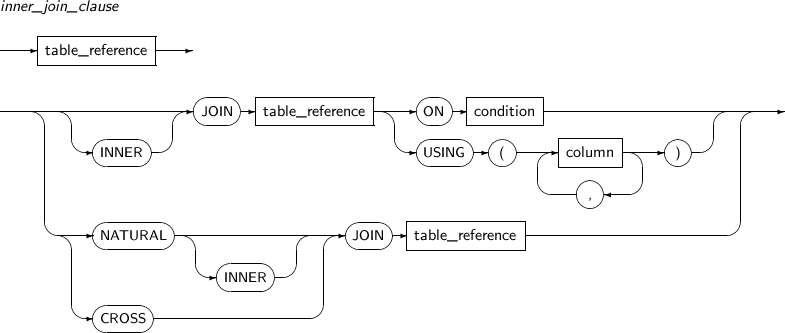
inner_join_clause
-
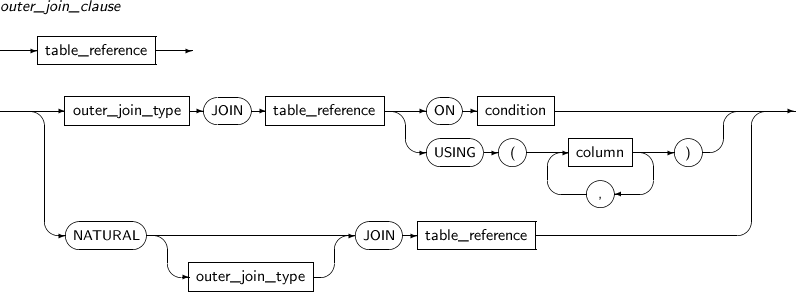
outer_join_clause
-
outer_join_type
-
cross_join_clause
Component Description table_reference Specifies tables, views and inline views to join. -
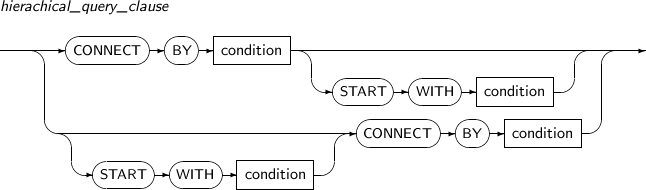
hierarchical_query_clause
Component Description CONNECT BY Specifies a conditional expression to define a hierarchy among rows. START WITH Specifies a conditional expression to define the root row in the hierarchy. condition Specifies conditional expressions. -
group_by_clause
Component Description expr Specifies an expression to group rows. rollup_cube_clause Specifies the ROLLUP and CUBE operations. grouping_sets_clause Specifies GROUPING SETS. HAVING condition Specifies a conditional expression to return only the desired group. -
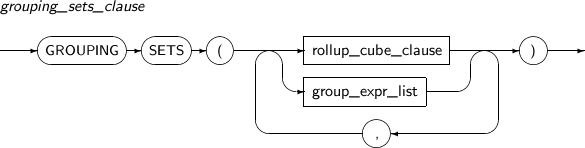
grouping_sets_clause
Component Description GROUPING SETS Groups selected rows based on multiple expressions specified after GROUPING SETS, and returns a row that includes summarized group information for each group.
GROUPING SETS is effective because it groups only the selected expressions whereas CUBE and ROLLUP will group every combination of expressions. GROUPING SETS is more efficient, because using a CUBE or ROLLUP operation is the same as using GROUP BY for multiple expressions and then using UNION ALL, which may create duplicate rows.
CUBE or ROLLUP can be specified with combinations of expressions after GROUPING SETS.
If multiple CUBE or ROLLUP operations are used after GROUPING SETS, all the expression combinations are evaluated with cross products of each combination.
-
rollup_cube_clause
-
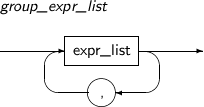
group_expr_list
Component Description expr_list List expressions. -
-
-
Combines the results of two SELECT statements into a single result set.
The type and number of corresponding columns in select_list should be the same. The column lengths may be different. To refer to column names, the left-most specified select_list in a SELECT statement is used.
When SELECT statements are combined by a set operator, queries are performed from left to right.
For details about set operators, see “5.4. Set Operators”.
-
-
Example
The following example illustrates the use of SELECT.
SELECT * FROM EMP; SELECT ENAME, SALARY * 1.05 FROM EMP WHERE DEPTNO = 5; SELECT ENAME, SALARY, DEPT.* FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO; SELECT ENAME, SALARY, LOC FROM EMP NATURAL JOIN DEPT; SELECT ENAME FROM EMP WHERE DEPTNO = 5 UNION SELECT ENAME FROM EMP WHERE DEPTNO = 7; SELECT DEPTNO, MAX(SALARY) FROM EMP GROUP BY DEPTNO HAVING DEPTNO >= 5; SELECT DISTINCT DEPTNO FROM EMP; SELECT * FROM EMP WHERE DEPTNO = 5 FOR UPDATE; SELECT ENAME, D.* FROM EMP E, DEPT D WHERE E.DEPTNO = D.DEPTNO FOR UPDATE OF LOC;
The next example shows how to execute a FLASHBACK query using time.
SQL> create table todo (item varchar2(20), duedate date); Table 'TODO' created. SQL> insert into todo values ('Attending the wedding ceremony', '2012-04-01'); 1 row inserted. SQL> insert into todo values ('Shopping', '2011-12-28'); 1 row inserted. SQL> commit; Commit completed. SQL> select systimestamp from dual; SYSTIMESTAMP ----------------------------------------------------------------- 2011/12/28 18:41:33.854889 1 row selected. SQL> select * from todo; ITEM DUEDATE ----------------------------------- -------------------------------- Attending the wedding ceremony 2012/04/01 Shopping 2011/12/28 2 rows selected. SQL> insert into todo values ('Paying newspaper subscription', '2011-12-31'); 1 row inserted. SQL> commit; Commit completed. SQL> select * from todo; ITEM DUEDATE ------------------------------------ -------------------------------- Attending the wedding ceremony 2012/04/01 Shopping 2011/12/28 Paying newspaper subscription 2011/12/31 3 rows selected. SQL> select * from todo as of timestamp '2011/12/28 18:41:33.854889'; ITEM DUEDATE ------------------------------------ -------------------------------- Attending the wedding ceremony 2012/04/01 Shopping 2011/12/28 2 rows selected.The following example illustrates the execution of a FLASHBACK query using TSN. The dynamic view V$TSN_TIME can display mapping information based on TSN and time.
SQL> create table todo (item varchar2(20), duedate date); Table 'TODO' created. SQL> insert into todo values ('Attending the wedding ceremony', '2012-04-01'); 1 row inserted. SQL> insert into todo values ('Shopping', '2011-12-28'); 1 row inserted. SQL> commit; Commit completed. SQL> select systimestamp from dual; SYSTIMESTAMP ----------------------------------------------------------------- 2011/12/29 09:48:35.494024 1 row selected. SQL> select * from todo; ITEM DUEDATE ------------------------------------ -------------------------------- Attending the wedding ceremony 2012/04/01 Shopping 2011/12/28 2 rows selected. SQL> insert into todo values ('Paying newspaper subscription', '2011-12-31'); 1 row inserted. SQL> commit; Commit completed. SQL> select systimestamp from dual; SYSTIMESTAMP ----------------------------------------------------------------- 2011/12/29 09:49:05.635549 1 row selected. SQL> select * from todo; ITEM DUEDATE ----------------------------------- -------------------------------- Attending the wedding ceremony 2012/04/01 Shopping 2011/12/28 Paying newspaper subscription 2011/12/31 3 rows selected. SQL> select * from v$tsn_time where time >= '2011/12/29 09:48:35.494024' and time <= '2011/12/29 09:49:05.635549'; TSN TIME ---------- ----------------------------------------------------------------- 12347 2011/12/29 09:48:36.018269 12347 2011/12/29 09:48:37.019113 12348 2011/12/29 09:48:38.020786 12348 2011/12/29 09:48:39.021757 12348 2011/12/29 09:48:40.022545 12349 2011/12/29 09:48:42.023222 12350 2011/12/29 09:48:43.722855 12350 2011/12/29 09:48:45.023568 12350 2011/12/29 09:48:46.024370 12351 2011/12/29 09:48:48.024938 12351 2011/12/29 09:48:49.025834 12352 2011/12/29 09:48:50.026523 12352 2011/12/29 09:48:51.027325 12352 2011/12/29 09:48:52.028122 12353 2011/12/29 09:48:54.027811 12353 2011/12/29 09:48:55.027850 12353 2011/12/29 09:48:56.028738 12354 2011/12/29 09:48:58.029017 12354 2011/12/29 09:48:59.030678 12355 2011/12/29 09:49:00.031466 12357 2011/12/29 09:49:02.033270 12357 2011/12/29 09:49:03.033251 12358 2011/12/29 09:49:04.034311 TSN TIME ---------- ----------------------------------------------------------------- 12358 2011/12/29 09:49:05.034333 24 rows selected. SQL> select * from todo as of scn 12350; ITEM DUEDATE ------------------------------------ -------------------------------- Attending the wedding ceremony 2012/04/01 Shopping 2011/12/28 2 rows selected.The following example illustrates the use of PIVOT/UNPIVOT.
SQL> SELECT * FROM (SELECT deptno, job, sal FROM emp ) PIVOT (SUM(sal) salary_sum FOR deptno IN (10 dept10 ,20 dept20, 30 dept30) ); JOB DEPT10_SALARY_SUM DEPT20_SALARY_SUM DEPT30_SALARY_SUM --------- ----------------- ----------------- ----------------- MANAGER 2450 2975 2850 PRESIDENT 5000 SALESMAN 5600 ANALYST 6000 CLERK 1300 1900 950 5 rows selected. SQL> CREATE VIEW pivoted_emp as SELECT * FROM (SELECT deptno, job, sal FROM emp ) PIVOT (SUM(sal) salary_sum FOR deptno IN (10 dept10 ,20 dept20, 30 dept30) ); View 'PIVOTED_EMP' created. SQL> SELECT * FROM pivoted_emp UNPIVOT ( salary_sum FOR department IN (dept10_salary_sum as 10, dept20_salary_sum as 20, dept30_salary_sum as 30) ); JOB DEPARTMENT SALARY_SUM --------- ---------- ---------- MANAGER 10 2450 MANAGER 20 2975 MANAGER 30 2850 PRESIDENT 10 5000 SALESMAN 30 5600 ANALYST 20 6000 CLERK 10 1300 CLERK 20 1900 CLERK 30 950 9 rows selected. SQL> SELECT * FROM pivoted_emp UNPIVOT INCLUDE NULLS ( salary_sum FOR department IN (dept10_salary_sum as 10, dept20_salary_sum as 20, dept30_salary_sum as 30) ); JOB DEPARTMENT SALARY_SUM --------- ---------- ---------- MANAGER 10 2450 MANAGER 20 2975 MANAGER 30 2850 PRESIDENT 10 5000 PRESIDENT 20 PRESIDENT 30 SALESMAN 10 SALESMAN 20 SALESMAN 30 5600 ANALYST 10 ANALYST 20 6000 ANALYST 30 CLERK 10 1300 CLERK 20 1900 CLERK 30 950 15 rows selected.
A join query is used to join rows from two or more tables or views. Tibero executes a join query when there are multiple tables in a FROM clause.
In the SELECT clause in a join query, users can select columns to be included in a joined table. If more than one column in the joined table has the same name, specify their table names to avoid ambiguity.
Most join queries contain a WHERE clause to compare columns from two different tables. This kind of condition is called a join condition.
For a join operation to be executed, each indicated row from each table must satisfy the join condition. Columns in a join condition are not necessarily included in the SELECT clause.
To join three or more tables, join two of them first by using a join condition between the columns of two tables. Then, join the third table together using a join condition between the result of the first join and the third table.
Tibero repeats this process until only a single table results. The optimizer determines the joining sequence based on table indexes and statistics.
A WHERE clause may contain a condition that is not a join condition. These conditions serve to further limit the rows returned from a join query.
Cartesian Products
If a join query does not have any join conditions, a Cartesian product is returned. A Cartesian product is a result which combines each row from the first table with each row from the second table.
For instance, a Cartesian product of two tables which have 100 rows each has 100 * 100 = 10,000 rows. Cartesian products are rarely used as they have too many results. Unless a Cartesian product is specifically required, a join condition has to be included. Even if no join condition for two tables out of three to be joined is specified, the optimizer will determine the join sequence so that a Cartesian product is not created.
An equi join is join where all the join conditions use the equality operator (=).
Equi join joins rows which have the same value for a specified column, and returns them as a result.
A self join is used to join a table with itself. Because a single table is used in the FROM clause twice, use aliases to distinguish columns.
An inner join, also called a simple join, is used to join two or more tables and return only those rows which satisfy the join condition.
An outer join displays an extended result of a general join. Outer joins output rows even if they don't satisfy the join requirement.
There are three kinds of outer joins; left outer joins, right outer joins, and full outer joins.
-
Left Outer Joins
-
When joining tables A and B, all matching records in the join condition are returned, and even if some rows in table B don't meet the join requirements for the row in table A, they are all displayed.
-
If a row in B does not match a row in A, the columns in B all have NULL values.
-
To use a left outer join in an SQL statement, specify LEFT [OUTER] JOIN in the FROM clause, or specify the outer join operator (+) for each column in B in the join condition of the WHERE clause.
-
-
Right Outer Joins
-
When joining table A and B, all matching records in the join condition are returned, and even if some rows in table A don't meet the join requirements for the row in table B, they are all displayed.
-
If a row in A does not match a row in B, the columns in A all have the NULL value.
-
To use a right outer join in an SQL statement, specify RIGHT [OUTER] JOIN in the FROM clause, or specify the outer join operator (+) for column in A in the join condition of the WHERE clause.
-
-
Full Outer Joins
-
When joining tables A and B, all matching records in the join condition are returned. Even if no row in table A meets the join requirements for a row in table B, all rows are displayed. When no rows in table B meets the join requirements for a row in table A, all rows are displayed.
-
If a row in B does not match a row in A, the columns in B all have the NULL value. If a row in A does not match a row in B, the columns in A all have the NULL value.
-
To use a full outer join in an SQL statement, specify FULL [OUTER] JOIN in the FROM clause
-
Note
Tibero supports left outer joins and right outer joins.
In a query that performs an outer join among multiple tables, a table can return NULL for only one of the other tables. For instance, both join conditions for table A and B and for table B and C cannot apply the (+) operator in columns from B.
To specify an outer join in the FROM clause, the outer join operator, (+), has the following rules and restrictions.
-
An outer join cannot be used for a query block that contains a join in the FROM clause.
-
The (+) operator can only be used for columns of a table or view that appears in the WHERE clause.
-
If there are multiple join conditions for table A and B, the (+) operator should be used for every condition. These operators may be treated as a general join without any notice or error message.
-
If the (+) operator is used in both an outer table and an inner table, the join will be treated as a general join.
-
The (+) operator can only be applied to columns, not to a general expression. However, it can be used in columns in an expression.
-
A condition containing the (+) operator cannot be combined with other conditions of the WHERE clause through the OR operator.
-
It is not possible to use a comparison condition for columns containing the (+) operator using the IN operator.
-
It is not possible to compare a column containing the (+) operator to the result of a subquery.
-
If the outer join conditions for table A and B contain a comparison condition between a column of B and a constant, the (+) operator should be applied to the column of B, or it will be treated as a general join.
An anti-join returns rows from the left side of the predicate if there is no corresponding row on the right side of the predicate. This means that it returns rows which fail to match a subquery of NOT IN on the right side of the predicate.
A semi-join returns rows in the same way as an EXIST subquery that handles rows from the left side of the predicate which correspond to multiple rows on the right side, without duplication. If the subquery is connected using an OR in the WHERE clause, it will not be converted into a semi-join or anti-join.
Executing a query in steps helps solve a problem more easily.
For example, when trying to retrieve all members of a department to which Peter belongs, you may first write a query to get the department of Peter, and then write another query to obtain the final result with the first query's result.
This type of query that contains another query is called a subquery.
There are two kinds of subqueries based on where they are used.
A subquery is often used in the following cases:
-
To determine the value of a row to be inserted using an INSERT statement
-
To create and enter values into a table using a CREATE TABLE statement
-
To define a set of rows selected by views using a CREATE VIEW statement
-
To determine a value to be updated in an UPDATE statement
-
To specify conditions for the WHERE, HAVING and START WITH clauses in SELECT, UPDATE and DELETE statements
-
To define a set of rows to use as if they were a table
(Subqueries can be used to specify a table in the INSERT, UPDATE, DELETE or FROM clause in a SELECT statement.)
Note
A subquery can include other subqueries, and in Tibero, a subquery can contain other subqueries in any step.
The following describes subqueries and column references.
-
Inline view
In an inline view, columns of other tables or views specified in the FROM clause of the parent query are not seen.
-
Nested subquery
Nested subqueries show columns of tables specified in the FROM clause of the parent query. If the parent query is a nested subquery of another query, table columns in the FROM clause of the parent query can also be seen in its subqueries.
-
Correlated subquery
When nested subqueries refer to table columns of the parent query, such subqueries are called correlated subqueries.
To refer to columns of a subquery, follow the rules below:
-
When a correlated subquery refers to a table column in the FROM clause of the parent query and the column has the same name as that of a table column in its own FROM clause, the table name of the parent query should prepend the column name.
-
A subquery can refer to columns from the parent or the parent's parents' queries. A correlated subquery is executed independently each time a row is handled in the parent query.
-
To search for a column name in a subquery, if the table name is not specified, tables in the subquery's FROM clause and then tables of its parent and the parent's parents are looked up, unless the column name is ambiguous.
Correlated subqueries are used when a value to be obtained in a child query is determined by each row of its parent queries.
Consider the following cases.
-
A query obtains a list of employees whose annual incomes are more than the average income of their departments.
-
Its child query finds the average annual income of each department.
-
Its parent query compares annual incomes of employees to the average incomes obtained by the child query.
To do this, an annual income should be found for every single employee, and a correlated subquery may help solve the problem.
The following describes a scalar subquery. For more information, see “3.3.6. Subquery Expressions”.
A set operator is used to combine two queries. The number of expressions shown in select_list of the combined queries should be equal, and two corresponding expressions should be the same data type.
The table below shows the priority of set operators and their descriptions.
| Priority | Set Operator | Description |
|---|---|---|
| 1 | INTERSECT | Returns rows that exist in both results of two queries. (A ∩ B) |
| 2 | UNION | Returns a result after removing duplicate rows in the results of two queries. (A ∪ B) |
| UNION ALL | Returns all results without removing duplicate rows in the results of two queries. (A + B) | |
| MINUS | Returns a result after removing results of the second query from a result of the first query. (A - B) | |
| EXCEPT | Identical to the MINUS set operator. (A - B) |
Two or more queries combined by a set operator follow the following rules:
-
The left side query is executed before the right side.
-
The execution order can be adjusted with brackets.
Set operators have the following restrictions:
-
A select_list containing BLOB or CLOB expressions cannot use a set operator.
-
The UA LONG column cannot be used with the UNION, INTERSECT, MINUS and EXCEPT operators.
-
Expressions in select_list should use an alias so that they can be used in order_by_clause.
-
for_update_clause cannot be specified.
If corresponding expressions are not compatible data types, implicit type conversion is not allowed. Otherwise, the following type conversion occurs:
-
If a data type group consists of numbers, the result is a NUMBER type.
-
If a data type group consists of characters, the data type of the result is determined by the following rules:
-
If both groups are CHAR types, the result is a CHAR type.
-
If either of the groups is a VARCHAR2, the result is a VARCHAR2.
-
A hierarchical query returns rows based on a hierarchy among rows in a table.
More than one hierarchical relation can be defined in one target table, and a hierarchical query can be used with one or more tables.
A hierarchical query uses a START WITH … CONNECT BY clause in a SELECT statement.
-
The START WITH clause and the CONNECT BY clause each include one conditional expression. For details about conditional expressions, see “3.4. Conditional Expressions”.
PRIOR
CONNECT BY clauses use a special operator which is not used in other conditional expressions. This operator is the PRIOR operator, which is used to display a hierarchy among rows.
A conditional expression with a PRIOR operator uses the structure below:
PRIOR expr = expr expr = PRIOR expr
A row that contains a result of a PRIOR expression is a parent of the row from the result on the opposite side of the expression.
For instance, when applying the following conditional expression to execute a hierarchical query for a table, EMP, which contains two columns, EMPNO and MGRNO, all rows whose MGRNO column value is the same as the EMPNO value of row A are child rows of row A.
PRIOR EMPNO = MGRNO
In the below table, EMP2, the rows with EMPNO values of 35 and 42 are child rows of their parent row , the row with an EMPNO value of 27. Both rows have a MGRNO value of 27.
EMPNO ENAME ADDR SALARY MGRNO
---------- ------------ ---------------- ---------- ----------
35 John Houston 30000 27
54 Alicia Castle 25000 24
27 Ramesh Humble 38000 12
69 James Houston 35000 24
42 Allen Brooklyn 29000 27
87 Ward Humble 28500 35
24 Martin Spring 30000 12
12 Clark Palo Alto 45000 5
A conditional expression of the CONNECT BY clause can be a complex conditional expression made by connecting several simple conditional expressions. However, the conditional expression should include only one simple conditional expression that uses a PRIOR operator. If there is not exactly one PRIOR operator, an error will occur. A conditional expression of a CONNECT BY clause cannot include a subquery.
CONNECT_BY_ROOT
The CONNECT_BY_ROOT operator can also only be used in a hierarchical query.
The CONNECT_BY_ROOT operator returns column values using data from the root row.
The below example illustrates the use of the CONNECT_BY_ROOT operator.
SQL> SELECT ENAME, CONNECT_BY_ROOT ENAME MANAGER,
SYS_CONNECT_BY_PATH(ENAME, '-') PATH
FROM EMP2
WHERE LEVEL > 1
CONNECT BY PRIOR EMPNO = MGRNO
START WITH ENAME = 'Clark';
ENAME MANAGER PATH
--------------- --------------- -----------------------
Martin Clark -Clark-Martin
James Clark -Clark-Martin-James
Alicia Clark -Clark-Martin-Alicia
Ramesh Clark -Clark-Ramesh
Allen Clark -Clark-Ramesh-Allen
JohnClark Clark -Ramesh-John
Ward Clark -Clark-Ramesh-John-Ward
7 rows selected.
-
CONNECT BY clause
For conditional expressions in a CONNECT BY clause, other relational operators including an equal sign can be used. However, their hierarchy can by defined cyclically, resulting in an infinite loop. To avoid this, an error will occur and Tibero will stop the execution.
The cyclic hierarchy can be output with the CONNECT_BY_ISCYCLE pseudo column value.
-
START WITH clause
The START WITH clause includes a conditional expression for the root row in order to search for the hierarchy. The search can start from zero or more root rows based on the conditional expression. If a START WITH clause is omitted, the hierarchy will treat every row in the table like a root row.
-
Combination of a CONNECT BY clause and a WHERE clause
If a CONNECT BY clause and a WHERE clause are used together in a SELECT statement, conditional expressions in the CONNECT BY clause will be applied first. If the WHERE clause contains a join condition and the SELECT statement executes a join operation, the join condition will be applied first to perform the join, and then the conditional expressions in the CONNECT BY clause and the rest of the conditional expressions in the WHERE clause will be applied in order.
The conditional expressions in the WHERE clause are applied after the hierarchy of rows is determined by the conditional expressions in the CONNECT BY clause, so even if a particular row is removed by the WHERE clause, the child rows of the row can still be included in the final result.
-
ORDER SIBLINGS BY clause
If a general ORDER BY clause is used for a hierarchical query, the hierarchy is ignored. By using ORDER SIBLINGS BY clause, only rows on the same level will be sorted, while maintaining the hierarchy.
A hierarchical query is executed recursively. First, all child rows of a root row are searched.
Next, child rows of the child rows are searched. This search continues until no child row is found. If an infinite loop is encountered, an error occurs.
The result output order is based on a depth-first order.
The next figure is an example of a hierarchy, created by a hierarchical query of table EMP2. The value in each circle is a EMPNO column value. The row display order is as follows: 12, 27, 35, 87, 42, 24, 54 and 69.
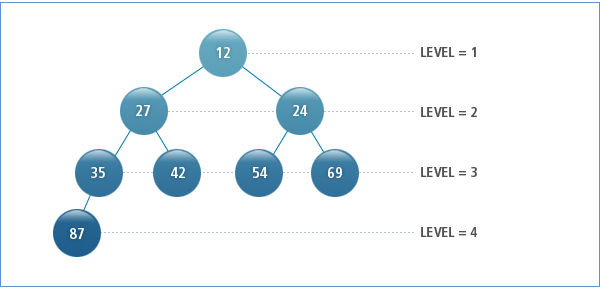
Each row in a hierarchy tree has a level value. The level of a root row is 1, and the level of each child row increases by one as it goes down.
In the above figure, [Figure 5.1], the row with an EMPNO value of 12 is level 1, the rows with values of 27 and 24 are level 2, the rows with values of 35, 42, 54 and 69 are level 3, and the row with EMPNO = 87 is level 4.
Level values can be output with the LEVEL pseudo-column.
The following is the query and result of using a SELECT statement to execute a hierarchical query without using the START WITH clause. This shows how to output child rows with every row as a root row.
SQL> SELECT EMPNO, ENAME, ADDR, MGRNO
FROM EMP2
CONNECT BY PRIOR EMPNO = MGRNO;
EMPNO ENAME ADDR MGRNO
---------- ------------ ---------------- ----------
12 Clark Palo Alto 5
27 Ramesh Humble 12
35 John Houston 27
87 Ward Humble 35
42 Allen Brooklyn 27
24 Martin Spring 12
54 Alicia Castle 24
69 James Houston 24
27 Ramesh Humble 12
35 John Houston 27
87 Ward Humble 35
42 Allen Brooklyn 27
24 Martin Spring 12
54 Alicia Castle 24
69 James Houston 24
54 Alicia Castle 24
69 James Houston 24
35 John Houston 27
87 Ward Humble 35
42 Allen Brooklyn 27
87 Ward Humble 35
21 rows selected.
The following example illustrates the query and result of using a SELECT statement to execute a hierarchical query with the START WITH clause. It searches for the child rows of a root row whose EMPNO value is 12.
SQL> SELECT EMPNO, ENAME, ADDR, MGRNO
FROM EMP2
START WITH EMPNO = 12
CONNECT BY PRIOR EMPNO = MGRNO;
EMPNO ENAME ADDR MGRNO
---------- ------------ ---------------- ----------
12 Clark Palo Alto 5
27 Ramesh Humble 12
35 John Houston 27
87 Ward Humble 35
42 Allen Brooklyn 27
24 Martin Spring 12
54 Alicia Castle 24
69 James Houston 24
8 rows selected.
The below example illustrates the query and result of using a SELECT statement to execute a hierarchical query with a WHERE clause. It shows that the row with an EMPNO value of 27 is removed by the WHERE clause, but its child rows are still displayed.
SQL> SELECT EMPNO, ENAME, ADDR, MGRNO
FROM EMP2
WHERE ENAME != ’Ramesh’
START WITH EMPNO = 12
CONNECT BY PRIOR EMPNO = MGRNO;
EMPNO ENAME ADDR MGRNO
---------- ------------ ---------------- ----------
12 Clark Palo Alto 5
35 John Houston 27
87 Ward Humble 35
42 Allen Brooklyn 27
24 Martin Spring 12
54 Alicia Castle 24
69 James Houston 24
7 rows selected.
The next example illustrates the query and result of using a SELECT statement to execute a hierarchical query with a LEVEL column.
SQL> SELECT EMPNO, ENAME, ADDR, MGRNO, LEVEL
FROM EMP2
START WITH EMPNO = 12
CONNECT BY PRIOR EMPNO = MGRNO;
EMPNO ENAME ADDR MGRNO LEVEL
---------- ------------ ---------------- ---------- ----------
12 Clark Palo Alto 5 1
27 Ramesh Humble 12 2
35 John Houston 27 3
87 Ward Humble 35 4
42 Allen Brooklyn 27 3
24 Martin Spring 12 2
54 Alicia Castle 24 3
69 James Houston 24 3
8 rows selected.
A parallel query is used to process an SQL statement with multiple worker threads. When scanning a large table, processing different areas of the table using multiple worker threads helps speed up execution.
Parallel queries are more often used to handle large data, such as in a data warehouse environment, than to perform OLTP (Online Transaction Processing).
The following example illustrates the use of a parallel query.
SELECT /*+ PARALLEL (4) */ DEPTNO, AVG(SAL) FROM EMP GROUP BY DEPTNO;
To use a parallel query, use the PARALLEL hint. In the above example, the number 4 in "PARALLEL (4)" indicates the number of working threads to be used in the parallel query, and this number is called the DOP (Degree of Parallelism). It states that the example should process the query with four worker threads.
After a parallel query is requested, Tibero server tries to secure as many idle worker threads as was specified in the DOP.
If the number of available worker threads is smaller than the number specified by the hint, the parallel query is executed only with the available worker threads. If the DOP is 1 due to a lack of worker threads, the query is not performed in parallel and is executed as a normal query. The user is not notified of this situation.
The following operations can be executed by Tibero using parallel processing:
-
TABLE FULL SCAN
-
INDEX FAST FULL SCAN
-
HASH JOIN
-
NESTED LOOP JOIN
-
MERGE JOIN
-
SET OPERATION
-
GROUP BY
-
ORDER BY
-
AGGREGATE FUNCTION
Tibero creates an execution plan to execute a parallel query.
The following example illustrates how to create an execution plan for a parallel query.
SQL> SET AUTOT TRACE EXPLAIN SQL> SELECT EMPNO, ENAME, SAL FROM EMP ORDER BY SAL; SQL ID: 451 Plan Hash Value: 2848347407 Explain Plan -------------------------------------------------------------------------------- 1 ORDER BY (SORT) 2 TABLE ACCESS (FULL): EMP SQL> SELECT /*+ PARALLEL (4) */ EMPNO, ENAME, SAL FROM EMP ORDER BY SAL; SQL ID: 449 Plan Hash Value: 979088785 Explain Plan -------------------------------------------------------------------------------- 1 PE MANAGER 2 PE SEND QC (ORDER) 3 ORDER BY (SORT) 4 PE RECV 5 PE SEND (RANGE) 6 PE BLOCK ITERATOR 7 TABLE ACCESS (FULL): EMP
As shown above, new operation nodes are added to the explanation plan of a parallel query that uses a PARALLEL hint. The new operation nodes perform tasks required to execute the parallel query.
If PE RECV and PE SEND nodes are added, Tibero uses a two-set model. In this case, the number of worker threads that are actually used is twice the DOP. The worker threads in one set work as consumers, while those in the other set work as producers. The system uses a two-set model for a pipelining effect using the parallel processing of the two operation nodes.
The dual table consists of a single VARCHAR (1) column whose name is DUMMY, and a single row that includes the string 'X'.
A dual table has the following features:
-
All users can access the dual table.
-
Insert, delete and update operations cannot be used with the dual table, and it is not possible to modify or delete the table.
-
The dual table can be used in an arithmetic expression not related to the table.
-
The dual table includes only one row, so the result of any expression is always one row.
The following example illustrates the use of a dual table:
SQL> SELECT SIN(3.141592654 / 2.0) FROM DUAL;
SIN(3.141592654/2.0)
--------------------
1
1 row selected.